
In today’s digital age, multi-core processors have become standard in computer systems, from our everyday office computers to the massive server clusters in data centers. This hardware advancement allows computer systems to handle multiple tasks simultaneously, greatly enhancing computational efficiency. Just like a busy traffic hub with multiple lanes, vehicles move back and forth, seemingly chaotic yet orderly.
However, in the Linux kernel, this “traffic control center,” when multiple processes or threads, like vehicles in a continuous flow, attempt to access shared resources simultaneously, problems arise. Imagine two roads where vehicles want to pass through a narrow intersection at the same time; without proper traffic rules, congestion or even collisions are inevitable. In the Linux kernel, these shared resources are like that narrow intersection, and if concurrent access by processes and threads lacks effective management, it can lead to severe issues such as data inconsistency and program crashes. This not only affects system stability but can also interrupt critical business operations, resulting in immeasurable losses.
So, how does the Linux kernel ensure safe access to shared resources in a complex concurrent environment, maintaining efficient and stable system operation? The answer lies in its meticulously designed synchronization mechanisms. It functions like a sophisticated traffic control system, guiding processes and threads—these “vehicles”—to pass through shared resources—this “intersection”—in an orderly manner. Next, let us delve into the world of Linux kernel synchronization mechanisms, exploring their mysteries and unlocking key techniques for concurrent programming, laying a solid foundation for building more stable and efficient systems.
Commonly used Linux kernel synchronization mechanisms include atomic operations, Per-CPU variables, memory barriers, spinlocks, mutex locks, semaphores, and RCU, with the latter few relying on the former three basic synchronization mechanisms. Before we formally analyze the specific implementations of kernel synchronization mechanisms, we need to clarify some basic concepts.
1. Basic Concepts
1.1 Synchronization Mechanism
Since it is a synchronization mechanism, we must first understand what synchronization is. Synchronization refers to the mechanism used to control multiple execution paths to access certain system resources according to specific rules or sequences. The so-called execution path is the flow of code running on the CPU. We know that the smallest unit of CPU scheduling is a thread, which can be a user-space thread, a kernel thread, or even an interrupt service routine. Therefore, the execution path here includes user-space threads, kernel threads, and interrupt service routines. Different terminologies such as execution path, execution unit, control path, etc., refer to the same essence. So why do we need synchronization mechanisms? Please continue reading.
1.2 Concurrency and Race Conditions
Concurrency refers to the simultaneous execution of two or more execution paths, and the concurrent execution paths accessing shared resources (hardware resources and global variables in software, etc.) can easily lead to race conditions. For example, suppose there is an LED light that can be controlled by an app. APP1 controls the light to turn on for one second and off for one second, while APP2 controls the light to turn on for 500ms and off for 1500ms. If APP1 and APP2 run concurrently on CPU1 and CPU2, respectively, what will the LED light’s behavior be? It is very likely that the LED light’s on-off rhythm will not align with what both apps desire; when APP1 turns off the LED light, it may coincide with APP2 trying to turn it on. Clearly, APP1 and APP2 have a competitive relationship over the LED light resource. Race conditions are dangerous; if left unchecked, they can lead to unexpected program results or even system crashes.
In operating systems, more complex and chaotic concurrency exists, and synchronization mechanisms are designed to address concurrency and race conditions. Synchronization mechanisms achieve mutual exclusion access to shared resources by protecting critical sections (the code area that accesses shared resources). Mutual exclusion access means that when one execution path accesses shared resources, another execution path is prohibited from accessing them. A relatable everyday example of concurrency and race conditions is as follows: Suppose you and your colleague Zhang Xiaosan both need to use the restroom, but the company only has one restroom and one stall. When Zhang Xiaosan enters the restroom and closes the door, you cannot enter and must wait outside.
Only when Xiaosan comes out can you go in to solve your problem. Here, the company restroom is the shared resource, and both you and Zhang Xiaosan needing this shared resource simultaneously is concurrency; your demand for the restroom constitutes a race condition, and the restroom door acts as a synchronization mechanism—if it is in use, you cannot use it.
In summary, as illustrated in the following diagram:
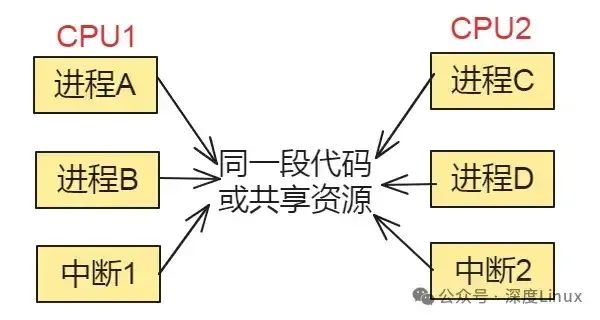
1.3 Interrupts and Preemption
The concept of interrupts is straightforward, and this article will not explain it. However, this does not mean that the interrupt part of the Linux kernel is simple. In fact, the Linux kernel’s interrupt subsystem is quite complex because interrupts are crucial for operating systems. The author plans to introduce this in a future topic. For the analysis of synchronization mechanism code, understanding the concept of interrupts is sufficient; there is no need to delve into the specific code implementations in the kernel.
Preemption is a concept of process scheduling. The Linux kernel has supported preemptive scheduling since version 2.6. Process scheduling (management) is one of the core subsystems of the Linux kernel, and it is exceptionally large. This article will only briefly introduce the basic concepts, which are sufficient for analyzing synchronization mechanism code. In simple terms, preemption refers to a situation where a task (which can be a user-space process or a kernel thread) happily running on the CPU is interrupted by another task (usually of higher priority) taking over the CPU’s execution rights.
There is a somewhat ambiguous relationship between interrupts and preemption; simply put, preemption relies on interrupts. If the current CPU has disabled local interrupts, it also means that preemption on that CPU is disabled. However, disabling preemption does not affect interrupts. In the Linux kernel, the preempt_enable() macro function is used to enable preemption on the current CPU, while preempt_disable() is used to disable it.
Here, the term “current CPU” is not entirely accurate; a more precise description would be the task running on the current CPU. The specific implementation of preempt_enable() and preempt_disable() could be elaborated in a separate article, and the author has not delved into it, so I will not overstep. Interested readers can refer to RTFSC. Regardless of whether it is user-space preemption or kernel-space preemption, it does not occur at any code location but at specific preemption points. The preemption points are as follows:
User-Space Preemption
- 1. When returning from a system call to user space;
- 2. When returning from an interrupt (exception) handler to user space.
Kernel-Space Preemption:
- 1. When an interrupt handler exits and returns to kernel space;
- 2. When a task explicitly calls schedule();
- 3. When a task becomes blocked (at this point, the scheduler completes the scheduling).
1.4 Compiler Reordering and Compiler Barriers
The job of the compiler is to optimize our code for better performance. This includes rearranging instructions without changing program behavior. Since the compiler does not know which parts of the code need to be thread-safe, it assumes that our code is executed in a single-threaded manner and performs instruction reordering optimizations while ensuring single-thread safety. Therefore, when you do not want the compiler to reorder instructions, you need to explicitly tell the compiler that you do not need reordering. Otherwise, it will not listen to you. In this article, we will explore the compiler’s optimization rules regarding instruction reordering.
Note: Testing was done using aarch64-linux-gnu-gcc version: 7.3.0
Compiler Instruction Reordering
The main job of the compiler is to convert human-readable source code into machine language, which is the code readable by the CPU. Therefore, the compiler can do some behind-the-scenes things. Consider the following C code:
int a, b;
void foo(void)
{
a = b + 1;
b = 0;
}Using aarch64-linux-gnu-gcc to compile the above code without optimization and using the objdump tool to view the disassembly results of foo(), we get:
<foo>:
...
ldr w0, [x0] //load b to w0
add w1, w0, #0x1
...
str w1, [x0] //a = b + 1
...
str wzr, [x0] //b = 0We should know that the default compilation optimization option for Linux is -O2, so we compile the above code with the -O2 optimization option and disassemble it to get the following assembly results:
<foo>:
...
ldr w2, [x0] //load b to w2
str wzr, [x0] //b = 0
add w0, w2, #0x1
str w0, [x1] //a = b + 1Comparing the optimized and unoptimized results, we find that in the unoptimized case, the memory write order of a and b follows the program order; however, after -O2 optimization, the write order of a and b is reversed compared to the program order. The code after -O2 optimization can be viewed as follows:
int a, b;
void foo(void)
{
register int reg = b;
b = 0;
a = reg + 1;
}This is compiler reordering. Why can this be done? For single-threaded execution, the write order of a and b is considered by the compiler to be unproblematic. Moreover, the final result is also correct (a == 1 && b == 0). This kind of compiler reordering is generally not an issue. However, in certain cases, it may introduce problems. For example, if we use a global variable flag to indicate whether shared data is ready, compiler reordering may introduce issues. Consider the following code (lock-free programming):
int flag, data;
void write_data(int value)
{
data = value;
flag = 1;
}If the assembly code generated by the compiler writes flag before data into memory, then even on a single-core system, we may encounter issues. After setting flag to 1, before data is written as 45, a preemption occurs. Another process sees that flag has been set to 1, assuming that data is ready. However, the value read from data is not 45. Why does the compiler do this? Because the compiler does not know that there is a strict dependency between data and flag. This logical relationship is imposed by us. How can we avoid this optimization?
Explicit Compiler Barriers
To resolve the dependency issues between variables that lead to incorrect compiler optimizations, the compiler provides compiler barriers that can be used to tell the compiler not to reorder. We will continue using the above foo() function as a demonstration experiment, inserting compiler barriers between the code.
#define barrier() __asm__ __volatile__("": : :"memory")
int a, b;
void foo(void)
{
a = b + 1;
barrier();
b = 0;
}barrier() is a barrier provided by the compiler, which tells the compiler that the values in memory have changed, and any previous memory caches (cached in registers) must be discarded. Memory operations after barrier() need to be reloaded from memory and cannot use previously cached values in registers. Furthermore, it can prevent the compiler from optimizing the memory access order before and after barrier(). barrier() acts like an insurmountable barrier in the code; load/store operations before barrier() cannot move after it; similarly, load/store operations after barrier() cannot occur before it. Still using the -O2 optimization option to compile the above code, we disassemble it to get the following results:
<foo>:
...
ldr w2, [x0] //load b to w2
add w2, w2, #0x1
str w2, [x1] //a = a + 1
str wzr, [x0] //b = 0
...We can see that after inserting compiler barriers, the write order of a and b is consistent with the program order. Therefore, when our code requires strict memory order, we need to consider compiler barriers.
Implied Compiler Barriers
In addition to explicitly inserting compiler barriers, there are other methods to prevent compiler reordering. For example, CPU barrier instructions will also prevent compiler reordering. We will consider CPU barriers later. Additionally, when a function contains compiler barriers, that function also acts as a compiler barrier. Even if this function is inlined, it still applies. For example, the foo() function with the inserted barrier() acts as a compiler barrier when other functions call it. Consider the following code:
int a, b, c;
void fun(void)
{
c = 2;
barrier();
}
void foo(void)
{
a = b + 1;
fun(); /* fun() call acts as compiler barriers */
b = 0;
}The fun() function contains barrier(), so the call to fun() in the foo() function also exhibits the effect of compiler barriers, ensuring the write order of a and b. What if the fun() function does not contain barrier()? In fact, most function calls exhibit the effect of compiler barriers. However, this does not include inline functions. Therefore, if fun() is inlined into foo(), then fun() does not have the effect of compiler barriers.
If the called function is an external function, its side effects are even stronger than compiler barriers. This is because the compiler does not know what side effects the function has. It must forget any assumptions it has made about memory, even if those assumptions may be visible to that function. Let’s look at the following code snippet, where printf() is certainly an external function.
int a, b;
void foo(void)
{
a = 5;
printf("smcdef");
b = a;
}Using the -O2 optimization option to compile the code, objdump disassembles it to get the following results:
<foo>:
...
mov w2, #0x5 //#5
str w2, [x19] //a = 5
bl 640 <__printf_chk@plt> //printf()
ldr w1, [x19] //reload a to w1
...
str w1, [x0] //b = aThe compiler cannot assume that printf() will not use or modify the variable a. Therefore, before calling printf(), it writes 5 to a to ensure that printf() may use the new value. After the printf() call, it reloads the value of a from memory and then assigns it to variable b. The reason for reloading a is that the compiler does not know whether printf() will modify the value of a.
Thus, we can see that even with compiler reordering, there are still many limitations. When we need to consider compiler barriers, we must explicitly insert barrier() rather than relying on the implicit compiler barriers of function calls. Because no one can guarantee that the called function will not be optimized into inline form.
Besides preventing compiler reordering, what else can barrier() do?
Consider the following code snippet:
int run = 1;
void foo(void)
{
while (run)
;
}run is a global variable, and foo() runs in one process, looping indefinitely. We expect that foo() will wait until another process modifies run to 0 before exiting the loop. Will the actual compiled code achieve our expected result? Let’s look at the assembly code:
0000000000000748 <foo>:
748: 90000080 adrp x0, 10000
74c: f947e800 ldr x0, [x0, #4048]
750: b9400000 ldr w0, [x0] //load run to w0
754: d503201f nop
758: 35000000 cbnz w0, 758 <foo+0x10> //if (w0) while (1);
75c: d65f03c0 retThe compiled code can be converted into the following C language form:
int run = 1;
void foo(void)
{
register int reg = run;
if (reg)
while (1)
;
}The compiler first loads run into a register reg, then checks if reg meets the loop condition. If it does, it enters an infinite loop. However, during the loop, the value of register reg does not change. Therefore, even if another process modifies run to 0, foo() cannot exit the loop. Clearly, this is not the result we want. Let’s see the result after adding barrier():
0000000000000748 <foo>:
748: 90000080 adrp x0, 10000
74c: f947e800 ldr x0, [x0, #4048]
750: b9400001 ldr w1, [x0] //load run to w0
754: 34000061 cbz w1, 760 <foo+0x18>
758: b9400001 ldr w1, [x0] //load run to w0
75c: 35ffffe1 cbnz w1, 758 <foo+0x10> //if (w0) goto 758
760: d65f03c0 retWe can see that after adding barrier(), the result is indeed what we want. Each iteration of the loop reloads the value of run from memory. Therefore, when another process modifies run to 0, foo() can exit the loop normally. Why does the assembly code after adding barrier() yield the correct result? Because barrier() tells the compiler that the value in memory has changed, and subsequent operations must be reloaded from memory rather than using cached values in registers. Thus, the run variable will be reloaded from memory, and the loop condition will be checked. This way, when another process modifies the run variable, foo() can see it.
In the Linux kernel, there is a function called cpu_relax(), which is defined as follows on the ARM64 platform:
static inline void cpu_relax(void)
{
asm volatile("yield" ::: "memory");
}We can see that cpu_relax() is based on barrier() with an additional assembly instruction yield. In the kernel, we often see while loops like the one mentioned above, where the loop condition is a global variable. To avoid the aforementioned issues, we would insert a call to cpu_relax() in the loop.
int run = 1;
void foo(void)
{
while (run)
cpu_relax();
}Of course, we can also use the READ_ONCE() provided by Linux. For example, the following modification can also achieve our expected effect.
int run = 1;
void foo(void)
{
while (READ_ONCE(run)) /* similar to while (*(volatile int *)&run) */
;
}Alternatively, you can modify the definition of run to be volatile int run, and you will get the following code, which can also achieve the expected result.
volatile int run = 1;
void foo(void)
{
while (run);
}2. The Origin of Synchronization Mechanisms
Before delving into the Linux kernel synchronization mechanisms, we first need to understand the concepts of concurrency and race conditions, as they are the fundamental reasons for the existence of synchronization mechanisms.
2.1 Various Forms of Concurrency
Concurrency, simply put, refers to the simultaneous and parallel execution of multiple execution units. In Linux systems, concurrency mainly occurs in the following scenarios:
SMP Multi-CPU: Symmetric Multi-Processing (SMP) is a tightly coupled, shared memory system model where multiple CPUs use a common system bus to access shared peripherals and memory. In this case, there is a possibility of concurrency between processes and interrupts on two CPUs. For example, process A on CPU0 and process B on CPU1 may simultaneously access the same data in shared memory.
Single CPU with Preemptive Processes: In a single CPU, although only one process can run at a time, the execution of a process may be interrupted. For instance, during execution, a process may be interrupted due to time slice exhaustion or preemption by another higher-priority process. When a high-priority process and the interrupted process access shared resources together, race conditions may occur. For example, if process A is accessing a global variable and has not finished modifying it, it may be preempted by process B, which also accesses and modifies that global variable, potentially leading to data corruption.
Interrupts and Processes: Interrupts can interrupt a running process. If the interrupt service routine also accesses the shared resource that the process is currently accessing, race conditions can easily arise. For example, if a process is sending data to a serial port and an interrupt occurs, the interrupt service routine may also attempt to send data to the serial port, leading to errors in data transmission.
2.2 Problems Caused by Race Conditions
When multiple concurrently executing units access shared resources, race conditions may occur. Race conditions can lead to unpredictable program behavior, such as data inconsistency and program crashes. Let’s look at a simple example: suppose there are two processes P1 and P2, both trying to increment a shared variable count. The code might look like this:
// Shared variable
int count = 0;
// Process P1's operation
void process1() {
int temp = count; // Read count's value
temp = temp + 1; // Increment temp
count = temp; // Write temp's value back to count
}
// Process P2's operation
void process2() {
int temp = count; // Read count's value
temp = temp + 1; // Increment temp
count = temp; // Write temp's value back to count
}If these two processes execute concurrently, the expected final value of count should be 2. However, due to the presence of race conditions, the following situation may occur:
- Process P1 reads the value of count, at which point temp is 0.
- Process P2 reads the value of count, at which point temp is also 0, because P1 has not yet written the modified value back to count.
- Process P1 increments temp and writes temp back to count, resulting in count being 1.
- Process P2 increments temp (at this point, temp is still 0) and writes temp back to count, resulting in count still being 1 instead of 2.
This is the data error caused by race conditions. In the actual Linux kernel, shared resources may include hardware devices, global variables, file systems, etc., and the problems caused by race conditions can be more complex and severe, potentially leading to system instability and data loss. Therefore, to ensure the correctness and stability of the system, the Linux kernel requires an effective set of synchronization mechanisms to address race condition issues.
3. Common Synchronization Mechanisms Analysis
To address concurrency and race condition issues, the Linux kernel provides various synchronization mechanisms, each with its unique working principles and applicable scenarios. Let’s take a closer look at these synchronization mechanisms.
3.1 Spinlocks
Spinlocks are a relatively simple synchronization mechanism. When a thread attempts to acquire a spinlock, if the lock is already held by another thread, that thread will not enter a blocked state but will continuously loop in place, checking whether the lock is available. This process is called “spinning.” It’s like going to a restaurant and finding your favorite table occupied by someone else; you really want to sit there, so you stand by and keep an eye on it, waiting for the person to finish eating and leave so you can sit down. This constant waiting is similar to spinning.
Spinlocks are suitable for scenarios where the lock hold time is very short because they avoid the overhead of thread context switching. In multi-processor systems, when a thread is spinning while waiting for a lock, other processor cores can continue executing other tasks without wasting CPU resources due to thread blocking. For example, in scenarios where multiple threads need to access shared hardware resource registers, the operations on the registers are usually very quick, and using spinlocks allows threads to quickly acquire the lock and complete the operation, avoiding the overhead of thread context switching.
However, spinlocks also have their limitations. If the lock is held for a long time, the thread will spin continuously, consuming CPU resources and leading to decreased system performance. Therefore, when using spinlocks, careful consideration of the actual situation is necessary.
Spinlock APIs include:
- spin_lock_init(x): This macro initializes the spinlock x. A spinlock must be initialized before it can be used. This macro is used for dynamic initialization.
- DEFINE_SPINLOCK(x): This macro declares a spinlock x and initializes it. This macro was first defined in 2.6.11 and did not exist in earlier kernels.
- SPIN_LOCK_UNLOCKED: This macro is used for statically initializing a spinlock.
- spin_is_locked(x): This macro checks whether the spinlock x is held by any execution unit (i.e., locked). If it is, it returns true; otherwise, it returns false.
- spin_unlock_wait(x): This macro waits for the spinlock x to become unheld by any execution unit. If no execution unit holds the spinlock, this macro returns immediately; otherwise, it will loop there until the holder releases the spinlock.
- spin_trylock(lock): This macro attempts to acquire the spinlock lock. If it can acquire the lock immediately, it returns true; otherwise, it returns false without spinning.
- spin_lock(lock): This macro acquires the spinlock lock. If it can acquire the lock immediately, it returns immediately; otherwise, it will spin there until the holder releases the spinlock. In summary, it only returns after acquiring the lock.
- spin_lock_irqsave(lock, flags): This macro acquires the spinlock while saving the value of the flags register to the variable flags and disabling local interrupts.
- spin_lock_irq(lock): This macro is similar to spin_lock_irqsave, but it does not save the value of the flags register.
- spin_lock_bh(lock): This macro disables local soft interrupts while acquiring the spinlock.
- spin_unlock(lock): This macro releases the spinlock lock. It is paired with spin_trylock or spin_lock. If spin_trylock returns false, indicating that the spinlock was not acquired, there is no need to use spin_unlock to release it.
- spin_unlock_irqrestore(lock, flags): This macro releases the spinlock lock while restoring the value of the flags register to the value saved in the variable flags. It is paired with spin_lock_irqsave.
- spin_unlock_irq(lock): This macro releases the spinlock lock while enabling local interrupts. It is paired with spin_lock_irq.
- spin_unlock(lock): This macro releases the spinlock lock. It is paired with spin_trylock or spin_lock. If spin_trylock returns false, indicating that the spinlock was not acquired, there is no need to use spin_unlock to release it.
- spin_unlock_irqrestore(lock, flags): This macro releases the spinlock lock while restoring the value of the flags register to the value saved in the variable flags. It is paired with spin_lock_irqsave.
- spin_unlock_irq(lock): This macro releases the spinlock lock while enabling local interrupts. It is paired with spin_lock_irq.
- spin_unlock_bh(lock): This macro releases the spinlock lock while enabling local soft interrupts. It is paired with spin_lock_bh.
- spin_trylock_irqsave(lock, flags): This macro attempts to acquire the spinlock lock while saving the value of the flags register to the variable flags and disabling local interrupts. If it cannot acquire the lock, it does nothing. Therefore, if it can acquire the lock immediately, it is equivalent to spin_lock_irqsave; if it cannot acquire the lock, it is equivalent to spin_trylock. If this macro acquires the spinlock lock, it must use spin_unlock_irqrestore to release it.
- spin_can_lock(lock): This macro checks whether the spinlock lock can be locked. It is essentially the negation of spin_is_locked. If the lock is not locked, it returns true; otherwise, it returns false. This macro was first defined in 2.6.11 and did not exist in earlier kernels.
There are several versions for acquiring and releasing spinlocks, so it is essential for readers to know which version of the lock acquisition and release macros to use in different situations.
If the protected shared resource is accessed only in process context and soft interrupt context, then when accessing the shared resource in process context, it may be interrupted by a soft interrupt, which may lead to access to the protected shared resource in soft interrupt context. Therefore, in this case, access to the shared resource must be protected using spin_lock_bh and spin_unlock_bh.
Of course, using spin_lock_irq and spin_unlock_irq, as well as spin_lock_irqsave and spin_unlock_irqrestore, is also possible. They disable local hard interrupts, and disabling hard interrupts implicitly also disables soft interrupts. However, using spin_lock_bh and spin_unlock_bh is the most appropriate, as it is faster than the other two.
If the protected shared resource is accessed only in process context and tasklet or timer context, then the same acquisition and release lock macros should be used as in the previous case, because tasklets and timers are implemented using soft interrupts.
If the protected shared resource is accessed only in a tasklet or timer context, then no spinlock protection is needed because the same tasklet or timer can only run on one CPU, even in an SMP environment. In fact, when a tasklet calls tasklet_schedule to mark itself for scheduling, it has already bound that tasklet to the current CPU, so the same tasklet cannot run simultaneously on other CPUs. Similarly, a timer is also bound to the current CPU when it is added to the timer queue using add_timer. Therefore, the same timer cannot run on other CPUs. Of course, it is even less likely for the same tasklet to have two instances running on the same CPU.
If the protected shared resource is accessed in two or more tasklet or timer contexts, then access to the shared resource only needs to be protected using spin_lock and spin_unlock, without needing to use the _bh version, because when a tasklet or timer runs, no other tasklet or timer can run on the current CPU.
If the protected shared resource is accessed in a soft interrupt context (excluding tasklets and timers), then this shared resource needs to be protected using spin_lock and spin_unlock, because the same soft interrupt can run simultaneously on different CPUs.
If the protected shared resource is accessed in two or more soft interrupt contexts, then this shared resource certainly needs to be protected using spin_lock and spin_unlock, as different soft interrupts can run simultaneously on different CPUs.
If the protected shared resource is accessed in both soft interrupt (including tasklets and timers) or process context and hard interrupt context, then during access in soft interrupt or process context, it may be interrupted by a hard interrupt, leading to access to the shared resource in hard interrupt context. Therefore, in process or soft interrupt context, access to the shared resource needs to be protected using spin_lock_irq and spin_unlock_irq.
As for which version to use in interrupt handling, it depends on the situation. If only one interrupt handler accesses the shared resource, then it is sufficient to protect access to the shared resource in the interrupt handler using spin_lock and spin_unlock.
Because during the execution of the interrupt handler, it cannot be interrupted by the same CPU’s soft interrupt or process. However, if different interrupt handlers access the shared resource, then it is necessary to use spin_lock_irq and spin_unlock_irq to protect access to the shared resource in the interrupt handler.
In cases where spin_lock_irq and spin_unlock_irq are used, spin_lock_irqsave and spin_unlock_irqrestore can completely replace them. Which one to use also depends on the situation. If it can be ensured that interrupts are enabled before accessing the shared resource, then using spin_lock_irq is better.
Because it is faster than spin_lock_irqsave, but if you cannot be sure whether interrupts are enabled, then using spin_lock_irqsave and spin_unlock_irqrestore is better, as it will restore the interrupt flag before accessing the shared resource rather than directly enabling interrupts.
Of course, in some cases, it is necessary to disable interrupts while accessing shared resources and enable interrupts after access. In such cases, using spin_lock_irq and spin_unlock_irq is best.
It is essential to remind readers that spin_lock is used to prevent simultaneous access to shared resources by execution units on different CPUs and to prevent asynchronous access to shared resources due to preemption between different process contexts, while disabling interrupts and soft interrupts is to prevent asynchronous access to shared resources by soft interrupts or interrupts on the same CPU.
3.2 Mutexes
A mutex, also known as a mutual exclusion lock, is a synchronization mechanism used to implement mutual access between threads. Its working principle is that when a thread acquires a mutex, other threads attempting to acquire that lock will be blocked until the thread holding the lock releases it. This is akin to a public restroom, where only one person is allowed to use it at a time. When someone enters the restroom and locks the door, others must wait outside until the person inside comes out and unlocks the door.
Unlike spinlocks, mutexes are suitable for scenarios where blocking may take a long time. When a thread cannot acquire the lock, it will be suspended by the operating system, yielding CPU resources, rather than continuously occupying the CPU as a spinlock would. In code segments involving extensive computation or I/O operations, using mutexes can prevent CPU resource wastage. For example, in database operations, a thread may need to occupy a database connection for an extended period to execute complex queries or transaction operations. In this case, using a mutex to protect the database connection resource allows other threads to be blocked when they cannot acquire the lock until the current thread completes the database operation and releases the lock, effectively managing resources and improving overall system performance.
3.3 Read-Write Locks
Read-write locks are a special synchronization mechanism that allows multiple threads to perform read operations simultaneously but only permits one thread to perform write operations. When a thread is performing a write operation, other threads, whether performing read or write operations, will be blocked until the write operation is completed and the lock is released. This is like a popular book in a library, where many people can read the book simultaneously, but if someone wants to modify the book (such as adding annotations or correcting errors), they must first have exclusive access to the book, preventing others from reading or modifying it until the modification is complete.
The advantage of read-write locks is that they can significantly improve concurrent performance, especially in scenarios where reads are frequent and writes are infrequent. In an online shopping system, displaying product information (read operations) occurs very frequently, while updating product information (write operations) is relatively rare. Using read-write locks allows multiple users to read product information simultaneously, while when a merchant needs to update product information, they only need to acquire the write lock, ensuring the atomicity and data consistency of the write operation, thus greatly enhancing the system’s concurrent processing capability and improving user experience.
APIs related to read-write semaphores include:
- DECLARE_RWSEM(name): This macro declares a read-write semaphore name and initializes it.
- void init_rwsem(struct rw_semaphore *sem): This function initializes the read-write semaphore sem.
- void down_read(struct rw_semaphore *sem): Readers call this function to obtain the read-write semaphore sem. This function will cause the caller to sleep, so it can only be used in process context.
- int down_read_trylock(struct rw_semaphore *sem): This function is similar to down_read, but it will not cause the caller to sleep. It attempts to obtain the read-write semaphore sem; if it can be obtained immediately, it returns 1; otherwise, it indicates that it cannot be obtained immediately and returns 0. Therefore, it can also be used in interrupt context.
- void down_write(struct rw_semaphore *sem): Writers use this function to obtain the read-write semaphore sem, which will also cause the caller to sleep, so it can only be used in process context.
- int down_write_trylock(struct rw_semaphore *sem): This function is similar to down_write, but it will not cause the caller to sleep. It attempts to obtain the read-write semaphore; if it can be obtained immediately, it acquires it and returns 1; otherwise, it indicates that it cannot be obtained immediately and returns 0. It can be used in interrupt context.
- void up_read(struct rw_semaphore *sem): Readers use this function to release the read-write semaphore sem. It is paired with down_read or down_read_trylock. If down_read_trylock returns 0, there is no need to call up_read to release the read-write semaphore, as it was never acquired.
- void up_write(struct rw_semaphore *sem): Writers call this function to release the semaphore sem. It is paired with down_write or down_write_trylock. If down_write_trylock returns 0, there is no need to call up_write, as it indicates that the write semaphore was not acquired.
- void downgrade_write(struct rw_semaphore *sem): This function is used to downgrade a writer to a reader, which is sometimes necessary. Since writers are exclusive, while a writer holds the read-write semaphore, any readers or writers will be unable to access the shared resource protected by the read-write semaphore. For those writers that do not need write access under the current conditions, downgrading to a reader allows waiting readers to access immediately, thus increasing concurrency and improving efficiency. Read-write semaphores are suitable for use in scenarios with more reads than writes; in the Linux kernel, access to the process’s memory image description structure is protected using read-write semaphores.
In Linux, each process is described by a structure of type task_t or struct task_struct, and the field mm of type struct mm_struct describes the process’s memory image. In particular, the mmap field of the mm_struct structure maintains the entire list of memory blocks for the process, which will be traversed or modified extensively during the process’s lifetime. The mmap field maintains the entire list of memory blocks for the process, which will be traversed or modified extensively during the process’s lifetime.
Therefore, the mm_struct structure has a field mmap_sem to protect access to mmap, and mmap_sem is a read-write semaphore. In the proc filesystem, there are many interfaces for viewing the memory usage of processes, and these interfaces can be used to view the memory usage of a specific process. Commands like free, ps, and top obtain memory usage information through proc, and the proc interface uses down_read and up_read to read the mmap information of processes.
When a process dynamically allocates or frees memory, it needs to modify mmap to reflect the memory image after allocation or release. Therefore, dynamic memory allocation or release operations need to acquire the read-write semaphore mmap_sem as a writer to update mmap. System calls brk and munmap use down_write and up_write to protect access to mmap.
3.4 Semaphores
A semaphore is an integer value that can be used to control access to shared resources. Semaphores primarily serve two purposes: one is to implement mutual exclusion, and the other is to control the number of concurrent accesses. The semaphore maintains a counter internally; when a thread requests access to a shared resource, it attempts to acquire the semaphore. If the counter is greater than 0, the thread can acquire the semaphore and continue executing, while the counter decreases by one; if the counter is 0, the thread will be blocked until another thread releases the semaphore, increasing the counter. This is like a parking lot, where there are a certain number of parking spaces (the initial value of the semaphore). Each car entering the parking lot (the thread requesting the resource) occupies a parking space, decreasing the number of available spaces. If the parking lot is full (the counter is 0), new cars can only wait outside until other cars leave the parking lot (threads release resources), increasing the number of available spaces, allowing waiting cars to enter.
Semaphores are very useful in limiting the number of threads accessing file resources. Suppose a system allows only 5 threads to read and write to a file simultaneously; we can create a semaphore with an initial value of 5. Each thread will first acquire the semaphore before accessing the file; if successful, it can access the file while the semaphore’s counter decreases by one. When the thread completes file access, it releases the semaphore, increasing the counter. This effectively controls the number of threads accessing the file, avoiding excessive competition and conflicts for resources.
Semaphore APIs include:
- DECLARE_MUTEX(name): This macro declares a semaphore name and initializes its value to 0, effectively declaring a mutex.
- DECLARE_MUTEX_LOCKED(name): This macro declares a mutex name but sets its initial value to 0, meaning the lock is in a locked state upon creation. Therefore, for this type of lock, it is generally released before being acquired.
- void sema_init(struct semaphore *sem, int val): This function initializes the semaphore’s initial value, setting the value of semaphore sem to val.
- void init_MUTEX(struct semaphore *sem): This function initializes a mutex, setting the value of semaphore sem to 1.
- void init_MUTEX_LOCKED(struct semaphore *sem): This function also initializes a mutex but sets the value of semaphore sem to 0, meaning it is in a locked state from the start.
- void down(struct semaphore *sem): This function is used to acquire the semaphore sem, which will cause the caller to sleep, so it cannot be used in interrupt context (including IRQ context and softirq context). This function will decrease the value of sem by 1; if the value of semaphore sem is non-negative, it returns directly; otherwise, the caller will be suspended until another task releases the semaphore to continue running.
- int down_interruptible(struct semaphore *sem): This function is similar to down, but down cannot be interrupted by signals, while down_interruptible can be interrupted by signals. Therefore, this function has a return value to distinguish whether it returned normally or was interrupted by a signal. If it returns 0, it indicates that the semaphore was acquired normally; if interrupted by a signal, it returns -EINTR.
- int down_trylock(struct semaphore *sem): This function attempts to acquire the semaphore sem. If it can be acquired immediately, it acquires the semaphore and returns 0; otherwise, it indicates that it cannot acquire the semaphore, returning a non-zero value. Therefore, it will not cause the caller to sleep and can be used in interrupt context.
- void up(struct semaphore *sem): This function releases the semaphore sem, increasing its value by 1. If the value of sem is non-positive, it indicates that there are tasks waiting for the semaphore, thus waking up those waiting.
In most cases, semaphores are used as mutexes. Below is an example illustrating the use of semaphores in a console driver system.
In the kernel source tree’s kernel/printk.c, the macro DECLARE_MUTEX is used to declare a mutex console_sem, which is used to protect the console driver list console_drivers and synchronize access to the entire console driver system.
Functions acquire_console_sem are defined to acquire the mutex console_sem, and release_console_sem to release the mutex console_sem. The function try_acquire_console_sem attempts to acquire the mutex console_sem. These three functions are essentially simple wrappers around the functions down, up, and down_trylock.
When accessing the console_drivers driver list, the acquire_console_sem function must be used to protect the console_drivers list. After accessing the list, the release_console_sem function is called to release the semaphore console_sem.
Functions console_unblank, console_device, console_stop, console_start, register_console, and unregister_console all need to access console_drivers, so they all use the functions acquire_console_sem and release_console_sem to protect console_drivers.
3.5 Atomic Operations
Atomic operations refer to operations that cannot be interrupted, meaning their execution is a complete, indivisible unit that will not be interrupted by other tasks or events. In multi-threaded programming, atomic operations can ensure that access to shared resources is thread-safe, avoiding the occurrence of race conditions. For example, atomic operations play a crucial role in implementing resource counting and reference counting.
Suppose there is a shared resource, and multiple threads may increment or decrement its reference count. If these operations are not atomic, race conditions may occur, leading to incorrect reference counts. However, using atomic operations ensures that each modification to the reference count is atomic and not interfered with by other threads, thus guaranteeing the accuracy and consistency of resource counting. In C, atomic operations can be implemented using the atomic library, such as the atomic_fetch_add function, which can atomically add to a variable. The atomic type is defined as follows:
typedef struct {
volatile int counter;
} atomic_t;The volatile modifier tells gcc not to optimize access to this type of data, ensuring that all accesses are to memory rather than registers.Atomic operation APIs include:
- atomic_read(atomic_t * v): This function performs an atomic read operation on an atomic type variable, returning the value of the atomic variable v.
- atomic_set(atomic_t * v, int i): This function sets the value of the atomic type variable v to i.
- void atomic_add(int i, atomic_t *v): This function adds value i to the atomic type variable v.
- atomic_sub(int i, atomic_t *v): This function subtracts i from the atomic type variable v.
- int atomic_sub_and_test(int i, atomic_t *v): This function subtracts i from the atomic type variable v and checks whether the result is 0. If it is, it returns true; otherwise, it returns false.
- void atomic_inc(atomic_t *v): This function atomically increments the atomic type variable v by 1.
- void atomic_dec(atomic_t *v): This function atomically decrements the atomic type variable v by 1.
- int atomic_dec_and_test(atomic_t *v): This function atomically decrements the atomic type variable v by 1 and checks whether the result is 0. If it is, it returns true; otherwise, it returns false.
- int atomic_inc_and_test(atomic_t *v): This function atomically increments the atomic type variable v by 1 and checks whether the result is 0. If it is, it returns true; otherwise, it returns false.
- int atomic_add_negative(int i, atomic_t *v): This function atomically adds i to the atomic type variable v and checks whether the result is negative. If it is, it returns true; otherwise, it returns false.
- int atomic_add_return(int i, atomic_t *v): This function atomically adds i to the atomic type variable v and returns a pointer to v.
- int atomic_sub_return(int i, atomic_t *v): This function subtracts i from the atomic type variable v and returns a pointer to v.
- int atomic_inc_return(atomic_t * v): This function atomically increments the atomic type variable v by 1 and returns a pointer to v.
- int atomic_dec_return(atomic_t * v): This function atomically decrements the atomic type variable v by 1 and returns a pointer to v.
Atomic operations are commonly used to implement reference counting for resources. In the TCP/IP protocol stack’s IP fragment processing, reference counting is used. The fragment queue structure struct ipq describes an IP fragment, and the field refcnt is the reference counter, which is of type atomic_t. When creating an IP fragment (in the function ip_frag_create), the atomic_set function is used to set it to 1. When the IP fragment is referenced, the atomic_inc function is used to increment the reference count.
When the IP fragment is no longer needed, the function ipq_put is used to release it. ipq_put uses the atomic_dec_and_test function to decrement the reference count and check whether it is 0. If it is, the IP fragment is released. The function ipq_kill removes the IP fragment from the ipq queue and decrements the reference count of the deleted IP fragment (using the atomic_dec function).
4. Choosing and Applying Synchronization Mechanisms
In practical applications within the Linux kernel, choosing the appropriate synchronization mechanism is crucial, much like selecting the right mode of transportation under different traffic conditions. Different synchronization mechanisms are suitable for different scenarios, and we need to make decisions based on specific needs and conditions.
Spinlocks, due to their spinning wait characteristics, are suitable for scenarios where the critical section execution time is very short and competition is not intense. In multi-core processor systems, when the access time to shared resources by threads is extremely short, such as quick read and write operations on hardware registers, using spinlocks can avoid the overhead of thread context switching and improve system response speed. Since threads occupy CPU resources while spinning, if the critical section execution time is short, they can quickly acquire the lock and complete the operation. Compared to the overhead of thread context switching, this spinning wait cost is acceptable. However, if the critical section execution time is long, threads spinning for a long time will waste a significant amount of CPU resources, leading to decreased system performance. Therefore, spinlocks are not suitable for scenarios where locks are held for extended periods.
Mutexes, on the other hand, are suitable for scenarios where the critical section may block for a long time. When extensive computation, I/O operations, or waiting for external resources are involved, using mutexes allows threads that cannot acquire the lock to enter a blocked state, yielding CPU resources to other threads and avoiding CPU resource wastage. In a network server, when a thread needs to read a large amount of data from the network or write data to a database, these operations typically take a long time. In this case, using mutexes to protect the relevant resources can effectively manage the execution order of threads and ensure system stability. In such situations, the overhead of thread context switching is relatively small, and allowing threads to block while waiting can prevent CPU resources from being ineffectively occupied, improving overall system efficiency.
Read-write locks are suitable for scenarios where reads are frequent and writes are infrequent. In a real-time monitoring system, many threads may need to frequently read monitoring data, while only a few threads will occasionally update this data. Using read-write locks allows multiple read threads to acquire read locks simultaneously and read data concurrently, while write threads can acquire write locks when they need to update data, ensuring the atomicity and data consistency of write operations. This greatly enhances the system’s concurrent performance.
Semaphores are commonly used to control the number of concurrent accesses to shared resources. In a file server, to avoid too many threads accessing the same file simultaneously, leading to excessive load on the file system, we can use semaphores to limit the number of threads accessing the file at the same time. By setting the initial value of the semaphore to the maximum number of threads allowed to access simultaneously, each thread will first acquire the semaphore before accessing the file, and after completing access, it will release the semaphore. This effectively controls access to file resources, ensuring system stability.
5. Practical Case Analysis
5.1 TCP Connection Management
In the Linux kernel’s network protocol stack, synchronization mechanisms play a critical role. Taking TCP protocol connection management as an example, when multiple threads simultaneously handle TCP connection establishment, disconnection, and data transmission, synchronization mechanisms are needed to ensure data consistency and operational correctness. When processing TCP connection requests, multiple threads may receive connection requests simultaneously, requiring the use of spinlocks to quickly operate on the shared connection queue, ensuring that each connection request is processed correctly and avoiding duplicate processing or data confusion.
Since connection request processing is usually very fast, using spinlocks can avoid the overhead of thread context switching and improve system performance. However, during TCP data transmission, due to factors such as network latency, the data transmission may take a longer time. In this case, mutexes are used to protect shared resources such as data buffers, ensuring correct reading and writing of data. Because during data transmission, threads may need to wait for network responses, using mutexes allows threads to enter a blocked state while waiting, yielding CPU resources and improving overall system efficiency.
We will create a simple TCP connection request handler that uses a spinlock to protect the shared connection queue.Code Implementation Example:
#include <linux/spinlock.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#define MAX_CONNECTIONS 10
struct connection {
int conn_id;
};
struct connection connection_queue[MAX_CONNECTIONS];
int queue_count = 0;
spinlock_t conn_lock;
void handle_connection_request(int conn_id) {
spin_lock(&conn_lock);
if (queue_count < MAX_CONNECTIONS) {
connection_queue[queue_count].conn_id = conn_id;
queue_count++;
printk(KERN_INFO "Handled connection request: %d\n", conn_id);
} else {
printk(KERN_WARNING "Connection queue is full!\n");
}
spin_unlock(&conn_lock);
}
static int __init my_module_init(void) {
spin_lock_init(&conn_lock);
return 0;
}
static void __exit my_module_exit(void) {
// Cleanup code here
}
module_init(my_module_init);
module_exit(my_module_exit);
MODULE_LICENSE("GPL");- Using spinlock_t type spinlock to protect access to the shared resource (connection queue).
- The handle_connection_request function simulates handling TCP connection requests. It acquires the spinlock before modifying the shared queue and releases it afterward.
5.2 File Read and Write Operations
In file systems, synchronization mechanisms are also indispensable. Taking file read and write operations as an example, when multiple processes simultaneously read and write to a file, appropriate synchronization mechanisms are needed. For file read operations, since reading does not modify the file content, multiple processes can read simultaneously. In this case, the read lock of a read-write lock can be used to improve concurrent performance. However, when a process needs to write to the file, to ensure data consistency, it must acquire the write lock of the read-write lock, exclusively occupying the file for writing. In managing file system metadata, such as creating, deleting, and traversing directories, these operations involve modifying critical data structures of the file system, requiring atomicity and consistency, and typically use mutexes to protect the relevant operations. Because these operations may involve complex file system operations and disk I/O, using mutexes can effectively manage the execution order of threads, avoiding data inconsistency.
Next is a simplified example of file read and write operations, using mutexes and read-write locks to ensure thread safety. Code implementation example:
#include <linux/fs.h>
#include <linux/mutex.h>
#include <linux/rwsem.h>
#include <linux/uaccess.h>
struct rw_semaphore file_rwsem;
char file_buffer[1024];
void read_file(char *buffer, size_t size) {
down_read(&file_rwsem); // Acquire read lock
memcpy(buffer, file_buffer, size);
up_read(&file_rwsem); // Release read lock
}
void write_file(const char *buffer, size_t size) {
down_write(&file_rwsem); // Acquire write lock
memcpy(file_buffer, buffer, size);
up_write(&file_rwsem); // Release write lock
}
static int __init my_file_module_init(void) {
init_rwsem(&file_rwsem);
return 0;
}
static void __exit my_file_module_exit(void) {
// Cleanup code here
}
module_init(my_file_module_init);
module_exit(my_file_module_exit);
MODULE_LICENSE("GPL");- Using rw_semaphore type read-write lock to control concurrent access to the file buffer.
- When reading, the read lock is obtained by calling down_read, allowing multiple threads to read simultaneously without blocking; when writing, the exclusive write lock is obtained by calling down_write to ensure data consistency.
Through these two simple examples, we can see how different synchronization mechanisms are applied in the Linux kernel to manage resource contention, improving performance and data consistency.