
Introduction
The AI chips needed for the vast IoT market consist of three parts: cloud service provider chips, edge intelligence chips, and endpoint chips. This article focuses on the selection of edge intelligence chips, the key factors for selection, and application cases, as edge intelligence chips are the “backbone process” that empowers enterprise applications. They are the core component that connects the three types of AI chips. The key factors for selecting edge intelligence chips include computing power, interface capability, programmability, and CPU architecture. Among these, end customers are most concerned with “visible and tangible” aspects such as screen drive capability, display pixels, and computation time.
(1) Strong Computing Power
The computing power of edge intelligence chips should be stronger than that of endpoint computing. They typically solve problems independently. For example, their performance is usually 1-2 orders of magnitude stronger than the AI chip processing capabilities based on certain application endpoints like facial recognition in neighborhoods or voice recognition in smart speakers.
(2) Interface Capability
Edge intelligence chips emphasize the availability of information, such as the ability to support multiple video and audio inputs simultaneously, which creates a significant demand for the number of interfaces like MIPI.
(3) Programmability
Edge intelligence chips are typically designed for industrial users who need AI empowerment. In other words, AI must be combined with user application scenarios and programmed according to the different needs of various industrial users. A good programmable architecture is key to solving problems. In industrial applications, edge intelligence chips must empower AI according to the needs of industrial clients through algorithms and hardware, which is a core feature of edge intelligence chips.
(4) CPU Architecture
The CPU architecture is described by three sets of data: the types and numbers of “cores” including CPU, GPU, NPU, etc., as well as ARM cores or RISC-V cores; the main frequency, embedded memory, RAM/FLASH, eMMC, and communication; and peripheral driving capabilities such as multi-screen display, WiFi 6, and 5G communication.
This article focuses on high-end GPU edge intelligence chips and mid-range low-power MPU, providing selection guidance for engineers and product managers. One is NVIDIA’s Jeston AGX Orin, and the other is Beijing Junzheng’s X2000. Practical advice and case studies are given based on evaluations of computing power, interfaces, programmability, and CPU architecture parameters. Finally, three Turn-Key solutions are introduced for terminal equipment manufacturers and solution providers, equipped with algorithms, SDKs, and AI learning capabilities.
01
Edge Intelligence Chip Architecture: NVIDIA Jeston AGX Orin Platform Case
The JESTON AGX Orin released by NVIDIA is an edge AI computing platform-level chip, although it is not as well-known as NVIDIA’s GPUs. However, JESTON inherits the Ampere architecture’s GPU and ARM Cortex-A78. In edge intelligence chips, it can perform both inference and training. As an edge intelligence chip product, it has a processing performance of 200 Tops (INT8). We take JESTON AGX Orin as an example to explore its internal chip architecture.
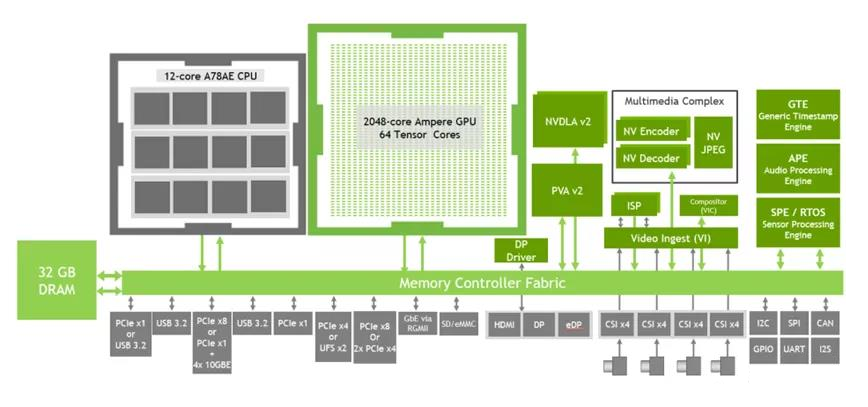
Figure: The computing part of the chip mainly includes: CPU, GPU, DSA (NVDLA+PVA)
CPU: JESTON has three sets of 4-core A78, with a frequency of up to 2GHz. This means that this chip has a 12-core A78 processor inside, and the three sets of A78 are symmetrical, mainly aimed at computing services. In some scalar computations, the multi-core A78’s computing power is very strong. This chip is built on a 7nm process, with power consumption of 15W, 30W, and 45W respectively.
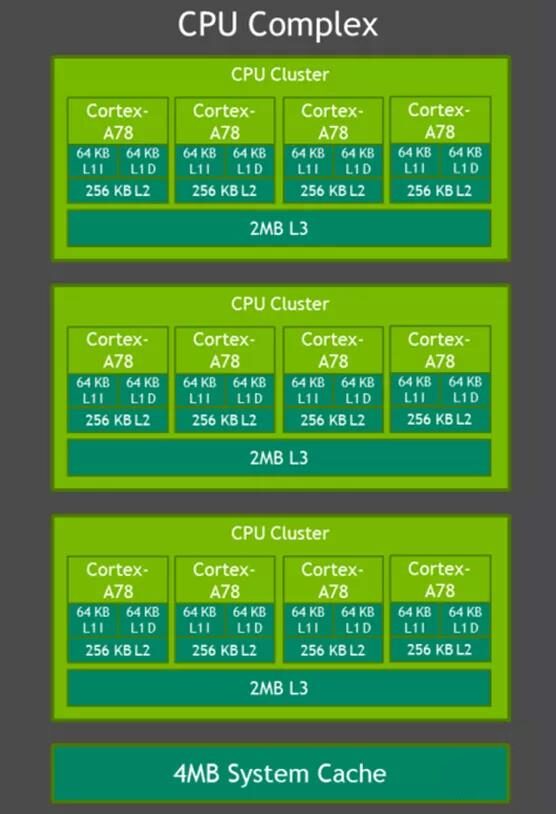
Figure: JESTON AGX Orin CPU balanced ratio
GPU: The GPU uses NVIDIA’s latest Ampere architecture, with 2048 CUDA cores and 64 Tensor cores. All of these are programmable and can provide 200 TOPs of computing power. The Ampere architecture is the latest generation of GPU architecture, with the previous generations being Kepler, Maxwell, Pascal, Volta, etc. Unlike other edge AI chips, the Ampere GPU can support both inference and training. Importantly, this AI chip can be programmed using CUDA, and programmability is a core requirement for edge AI chips.
DSA: As an AI acceleration unit, JESTON also has 2 NVDLA hard cores and a VISION accelerator PVA. NVDLA is mainly used for inference. The core is still a large matrix convolution operation. PVA uses VPU architecture and employs VLIW architecture, which has good parallelism. The VIEW architecture design simplifies the hardware structure. The large width execution of VLIW does not sacrifice performance and frequency but delegates the problem to the software.
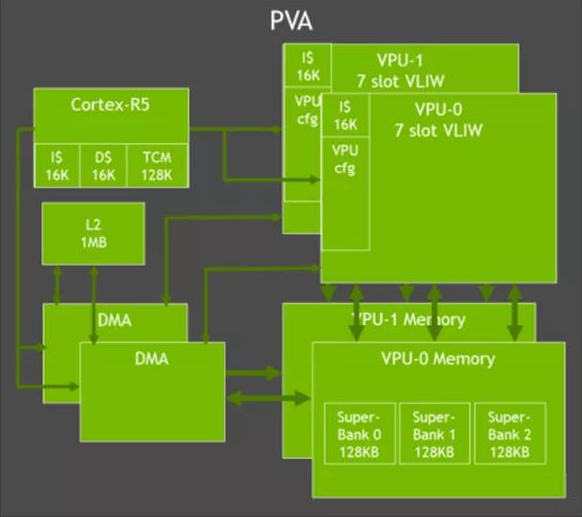
Figure: VISION accelerator PVA
I/O Interface Resources: Edge intelligence needs to “see in all directions and hear in all directions,” requiring rich I/O. Among these, the most important interface is MIPI, which is the eyes of edge AI chips (used to connect cameras). It supports 6 cameras and 16 sets of MIPI interfaces. It also has USB interfaces, which can support some USB cameras. It can also support PCIe, RC, and EP. This means it can serve as an accelerator card plugged into other hosts or as a main device plugged into other accelerator cards. Additionally, in terms of networking, it supports 4 channels of 10G ports for high-speed interconnection. If needed, it can also achieve high-speed network transmission or interconnection between several JESTON AGX.
02
Edge Intelligence Chip Architecture: Key Selection Factors and Cases for Beijing Junzheng X2000 Platform
The AI capability keywords for X2000 include: computing power, memory, low power consumption, AI platform, and a new engine for endpoint AI empowerment.
X2000 is a new generation SoC product launched by Junzheng for the IoT market. This product marks the debut of XBurst 2, featuring a dual XBurst 2 + XBurst 0 three-core heterogeneous layout, a gigabit network port compliant with IEEE1588-2002 standards, three camera access capabilities, and the inheritance and development of Junzheng’s low power consumption technology. As an endpoint AI platform, X2000’s capabilities are comprehensive: it has hard capabilities embedded in the chip, such as the computing power, instruction set, and memory management of XBurst 2, as well as Junzheng’s self-developed operating system, various IoT application development support suites, and the AI open platform MAGIK. The AI capabilities of X2000, built on its capabilities in image, video, and interconnectivity, will undoubtedly make it a main control chip in the era of intelligent interconnectivity, capable of being deployed independently as a complete intelligent unit or collaborating with multiple X2000s to form a larger-scale intelligent unit or distributed intelligent system.
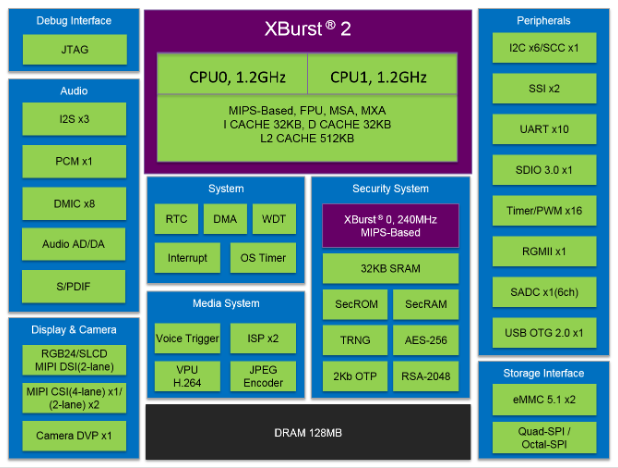
Figure: X2000 architecture diagram and I/O layout
X2000’s AI Capability Performance
X2000 includes “hard equipment” such as computing power, storage, and low power consumption embedded in the chip, and “soft equipment” such as training, optimization, and deployment on the deep neural network open platform MAGIK. These “equipments” provide the possibility for users to elevate the application of Junzheng chips from IoT to AIoT. X2000 integrates 128MBytes LPDDR3 (X2000E pin compatible, with 256Mbytes LPDDR2 integrated internally).
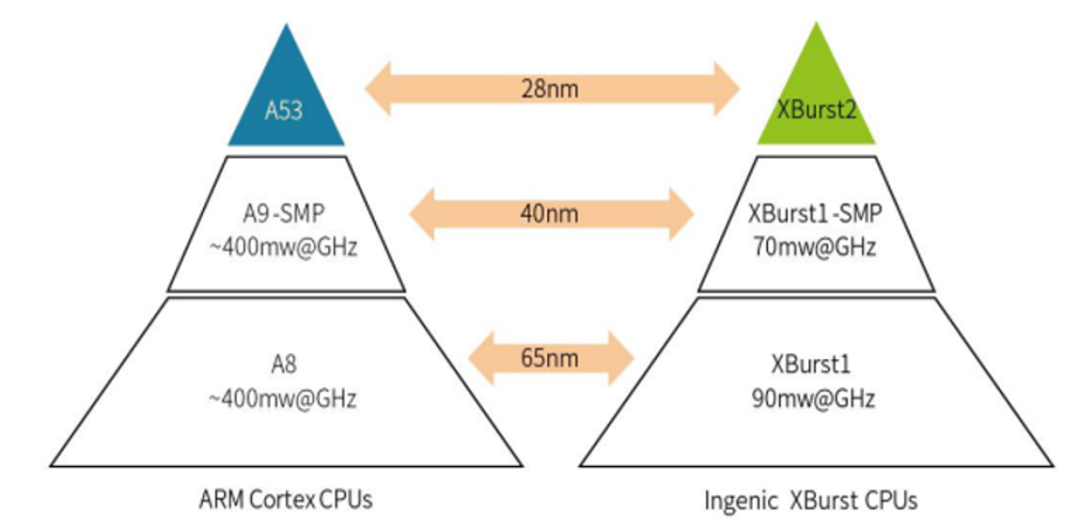
Figure: Comparison of XBurst 2 core with A53 core performance
Empowering Endpoint AI is an Important Positioning for X2000
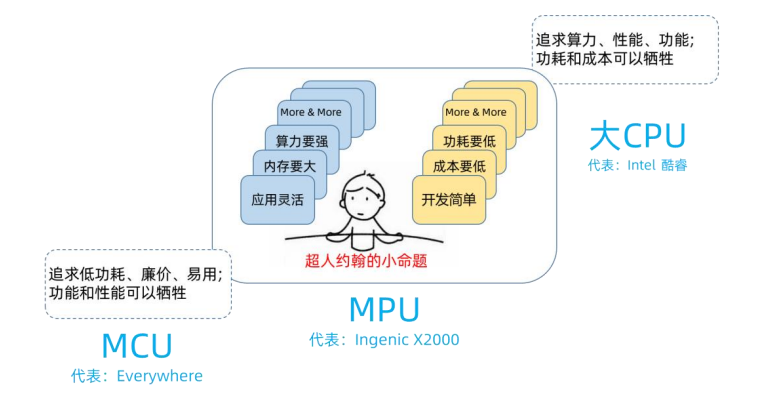
X2000 belongs to the MPU category. The following diagram illustrates the application division between MPU and large CPU, MCU.
The three mission values of MPU deploying endpoint AI include:
1. Faster and closer interaction methods, as models execute locally, resulting in low latency;
2. More autonomous service capabilities, as services can still be provided without a network;
3. Better privacy protection, as data collection and processing are done locally, eliminating the need to upload data.
To achieve endpoint AI deployment, models must strike a balance between performance and cost, which presents three challenges:
1. Limited endpoint computing power and energy restrict the complexity of models, necessitating low power consumption;
2. There must be dedicated tools for training and optimizing models for endpoint hardware platforms;
3. Limited endpoint memory restricts the size of models that can be run.
Empowering endpoint AI is the most important application positioning for X2000:
1. It can deploy endpoint AI, also known as embedded AI.
2. The Junzheng MAGIK platform provides training and optimization capabilities for models on X2000;
3. On-chip integration of larger capacity memory;
4. The MAGIK platform fully considers these boundary conditions;
5. Extremely low power consumption levels, with the entire chip’s typical power consumption < 400mW;
X2000’s Computing Power
This computing power is reflected in the dual XBurst 2 + XBurst 0 three-core heterogeneous CPU, MIPS instruction set, and SIMD extended instruction set.
1. Main CPU—dual XBurst 2 cores, with a rated operating frequency of 1.2GHz.
2. Dual logical cores based on simultaneous multithreading technology (Simultaneous Multi-Threading) have stronger synergy and higher energy efficiency compared to dual physical cores.
3. Each logical core can issue 2 instructions per cycle, completing lightweight out-of-order execution.
4. L1 Instruction Cache and Data Cache are both 32KB.
5. Floating Point Unit and Programmable Memory Management Unit.
6. L2 Cache is 512KB.
7. Advanced energy consumption management, hardware-level idle hardware module clock shutdown technology;
8. Special third core—XBurst 0 core rated operating frequency of 240MHz; built-in TCSM (Tightly Coupled Sharing Memory) of 32KB, which the main CPU and DMA can directly access.
XBurst 2’s SIMD Extended Instruction Set
1. XBurst 2 is based on the 32-bit MIPS32 ISA R5 and SIMD extended instruction set;
2. MIPS SIMD instruction set architecture: MSA128;
3. Ingenic 128bit SIMD instruction set: MXA128;
4. Fully supports vector computing;
5. Data types can be integer or floating point;
6. Can accelerate audio and video signal processing, supporting speech recognition, facial recognition, human/object detection, and other deep learning intelligent applications;
Deep Neural Network Open Platform MAGIK
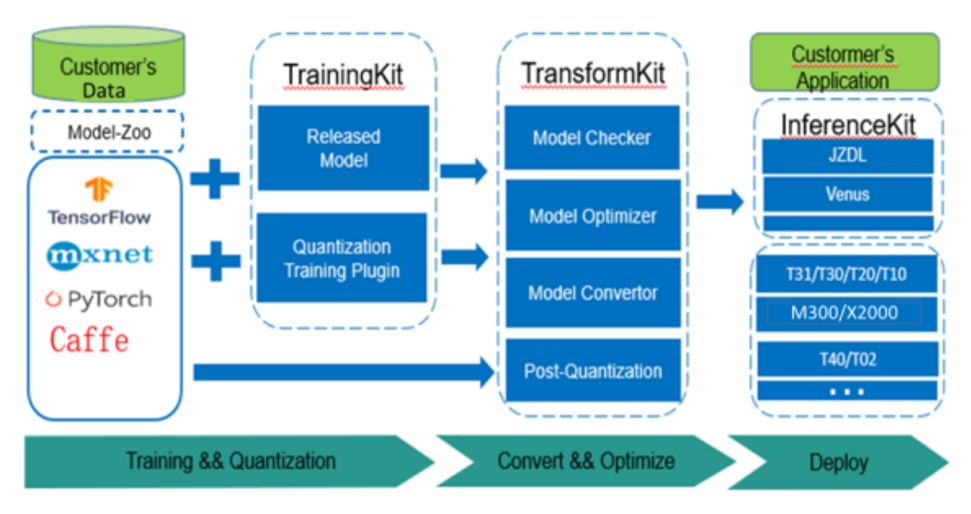
Figure: MAGIK architecture
MAGIK is Beijing Junzheng’s deep learning framework, providing a “soft” environment for model quantization, model conversion, and model deployment on X2000.
With MAGIK’s support, deploying AI applications on X2000 requires three steps: model quantization training, model conversion, and model deployment.
Model Quantization Training
1. Different model construction conditions for users can adopt different model quantization training strategies;
2. Users can train using Junzheng’s developed models provided by MAGIK’s internal ReleaseModel, combined with their own data to obtain 4-8bit quantized models;
3. Users can train using commonly used models provided by Model Zoo, combined with their own data to obtain 4-8bit quantized models;
4. Users can train using TensorFlow, MXNet, PyTorch, Caffe, etc., to obtain Float or 4-8bit quantized models;
5. Users can also use already mature models without quantization training and directly proceed to model conversion (if optimal system performance is not pursued).
Model conversion consists of detection, transformation, and optimization subsets
① Model Checker checks whether the model is suitable for the hardware platform and whether the required operators are in MAGIK’s operator library;
② Model Converter transforms model files from different training frameworks into MAGIK models;
③ Model Optimizer deeply optimizes the model according to the characteristics of the hardware platform.
Model deployment in MAGIK is suitable for the underlying inference firmware library of X2000, which is JZDL.
Model Deployment on X2000
AI inference is the process of running data through a model to obtain predictions (classification or regression). Due to fine memory management and data structure design, memory usage is extremely low, with the entire inference suite requiring only 393KB. To support users in deploying AI in systems based on X2000, MAGIK includes the inference suite JZDL, which has the following technical features: compatibility with X2000’s dedicated inference firmware library; optimization based on XBurst 2’s SIMD extended instruction set and handwritten assembly for deep optimization, fully leveraging XBurst 2’s performance.
Model Algorithm Technical Support
1. Supports various operators such as conventional convolution, depthwise convolution, pooling, activation, fully connected, squeeze and excitation, concat, split, etc.;
2. Supports multi-input and branching structure neural networks;
3. Supports Float full precision forward inference and 8bit/4bit quantized forward inference;
4. Detection classes: human detection, face detection, pet detection, live detection, crying detection, vehicle detection;
5. Recognition classes: face recognition, text recognition, license plate recognition.

Figure: Main technical specifications of X2000
Junzheng X2000 Smart Lock + Electronic Cat Eye Doorbell Single Chip Solution
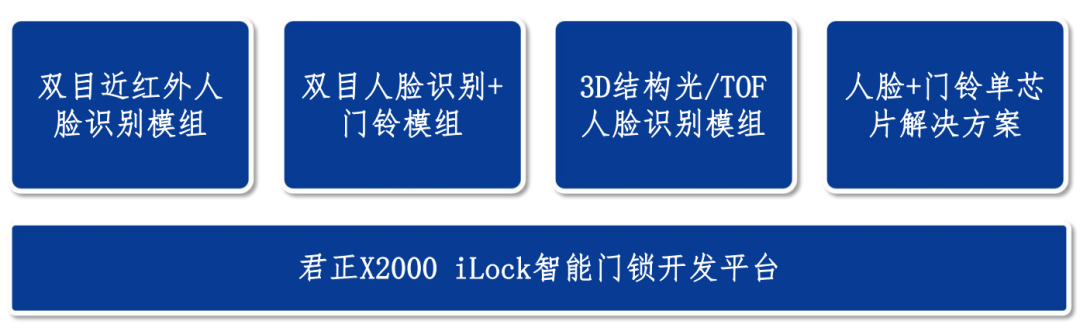
Figure: Smart cat eye lock solution block diagram

Binocular Near-Infrared Face Recognition Lock Solution
View solution details >>
Low Power Consumption, Fast Response Face Recognition Access Control Solution
View solution details >>
Junzheng Open Source Display Control Solution, Successful Application Cases with TOP Clients
Junzheng X2000 is applied in industrial equipment display and control motherboards, home appliances, and smart home control panels, with high cost-performance applications in instruments, production equipment, elevators, electric two-wheeled vehicles, refrigerators, kitchen appliances, etc. Due to its MPU characteristics, it can completely replace the original MCU, achieving a single X2000 to handle display and control for an entire device. At the same time, Junzheng provides open source software and algorithm library support and other turn-key solutions.

Figure: Display control solution application
Junzheng Open Source Software Support
1. Lower-level machine transceiver and communication codes
a) Applied in air conditioning panels, kitchen appliances, and other home appliance panel projects.
b) Mature code, stable functionality.
2. Framework: MVC software architecture
a) A standard application software architecture that decouples customer business logic, facilitating rapid productization.
b) Modular software structure design that meets software engineering standards, ensuring strong reliability.
X2000 Display Control Solution Technical Specifications
1. Low power consumption chip: self-controlled IP, fully optimized power consumption design: sleep state 2.2mW;
2. Complete platform: Each panel product has a targeted software framework, facilitating rapid productization.
a) Supports QT/AWTK.
b) Supports Linux kernel 4.4/kernel 5.10.
3. Layer acceleration, built-in DPU
a) Supports rotation functions 90/180/270.
b) Supports up to four layers of GUI, video, etc.
4. Multimedia functions
a) Built-in codec, supports voice playback.
b) Built-in VPU codec, supports video playback, can support 720P@60.
5. Supports networking functions: supports network protocols, can support Wi-Fi, Bluetooth, etc.
6. Strong computing power
a) Can support offline/online voice control.
b) Chip computing power can support light intelligent face detection.
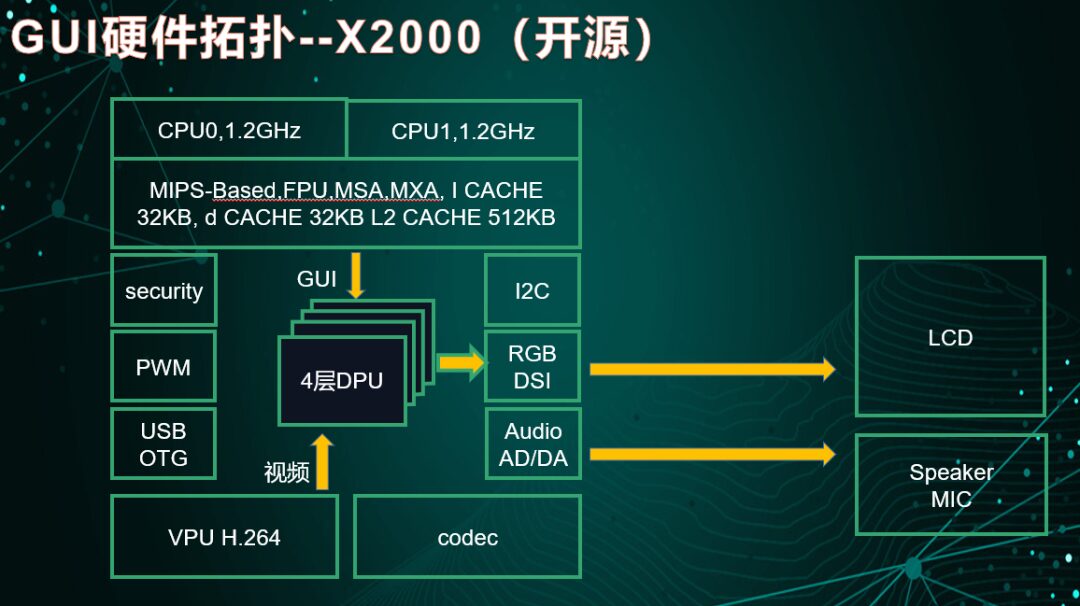
Figure: Display control hardware layout
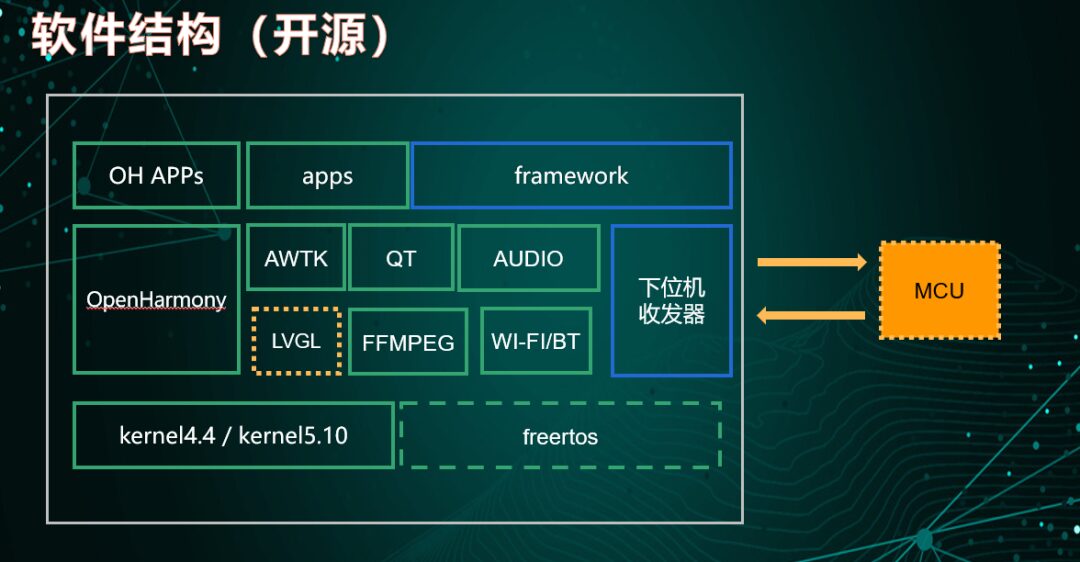
Figure: Display control open source software support

Smart Home Control Tablet Solution with ID Login Voice Broadcast Support
View solution details >>
Cloud Thermal Printer: A Typical Case of X2000 Multi-Core Heterogeneous Cross-Border Applications

Figure: Cloud thermal printer solution application
1. Print head control functions, including motor drive, heating control, overheating detection and control, paper shortage and paper jam detection;
2. Fastest printing speed of 123mm/S;
3. Operating system and software: Linux 4.4, large and small core cross-border application development platform and driver software open source;
4. Interconnectivity: Wi-Fi, Bluetooth, Ethernet, USB, serial port;
5. Supports Wi-Fi network configuration, OTA remote upgrades;
6. Inputs: keyboard, touchscreen, camera;
7. Outputs: LCD, voice;
8. Standard support: supports IPP (Internet Printing Protocol);
9. Supports CUPS (Common UNIX Printing System);
10. Supports QR code scanning and generation, forming a scanning and printing integrated solution;
11. Decoding capability: supports decompressing PDF and JPG formats, cloud and endpoint cooperation to reduce network service burden.
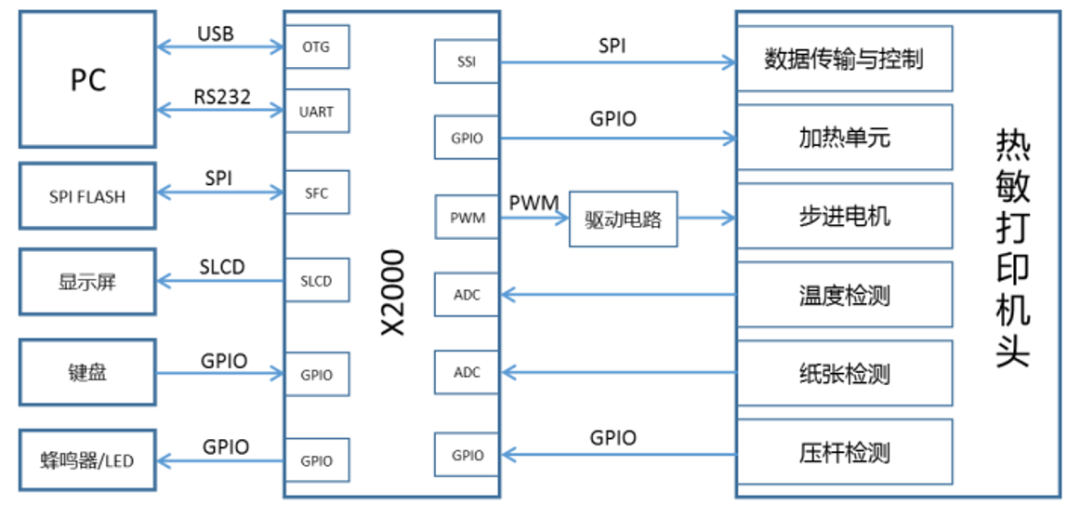
Division of Labor Between Large and Small Cores in the Cloud Thermal Printer Solution
Large core tasks:
1. Responsible for managing system software and hardware resources;
2. Responsible for running Linux 4.4;
3. Responsible for receiving print tasks and QR code scanning tasks;
4. Responsible for data processing and calculation;
5. Sends the required print task data to the small core via DMA according to agreed rules.
Small core tasks:
1. Responsible for collecting the status of the print head;
2. Coordinate the synchronization relationship between the printer and data preparation;
3. Responsible for transmitting data to the print head according to the print head’s interface standards.
Software Framework for Cloud Thermal Printer Solution Based on X2000
The operating system and SDK suite, application-oriented software service package, and various printer applications consist of three levels. The SDK suite includes Cross Cores and DMA modules to achieve cross-core resource interaction and collaboration. OpenAMP (Open Asymmetric Multi Processing) provides developers with open cross-core communication, resource scheduling, and dynamic collaboration development interfaces.
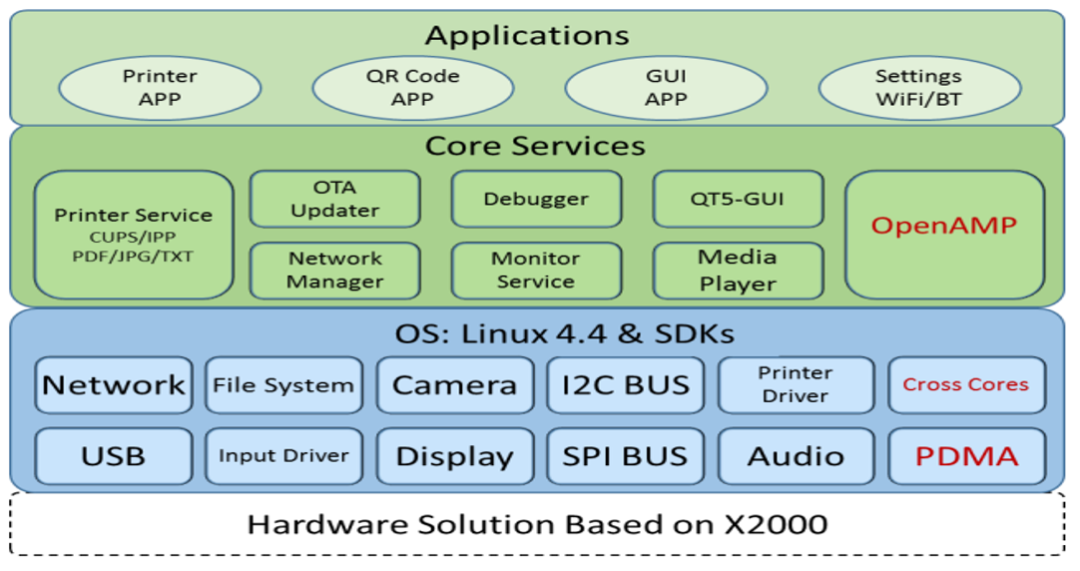
Figure: Software framework for cloud thermal printer solution
Conclusion
The three-core heterogeneous layout of X2000 provides a processor basis for expanding intelligent IoT applications to cross-border applications that involve both data computation and real-time control, offering great flexibility for application layer development. With its integration of three-core heterogeneity, up to 256MB of on-chip LPDDR, dual gigabit networks, three camera access capabilities, and rich interface capabilities, X2000 will undoubtedly provide abundant development means for fragmented intelligent IoT applications.
