MultiTalk, open-sourced by Sun Yat-sen University, Meituan, and Hong Kong University of Science and Technology, enables the generation of multi-character dialogue videos. It achieves state-of-the-art performance in synchronizing voice with lip movements and supports interactions between characters, objects, and scenes through prompts.
Related Links
- Homepage: https://meigen-ai.github.io/multi-talk/
- Code: https://github.com/MeiGen-AI/MultiTalk
- Paper: https://arxiv.org/abs/2505.22647
Paper Introduction
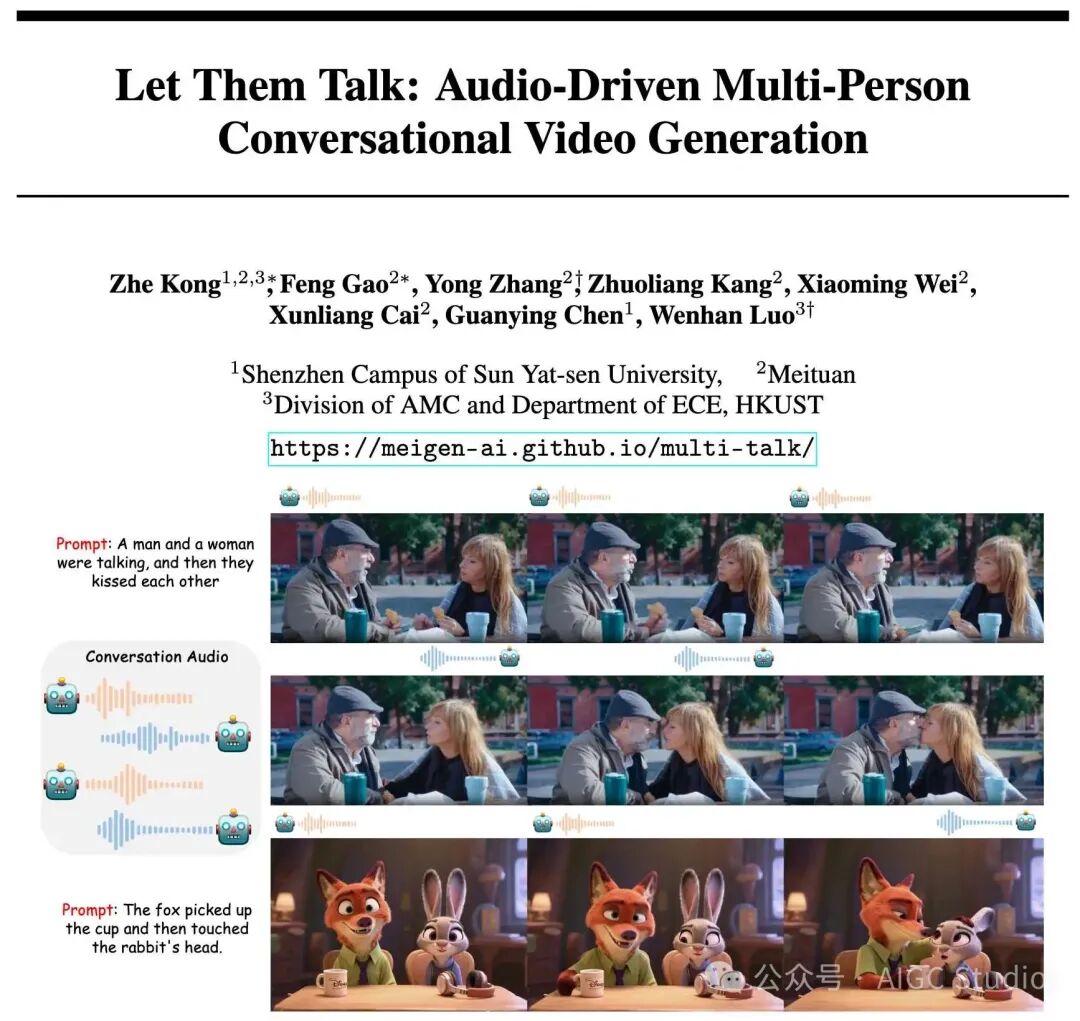
In recent years, audio-driven human animation technology has developed rapidly, from realistic talking heads to full-body motion synchronization, enabling the generation of high-quality single-character videos. However, existing technologies are mostly limited to single-character scenarios and face three major challenges when generating multi-character dialogue videos:
- Multi-audio stream input adaptation: How to distinguish and bind different characters’ audio signals?
- Dynamic character localization: How to accurately locate the movement area of characters when they move in the frame?
- Instruction-following capability: How to ensure that the generated video strictly follows complex actions described in text (such as large body movements)?
Method Overview
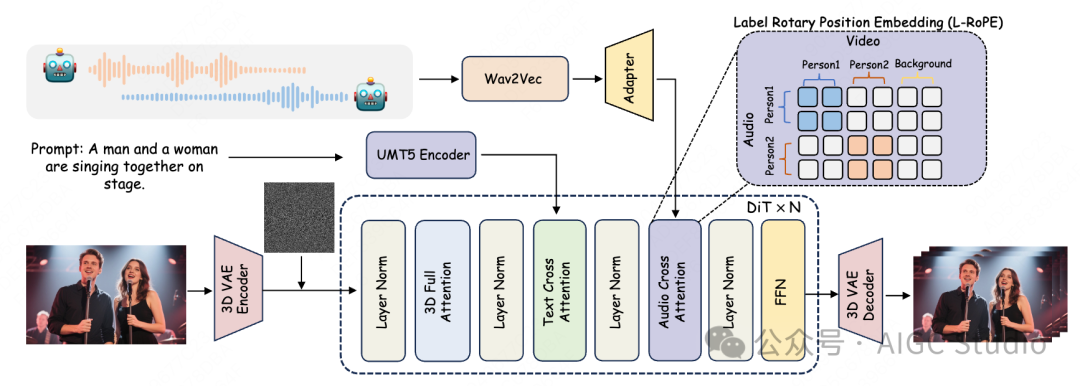
MultiTalk is based on the DiT (Diffusion-in-Transformer) video diffusion model as its core framework. The basic image-to-video (I2V) diffusion model typically does not natively support audio input. To enable the model to “speak,” MultiTalk adds new layers after the text cross-attention layer in each DiT block, which include layer normalization and an audio cross-attention mechanism specifically designed to process and integrate audio conditions.
Traditional methods that directly fuse multiple audio streams can lead to mismatches between characters and audio. MultiTalk proposes Label Rotary Position Embedding (L-RoPE) to achieve precise binding through the following steps:
-
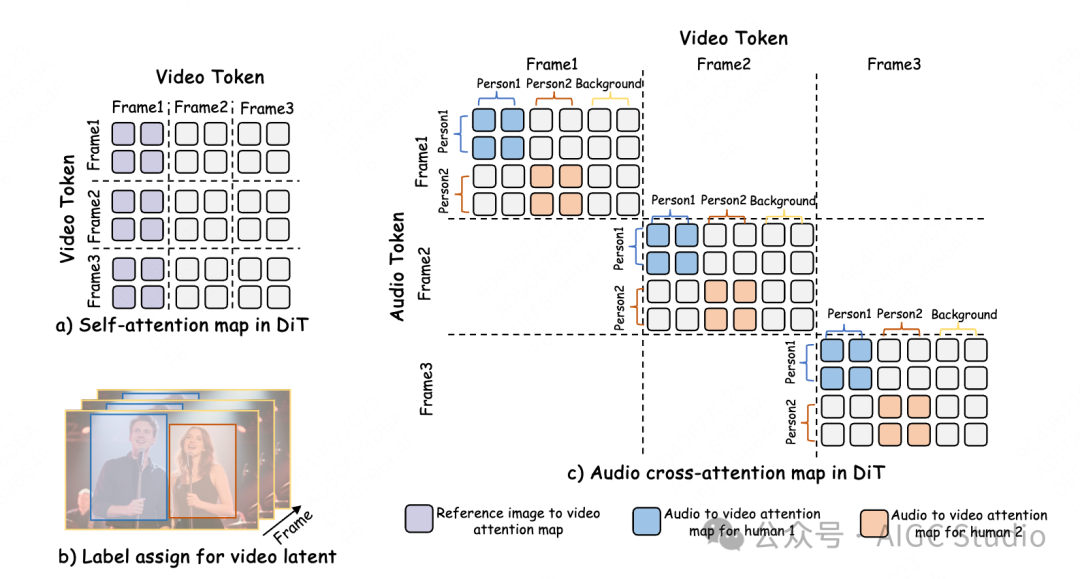
Step 1: Adaptive character localization uses the self-attention map of the reference image to calculate the similarity matrix between character areas and the background, dynamically segmenting video latents into different character areas.
-
Step 2: Label assignment and rotation encoding assign independent numerical range labels to each speaker (e.g., Person1: 0-4, Person2: 20-24) and map these labels to the audio cross-attention layer using rotary position encoding (RoPE). Audio and video areas with the same label will be activated, thus binding audio to the character’s lip movements.
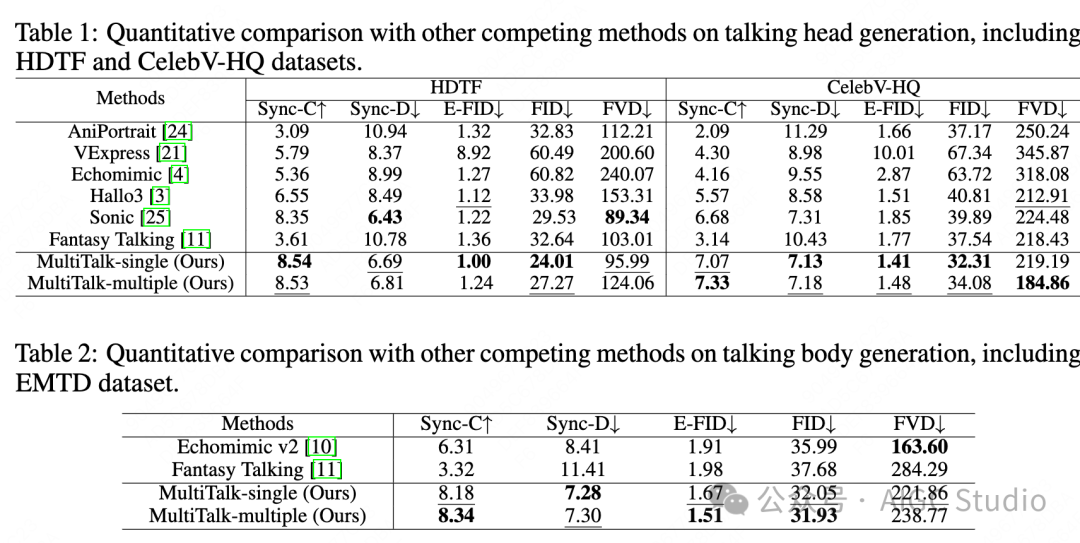
Experimental Results
Conclusion
MultiTalk proposes an audio-driven multi-character dialogue video generation solution, with its core breakthrough being the innovative L-ROPE method, which effectively addresses the challenges of multi-stream audio injection and character binding by combining adaptive character localization and label encoding with category information. Additionally, its carefully designed partial parameter training and multi-task training strategies ensure that the model maintains strong instruction-following capabilities and high-quality visual output even with limited resources. MultiTalk pushes voice-driven animation from single to multi-character scenarios for applications in virtual broadcasting, film production, and more.
Thank you for reading this far, and feel free to click to follow the official WeChat account below and add the assistant to join the official reader group. This is an interesting AIGC WeChat account focusing on AI, deep learning, computer vision, AIGC, Stable Diffusion, Sora, and related technologies. We welcome you to exchange and learn together 💗~