Skip to content
With the development of ICT technology, a single SOC’s computing power can undertake more services. The expansion of network bandwidth and features such as low latency and differentiated services make business deployment and function allocation more flexible. For example: perception, fusion, planning, control, and execution can be decoupled. The electronic and electrical architecture transitions from a distributed architecture to a domain-centralized architecture, and then to a central centralized architecture, integrating the dispersed ECU functions into domain controllers or even onboard central computers. This is multi-domain fusion.
The underlying hardware of automotive electronics is no longer provided by a single chip for simple logical calculations but requires complex multi-core SoC chips to provide more complex control logic and strong computing power support. However, multi-domain services have different technical requirements. For example, the cockpit domain IVI services emphasize interactive experience and a rich application ecosystem, making Android a suitable operating system; the dashboard and assisted driving require real-time and reliability, leaning towards RTLinux or RTOS; the intelligent driving domain emphasizes high computing power for integrated perception and planning, also requiring real-time and reliability, thus choosing RTLinux or RTOS. While merging domains, it is necessary to ensure the safety and reliability of critical services and consider the sustainability and compatibility of the application ecosystem, which requires resource isolation technology to support resource partitioning on the same SOC, allowing multiple operating systems to run concurrently without interference.
There are various resource isolation technologies, ranging from hardware-level isolation to virtualization isolation, container isolation, and process isolation. Hardware isolation has the best isolation, with the best performance and safety reliability for a single isolation domain, but it has poor flexibility and configurability, cannot achieve hardware sharing, resulting in poor overall system resource utilization, failing to fully achieve the goal of software-defined vehicles. Container isolation and process isolation can achieve business isolation more lightweight, but they still exist within the same operating system, posing risks of resource interference and mutual security attacks, and cannot support the fusion of heterogeneous operating system business domains, affecting the inheritance of traditional businesses and hindering ecosystem development. Among many resource isolation technologies, virtualization is a safe, reliable, elastic, and flexible preferred solution and is an important supporting technology for software-defined vehicles. Typical application scenarios are shown in Figure 1:
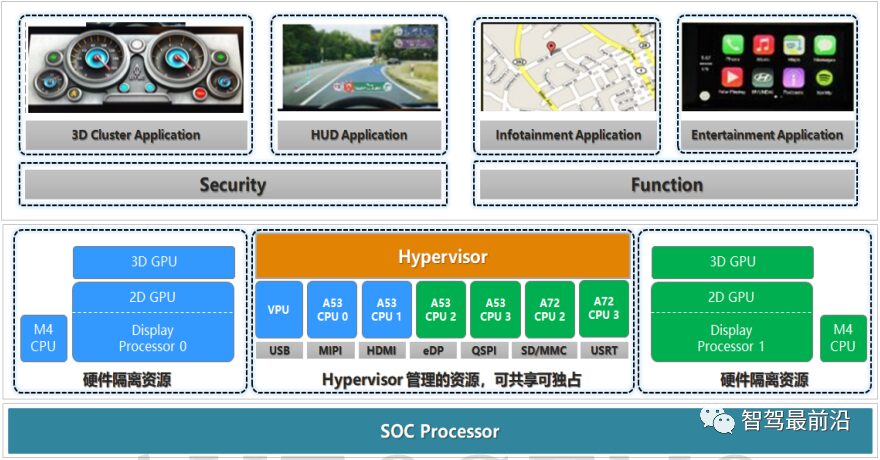 Figure 1 Typical Application Scenarios of Virtualization
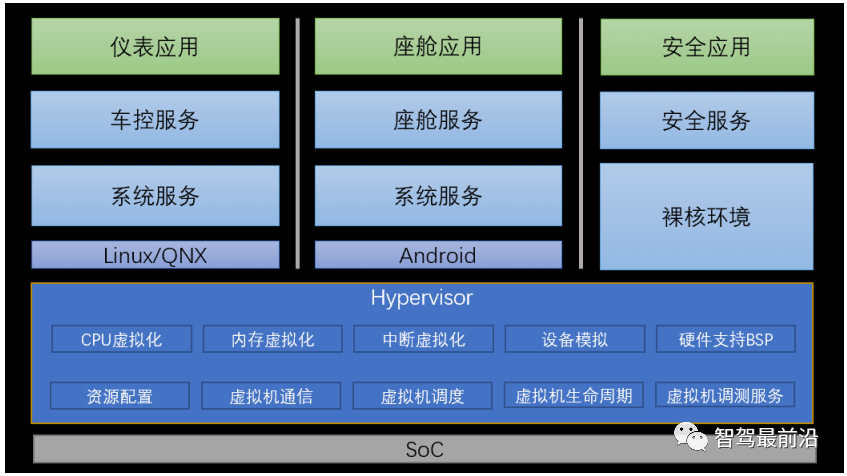
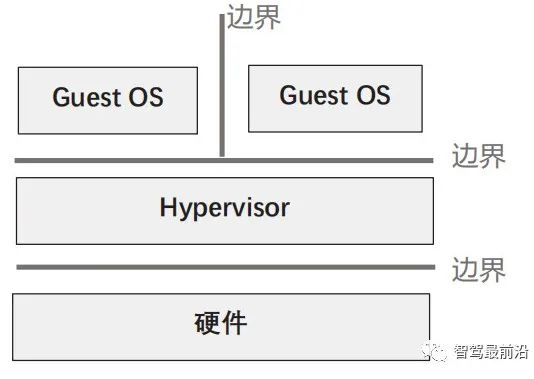
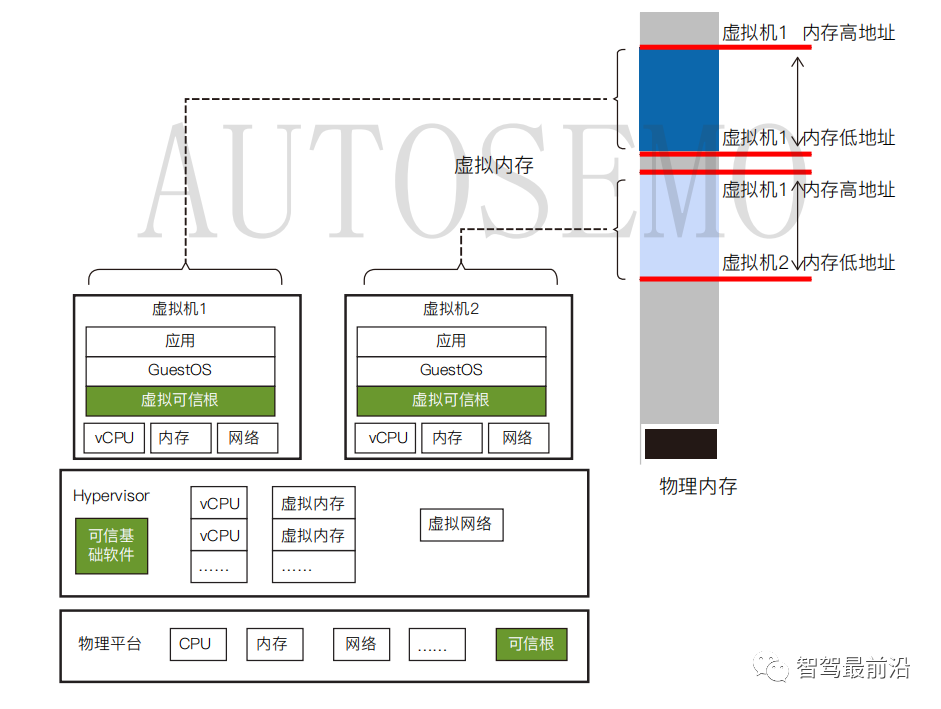
Hypervisor, literally meaning “supervisor”, is also known as Virtual Machine Monitor (VMM). As shown in Figure 2, Hypervisor sits on top of the SoC hardware platform, converting physical resources (such as CPU, memory, storage space, network adapters, peripherals, etc.) into virtual resources, allocating them to each virtual machine as needed, allowing them to independently access the authorized virtual resources. Hypervisor achieves the integration and isolation of hardware resources, enabling applications to share physical hardware like CPUs while relying on different kernel environments and drivers to operate, thus meeting the diverse application scenario needs in the automotive field.
Figure 2 Position of Virtualization in the System
In the automotive field, Hypervisor mainly performs the following tasks:
Figure 1 Typical Application Scenarios of Virtualization
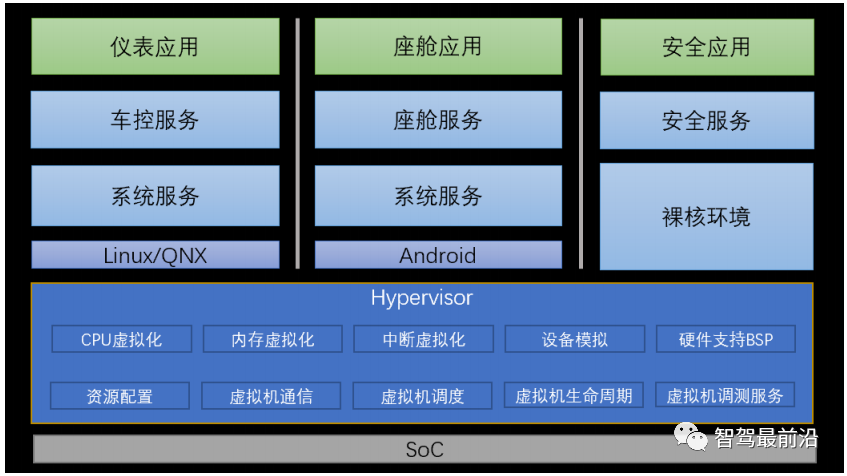
Hypervisor, literally meaning “supervisor”, is also known as Virtual Machine Monitor (VMM). As shown in Figure 2, Hypervisor sits on top of the SoC hardware platform, converting physical resources (such as CPU, memory, storage space, network adapters, peripherals, etc.) into virtual resources, allocating them to each virtual machine as needed, allowing them to independently access the authorized virtual resources. Hypervisor achieves the integration and isolation of hardware resources, enabling applications to share physical hardware like CPUs while relying on different kernel environments and drivers to operate, thus meeting the diverse application scenario needs in the automotive field.
Figure 2 Position of Virtualization in the System
In the automotive field, Hypervisor mainly performs the following tasks:
-
CPU virtualization: Provides VCPU resources and operating environment for virtual machines;
-
Memory virtualization: Responsible for allocating and managing hardware memory resources for itself and virtual machines;
-
Interrupt virtualization: Routes interrupts and exceptions to virtual machines for processing as needed when they occur;
-
Virtual machine device simulation: Creates virtual hardware components that virtual machines can access as needed;
-
Hardware support BSP: Provides board-level support packages for Hypervisor running on SoC, such as serial port drivers;
-
Virtual machine resource configuration: Configures and manages resources such as CPU, memory, and IO peripherals for virtual machines;
-
Virtual machine communication: Provides IPC, shared memory, and other communication mechanisms for virtual machines.
-
Virtual machine scheduling: Provides scheduling algorithms such as priority and time slices for virtual machines;
-
Virtual machine lifecycle management: Creates, starts, and stops virtual machines;
-
Virtual machine debugging services: Provides console, logs, and other debugging functions;
In the automotive field, Hypervisor also faces the following challenges:
-
Lightweight and efficient. While Hypervisor brings the flexibility of software definition, it also leads to an increase in software stack layers, inevitably resulting in performance loss. The cost-sensitive nature of the automotive field necessitates a continuous demand to reduce performance loss of CPU, storage, network, GPU, and other peripherals throughout the vehicle project, making the lightweight and efficient nature of Hypervisor very important;
-
Safe and reliable. Compared to the resource dynamic allocation and idle utilization emphasized in the Internet field, the automotive field places greater importance on the real-time, reliability, and safety of Hypervisor;
-
Convenient adaptation. In the automotive field, there is a rich variety of chip types and operating systems, and a major characteristic of embedded virtualization is heterogeneity. Hypervisor must possess the capability to quickly adapt to different underlying hardware and upper-layer operating systems.
Technical Development Trends
2.1 Differentiation of Key Technologies in Cloud, Edge, and Endpoint Virtualization
Virtualization technology can be traced back to the 1960s when IBM developed virtual machine monitor software to virtually partition computer hardware into one or more virtual machines, supporting multiple users to access large computers simultaneously and interactively. With the improvement of general server computing power in the 21st century, cloud computing has flourished, and cloud virtualization, as a supporting technology, has rapidly iterated and evolved. Later, computing power gradually descended from cloud to edge to endpoint, leading to the emergence of edge virtualization and endpoint embedded virtualization. Their typical architectures and key technical requirements are shown in Figure 3.
Figure 3 Typical Architecture and Key Technical Requirements of Cloud, Edge, and Endpoint Virtualization
(1) Cloud-side Virtualization
Its characteristics include a basically homogeneous hardware platform, a large number of nodes forming a cluster, and architecture design prioritizing throughput capability. It must support multi-business concurrency, and virtualization must meet resource scheduling strategies for cluster load balancing and energy conservation. During cross-node virtual machine allocation, it must ensure business uninterrupted migration. When a virtual machine fails, it must ensure recovery from checkpoints to minimize business loss. The virtual machine must support elastic expansion of capabilities such as CPU computing power, memory, storage space, network, GPU, and peripherals, and must allow over-allocation to enhance the operational benefits of the data center.
(2) Edge-side Virtualization
This is implemented on edge nodes for certain specific businesses, adopting a general ICT architecture that supports dynamic deployment of various businesses, typically like SDN and NFV. Its technical features include: based on a general hardware platform and industry-customized management deployment platform, achieving soft and hard decoupling and software definition, deploying multifunctional nodes on demand and elastic networking, generally adopting a 1+1 or N+1 redundancy method to ensure high availability of services. In 5G telecom network elements, it is necessary to consider the end-to-end real-time nature of 5G services; Hypervisor, virtual machines, and communication protocol stacks all need to be designed with this consideration.
(3) Endpoint-side Virtualization
Endpoint-side typically features heterogeneity, with significant differences in chip architecture and processing capabilities. Generally, it is a single-chip solution without clusters or primary-backup virtual machine migration, thus emphasizing high security and high reliability for a single node, such as functional safety ASIL level requirements, while also having stronger requirements for real-time performance and determinism. Additionally, endpoint resources are more limited and cost-sensitive, thus requiring Hypervisor to be lightweight and high-performance.
2.2 Virtualization Model Trends
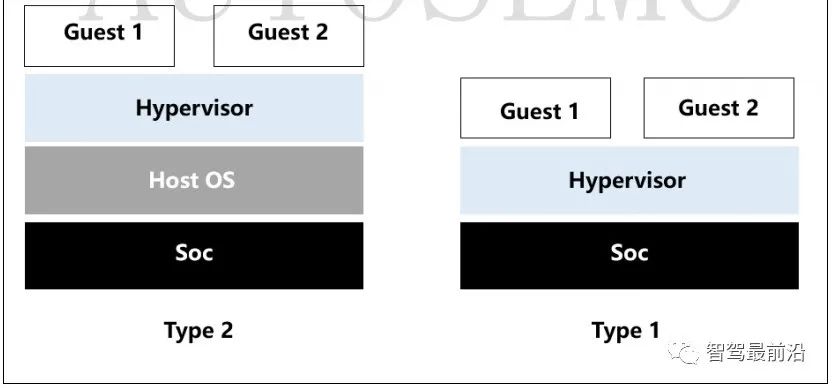
Hypervisor can be divided into two main categories: one is Type 1 bare-metal, where Hypervisor runs directly on hardware, also known as Bare-Metal Hardware Virtualization; the other is Type 2 hosted, also known as Hosted Virtualization. Figure 4 shows the layered architecture of the two types of Hypervisor.
Figure 4 Type 1 and Type 2 Hypervisor
Type 2 Hypervisor needs to rely on a host operating system to manage resources such as CPU, memory, and network. Since there is a host operating system between the Hypervisor and hardware, all operations of the Hypervisor and VM must pass through the host operating system, leading to inevitable delays and performance losses. Additionally, the security flaws and stability issues of the host operating system will affect the VMs running on it, so Type-2 Hypervisor is primarily used in scenarios where performance and security requirements are not high, such as personal PC systems.
Type 1 Hypervisor does not depend on a host operating system, having basic operating system functions itself. It is designed to be simpler, running directly on hardware, with a smaller overall code base and architecture, requiring fewer memory and storage resources, able to meet the functional safety level requirements of autonomous driving vehicle control systems, and conditions for formal verification. Thus, automotive operating systems are more suited to use Type 1 Hypervisor.
With the development of microkernel operating system technology, many Hypervisors designed based on microkernel operating systems have become very streamlined, only including basic, unchanging functions such as CPU scheduling and memory management, while device drivers and other variable components are outside the kernel. There is industry debate on whether this type of Hypervisor should be classified as Type 1 or Type 2. Overall, microkernel Hypervisors are smaller, more stable, and have better scalability, making them more suitable for embedded virtualization scenarios.
2.3 Collaboration Technology Routes between Hypervisor and Virtual Machines
The original virtualization was achieved by software simulating a computer system with complete hardware system functions, running in an isolated environment, that is, providing virtual hardware devices for GuestOS to use. The advantage is that the GuestOS is unaware of the external real hardware environment and does not need modifications. Since each access to fully virtualized hardware in the Guest OS must trap into the Hypervisor, this leads to poor performance of the virtualized hardware, generally only used to simulate simpler hardware like serial ports. The hardware simulation can be directly simulated in the Hypervisor or can pass requests to other VMs for simulation, such as simulating through QEMU in a certain VM.
(2) Hardware-Assisted Virtualization
Intel was the first to propose hardware-assisted virtualization technology, providing shared functions directly from hardware to support access by multiple GuestOS, reducing the latency and performance loss brought by software virtualization technology. Intel proposed technologies such as Intel VT-x, Intel VT-d, and Intel VT-c for processors, memory, IO, and networks. As ARM’s computing power increases, transitioning from mobile to edge and even cloud computing centers, ARM is continuously enhancing its hardware-assisted virtualization technology, such as stage 2 page table translation and virtual exceptions.
In the developmental stage where hardware-assisted virtualization technology is not mature or strong, or for sharing and reusing certain complex peripherals, paravirtualization technology can be adopted, where GuestOS collaborates with Hypervisor. This technology is generally applied to IO device virtualization, using a front-end and back-end approach. In the Guest OS, front-end drivers are implemented, while back-end drivers are implemented in the Hypervisor or Host OS, generally following the VirtIO standard. The front-end driver in the Guest OS communicates with the back-end driver through communication mechanisms provided by the Hypervisor, passing requests from the Guest OS to the back-end driver, which sends requests to the hardware driver and returns results back to the front-end driver. Paravirtualization achieves better hardware performance compared to full virtualization and can implement relatively complex hardware like block devices, network cards, display devices, etc. As shown in Figure 5.
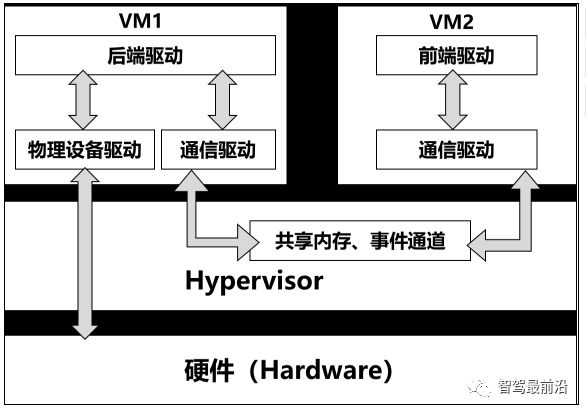 Figure 5 Paravirtualization Pass-through Resource Allocation
Hypervisor supports directly allocating hardware resources to the Guest OS in its virtual machine without needing to go through the Hypervisor for address and instruction translation. For example: serial port resources, USB resources, and other interface-rich resources can be directly allocated to a certain virtual machine via Pass-through. Device controllers are generally accessed in MMIO mode, so it is only necessary to map the controller address area to the VM to achieve allocation of the device controller, while also needing to allocate a virtual interrupt corresponding to a device hardware interrupt to that VM. The direct pass-through method allows the VM to exclusively access that hardware, thus providing the best performance.
Key Technology Interpretation
3.1 CPU Virtualization and Energy Saving Technology
High-performance processors in vehicles generally adopt a multi-core CPU architecture. In an SMP (Symmetric Multi-Processing) architecture, the Hypervisor scheduler configures the guest operating system to run on specified CPUs based on CPU affinity, while the operating system of the virtual machine can perform task scheduling on the CPU according to its scheduling method, such as priority-based scheduling. To maximize system resource utilization, the Hypervisor also supports multiple virtual machines sharing a certain CPU. On shared cores, the Hypervisor can schedule virtual machines through priority or time partitioning methods, ensuring that the virtual machine’s running time and scheduling strategy are deterministic. The Hypervisor’s scheduling algorithm needs to ensure that no virtual machine in the partition gets stuck in a loop or fails, occupying processor resources for an extended time, preventing other virtual machines from receiving reasonable time allocations.
Virtual machine scheduling also needs to consider energy saving and consumption reduction. In high workload conditions, the system increases the main frequency to enhance user experience, while in low workload conditions, the system automatically conserves energy by reducing frequency to extend battery life. High-performance processors in vehicles are designed with a big.LITTLE architecture for energy saving and consumption reduction requirements. The CPU and the complex operating systems running above it need to support big.LITTLE scheduling, dynamic frequency scaling, low-power settings, turning off CPU cores, and sleep (Suspend to RAM/Suspend to Disk) energy-saving functions. After system virtualization, physical resources such as CPU must be accessed directly through the Hypervisor, and the Hypervisor’s scheduling algorithm also needs to support energy-saving and consumption-reduction for virtual machines.
3.2 IO Device Virtualization
For performance considerations, paravirtualization technology is generally used in embedded fields. Paravirtualization technology requires cooperation between the front-end driver in the Guest OS and the back-end driver in the Hypervisor. The front-end driver sends requests from the Guest OS to the back-end driver through communication mechanisms provided by the Hypervisor, and the back-end driver accesses the device by calling the physical driver. This involves the integration problem between different vendors’ Guest OS and different vendors’ Hypervisor ecosystems.
Virtio is currently the most popular I/O paravirtualization solution. Virtio is an open protocol and interface managed by the OASIS standards group to standardize virtual machine access to IO devices. Virtio was officially standardized in March 2016, with version 1.1 released in 2020. The Virtio standard adopts a general and standardized abstraction model, supports an increasing number of device types, is highly efficient, widely used in cloud computing, and has high open-source activity, with stable front-end driver code available in operating systems like Linux. Most commercial and open-source Hypervisors already support the Virtio standard.
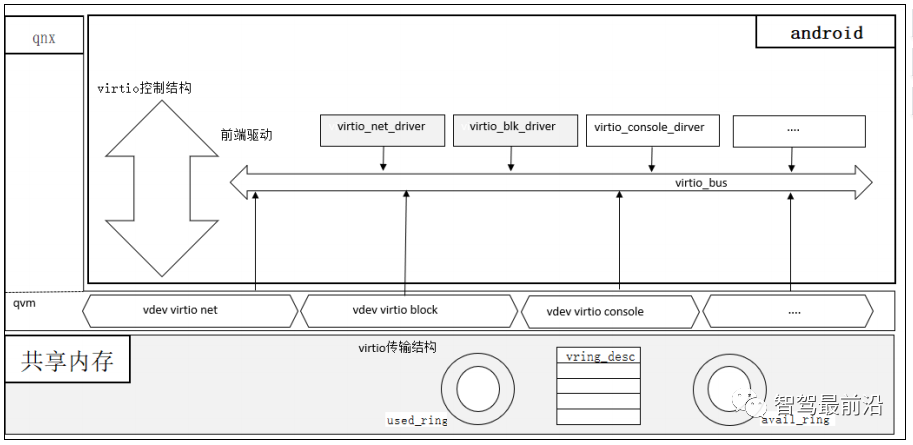
Virtio is a commonly used implementation of paravirtualization technology in the automotive industry, as shown in Figure 6. A virtual device bus Virtio-bus is created inside the Guest OS, and communication is performed through the Virtio Ring bi-directional communication mechanism, allowing front-end drivers to communicate with back-end virtual devices mounted on the Virtio-bus that comply with the Virtio standard. Virtio provides a comprehensive Virtio bus and device control interface, including virtio-net, virtio-blk, virtio-console, virtio-input, etc.
Figure 6 Virtio Virtualization Implementation Model
Figure 5 Paravirtualization Pass-through Resource Allocation
Hypervisor supports directly allocating hardware resources to the Guest OS in its virtual machine without needing to go through the Hypervisor for address and instruction translation. For example: serial port resources, USB resources, and other interface-rich resources can be directly allocated to a certain virtual machine via Pass-through. Device controllers are generally accessed in MMIO mode, so it is only necessary to map the controller address area to the VM to achieve allocation of the device controller, while also needing to allocate a virtual interrupt corresponding to a device hardware interrupt to that VM. The direct pass-through method allows the VM to exclusively access that hardware, thus providing the best performance.
Key Technology Interpretation
3.1 CPU Virtualization and Energy Saving Technology
High-performance processors in vehicles generally adopt a multi-core CPU architecture. In an SMP (Symmetric Multi-Processing) architecture, the Hypervisor scheduler configures the guest operating system to run on specified CPUs based on CPU affinity, while the operating system of the virtual machine can perform task scheduling on the CPU according to its scheduling method, such as priority-based scheduling. To maximize system resource utilization, the Hypervisor also supports multiple virtual machines sharing a certain CPU. On shared cores, the Hypervisor can schedule virtual machines through priority or time partitioning methods, ensuring that the virtual machine’s running time and scheduling strategy are deterministic. The Hypervisor’s scheduling algorithm needs to ensure that no virtual machine in the partition gets stuck in a loop or fails, occupying processor resources for an extended time, preventing other virtual machines from receiving reasonable time allocations.
Virtual machine scheduling also needs to consider energy saving and consumption reduction. In high workload conditions, the system increases the main frequency to enhance user experience, while in low workload conditions, the system automatically conserves energy by reducing frequency to extend battery life. High-performance processors in vehicles are designed with a big.LITTLE architecture for energy saving and consumption reduction requirements. The CPU and the complex operating systems running above it need to support big.LITTLE scheduling, dynamic frequency scaling, low-power settings, turning off CPU cores, and sleep (Suspend to RAM/Suspend to Disk) energy-saving functions. After system virtualization, physical resources such as CPU must be accessed directly through the Hypervisor, and the Hypervisor’s scheduling algorithm also needs to support energy-saving and consumption-reduction for virtual machines.
3.2 IO Device Virtualization
For performance considerations, paravirtualization technology is generally used in embedded fields. Paravirtualization technology requires cooperation between the front-end driver in the Guest OS and the back-end driver in the Hypervisor. The front-end driver sends requests from the Guest OS to the back-end driver through communication mechanisms provided by the Hypervisor, and the back-end driver accesses the device by calling the physical driver. This involves the integration problem between different vendors’ Guest OS and different vendors’ Hypervisor ecosystems.
Virtio is currently the most popular I/O paravirtualization solution. Virtio is an open protocol and interface managed by the OASIS standards group to standardize virtual machine access to IO devices. Virtio was officially standardized in March 2016, with version 1.1 released in 2020. The Virtio standard adopts a general and standardized abstraction model, supports an increasing number of device types, is highly efficient, widely used in cloud computing, and has high open-source activity, with stable front-end driver code available in operating systems like Linux. Most commercial and open-source Hypervisors already support the Virtio standard.
Virtio is a commonly used implementation of paravirtualization technology in the automotive industry, as shown in Figure 6. A virtual device bus Virtio-bus is created inside the Guest OS, and communication is performed through the Virtio Ring bi-directional communication mechanism, allowing front-end drivers to communicate with back-end virtual devices mounted on the Virtio-bus that comply with the Virtio standard. Virtio provides a comprehensive Virtio bus and device control interface, including virtio-net, virtio-blk, virtio-console, virtio-input, etc.
Figure 6 Virtio Virtualization Implementation Model
-
Using virtio-blk technology to achieve block device sharing
Block devices are storage devices read and written using a caching mechanism, allocated for management by the operating system where the Hypervisor resides. The virtio-blk driver is a block device driver compliant with the Virtio standard, where vdev virtio block is the back-end virtual block device, and the virtio blk driver completes read and write operations on the physical block device through the vdev device and obtains execution results.
-
Using virtio-net technology to achieve inter-system communication
Virtio-net achieves point-to-point communication between multiple systems, with the virtio-net driver inside the Guest system communicating in full duplex with the virtio-net device of the system where the Hypervisor resides, allowing for control and configuration commands and data exchange between multiple systems. It is suitable for data transmission other than audio and video streams, has good stability, but due to the complex control logic of the virtqueue, it has some impact on real-time performance.
-
Using virtio technology to achieve touch sharing
Touch devices are character-type devices, achieving front-end driver and back-end device interaction through the virtio-input driver and vdev-input. The device side reports touch coordinate data to the driver through the virtqueue.
Real-time performance is a key performance indicator of embedded real-time operating systems. The real-time performance of the Hypervisor is the foundation of the entire system’s real-time performance. If the Hypervisor cannot schedule the guest operating system to run in a timely manner, the guest operating system cannot achieve good real-time performance metrics. The main indicators for measuring Hypervisor real-time performance include interrupt latency and scheduling latency. Interrupt latency starts from the moment an external interrupt occurs and ends when the virtual machine receives the interrupt injected by the Hypervisor. The longest delay time under various pressures is the interrupt latency. Scheduling latency refers to the time from when a high-priority virtual machine process becomes ready to when that high-priority virtual machine process is scheduled to run. The longest delay time under various system pressures is the scheduling latency.
After interrupt virtualization, when an external interrupt occurs, the Hypervisor receives it and injects it into the virtual machine as quickly as possible, minimizing the time for interrupt processing in the Hypervisor. The Hypervisor optimizes the context-switching time of virtual machines, minimizing the time spent on disabling interrupts and preemption, and reducing the use of kernel locks. When a high-priority virtual machine needs to switch to run, it can switch to the high-priority virtual machine as quickly as possible.
3.4 Safety and Reliability Technology
Functional safety, information security, and reliability are necessary components for the reliable and safe operation of vehicle control operating system products. The Hypervisor provides a basic operating environment for intelligent vehicle domain controllers, and its safety and reliability are the foundation and core to ensure the functional safety and reliability of the entire system. The Hypervisor must be designed, developed, and tested according to the highest standards of automotive functional safety ISO26262 ASIL-D, with its functional safety requirements derived from the safety requirements of the domain controller products.
Multiple virtual machines run on the Hypervisor, and an exception in one virtual machine cannot propagate to other virtual machines. The Hypervisor can obtain the overall health status of the current system. When a virtual machine has an exception, the Hypervisor should monitor the system’s health status in real-time, effectively isolate the fault, and repair the exception within the smallest impact range to ensure continuous system availability.
Integrating the Hypervisor into the automotive software stack will increase the vertical software stack layers and the horizontal complexity of business software. However, the safety and reliability requirements of the automotive industry are stronger than those of existing cloud-side virtualization and edge-side virtualization, so the safety of virtualization is increasingly gaining attention in the industry. These safety concerns include:
-
The trust chain issue between the virtual machine manager and virtual machines. Using virtualization technology to create multiple virtual machines on a trusted physical platform and passing the trust chain built from the hardware trusted root to each virtual machine, thus constructing multiple virtual trusted computing platforms on a trusted physical platform. Some solutions lack trust chain verification from the virtual machine manager to the virtual machines;
-
Attacks between virtual machines: Malicious intruders can exploit vulnerabilities in the virtual machine manager to gain control over a virtual machine through another virtual machine on the same physical host, thereby compromising the target virtual machine;
-
Virtual machine escape: Attacks that exploit vulnerabilities in the virtualization software or software running in the virtual machine to attack or control the virtual machine host operating system.
To enhance the security of the Hypervisor, it is important to establish corresponding security objectives. The table below briefly lists the relevant requirements:
The security capabilities of the Hypervisor can be improved from three dimensions.
(1) Establishing security boundaries
As shown in Figure 7, this boundary is strictly defined and enforced by the Hypervisor. The confidentiality, integrity, and availability of the Hypervisor’s security boundary need to be guaranteed. The boundary can defend against a range of attacks, including side-channel information leakage, denial of service, and privilege escalation. The Hypervisor’s security boundary also provides isolation capabilities for network traffic, virtual devices, storage, computing resources, and all other virtual machine resources.
Figure 7 Security Boundary
The overall virtualization security architecture is shown in Figure 8. The confidentiality of the security boundary can be implemented through traditional cryptographic methods. Integrity is ensured through trusted measurement mechanisms, and trusted reporting mechanisms achieve trusted interoperability between different virtual environments. Monitoring mechanisms dynamically measure the behavior of entities, detecting and eliminating unexpected mutual interference. The isolation mechanisms provided by virtualization technology separate the operating spaces of entities.
Figure 8 Overall Virtualization Security Architecture
The isolation of the security boundary is supported by the Hypervisor’s vCPU scheduling isolation, memory isolation, network isolation, and storage isolation technologies, achieving isolation between the Hypervisor and virtual machines and among virtual machines on the same physical machine.
(2) Establishing a deep defense vulnerability mitigation mechanism
For potential vulnerabilities in the security boundary, the Hypervisor needs certain technical means for proactive defense. These technical means include Address Space Layout Randomization (ASLR), Data Execution Prevention (DEP), arbitrary code protection, control flow protection, and data corruption protection.
(3) Establishing a robust security assurance process
The attack surfaces related to the Hypervisor include virtual networks, virtual devices, and all surfaces across virtual machines. It is recommended to implement threat modeling, code reviews, and fuzzed testing on all virtual machine attack surfaces, triggering regular security checks through automated builds and environments.
As an important technology in cloud computing scenarios, virtualization technology has accumulated many security paradigms over more than a decade of production practice, which can also be referenced in automotive scenarios. However, compared to cloud scenarios, the virtualization technology in automotive scenarios has its particularities, such as virtual machines not needing dynamic migration/creation, and the Hypervisor having functional safety level requirements, etc. Its security measures need to be continuously enriched and improved in practice.
Typical Application Cases
In the development of automotive intelligence, virtualization is mainly applied in scenarios such as intelligent cockpits, intelligent driving, and intelligent gateways. Intelligent driving is limited by technological maturity and policies, mostly remaining in the research and prototype stages. The functional capabilities of intelligent gateways are relatively homogeneous and may further integrate into other scenario solutions. Therefore, the current major application cases are concentrated in the intelligent cockpit.
The integration of intelligent cockpit domains has also started in recent years and is continuously iterating and evolving. Influenced by factors such as chip computing power, the maturity of virtualization technology, and the ecosystem’s control over virtualization solutions, some manufacturers have simultaneously adopted hardware isolation schemes to achieve domain integration, maximizing the use of existing technical capabilities with certainty. However, this lacks the flexibility of software definition, resulting in limited intelligent levels, making it a selectable solution for domain integration. In terms of embedded virtualization technology, foreign companies like QNX, OpenSynergy, PikeOS, etc., have a first-mover advantage, especially in the automotive field where they have been cultivating for many years, thus many application cases have emerged in the past two years. Driven by the trend of localized intelligent development, many domestic chip manufacturers and independent software vendors have developed embedded virtualization technologies, products, and solutions in recent years, such as Raite Hypervisor (RHOS) by Zhongling Zhixing, ZTE’s GoldenOS, AliOS Hypervisor by Zebra Zhixing, and CAIC Hypervisor by China Automotive Innovation.
4.1 Intelligent Cockpit Domain Controller Products
For example, a manufacturer’s intelligent cockpit domain controller product, as shown in Figures 9 and 10, is based on Qualcomm 8155 and Renesas R-Car H3 processors, using QNX Hypervisor, equipped with QNX Host, and Android P/R/S Guest OS, capable of outputting up to 6 high-definition large screens for independent display, integrating entertainment systems, LCD instruments, body control, DMS, APA, and other functions, supporting independent four-zone audio, multi-screen interaction, and audio-video sharing, with high integration, adapted for mass production in multiple models such as Great Wall, Changan, and Yutong buses.
Additionally, the domestic solution, the Chipstar X9HP+ platform, flexibly configures to achieve mid-to-low-end intelligent cockpit domain controller products using both hardware partitioning and Hypervisor solutions.
Figure 9 Intelligent Cockpit Domain Controller
Figure 10 Domestic Solution Intelligent Cockpit Domain Controller
4.2 RHOS Intelligent Cockpit Domain Controller Platform
(1) NXP I.MX8QM Cockpit Domain Controller
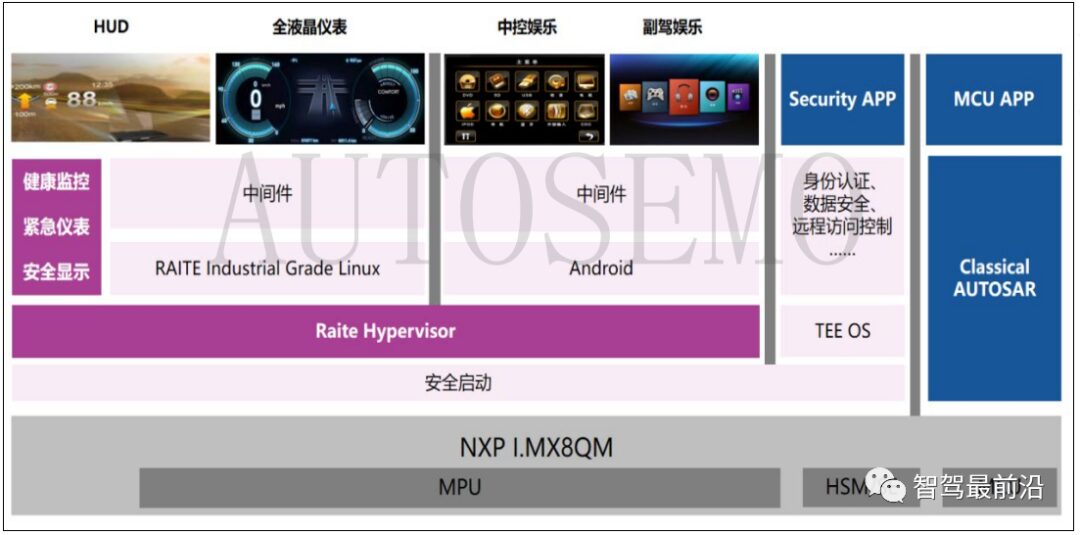
A manufacturer based on self-developed Type-1 virtualization software RHOS (Raite Hypervisor OS) supports NXP I.MX8QM, providing a lightweight and flexible automotive intelligent cockpit virtualization solution, which has been mass-produced and launched in Dongfeng models. Its system architecture is shown in Figure 11:
Figure 11 NXP I.MX8 Intelligent Cockpit System Architecture
After running Hypervisor on the SoC, it can support multiple operating systems running simultaneously. For instance, the Linux system can run real-time and high-security requirements business functions, such as fully LCD dashboards, while also expanding to run DMS, HUD, etc. Another virtual machine runs the Android operating system, deploying business functions with lower security and real-time requirements, such as infotainment. To ensure the system has good market competitiveness, the domain controller is compatible with TBOX functional requirements, supporting sleep wake-up and fast startup.
Linux and Android virtual machines can be configured for resources as needed, including memory, CPU, storage space, peripherals, etc. This architecture supports system upgrades, including upgrades for virtual machines and the Hypervisor, and supports exception log recording, including virtual machine kernel and Hypervisor logs.
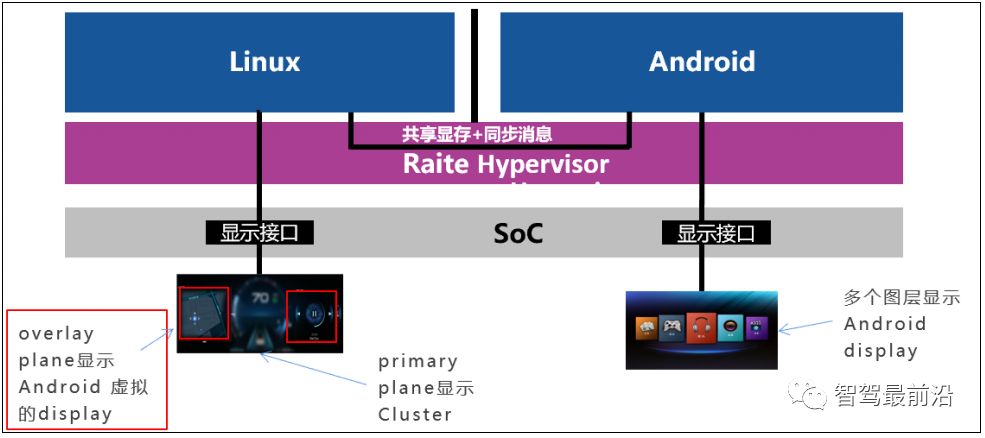
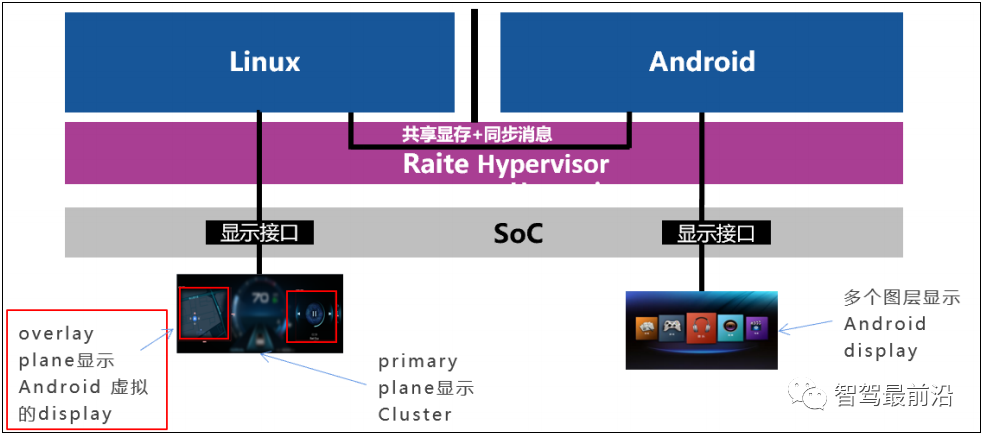
Multi-screen interaction is an important application scenario for intelligent cockpits. Android’s APP applications can be pushed to display on the Linux instrument through the Hypervisor.
Figure 12 Virtual Machine Multi-Screen Interaction Architecture
The interaction scheme between Android and Linux instruments is shown in Figure 12. The NXP I.MX8QM chip has more than two display interfaces, and each display interface can connect to 2 displays. When the Android system needs to project information onto the instrument screen, the instrument display screen’s Overlay layer can display the projected content. The system interaction has zero latency and zero copying, and multi-system interaction does not additionally occupy CPU and GPU resources. Through Hypervisor virtualization technology, cross-system multi-screen interaction is effectively improved, enhancing driving safety and reducing the hardware costs of the intelligent cockpit.
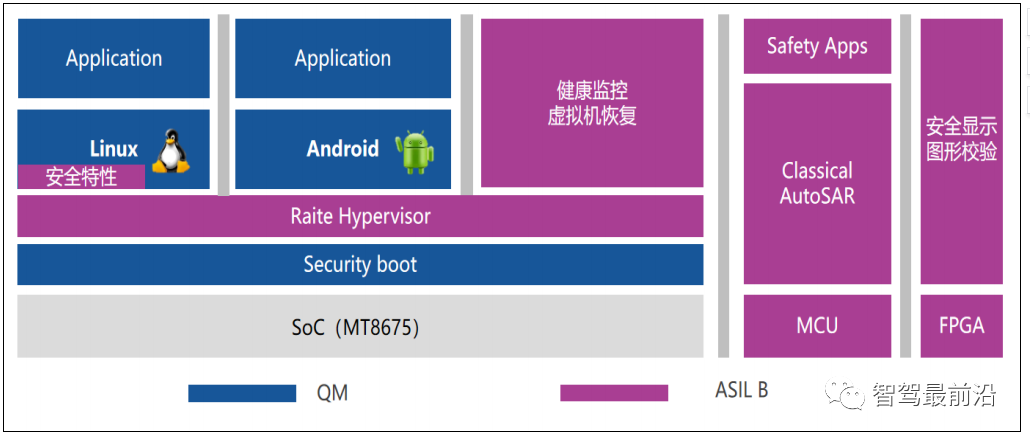
(2) MT8675 Cockpit Domain Controller
RHOS supports MT8675, forming a feature-rich, cost-effective multi-screen intelligent cockpit domain controller solution, which has obtained mass production projects from multiple car manufacturers. Its overall system architecture is shown in Figure 13:
Figure 13 MT8675 Intelligent Cockpit System Architecture
MT8675 only provides one GPU, and the cockpit domain needs to share GPU resources between the dashboard and central control. RHOS implements GPU virtualization sharing and achieves industry-leading virtualization performance (loss < 6%). RHOS supports Suspend to RAM function, allowing the MT8675 A core to be completely powered down, meeting the intelligent cockpit standby static power consumption requirement of less than 4mA.