Machine Heart SOTA! Model Community Column
This column is produced by Machine Heart SOTA! Model Community, updated every Sunday on the Machine Heart public account.
This week we invite “LLM Modification Group” member “Hoshino Gen” to share how to implement your own AI Agent through modifying AIDC-ai-business/Marcoroni-70B, codellama 34b/7b based on the Smart Agent project he maintains, focusing on task splitting and function calling.
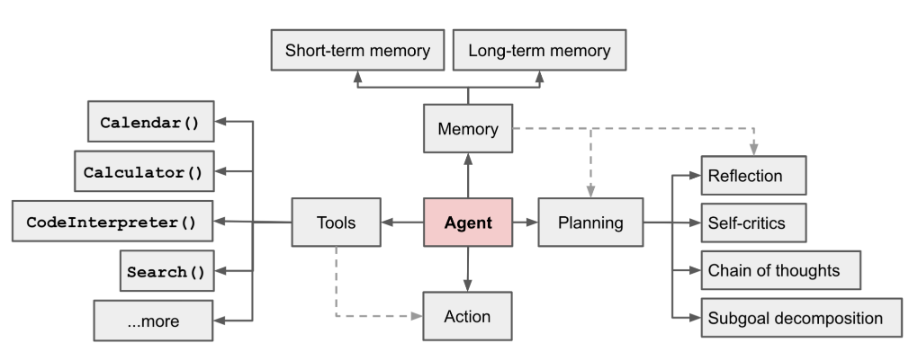
Figure 1 Overview of a LLM-powered autonomous agent system
In simple terms, an Agent uses the powerful language understanding and logical reasoning capabilities of LLMs to call tools to assist humans in completing tasks. However, there are also challenges, such as the efficiency of an agent’s tool usage being determined by the capabilities of the underlying model, which itself may have issues like hallucinations.
This article takes the scenario of “inputting a command to automatically achieve complex task splitting and function calling” as an example to construct a basic Agent process, focusing on how to successfully build the “task splitting” and “function calling” modules through “model selection” and “prompt design”.
Project Address:
https://sota.jiqizhixin.com/project/smart_agent
GitHub Repo:
https://github.com/zzlgreat/smart_agent

Task Splitting & Function Calling Agent Process
To implement “inputting a command to automatically achieve complex task splitting and function calling”, the Agent process constructed by the project is as follows:
-
Planner: Splits tasks based on user input commands. Determines the list of tools available (toolkit), informs the large model planner about what tools it has, and what kind of tasks need to be completed, then splits the tasks into plans 1, 2, 3…
-
Distributor: Responsible for selecting appropriate tools from the toolkit to execute the plans. The function calling model needs to choose the corresponding tools based on different plans.
-
Worker: Responsible for calling tasks in the toolbox and returning the results of the task calls.
-
Solver: Combines the distributed plans and corresponding results into a long story, and then summarizes and concludes by the solver.
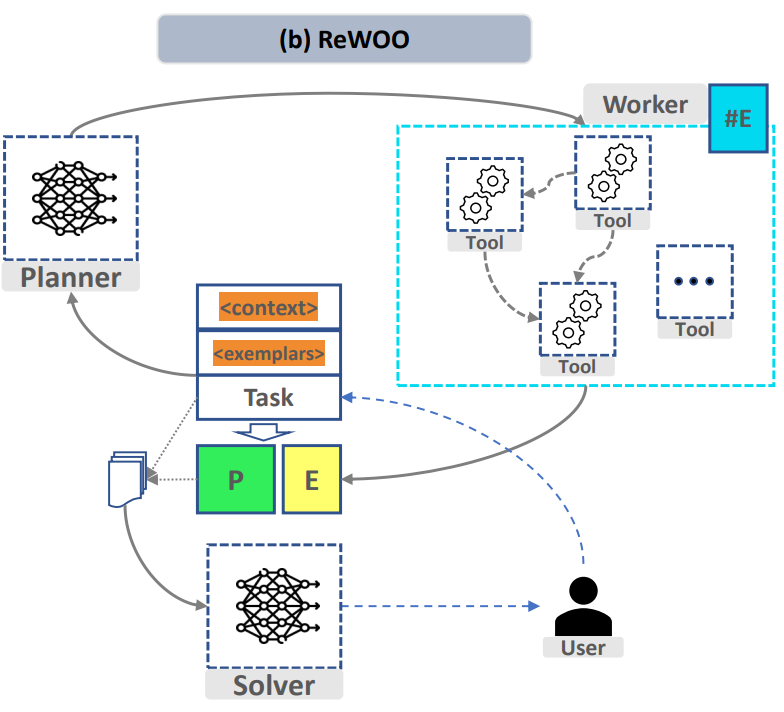
Figure 1 “ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models”
To implement the above process, the project designed two fine-tuning models for the “task splitting” and “function calling” modules, respectively, to achieve the functionality of breaking down complex tasks and calling custom functions as needed. The summarized model solver can be the same as the task splitting model.
Fine-tuning Task Splitting & Function Calling Models
2.1 Fine-tuning Experience Summary
In the “task splitting” module, the large model needs to have the ability to decompose complex tasks into simple tasks. The success of “task splitting” largely depends on two factors:
-
Model Selection: To split complex tasks, the selected base model for fine-tuning needs to have good understanding and generalization capabilities, meaning it should decompose unseen tasks in the training set based on prompt instructions. Currently, choosing a high-parameter large model makes this easier.
-
Prompt Design: Whether the prompt can successfully invoke the model’s reasoning chain to decompose the tasks into sub-tasks.
At the same time, it is hoped that the output format of the task splitting model under a given prompt template can be as fixed as possible, but it should not overfit and lose the model’s original reasoning and generalization capabilities; here, lora fine-tuning qv layers are applied to minimize changes to the original model’s structure.
In the “function calling” module, the large model needs to have the ability to stably call tools to meet the requirements of processing tasks:
-
Loss Function Adjustment: In addition to the generalization ability of the chosen base model and prompt design, to achieve a stable output of the model and to call the required functions based on the output, the “prompt loss-mask” method [2] is used for qlora training (see below for details), and a small trick of inserting eos tokens is used in qlora fine-tuning to stabilize the model’s output.
Additionally, in terms of computational power usage, low-power fine-tuning and inference of large language models are achieved through lora/qlora fine-tuning, and further reduction of inference thresholds is achieved through quantized deployment.
2.2 Base Model Selection
For the “task splitting” model selection, the model should have strong generalization ability and some reasoning chain capability. The Open LLM Leaderboard on HuggingFace can be referenced for model selection, focusing more on the MMLU test measuring multi-task accuracy and the overall score Average.
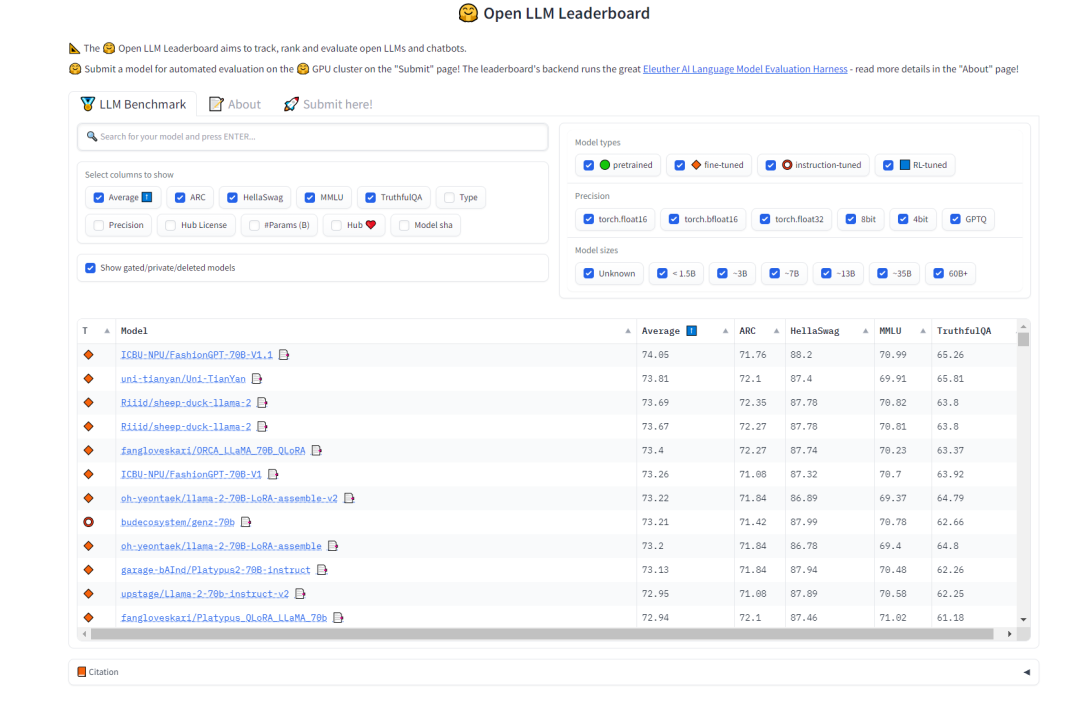
Figure 2 HuggingFace Open LLM Leaderboard (0921)
The selected model for task splitting is:
-
AIDC-ai-business/Marcoroni-70B: This model is fine-tuned based on Llama2 70B and is responsible for task splitting. According to the Open LLM Leaderboard on HuggingFace, this model has high MMLU and average scores, and a significant amount of Orca-style data was included during its training process, making it suitable for multi-turn dialogues, resulting in better performance in the plan-distribute-work-plan-work…summary process.
For the “function calling” model selection, the open-source Llama2 version of the code programming model CodeLlama’s original training data included a large amount of code data, allowing for the possibility of custom script qlora fine-tuning. For the function calling model, CodeLlama model (34b/13b/7b can be used) is selected as the base.
The selected model for function calling is:
-
codellama 34b/7b: This model is responsible for function calling and is trained on a large amount of code data, which necessarily includes a lot of natural language descriptions of functions, providing good zero-shot capabilities for given function descriptions.
For the fine-tuning of the “function calling” model, the project uses the prompt loss mask method for qlora training to stabilize the model output. The loss function adjustment method is as follows:
-
Loss Mask:
-
The loss_mask is a tensor with the same shape as the input sequence input_ids. Each element is either 0 or 1, where 1 indicates that the corresponding position’s label should be considered in the loss calculation, and 0 indicates it should not be considered.
-
For example, if some labels are padding (usually because of different sequence lengths in the batch), and you don’t want to consider these padding labels in the loss calculation, the loss_mask provides a 0 for these positions, thus masking out their loss.
-
Loss Calculation:
-
First, CrossEntropyLoss is used to calculate the unmasked loss.
Set reduction=’none’ to ensure that a loss value is returned for each position in the sequence, rather than a sum or average.
-
Then, the loss_mask is used to mask the loss. By multiplying the loss_mask with the losses, the masked_loss is obtained. Thus, the loss values for positions where the loss_mask is 0 are also 0 in masked_loss.
-
Loss Aggregation:
-
Sum all masked_loss and normalize it by loss_mask.sum(). This ensures that only the losses of labels masked as 1 are considered. To prevent division by zero, add a very small number 1e-9.
-
If all values of loss_mask are 0 (i.e., loss_mask.sum() == 0), then directly return a loss value of 0.
2.2 Hardware Requirements:
-
6*4090 for Marcoroni-70B’s 16bit lora
-
2*4090 for codellama 34b’s qlora / 1*4090 for codellama 13/7b’s qlora
2.3 Prompt Format Design
For task splitting, the project adopts the prompt format designed for the planner in the efficient reasoning framework ReWOO (Reasoning WithOut Observation) [2]. You only need to replace functions like ‘Wikipedia[input]’ with the respective functions and descriptions. The prompt example is as follows:
For the following tasks, make plans that can solve the problem step-by-step.
For each plan, indicate which external tool together with tool input to retrieve evidence.
You can store the evidence into a variable #E that can be called by later tools.
(Plan, #E1, Plan, #E2, Plan, ...) Tools can be one of the following:
Wikipedia[input]: Worker that search for similar page contents from Wikipedia.
Useful when you need to get holistic knowledge about people, places, companies, historical events, or other subjects.
The response are long and might contain some irrelevant information. Input should be a search query.
LLM[input]: A pretrained LLM like yourself. Useful when you need to act with general world knowledge and common sense.
Prioritize it when you are confident in solving the problem yourself. Input can be any instruction.
For function calling, since subsequent qlora fine-tuning will be performed, the prompt style from the open-source function calling dataset on HuggingFace [3] is directly adopted. Please see below.
Instruction Dataset Preparation
3.1 Data Sources
-
Task Splitting Model: Marcoroni-70B uses the alpaca prompt template. This model is fine-tuned on Llama2 70B, and to align with the original model template, an alpaca format dataset is required. Here, the rewoo planner dataset format is used, but the original dataset only includes calls to wiki and its own options, so this template can be applied, and the gpt4 interface can be used to create this style dataset.
-
Function Calling Model: Although the selected HuggingFace open-source function calling dataset has a small amount of data (55 rows), qlora is very effective, and this dataset also includes code training templates.
3.2 Dataset Format
-
Task Splitting Model Data Format: alpaca
### Instruction:
<prompt> (without the <>)
### Response:
如:
### Instruction:
For the following tasks, make plans that can solve the problem step-by-step. For each plan, indicate which external tool together with tool input to retrieve evidence. You can store the evidence into a variable #E that can be called by later tools. (Plan, #E1, Plan, #E2, Plan, ...) Tools can be one of the following:get_current_time[input]: Get the current time for now. search_bing[input]: Search the web for content on Bing, and return the top 10 results. Remember, the results may not as good as Wikipedia. If you think the result will not exist in wikipedia, use it. search_wiki[input]: Search the web for content on Wikipedia, and return the top 3 results. If you think the result can exist in wikipedia, use it. search_bilibili[input]: Search for videos on Bilibili, which is a website full of ACG. It can return top 10 search results. save_file[input]: save a file in the target dir which contains the data. query_mysql[input]: Execute the sql in the local mysql database. And return the result.
What movies did the director of 'Oppenheim' direct? List the top 10 best.
### Response:
Step 1: Identify the director of "Oppenheimer" movie.
#E1 = search_wiki("Director of Oppenheimer")
Step 2: Retrieve information about the director's other works.
If the retrieved name exists in Wikipedia, proceed with searching their filmography using search_wiki. Otherwise, try searching through Bing or another source like IMDb.
For example, if Christopher Nolan is found as the director of "Oppenheimer":
#E2 = search_bing("Filmography of Christopher Nolan")
Step 3: Extract the list of films directed by this person from the retrieved information.
From the returned results, extract the titles of the top 10 best movies according to critics/audience ratings or personal preference.
-
Function Calling Model Data Format:
The format of the dataset follows that of trelis. The dataset is not large, only 55 rows. Structurally, it is also in the alpaca format, divided into systemPrompt, userPrompt, and assistantResponse, corresponding to alpaca’s Instruction, prompt, Response. An example is as follows:
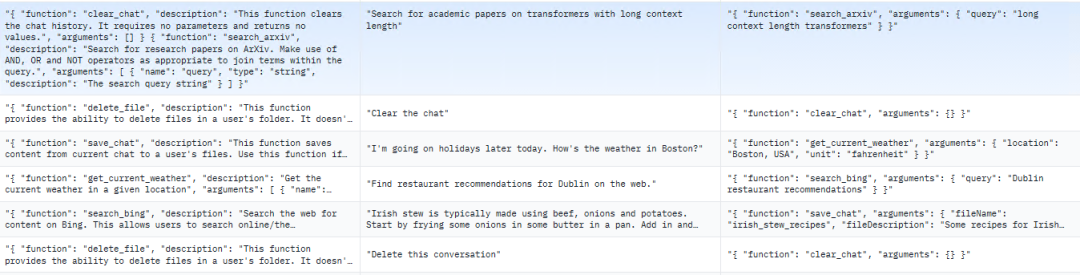
Figure 3 Example of HuggingFace Open-source Function Calling Dataset
Fine-tuning Process Explanation
4.1 Fine-tuning Environment
Ubuntu 22.04 system, CUDA 11.8, PyTorch 2.0.1, using the LLaMA-Efficient-Tuning framework. Deepspeed 0.10.4
4.2 Fine-tuning Steps
1) Lora Fine-tuning for Marcoroni-70B
-
The LLaMA-Efficient-Tuning framework supports Deepspeed integration. Before training starts, input the accelerate config for settings, choosing Deepspeed zero stage 3, as 6 cards totaling 144G of VRAM are used for lora fine-tuning, offloading optimizer states can be set to none, without offloading optimizer states to memory.
-
Offload parameters need to be set to cpu, unloading the parameters into memory, thus the peak memory usage can reach about 240G. Gradient accumulation needs to be consistent with the training script, here it is set to 4. Gradient clipping is used to normalize the error gradient vector, set to 1 to prevent gradient explosion.
-
Zero.init can be partitioned and converted to half precision, speeding up model initialization and allowing high-parameter models to be fully allocated in CPU memory. This can also be set to yes.
After all selections are made, create a training bash script as follows:
accelerate launch src/train_bash.py \
--stage sft \
--model_name_or_path your_model_path \
--do_train \
--dataset rewoo \
--template alpaca \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir your_output_path \
--overwrite_cache \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-6 \
--num_train_epochs 4.0 \
--plot_loss \
--flash_attn \
--bf16
This setup requires a peak memory usage of up to 240G but still ensures that 6 cards of 4090 can be trained. Initially, it may take a while due to Deepspeed needing to initialize the model. After that, training begins.

Figure 4 Training bandwidth speed of 6 cards 4090
Total training time was 8:56 hours. During this training, because the NVME slots on the motherboard share a PCIe 4.0 x16 bandwidth with OCULINK, two of the six cards ran on PCIe 4.0 x4, as shown in the figure, where both RX and TX are just the bandwidth speed of PCIe 4.0 x4. This became the biggest communication bottleneck in this training. If all cards ran on PCIe 4.0 x16, the speed should have been significantly faster.

Figure 5 LLaMA-Efficient-Tuning generated loss curve
The above is the loss curve automatically generated by LLaMA-Efficient-Tuning, which shows good convergence effects after 4 epochs.
2) Qlora Fine-tuning for Codellama
According to the prompt loss mask method described above, the trainer class was reconstructed (see project code repository func_caller_train.py). Since the dataset itself is small (55 rows), running 4 epochs took only two minutes, and the model quickly converged.
4.3 Testing Results After Fine-tuning
The project code repository provides a brief example of a usable toolkit. The functions include:
-
Bing Search
-
Wiki Search
-
Bilibili Search
-
Get Current Time
-
Save File
-
…
Now there is a 70B and a 34B model. In practical use, running both models simultaneously on 6 cards of 4090 at bf16 precision is unrealistic. However, model size can be compressed through quantization methods while improving inference speed. Here, the high-performance LLM inference library exllamav2 is used to quantize and infer the model using flash_attention features. The author introduces a unique quantization method on the project page, which will not be elaborated here. According to the conversion mechanism, the 70B model can be quantized to a size of 22G at 2.5-bit, allowing it to be easily loaded onto a single graphics card.
1) Testing Method
Given a complex task description not in the training set, while adding functions and corresponding descriptions not included in the training set to the toolkit. If the planner can complete the task splitting, the distributor can call functions, and the solver can summarize the results based on the entire process.
2) Testing Results
Task Splitting: First, use text-generation-webui to quickly test the task splitting model’s effectiveness, as shown in the figure:

Figure 6 Task Splitting Testing Results
A simple RESTful API interface can be written here for easy calls in the agent testing environment (see project code fllama_api.py).
Function Calling: The project has already written a simple planner-distributor-worker-solver logic. Next, let’s test this task. Input a command: what movies did the director of ‘Killers of the Flower Moon’ direct? List one of them and search it in bilibili.
The calling process is as follows:
“Search Bilibili” function is not included in the function calling training set of the project. At the same time, this movie is also a new film that has not yet been released, so it is uncertain whether the model’s training data includes it. It can be seen that the model effectively splits the input command:
-
Search for the director of the movie on Wikipedia
-
Based on the result from step 1, search for the movie Goodfellas on Bing
-
Search for the movie Goodfellas on Bilibili
At the same time, the function calling produced the following results: the click result is Goodfellas, which matches the director of that movie.
Conclusion
This project designs a basic agent process of toolkit-plan-distribute-worker-solver based on the scenario of “inputting a command to automatically achieve complex task splitting and function calling” to create an agent capable of executing primary complex tasks that cannot be completed in one step. Through the selection of base models and lora fine-tuning, low-power conditions can still complete fine-tuning and inference of large models. Finally, through this pipeline, an example of searching for other works of a movie director was realized, achieving basic complex task completion.
Limitations: This article only designed the function calling and task splitting based on a toolkit of search and basic operations. The toolset used is very simple and does not have much design. There was also not much consideration for fault tolerance mechanisms. Through this project, everyone can further explore applications in the RPA field, further improve the agent process, and achieve a higher degree of intelligent automation to enhance process manageability.
Interested in discussing LLM practical findings with “modification professionals” and exploring the best practices for Agent development? Feel free to apply to join the SOTA! model community modification group through the following poster.
