The implementation of a state machine consists of three elements: state, event, and response.
When converted into specific behaviors, it can be summarized in three questions:
-
What happened? -
What state is the system currently in? -
In this state, what should the system do when this event occurs?
1. Switch-Case Method
The states are organized using switch-case, and the events are also organized using switch-case, then one switch-case is nested within each case of the other switch-case.
Program Listing 4:
switch(StateVal)
{
case S0:
switch(EvntID)
{
case E1:
action_S0_E1(); /* Response for event E1 in state S0 */
StateVal = new state value;/* State transition, if not transitioning, this line is omitted */
break;
case E2:
action_S0_E2(); /* Response for event E2 in state S0 */
StateVal = new state value;
break;
......
case Em:
action_S0_Em(); /* Response for event Em in state S0 */
StateVal = new state value;
break;
default:
break;
}
break;
case S1:
......
break;
......
case Sn:
......
break;
default:
break;
}
The above pseudocode example represents a general situation; actual applications are often not this complex. Although there may be many types of events in a system, many of these events may be irrelevant to a particular state.
For example, in Program Listing 4, if E2, …, Em are irrelevant to the system in state S0, then there is no need to write the code for events E2, …, Em under the case for S0; the state S0 only needs to consider the handling of event E1.
Since there is nesting between the two switch-case statements, there is a question of which one nests the other, so there are two writing styles for the switch-case method: state nested events and events nested states. Both styles are valid, each with their advantages and disadvantages, and the choice of which to use is left to the designer based on the specific situation.
One last point to note about the switch-case method is that because the principle of switch-case is to compare from top to bottom, the further down you go, the longer it takes to find the match, so attention should be paid to the order in which states and events are arranged in their respective switch statements. It is not recommended to arrange them in the order shown in Program Listing 4. States and events that occur frequently or have high real-time requirements should be placed as far forward as possible.
2. Table-Driven Method
If the switch-case method is linear, then the table-driven method is planar. The essence of the table-driven method is to solidify the relationship between states and events into a two-dimensional table, treating events as the vertical axis and states as the horizontal axis; the intersection [Sn , Em] represents the system’s response to event Em while in state Sn.
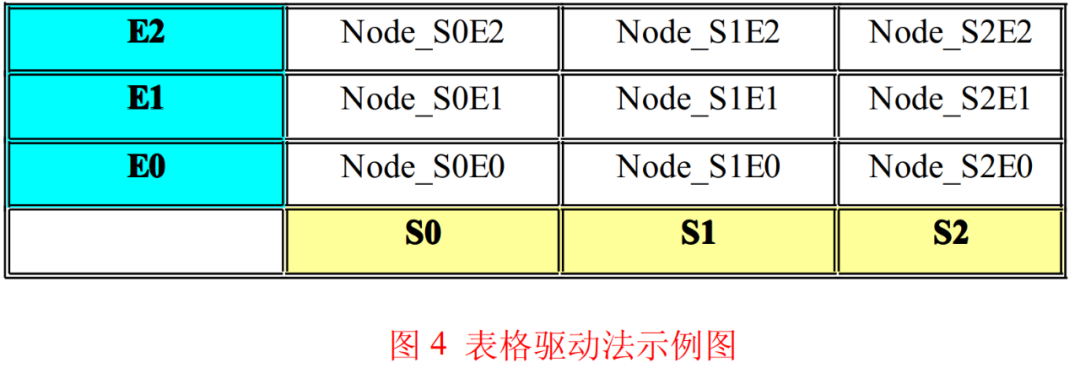
As shown in Figure 4, I refer to the node in the table as a state machine node; the state machine node Node_SnEm is the system’s response to event Em while in state Sn. This response includes two aspects: output actions and state transitions. A state machine node is generally a structure variable similar to that in Program Listing 5.
struct fsm_node
{
void (*fpAction)(void* pEvnt);
INT8U u8NxtStat;
};
This structure in Program Listing 5 has two members: fpAction and u8NxtStat. fpAction is a function pointer pointing to a function with the form void func(void * pEvnt), and this function func standardizes the encapsulation of the action sequence during state transitions.
That is to say, when the state machine transitions states, regardless of how many actions it outputs, how many variables it operates on, or how many functions it calls, all these behaviors are handled by the function func.
After encapsulating the actions, the address of the encapsulated function func is assigned to the function pointer fpAction, so that to output actions, you only need to call the function pointer fpAction.
Now looking at the above func function, we find that it has a parameter pEvnt, which is a pointer of type void *. During the actual execution of the program, it points to a variable that can store the event; through this pointer, we can know all the information about the event, making this parameter quite necessary.
Events generally include two attributes: the type of the event and the content of the event.
For example, in the case of a key press event, we not only need to know that it is a key press event, but also which key was pressed.
The type of the event and the current state of the state machine allow us to quickly locate in the table shown in Figure 4 and determine which action encapsulation function to call. However, to correctly respond to the event, the action encapsulation function also needs to know what the content of the event is, which is the significance of the parameter pEvnt.
Due to the diversity of events, the data format used to store event content may vary, so pEvnt is defined as type void * to increase flexibility.
Regarding fpAction, one last question: if event Em is meaningless for state Sn, what should the fpAction in the state machine node Node_SnEm point to?
My answer is: let it point to a null function! Didn’t we say that doing nothing is also a response?
u8NxtStat stores a state value of the state machine. We know that the state machine responds to events by outputting actions, which means calling the encapsulated function pointed to by the function pointer fpAction. Once the function call is complete and returns to the calling function, the response to the event is considered finished, and the next step is to consider state transitions.
It may either keep the current state unchanged or transition to a new state. How should this choice be made? The state stored in u8NxtStat is the answer that the state machine wants!
The table shown in Figure 4 is reflected in C language code as a two-dimensional array, where the first dimension is the state of the state machine, and the second dimension is the uniformly classified events. The elements of the array are the structure constants from Program Listing 5.
If the table-driven method is used in the program, some special considerations must be taken into account. To treat states as the horizontal axis of the table, the set of state values must meet the following conditions:
-
(1) The set must be an increasing arithmetic integer sequence -
(2) The initial value of the sequence must be 0 -
(3) The common difference of the sequence must be 1
The “event” acting as the vertical axis has characteristics and requirements that are completely consistent with those of the “state” used for the horizontal axis. Among the data types provided by C language, there is no option more suitable than an enumeration constant to meet the above requirements, so I strongly recommend making the set of states and the set of event types into enumeration constants. The advantages of the table-driven method include: unified calling interface and quick positioning.
The table-driven method masks the differences in handling various events under different states, allowing the common parts of the processing process to be extracted and made into standardized framework code, forming a unified calling interface.
Based on the structure of the state machine node in Program Listing 5, the framework code is shown in Program Listing 6.
Looking up the target in the table-driven method is essentially a two-dimensional array addressing operation, so its average efficiency is significantly higher than that of the switch-case method.
Program Listing 6:
extern struct fsm_node g_arFsmDrvTbl[][]; /* State machine driving table */
INT8U u8CurStat = 0; /* Current state temporary storage */
INT8U u8EvntTyp = 0; /* Event type temporary storage */
void* pEvnt = NULL; /* Event variable address temporary storage */
struct fsm_node stNodeTmp = {NULL, 0}; /* State machine node temporary storage */
u8CurStat = get_cur_state(); /* Read current state */
u8EvntTyp = get_cur_evnt_typ(); /* Read current triggered event type */
pEvnt = (void*)get_cur_evnt_ptr(); /* Read event variable address */
stNodeTmp = g_arFsmDrvTbl[u8CurStat ][u8EvntTyp ];/* Locate state machine node */
stNodeTmp.fpAction(pEvnt ); /* Action response */
set_cur_state(stNodeTmp.u8NxtStat); /* State transition */
.....
The table-driven method is excellent, but there are still some small issues with the programs written using it. Let’s first look at the characteristics of the programs written using the table-driven method.
As mentioned earlier, the table-driven method can standardize the state machine scheduling part into a framework code that is extremely versatile; regardless of what application the state machine is used to implement, the framework code does not need to be modified. We only need to plan the state transition diagram according to the actual application scenario and then implement the various elements in the diagram (states, events, actions, transitions, and the relevant “conditions” element will be discussed later) in code. I refer to this part of the code as application code.
In the application code’s .c file, you will see a two-dimensional array declared as const, which is the state-driven table shown in Figure 4, and you will also see many functions that are unrelated to each other, which are the action encapsulation functions mentioned earlier.
This format directly leads to poor code readability issues, as it would be confusing for anyone to understand the code without having a state transition diagram on hand.
If we want to add a new state to the state machine, it would involve adding a new column to the driving table and also adding several new action encapsulation functions.
If the driving table is large, this work can be quite tedious and prone to errors. If one is not careful and fills in the wrong position in the array, the program will run contrary to the designer’s intentions.
It is far less convenient and safe than making changes in the switch-case method. The most significant feature of the Extended State Machine is that before the state machine responds to an event, it first checks conditions, and based on the evaluation results, it chooses which actions to execute and which state to transition to.
In other words, when an event Em occurs in state Sn, the next state to transition to may not be unique. This flexibility is the most valuable advantage of the Extended State Machine.
Looking back at the state machine node structure provided in Program Listing 5, if the system transitions to state u8NxtStat after executing the actions specified by fpAction when event Em occurs in state Sn, the code implementation of the table-driven method does not include the “condition” element of the state machine. ESM, you are so excellent, how could I bear to abandon you?!
Now looking at the example diagram of the table-driven method shown in Figure 4, if we remove the vertical axis representing events from the table and merge one column into one cell, can the issues mentioned earlier be resolved? Indeed! This is the long-lost “Kuwait Flower Manual” — the Castrated Version of the Table-Driven Method!!
The castrated version of the table-driven method, also known as the compressed table-driven method, combines a one-dimensional state table with an event switch-case. The compressed table-driven method uses a one-dimensional array as the driving table, where the index of the array represents the various states of the state machine.
The elements in the table are called compressed state machine nodes, and the main content of the nodes is still a function pointer pointing to the action encapsulation function; however, this action encapsulation function is not prepared for a specific event, but is valid for all events.
In the node, it is no longer mandatory to specify the state to transition to after the output actions of the state machine are completed; instead, the action encapsulation function returns a state, and this state becomes the new state of the state machine.
This characteristic of the compressed table-driven method perfectly solves the issue of the Extended State Machine not being usable in the table-driven method.
The example code in Program Listing 7 contains the structure of the compressed state machine node and the framework code for calling the state machine.
Program Listing 7:
struct fsm_node /* Compressed state machine node structure */
{
INT8U (*fpAction)(void* pEvnt); /* Event handling function pointer */
INT8U u8StatChk; /* State check */
};
......
u8CurStat = get_cur_state(); /* Read current state */
......
if(stNodeTmp.u8StatChk == u8CurStat )
{
u8CurStat = stNodeTmp.fpAction(pEvnt ); /* Event handling */
set_cur_state(u8CurStat ); /* State transition */
}
else
{
state_crash(u8CurStat ); /* Illegal state handling */
}
.....
Comparing with Program Listing 5, we can see the changes made in the struct fsm_node structure in Program Listing 7. First, the form of the function pointed to by fpAction has changed; the action encapsulation function func now looks like this:
INT8U func(void * pEvnt);
The current action encapsulation function func must return a value of type INT8U, which indicates the state to which the state machine should transition. In other words, in the compressed table-driven method, the state machine node does not determine the new state of the state machine; instead, this task is assigned to the action encapsulation function func. The state machine transitions to whatever state func returns.
The new state has changed from a constant to a variable, making it much more flexible. As mentioned earlier, the action encapsulation function func is responsible for all events that occur, so how does func know which event triggered it? Look at the parameter void * pEvnt of func.
In Program Listing 5, we mentioned that this parameter is used to pass event content to the action encapsulation function. However, from the previous description, we know that the memory pointed to by pEvnt contains all the information about the event, including the event type and event content. Therefore, through parameter pEvnt, the action encapsulation function func can still know the type of the event.
The struct fsm_node structure in Program Listing 7 also has a member u8StatChk, which stores a state of the state machine; what is its purpose?
Those who work with C language arrays know to be wary of array index out-of-bounds.
To know, the driving table of the compressed table-driven method is a one-dimensional array indexed by state values. The most important part of the array elements is the addresses of the action encapsulation functions.
Function addresses, from the perspective of microcontrollers, are just segments of binary data, and there is no difference from other binary data in memory. No matter what value is fed into the microcontroller’s PC register, the microcontroller has no objections. Suppose that due to some unexpected reason, the variable storing the current state of the state machine has been altered, causing its value to become an illegal state.
Then, when an event occurs, the program will use this illegal state value to address the driving table, which will lead to memory leaks, and the program will jump to an unknown address in the leaked memory, making it impossible to avoid running amok!
To prevent this phenomenon, the compressed state machine node structure adds the member u8StatChk. The u8StatChk stores the position of the compressed state machine node in the one-dimensional driving table. For example, if a node is the 7th element in the table, then the value of this node’s member u8StatChk is 6.
Looking at the framework code example in Program Listing 7, the program first checks if the values of the current state and the current node’s member u8CurStat are consistent before referencing the function pointer fpAction. If they are consistent, the state is considered valid, and the event is handled normally. If they are inconsistent, the current state is considered illegal, and the program will handle it as an unexpected condition to ensure the program runs safely.
Of course, if the leaked memory data happens to match u8CurStat, then this method would be powerless.
Another method to prevent the state machine from going awry is to use an enumeration for the state variable. The framework code can then determine the maximum value of the state value and check whether the current state value is within the legal range before calling the action encapsulation function, which can also ensure the safe operation of the state machine.
We have already understood the definition form of the action encapsulation function in the compressed table-driven method; what does the function look like? Program Listing 8 provides a standard example.
Program Listing 8:
INT8U action_S0(void* pEvnt)
{
INT8U u8NxtStat = 0;
INT8U u8EvntTyp = get_evnt_typ(pEvnt);
switch(u8EvntTyp )
{
case E1:
action_S0_E1(); /* Action response for event E1 */
u8NxtStat = new state value; /* State transition, even if not transitioning, this line must exist */
break;
......
case Em:
action_S0_Em(); /* Action response for event Em */
u8NxtStat = new state value; /* State transition, even if not transitioning, this line must exist */
break;
default:
; /* Handling unrelated events */
break;
}
return u8NxtStat; /* Return new state */
}
From Program Listing 8, we can see that the action encapsulation function is essentially the specific implementation of the event switch-case. The function determines the event type based on the parameter pEvnt and selects the action response accordingly, determining the state machine’s transition state, and finally returning the new state as the result to the framework code.
With such an action encapsulation function, the application of the Extended State Machine can be completely unrestricted! Thus concludes the introduction to the compressed table-driven method.
I personally believe that the compressed table-driven method is quite excellent; it combines the simplicity, efficiency, and standardization of the table-driven method with the straightforwardness, flexibility, and variability of the switch-case method, allowing them to complement each other and achieve a harmonious balance.
3. Function Pointer Method
As mentioned earlier, there are three main methods for implementing a state machine in C language (switch-case method, table-driven method, and function pointer method), with the function pointer method being the most challenging to understand. Its essence is to treat the function address of the action encapsulation function as the state itself. However, with the groundwork laid by the compressed table-driven method, the function pointer method becomes easier to understand, as both methods are essentially the same.
The essence of the compressed table-driven method is a one-to-one mapping from an integer value (the state of the state machine) to a function address (the action encapsulation function). The driving table of the compressed table-driven method serves as the direct carrier of all mapping relationships. In the driving table, one can find the function address through the state value, and conversely, one can find the state value through the function address.
We can use a global integer variable to record the state value and then look up the driving table to find the function address. Why not simply use a global function pointer to record the state? This is the origin of the function pointer method.
The action encapsulation functions written using the function pointer method are very similar to the example function in Program Listing 8; however, the return value of the function is no longer an integer state value, but the function address of the next action encapsulation function. After the function returns, the framework code stores this function address in the global function pointer variable.
Compared to the compressed table-driven method, the safety of the state machine’s operation is a significant issue in the function pointer method. It is challenging to find a mechanism to check whether the function address in the global function pointer variable is a valid value. If left unchecked, if the data in the function pointer variable is tampered with, it is almost inevitable that the program will go haywire.
4. Conclusion
Having discussed so much about state machines, I believe everyone has already felt the superiority of this tool; state machines are incredibly useful! In fact, what we have been talking about all along is the Finite State Machine (now you know why the code often has the abbreviation fsm!), and there is another type of state machine that is even more powerful and complex than the finite state machine, which is the Hierarchical State Machine (commonly abbreviated as HSM).
In simple terms, a system with only one state machine is called a finite state machine, while a system with multiple state machines is called a hierarchical state machine (this explanation of hierarchical state machines is somewhat imprecise, as parallel state machines also have multiple state machines, but the state machines in a hierarchical state machine have a parent-child relationship, while those in a parallel state machine are at the same level).
The hierarchical state machine is a multi-state machine structure where a parent state machine contains child state machines, incorporating many object-oriented ideas, thus providing it with more powerful functionality. When a problem becomes challenging to solve with a finite state machine, it is time for the hierarchical state machine to step in.
I do not fully understand the theory of hierarchical state machines, so I will not elaborate on it here. You can find some professional books on state machine theory to read. To master state machine programming, understanding state machines (mainly referring to finite state machines) is just the first and simplest step. The more important skill is to use the state machine tool to analyze and dissect actual problems: dividing states, extracting events, determining transition relationships, stipulating actions, etc., forming a complete state transition diagram, and finally optimizing the transition diagram to achieve the best.
Turning actual problems into state transition diagrams completes a significant portion of the work; this is a task that requires the qualities of an architect, while the remaining task of programming according to the state diagram is more characteristic of a programmer.
END
→ Follow to avoid getting lost ←