
Does the above description sound familiar? That’s right, recently, the phrase “rewrite in Rust” has been sweeping the entire development field like a pyramid scheme. It is said that currently, 60% to 70% of browser and kernel vulnerabilities are caused by memory defects, so system developers are increasingly inclined to choose memory-safe languages, specifically turning to Rust.
This is because Rust promises to be both fast and safe, capable of implementing necessary abstract types for low-level systems, including interactions with the operating system, low-level memory management, and concurrency. These inherent advantages, coupled with ecosystem tool support, have helped Rust grow and become a favorite among tech giants like Amazon and Google.
Indeed, Rust has many unique advantages, but its types can also be quite painful. If you make a mistake, you may be forced to revert to C, losing the benefits you sought from rewriting.
Many friends are not clear that simply rewriting large C/C++ system components in a memory-safe language will only introduce additional attack surfaces: the external function interfaces (FFI) between new components and existing code. In fact, interacting with Rust can make matters worse. Consider the following C function code:
1 void add_twice(int *a, int *b) {2 *a += *b;3 *a += *b;4 }This part is a bit strange; it performs arithmetic operations in place on integer pointers, so we want to rewrite it in a safer Rust form:
#[no_mangle]pub extern "C"fn add_twice(a: &mut i32, b: &i32) {4 *a += *b;5 *a += *b;6 }Unfortunately, Rust and C make different assumptions about a and b, and calling add_twice(&bar, &bar) from C can lead to undefined behavior. This is because the Rust compiler optimizes add_twice to a += 2*b. (In Rust, a and b cannot have aliases.) Furthermore, this optimization can introduce new memory safety errors. If the C program uses add_twice to update memory-related data (for example, doubling the size of a buffer twice), then the “safe” Rust function is actually worse than the original “unsafe” C function.
This example is worth noting because both the original C code and the Rust code pass their respective compilers without any errors. However, the combined C and Rust code silently invokes undefined behavior, which, depending on the specific architecture, Rust version, and LLVM version, could lead to memory safety issues.
In practice, this problem does not involve human factors and is difficult to prevent.
Essentially, Rust and C/C++ cannot interact directly—they take fundamentally different approaches to types, memory management, and control flow. The result is that if you manually write “glue” code, you may break implicit assumptions (such as calling conventions and data representations), critical invariants (such as memory and type safety, synchronization, and resource handling protocols), and cross language boundaries to introduce undefined behavior errors, such as unwinding panics, integer representation errors, and silently creating invalid values for enums and tagged unions.
In fact, this issue is not only troubling for Rust; FFI is notoriously tricky and prone to errors, and even Rust struggles to “tame” it. This insecurity is actually unavoidable, and developers currently lack the foundational techniques and tools to write safe FFI, so recklessly using Rust to rewrite code may introduce new errors and vulnerabilities.
Next, we will focus on real-world scenarios of rewriting large C/C++ system components in Rust and discuss the new type errors and issues developers may introduce when writing FFI code.
The mismatches between Rust and C often lead to a lot of unsafe code at the FFI boundaries—making it difficult for developers to safely port components to Rust. What’s worse is that even developers who are proficient in Rust and Modula 3 system architecture can hardly avoid these troubles.
Of course, Rust is not unusable; there are extensions like R³ that refine type systems to expand the boundaries of Rust FFI, and the combination of the two is enough to eliminate the various specifications and proof burdens that validation tools bring while almost resolving FFI errors, truly allowing Rust to leverage its memory safety advantages.
In this section, we will specifically explore the security vulnerabilities caused by porting C/C++ components to Rust in real-world scenarios. Since we mainly focus on bugs at the FFI layer, we will not discuss the original bugs in C/C++ code that do not affect the ported code. In other words, we assume that the original code itself meets memory safety requirements and only consider the memory unsafety and undefined behavior that may occur at the FFI layer between the two pieces of code.
We assume that developers are well-intentioned in porting code but may inadvertently pass formatting errors or bugs to the FFI, such as incorrect values for pointers and buffer lengths. Since C/C++ programs and Rust libraries share memory, any incorrect handling of such inputs from the Rust library could trigger memory safety errors throughout the program.
We analyzed the Rust implementations of two network protocol libraries, namely the TLS library rusTLS and the HTTP library Hyper, as well as their FFIs. These libraries and their C bindings are actively developed and are currently integrated into Curl, making them ideal case studies for C-Rust FFI. We also considered some other projects: Encoding_C, a Rust implementation of an encoding standard to replace the C++ implementation in Firefox; Ockam, a secure end-to-end communication library; Artichoke, a Rust implementation of the Ruby language; and several core challenges discovered by the Rust language team.
We categorize the issues in this section into the following types: first, memory temporal safety; secondly, a common error in exception issues—unwinding the stack across FFI boundaries constitutes undefined behavior, which may lead to hard-to-detect severe failures; thirdly, errors related to type safety and Rust’s critical invariants, including aliasing, pointer safety assumptions, and mutability of references. Finally, we will also discuss several other types of undefined behavior.
Rust, C, and C++ have fundamentally different memory management approaches. Rust’s type system statically tracks the lifecycle and ownership of objects, while C requires programmers to manage memory manually, and C++ provides memory-safe abstractions but also allows free mixing with raw pointers.
More importantly, when migrating C/C++ systems to Rust, developers must coordinate these differences through the FFI layer, which can be quite challenging. For example, sharing pointers across FFI boundaries can lead to cross-language memory management issues, where a pointer allocated by one language could be freed by another language. And when C and Rust code try to share memory ownership, the situation becomes even more complicated.
rusTLS allows clients to create certificate validators and share these validators among server configurations. To facilitate sharing, rusTLS uses atomic reference counters (Arc) to represent these validators, allowing the corresponding memory to be automatically reclaimed when no references remain.
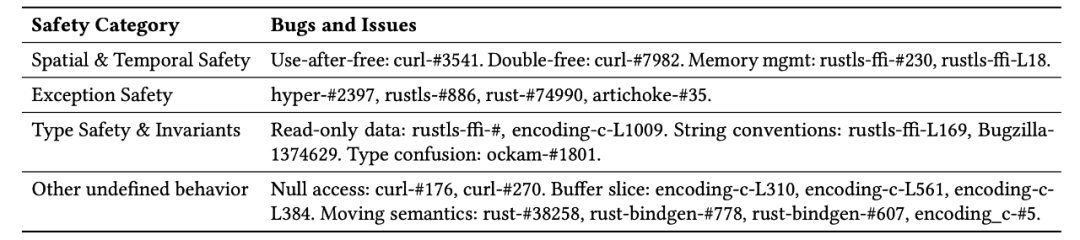
Several types of memory safety issues that may arise when C/C++ interacts with Rust

Figure 1: Examples of security issues in rusTLS FFI functions. Exception safety: (1) If the clone operation exhausts memory, it may trigger unwinding across FFI boundaries. Temporal safety: (2) and (3) may lead to use-after-free and double-free errors due to incorrect function parameters or duplicate function calls.
Since rusTLS exposes pointers to these objects through its FFI, it is necessary to explicitly deallocate them using the rustls_client_cert_verifier_free function in Figure 1. This function reconstructs the Arc reference from the raw pointer in an unsafe manner and immediately removes it, thereby reducing the reference count. More importantly, this function expects the count to be 1 (i.e., the caller’s copy), so if used correctly, this function should remove the object referenced by the pointer simultaneously. However, the caller may misuse this function, such as releasing the same pointer twice or reusing a released pointer, leading to reference count errors and ultimately introducing double-free and use-after-free vulnerabilities in the “safe” part of rusTLS.
Currently, rusTLS cannot detect double-free: reading the count of a “freed” Arc reference will first trigger undefined behavior [rustls-#32]. Moreover, the C implementation of the TLS library may not necessarily rely on specific APIs to release these objects (and their referenced objects) but may simply require the client to use the standard free function. Directly replacing such C implementations with rusTLS can easily lead to cross-language memory corruption and introduce new memory vulnerabilities into the system.
Rust handles unrecoverable errors (usually indicated by the panic! macro or any number of panicking function calls, such as unwrap or integer addition) by unwinding the stack and calling destructors in the process. Note that unwinding across FFI boundaries is considered undefined behavior.
Although there is still debate in the Rust community, FFI should indeed explicitly handle panics to ensure exception safety—ideally, failures should be communicated to the caller. However, Rust does not provide any special support for this, so the actual effect entirely depends on whether the developer enforces safety guarantees in the code.
For example, rusTLS packages error-prone top-level externs using the ffi_panic_boundary! macro (see Figure 1), which captures all unwinding panics and returns default values to the caller. Since many fundamental operations in Rust may cause crashes, it is easy to overlook necessary handling processes. As for explicit bugs, note that the rustls_client_cert_verifier_new in Figure 1 is not exception-safe because cloning the RootCertStore may trigger an unhandled memory shortage panic and unwind across FFI.
Rust code often heavily relies on the invariants guaranteed by the type system to ensure memory safety and code correctness. Since C/C++ programs typically do not follow the same invariants, conflicts may arise when C/C++ interacts with Rust code, especially common after rewriting.
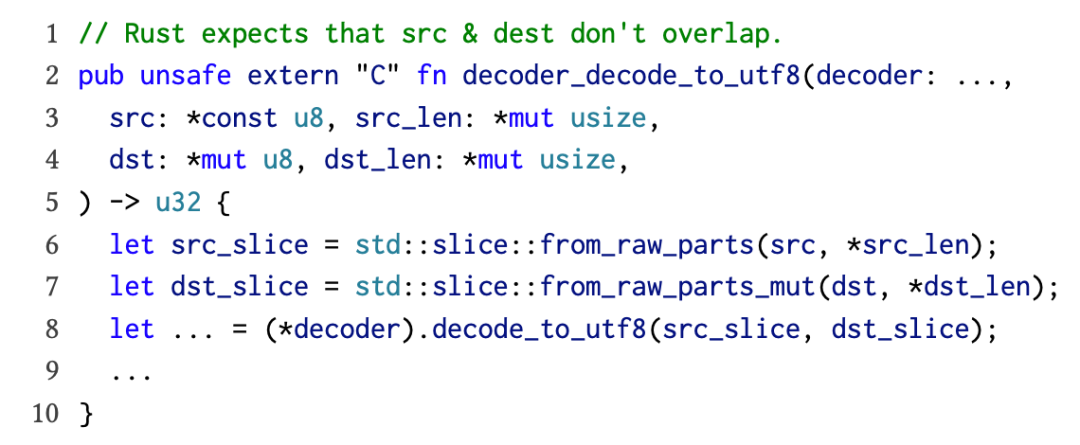
Figure 2: FFI functions from the encoding_c library may be affected by aliasing violations. Rust requires that src_slice and dest_slice cannot have aliases, but the code itself does not check for this.
The decode_to function (see Figure 2) decodes the contents of an immutable slice into a mutable slice. Rust’s aliasing rules ensure that these slices do not alias, allowing for compilation optimization. However, when reconstructing slices through unsafe functions fram_raw_parts and from_raw_parts_mu, decoder_decode_to_utf8 does not check or guarantee these conditions. The packager replaces the buffer slices with C-compatible equivalent types (i.e., raw pointers and their lengths), leading to type aliasing. This may trigger undefined behavior in Rust FFI and unreasonable optimizations in LLVM.
There are also some more “fantastical” undefined behaviors, mainly involving the details of different languages and the special conventions of the architecture ABI (Application Binary Interface).
-
Glue Code. A common issue in the examples discussed above is that glue code needs to use unsafe APIs to reconstruct Rust abstractions. The existence of unsafe functions shifts the safety responsibility from the compiler to the developer, requiring these interfaces to be redesigned independently of the application to meet key assumptions that must be included within the interface. However, most of these assumptions (such as pointer lifetimes, ownership, and boundaries) cannot be validated at runtime, and Rust does not provide the necessary constructors for checking, so FFI functions implicitly trust the caller and assume the input is valid. But this trust is clearly unfounded: FFI represents the boundary between safe Rust components and abstract/untrusted code. Thus, caller code can easily pass invalid inputs and easily undermine Rust’s safety guarantees. This not only undermines the safety protection significance of Rust rewrites but also creates ideal conditions for cross-language attacks.
-
ABI Compatibility. ABI-level optimizations can also cause issues in C/C++/Rust systems, where components are compiled using different compilers and potentially incompatible optimization methods. For example, in a 64-bit architecture, a compiler may pack consecutive 32-bit function parameters into the same 64-bit register to reduce register pressure. However, if the corresponding compilers do not pack function inputs in the same way, cross-language function calls may lead to undefined behavior. For instance, although C’s size_t and Rust’s u32 types are both 32 bits, only the C compiler can pack both simultaneously; rustc cannot.
In summary, as Rust code becomes more prevalent, interactions between other languages and Rust will also create new attack surfaces, and the Rust FFI code we write manually is likely to introduce memory safety vulnerabilities. We hope for better methods and tools to help developers write safe FFI code, truly fulfilling the safety guarantees and promises made by the Rust language.
Original link:
https://goto.ucsd.edu/~rjhala/hotos-ffi.pdf
Disclaimer: This article is a translation by InfoQ and reproduction is prohibited without permission.
Funding without even writing code: The vector database ignited by ChatGPT brings a wave of wealth myths.
The “2023 Comprehensive Capability Assessment Report of Large Language Models” is out: domestic products represented by Wenxin Yiyan are about to break through the encirclement.
Free version of “Github Copilot”, programming capabilities doubled?! Google takes on Microsoft with a brand new Colab programming platform.
Baidu responds to Bing becoming the number one desktop search in China; Alibaba responds to rumors of mass layoffs; Wenxin Yiyan’s market head angrily retorts to iFLYTEK | Q News
🔥 Recently, intelligent products and technologies have attracted much attention from developers. How can developers grasp the pulse of the times and keep up with the new wave? On June 15 at 13:00, the hot topic of intelligent technology will be the protagonist of Microsoft Build. If you want to hear Microsoft leaders’ outlook on the next generation of intelligent technology and meet community leaders and technical experts in person, the registration channel is now open. Click 【Read the Original】 or scan the code to register and grab your spot!
