
Kyber – Throughput Priority
The Kyber scheduler is designed specifically for modern high-performance storage devices. Historically, the ultimate goal of disk schedulers has always been to reduce the seek time of mechanical drives, thereby minimizing the overhead caused by random access operations. As a result, different disk schedulers employ complex techniques to achieve this common goal. Each scheduler prioritizes certain aspects of performance in different ways, introducing additional overhead when handling I/O requests. Since modern drives (such as SATA and NVMe SSDs) are not hindered by random access operations, some of the complex techniques used by certain schedulers may not be applicable to these devices. For example, the BFQ scheduler has slightly higher overhead for each request, making it unsuitable for systems with high-throughput drives. This is where the Kyber scheduler comes into play.
The Kyber scheduler does not have complex internal scheduling algorithms. It is designed for environments that include high-performance storage devices. It employs a very simple approach and implements some basic strategies to orchestrate I/O requests. The Kyber scheduler divides the underlying devices into multiple domains. The idea is to maintain a queue for different types of I/O requests.
The Kyber scheduler classifies requests into four categories: read, write, discard, and other. The Kyber scheduler maintains queues for these types of requests. Discard requests are used for devices like NVMe SSDs, and SATA’s trim is the same mechanism. The filesystem on the device can issue this request to discard blocks that are not used by the filesystem. For the previously mentioned request types, the scheduler imposes limits on the corresponding operations in the device queue.

The key to the Kyber scheduling method is to limit the size of the scheduling queue. This is directly related to the waiting time of I/O requests in the request queue. The scheduler only sends a limited number of operations to the scheduling queue, ensuring that the scheduling queue does not become too congested. This leads to requests in the scheduling queue being processed quickly. Therefore, I/O operations in the request queue do not have to wait too long to be serviced. This approach can reduce latency.
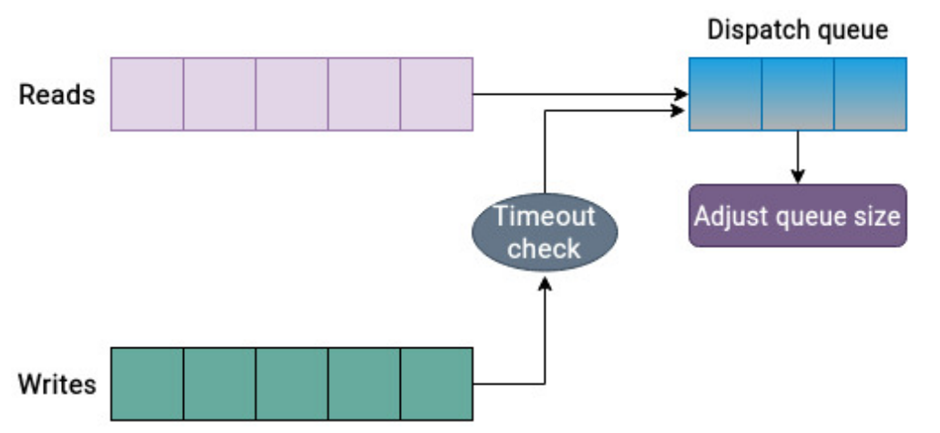
To determine the number of requests allowed in the scheduling queue, the Kyber scheduler uses a simple yet effective method. It calculates the completion time for each request and adjusts the number of requests in the scheduling queue based on this feedback. Additionally, the target latency for read and synchronous write operations is an adjustable parameter that can be changed. Depending on their values, the scheduler will limit requests to meet these target latencies. The Kyber scheduler prioritizes requests in the read queue over those in the write queue unless the time for unfinished write requests is too long, indicating that the target latency has been breached. (The principle of simplicity is paramount.)
The Kyber scheduler is the high-performance engine for modern storage devices. It is tailored for high-speed storage devices (such as SATA SSDs and NVMe SSDs) and prioritizes low-latency I/O operations. The scheduler dynamically adjusts itself by carefully examining I/O requests and allows for establishing target latencies for synchronous writes and reads. Thus, it regulates I/O requests to meet specified targets. NVMe drives are referred to as Kyber.
None – Minimal scheduling overhead
The scheduling of I/O requests is a multifaceted issue. The scheduler must consider several aspects, such as reordering requests in the queue, allocating a portion of the disk to each process, controlling the execution time of each request, and ensuring that a single request does not monopolize available storage resources. Each scheduler assumes that the host itself cannot optimize requests. Therefore, it intervenes and applies complex techniques to try to make the most of the available storage resources. The more complex the scheduling techniques, the greater the processing overhead. When optimizing requests, the scheduler often makes some assumptions about the underlying devices. This is effective unless the lower layers in the stack have better visibility of the available storage resources and can make scheduling decisions themselves, such as:
• In high-end storage setups, such as SAN, storage arrays often include their own scheduling logic because they have a deeper understanding of the nuances of the underlying devices. Therefore, I/O request scheduling typically occurs at lower layers. When using RAID controllers, the host system does not have complete knowledge of the underlying disks. Even if the scheduler has optimized the I/O requests, it may not make much difference because the host system lacks the visibility to accurately reorder requests to reduce seek time. In this case, it makes sense to simply dispatch requests to the RAID controller. Let the RAID controller handle scheduling. (Of course, this also introduces a new topic. Once mounted behind the RAID controller, the performance of I/O is no longer determined solely by the disks. Once the disks are mounted to the RAID controller, the performance differs from that of disks directly connected to the system bus, necessitating consideration of the compatibility between the RAID card and the disks.)
• Most scheduling optimizations are geared towards slow mechanical drives. If the environment consists of SATA SSDs and NVMe SSDs, the processing overhead associated with these scheduling optimizations may seem excessive..
In this case, a unique but effective solution is to use “no scheduler“. The no scheduler is a multi-queue “no-opI/O scheduler“. For single-queue devices, the same functionality is achieved through the “no-op scheduler“.
The none scheduler is the simplest of all schedulers, as it does not perform any scheduling optimizations. Each incoming I/O request is appended to a FIFO queue and delegated to the block device for processing. This strategy proves beneficial when it is determined that the host should not rearrange requests based on their sector numbers. The none scheduler has a single request queue containing read and write I/O requests. Due to its basic approach, while the none I/O scheduler imposes minimal overhead, it does not guarantee any specific quality of service. The no scheduler also does not perform any request reordering. It only performs request merging to reduce seek time and improve throughput. Unlike all other schedulers, the none scheduler has no adjustable parameters or settings for optimization. The request merging operation is the entirety of its complexity. Therefore, the none scheduler uses minimal CPU instructions for each I/O request. The operation of the none scheduler is based on the assumption that lower layers (such as RAID controllers or storage controllers) will optimize I/O performance. There is a saying about letting go.
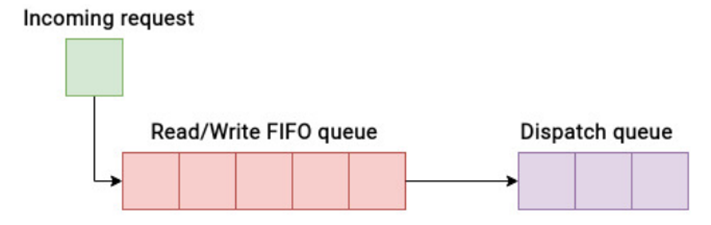
Although every environment has many variables, based on operational patterns, the None scheduler seems to be the preferred scheduler for enterprise SAN systems because it makes no assumptions about the underlying physical devices and does not make scheduling decisions that may compete or conflict with low-level I/O controller logic.
Scheduler Challenges
The Linux I/O scheduler is part of the kernel, integrated by default into Linux. When selecting a scheduler, benchmark results collected through actual application workloads should always be attached. Most of the time, the default settings may already be good enough. It is only when we try to achieve maximum efficiency that we need to attempt to modify the default settings. The pluggable nature of these schedulers means we can dynamically change the I/O scheduler for block devices. The currently active scheduler for a specific disk device can be checked through the system filesystem (sysfs).
[root@linuxbox ~]# cat /sys/block/sda/queue/scheduler
 Nvme device:
Nvme device: 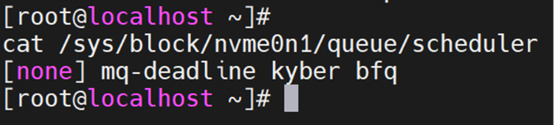
SATA device:

Square brackets [ ] indicate the currently active scheduler.
To change the active scheduler, write the name of the desired scheduler to the scheduler file. For example, to set the sda to use the BFQ scheduler, use the following command:
[root@linuxbox ~]# echo bfq > /sys/block/sda/queue/scheduler
The above method will only temporarily set the scheduler and revert to the default settings after a reboot. To make this change permanent, edit the /etc/default/grub file and add the elevator=bfq parameter to the GRUB_CMDLINE_LINUX_DEFAULT. Then, regenerate the GRUB configuration and reboot the system.
Simply changing the scheduler will not yield a twofold performance increase. Typically, the improvement will be in the range of 10-20%. While every environment is different and the performance of the scheduler may vary due to several variables, as a baseline, here are some use cases for the schedulers discussed in this chapter:
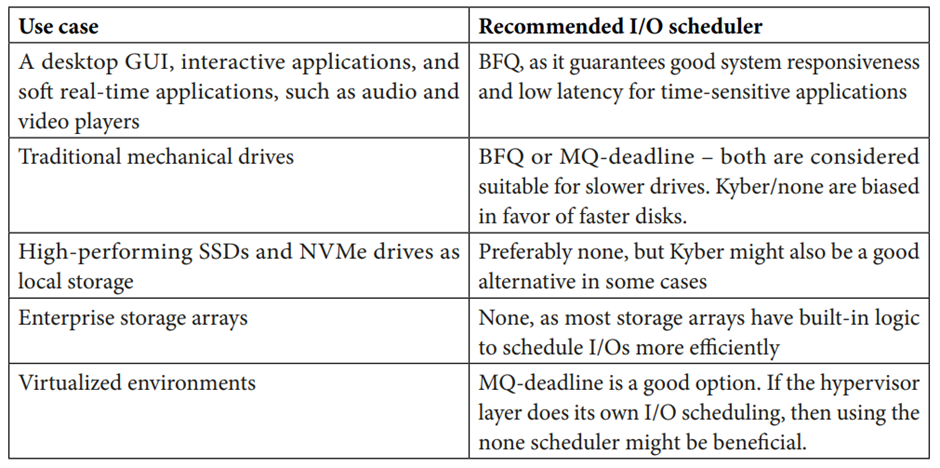
These are not strict use cases, as several situations may overlap. The type of application, workload, host system, and storage medium are just some of the factors that the scheduler must consider before making a decision. Generally, deadline schedulers are considered a good choice because they have moderate CPU overhead. BFQ performs well in desktop environments, while None and Kyber are better suited for high-end storage devices.
Conclusion
I/O scheduling is a critical function at the block layer. When read or write requests pass through all layers of the virtual file system, they ultimately reach the block layer. The block layer includes multiple I/O schedulers suitable for specific use cases. The choice of I/O scheduler plays a crucial role in determining how I/O requests are handled at lower layers. To make more performance-oriented decisions, most schedulers adopt common techniques that help improve overall disk performance. These techniques include merging, coalescing, sorting, and insertion.
The kernel provides a separate set of I/O schedulers for single-queue and multi-queue devices. Since kernel version 5.0, single-queue schedulers have been deprecated. Multi-queue scheduling options include multi-queue deadline schedulers, BFQ, Kyber, and none schedulers. Each of these schedulers is suitable for specific use cases, and there is no single recommendation that fits all situations. The MQ-deadline scheduler offers excellent overall performance. The BFQ scheduler is more geared towards interactive applications, while Kyber and None are aimed at high-end storage devices. To choose a scheduler, one must understand the details of the environment, including workload types, applications, host systems, and backend physical media.
<End of Full Text>
The local ruffian tabby cat heard that a silver tabby had come from the city last night, worth a lot, so it took its little follower, the orange cat, to investigate.Just as they arrived at the silver tabby’s courtyard, they were just blocked.
Tabby: Hey, who is it, is this? Oh, isn’t this the little eunuch from the city, hmm?
The silver tabby shrank back: Um… My mom sent me here. I didn’t want to come… I want my mom to buy a ticket back…

“Where to go?”
“Back to my home in the city.”
“If you crawl under me, I’ll let you go.”
“You, you better not mess around, I was bought for 3000 bucks by my owner, raised from a young age…””
“What, are you comparing your background with me and little orange? I was given as a bonus for recharging! I grew up drinking dog milk! I’ve never tasted cat food!”
“What’s so great about that?……”
“You don’t understand! In this area, ask little orange, what do they all call me?!”
Orange cat:“My brother is so tough! We all call him a dog mother raised!”