Click belowCard, follow the “Embodied Intelligence Heart” public account
Editor | Embodied Intelligence Heart
This article is for academic sharing only. If there is any infringement, please contact us to delete the article.
>>Click to enter→Embodied Intelligence Heart Technical Exchange Group
For more valuable content, welcome to join the first full-stack learning community of embodied intelligence in China:Embodied Intelligence Heart Knowledge Planet(Click me), this contains everything you want.
Introduction & Starting Point
DiVLA, a novel framework that seamlessly combines autoregressive models with diffusion models for learning visual motion strategies. The core of the method is a next-token prediction objective that enables the model to effectively reason about user queries in the context of current observations. An additional diffusion model is attached to generate robust action outputs. To enhance policy learning through self-inference, a novel inference injection module is introduced that directly integrates inference phrases into the policy learning process. The entire framework is simple, flexible, and easy to deploy and upgrade.
Extensive experiments were conducted using multiple real robots to validate the effectiveness of DiVLA. The tests included a challenging factory sorting task, where DiVLA successfully classified objects, including those not seen during training. We observed that the reasoning module improved interpretability, allowing observers to understand the model’s thought process and identify possible reasons for policy failures. Additionally, DiVLA’s performance was tested on zero-shot grasping tasks, achieving an accuracy of 63.7% when tested on 102 unseen objects. Our method demonstrated robustness to visual variations, such as distractions and new backgrounds, and easily adapted to new entity forms. Furthermore, DiVLA could follow new instructions while maintaining conversational ability. Notably, DiVLA excelled in data efficiency and reasoning speed. Our smallest DiVLA-2B model runs at 82Hz on a single A6000 GPU, and for complex tasks, it can train from scratch in less than 50 demonstrations. Finally, the model was scaled from 2B parameters to 72B parameters, showing improved generalization capabilities with increased model size.
The content is from the first full-stack learning community of embodied intelligence in China:Embodied Intelligence Heart Knowledge Planet, which contains everything you want.
Background and Problems Addressed
Autoregressive models dominate large language models, operating by sequentially predicting discrete tokens, where each token’s generation depends on previous tokens. This approach has also impacted robotics, driving the development of visual-language-action (VLA) models that frame action prediction as a next-token prediction task. Despite significant successes with models like RT-2 and OpenVLA, they face inherent limitations. Firstly, discretizing continuous action data into fixed-size tokens disrupts the coherence and precision of actions. Secondly, next-token prediction (NTP) is inherently inefficient in action generation, especially in real-time robotic applications where performance is critical.
Meanwhile, the success of diffusion models in content generation has garnered immense attention over the past two years for learning visual motion strategies. Many methods have demonstrated strong performance in manipulation tasks by modeling action sequence generation as a denoising process. Compared to NTP-based VLA models, this approach captures the multimodal characteristics of robot actions better and achieves faster sequence generation. However, despite the advantages of diffusion models in policy learning, they lack the reasoning capabilities crucial for effectively solving complex tasks, which is a significant component that has notably enhanced the performance of large language models (LLMs).
This prompted us to ask: can we combine the advantages of both, particularly the reasoning capabilities of autoregressive models and the robustness of diffusion models in high-frequency action generation? This study proposes a unified model named DiffusionVLA (DiVLA), which integrates autoregressive and diffusion models. The autoregressive part is responsible for handling the reasoning of queries, while the diffusion model controls the robot. DiVLA builds on pre-trained visual-language models (VLMs), retaining their autoregressive reasoning capabilities based on text. We extend this foundation by integrating a diffusion model that promotes learning robot actions through a denoising process, enabling DiVLA to achieve language-driven reasoning and robust action generation in robotic environments. However, merely combining these elements does not fully unleash the potential of reasoning, as there often exists an implicit gap between logical reasoning and executable robotic policies. To bridge this gap, we propose an inference injection module that reuses inference outputs and directly embeds them into the policy head, thereby adding explicit reasoning signals to the policy learning process. This innovation enables us to directly integrate reasoning into action generation, enhancing the model’s flexibility, robustness, and generalization capabilities across various scenarios. Experiments confirm that DiVLA has the following advantages:
-
Fast reasoning speed: DiVLA-2B achieves a reasoning rate of 82Hz on a single A6000 GPU, while DiVLA-7B runs at 42Hz, ensuring real-time responses in high-demand environments. -
Enhanced visual generalization capabilities: DiVLA is unaffected by visual distractions or novel backgrounds, exhibiting strong robustness in visually dynamic environments. -
Generalizable reasoning abilities: DiVLA can accurately identify and classify previously unseen objects, demonstrating its ability to generalize reasoning on new inputs. -
Adaptability to novel instructions and conversational ability: The method can interpret and execute complex, novel instructions while maintaining conversational fluidity, offering a multifunctional range of responses in interactive scenarios. -
Generalization to other entities: DiVLA can be easily fine-tuned and deployed on real dual-arm robots, achieving high performance with minimal adjustments, demonstrating its adaptability across different robotic entities. -
Scalability: A range of scalable models are provided—DiVLA-2B, 7B, and 72B—demonstrating that as the model size increases, generalization capabilities and performance improve, aligning with established scaling laws.
We believe that DiVLA offers a new perspective for learning and promoting robotic strategies.
Some Related Works
Autoregressive models. Due to their success in training language models, predicting the next token has long been viewed as a key pathway to general artificial intelligence. RT-2 was the first to apply next-token prediction to robotic learning by predicting actions by converting continuous actions into discrete tokens, thus learning robot motions. Building on this, OpenVLA introduced an open-source, improved, and more compact version of RT2, employing a similar approach, while ECoT developed a chain-of-thought method. However, research indicates that next-token prediction may not be the optimal method for robotic models, especially when adapting to various entities. In this study, we specifically leverage the advantages of next-token prediction in reasoning tasks.
Diffusion models. Diffusion models have become mainstream in the field of visual generation. Diffusion Policy extends the application of diffusion models to robotic learning, demonstrating their effectiveness in handling multimodal action distributions. Subsequent work has improved Diffusion Policy by applying it to 3D environments, scaling it up, enhancing efficiency, and introducing architectural innovations. For instance, TinyVLA combines diffusion models with lightweight visual-language models, while pi0 utilizes flow matching rather than diffusion to generate actions. Our approach introduces reasoning— a key element in language models—into diffusion-based visual-language-action (VLA) models.
Robotic foundation models. Existing work utilizes reinforcement learning (RL) and large language models (LLMs) to decouple multimodal understanding and embodied control. Another research direction employs pre-trained visual-language models (VLMs) and fine-tunes them directly on robotic data. Our work follows this approach, unifying autoregressive and diffusion models for reasoning and manipulation tasks.
Unified autoregressive models and image generation. Recent work has focused on combining multimodal understanding with image generation, including efforts to generate images using autoregressive methods, utilize diffusion models for text generation, or combine both methods into a unified model, such as Show-O, Transfusion, and Vila-U. Unlike these methods, our framework explores the combination of next-token prediction with diffusion models to enhance the reasoning capabilities of robotic models. This reasoning capability, in turn, improves the model’s generalization ability across various tasks and environments.
Detailed Explanation of the Diffusion-VLA Method
Our ultimate goal is to create a unified framework that combines autoregressive models proficient in predicting language sequences for reasoning with diffusion models that are highly effective in generating robotic actions. Developing such an integrated model poses significant challenges, with key issues focusing on: (i) designing an architecture that seamlessly and efficiently integrates autoregressive and diffusion mechanisms; (ii) leveraging self-generated reasoning to enhance action generation without increasing the computational overhead of reasoning.
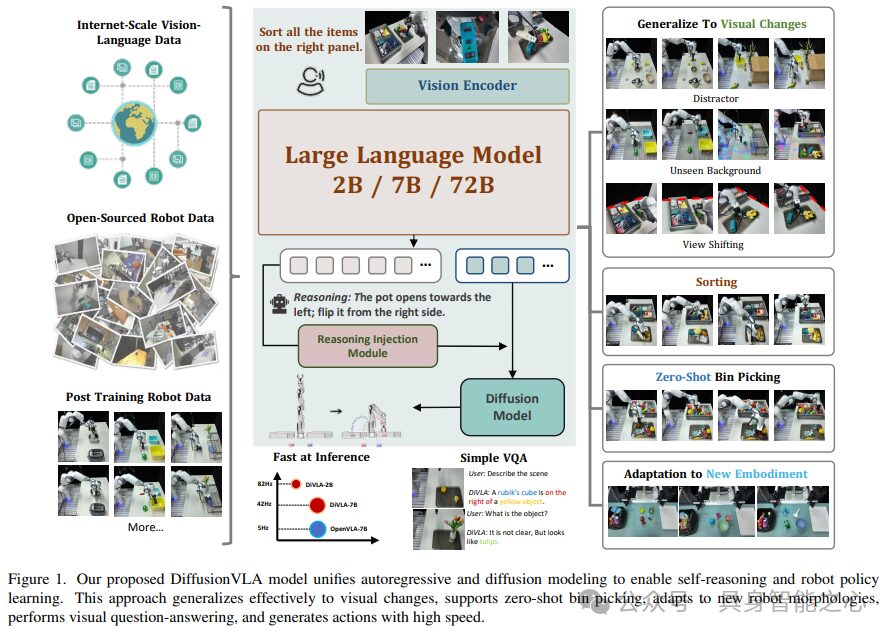
Network Architecture
Given any sequence composed of interleaved images, text, and videos, the images are first encoded into dense visual features using SigLIP. These encodings are then transformed into a fixed number of N visual embeddings via a Transformer. Notably, typical visual inputs in robotic learning often include multiple camera perspectives. To address this issue, a shared SigLIP visual backbone network is applied to each perspective, and the generated visual tokens are concatenated.
For visual language processing, we utilized Qwen2-VL, a state-of-the-art visual language model that offers three scales: 2 billion, 7 billion, and 72 billion parameters. The backbone network of the visual language model (VLM) was initialized using publicly released checkpoints.
Additionally, any other pre-trained VLM can be used as the backbone network, as we decoupled visual language understanding from action generation, making the overall architecture flexible and adaptable to advanced new models.
Action Decoder. A latent diffusion model is employed to decode visual instructions into actions. Specifically, a large language model (LLM) generates a set of tokens, which are then input as conditional inputs to the diffusion model for action decoding. Our architecture follows the design of the standard diffusion policy (Diffusion Policy), with the model weights randomly initialized. This component also incorporates reasoning from the large language model. At the bottom of the action decoder, a multi-layer perceptron (MLP) layer is connected to predict the robot’s joint space. If multiple entities evolve, a separate action decoder is not copied; instead, a new MLP layer is simply initialized for training and evaluation. This step ensures that knowledge acquired from pre-training data is retained, allowing for rapid adaptation to new entities.
Inference Injection Module. The core of our method lies in introducing explicit reasoning into the visual-language-action (VLA) model. Unlike most autoregressive VLA models that require recursive setups (i.e., converting reasoning outputs into inputs for subsequent model runs), our approach proposes a more efficient and seamless integration of reasoning. By directly embedding reasoning into the policy model, we avoid the computational and operational complexities of iterative input-output loops, achieving faster and more seamless reasoning integration.
The inference injection module operates by obtaining the final embeddings of the tokenized outputs from the reasoning component and directly injecting them into the policy model through feature linear modulation (FiLM). This injection technique is inspired by methods in RT-1 and YAY, allowing us to adjust the layers of the policy network based on reasoning signals. We refer to this process as “injection” because, in design, the policy network primarily focuses on action-specific tokens, while the reasoning module serves as an auxiliary enhancement, providing contextual depth without dominating the primary decision-making process. This approach ensures that reasoning is not only present in the training of the policy model but is actively utilized.
Model Design Choices
View-Adaptive Tokenization. Since robotic policy learning experiments typically use multiple camera views, the number of visual tokens increases with the number of views, leading to significant computational overhead due to the complexity of self-attention mechanisms. To address this issue, we propose a view-adaptive tokenization method that reduces the number of visual tokens, thereby optimizing computational efficiency.
The method is simple yet effective: it significantly reduces the number of tokens from the wrist camera view to only 16, which is more than 20 times fewer than the number of tokens from external views. This reduction is based on the unique role of the wrist camera, which primarily assists in the precise positioning of grasping tasks. While high-resolution processing of the wrist view is detailed, it is often inefficient, consuming resources that could be better allocated to processing more critical visual signals from external perspectives.
This optimization is particularly beneficial in dual-arm robotic systems, as both wrist cameras work simultaneously. By reducing the computational load associated with the wrist view, we free up resources to handle other important tasks, allowing for smoother and more efficient operations and potentially improving the overall responsiveness and accuracy of the robotic system.
Training Objective. Given a batch of input sequences, the overall training loss is set as a combination of diffusion loss and next-token prediction loss: , where α is a hyperparameter used to weigh the contribution of each loss term. In our observations, the magnitude of the is consistently about ten times smaller than Ldiff. To balance the contribution of each component to the overall loss, α is typically set to 1 in all experiments. This adjustment ensures that the weights of the two losses are comparable during training, allowing the model to learn effectively from both the action and next-token prediction tasks.
Pre-training Data. Consider using the OXE and Droid datasets for pre-training. The Droid data is used to pre-train DiVLA-2B and DiVLA-7B. For DiVLA-72B, both OXE and Droid are used for pre-training. The original Droid data only contains robotic actions, some paired with observations and language instructions. These data only contain robotic actions, some paired with observations and language instructions. To enhance the model’s generalization capabilities in language, GPT-4o is used to automatically convert these data into forms that include reasoning. Thus, the network architecture remains consistent during pre-training and fine-tuning phases.
Experimental Analysis
Here, we evaluate the effectiveness of DiVLA in embodied control. In a standard multi-task setting, DiVLA was compared with other state-of-the-art models, assessing its performance in both in-distribution and out-of-distribution scenarios. DiVLA was evaluated through a challenging sorting task, demonstrating its superior performance and illustrating how reasoning capabilities enable the model to analyze robotic actions and accurately sort items. Next, DiVLA’s astonishing generalization ability was showcased in zero-shot grasping tasks involving over 102 unseen targets. Finally, DiVLA’s adaptability to new embodied forms was demonstrated, successfully completing complex tasks requiring dual-hand coordination.
Experimental Setup Explanation
Implementation details and pre-training data. The model is pre-trained on the Droid dataset. Then, similar to the setup of π0, the model is fine-tuned on evaluation tasks. LoRA is used to fine-tune the visual language model (VLM). During the pre-training phase, a fixed learning rate of 2e-5 is used.
Fine-tuning Data. Here, we explore four experimental settings: sorting, grasping, multi-task learning, and table cleaning. The first three settings use the Franka robot, while the table cleaning task uses the dual-arm AgileX robot. The datasets include 500 sorting task trajectories and 580 multi-task learning trajectories. The grasping task is designed as a zero-shot task, so no training data was collected for it. For the table cleaning task, we collected 400 trajectories where objects were randomly placed on the table, often overlapping with each other. During the fine-tuning phase, all data corresponding to the same embodied form are trained together. For example, sorting and multi-task data are merged for training purposes.
Real-World Multi-Task Learning
Starting from a standard setting, where the model is trained on multiple tasks and completes each task based on different user queries. We designed five tasks: selecting objects, flipping vertically placed pots, placing cubes into designated boxes, placing cups on plates, and putting cubes into boxes.
Our method was compared with Diffusion Policy, TinyVLA, Octo, and OpenVLA. Note that both Octo and OpenVLA were pre-trained on OXE, which is 25 times larger than our pre-training dataset.

Generalization capabilities to visual changes. To evaluate the model’s robustness and adaptability in diverse, dynamic environments, further evaluations were conducted under multi-task settings, introducing visual changes. We designed three challenging scenarios to test the model’s ability to handle visual changes: 1) introducing additional distractors in the surrounding environment to increase visual clutter and complexity; 2) changing backgrounds to test the model’s adaptability to scene context changes; 3) implementing color lighting effects to introduce different lighting and tones. Figure 5 illustrates these scenarios to show the impact of each change on the visual environment. Experimental results are referenced in Table 1.
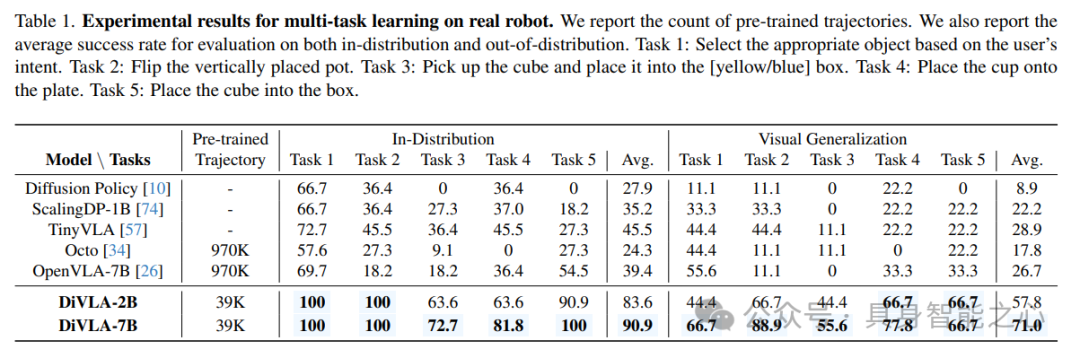
Evaluations of these scenarios indicate that while all methods experienced performance degradation due to these visual changes, our method consistently maintained the highest average success rate across five different tasks. This result highlights the model’s inherent robustness and adaptability, despite not employing any specific data augmentation techniques during training.
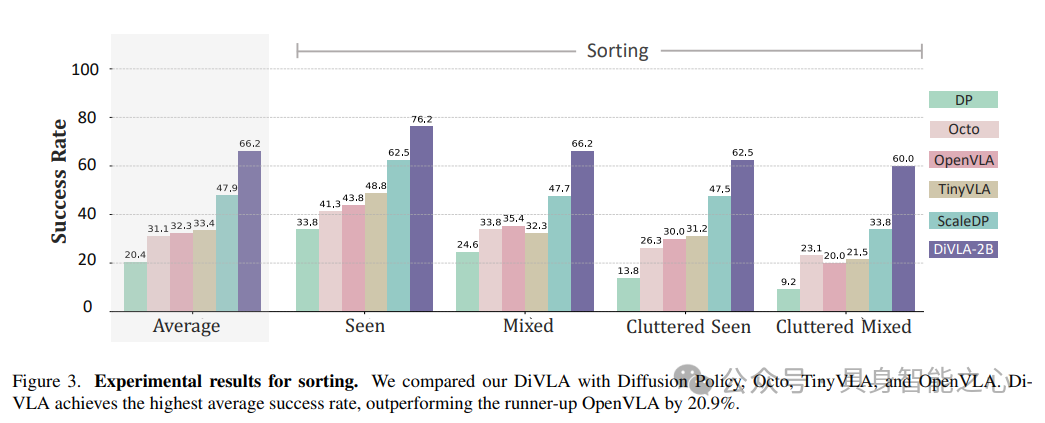
End-to-End Sorting on Real Robots
DiVLA’s capabilities were evaluated in an industrial environment, where robots needed to sort items into designated areas within a large box based on object categories.
Specifically, items were categorized into four classes: (1) toy cars, (2) knitted gloves, (3) plush toys, and (4) hex wrenches. The provided language instruction was “Sort all items into the corresponding areas.” A total of 500 trajectories were collected as training data, and the task was considered successful only when the robot successfully grasped an object and placed it in the correct area. The experimental setup is illustrated in Figure 2.

This task posed multiple challenges, requiring both precise grasping of objects and accurate identification of categories. We evaluated our method under two difficulty settings: simple and difficult. In the simple mode, fewer than 5 items were placed on the table, while in the difficult mode, 6 to 11 items were randomly arranged. Additionally, these scenes included both seen and unseen objects. In cluttered scenes, objects may overlap or be randomly distributed on the table, increasing the complexity of the sorting task.
Experimental results are shown in Figure 3. In all experimental settings, DiVLA demonstrated robust performance, achieving an average success rate of 66.2%. As the complexity of the scenes increased (i.e., the number of objects and clutter level increased), the performance of other methods significantly declined, particularly in highly cluttered mixed scenes, where the success rate of DP plummeted to 9.2%, while DiVLA still maintained a high success rate of 60%. This consistently stable performance underscores our method’s capability in handling complex and dynamic real-world scenarios.
Diagnosing the policy model by examining reasoning. Our model can generate outputs with natural language reasoning, enabling us to understand what the model is “thinking” by observing its reasoning phrases. For example, as shown in Figure 6, the model identifies a toy car and decides to pick it up. If we intervene and place a hex wrench in the gripper, the reasoning phrase changes from “grab the toy car” to “grab the hex wrench,” allowing the model to adapt and accurately sort the items. This dynamic reasoning enhances the model’s decision-making process, making it more transparent and interpretable. The inference injection module also benefits from self-correcting reasoning, making the robot’s actions more robust.

Identifying and sorting unseen objects. We observed that the model could recognize unseen objects by name. When we placed four previously unseen objects on the plate—a plush toy cat, a pair of green gloves, a dark toy car, and a screwdriver—the model successfully identified the first two objects as “brown toy cat” and “green gloves,” and sorted them correctly. For the remaining two unidentifiable objects on the right side, the model labeled them as “black object” and “that object.” Although it failed to sort these unidentifiable items, our model still demonstrated generalization capabilities in recognizing objects and effectively translating these recognition results into appropriate actions.
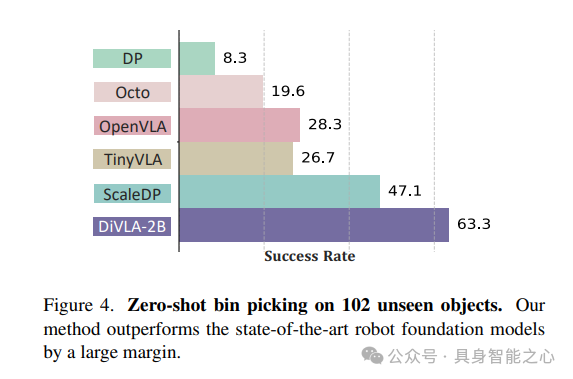
Zero-Shot Grasping of Unseen Objects (Zero-Shot Bin Picking)
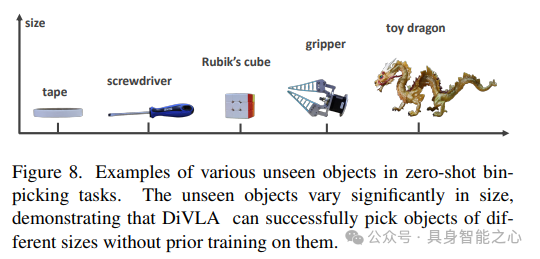
Here, we evaluated DiVLA’s instance generalization capabilities, focusing particularly on the bin picking task—a standard benchmark for assessing robotic model performance. In the evaluation, 102 unique objects were used, none of which were included in the training data, with some objects shown in Figure 7.

We modified the task instruction to “Move any object from the right panel to the left basket.” Figure 2 (right) illustrates the experimental setup, while Figure 7 showcases some of the objects used in this test. The challenge of this evaluation lies in the significant differences between the objects, which include not only size differences but also variations in color patterns, textures, and degrees of deformation. This diversity aims to simulate real-world scenarios where robots must adapt to various unpredictable objects. Figure 8 provides examples of five different-sized objects used in this experiment.
Experimental results are shown in Figure 4. DiVLA achieved a success rate of 63.7%, whereas the success rates for Diffusion Policy, Octo, TinyVLA, and OpenVLA were 8.9%, 19.6%, 23.5%, and 28.4%, respectively. These results indicate that DiVLA exhibits strong adaptability across a wide range of object shapes and sizes, while other models often fail due to reliance on specific object features that may not generalize well to new instances. This underscores DiVLA’s potential applications in dynamic, unstructured environments where robots encounter unfamiliar objects and must perform tasks with minimal human intervention.
Adapting to Real-World Dual-Arm Robots
Here, we investigated DiVLA’s adaptability to dual-arm robots. Inspired by π0, we designed a table cleaning task that involves clearing various items placed on the table. This task has been adjusted for dual-arm robot setups: all tableware should be placed on the left panel, while trash items should be disposed of in the right trash bin. Similar to the previous factory sorting task, the model’s performance was evaluated using a combination of seen and unseen objects. The environmental setup and all objects used for training and evaluation are illustrated in Figure 9. The evaluation included twelve trials, in each of which three to five objects were randomly placed on the table. The success rate was calculated based on the number of correctly placed objects.

Experimental results indicate that when objects appear in the training data, our model can successfully complete the task in most cases, achieving an average success rate of 72.9% for seen objects. In contrast, the success rates for Diffusion Policy and OpenVLA were 45.8% and 0%, respectively. For tasks involving both seen and unseen objects, DiVLA achieved a success rate of up to 70.8%, showing only a slight decrease compared to tasks involving only seen objects, but demonstrating significant generalization capability for objects of different colors and shapes. Finally, DiVLA demonstrated the ability to recognize unseen objects, particularly by sensitively responding to the color of the objects. For example, it classified a can of Sprite as a “green can” and correctly placed it in the trash bin. This observation further supports the notion that reasoning aids generalization.
Following New Instructions
We tested the model with four objects: 1) a watermelon, 2) a cup of lemonade, 3) a piece of blue waste paper, and 4) a red chili pepper. This is a highly challenging task as these new instructions are neither in the Droid dataset nor in our collected data. We evaluated the four new instructions, and the results are summarized in Table 2.
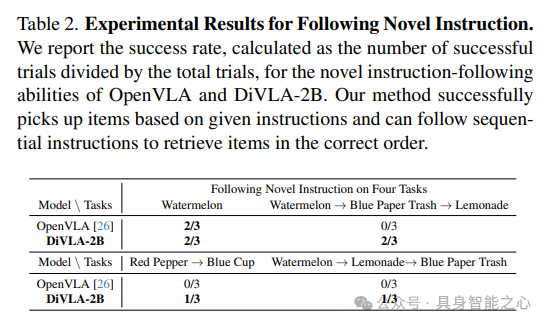
Research findings indicate that both OpenVLA and DiVLA2B can recognize these unseen objects and perform basic pick-and-place tasks. However, when handling complex sequential tasks, OpenVLA fails to accurately interpret the instructions and randomly selects items. In contrast, our method can correctly follow the instructions and pick up items in the specified order. We hypothesize that by learning to decompose long tasks into subtasks, our method gains a generalization capability for understanding complex, multi-step instructions. While OpenVLA can execute simple commands like “pick up the watermelon,” it struggles with more advanced instructions that require selecting items in a specific order. Additionally, we observed that when the model processes new instructions, grasping accuracy declines, indicating that the novelty of the instructions adds extra complexity to task execution.
References
[1] Diffusion-VLA: Scaling Robot Foundation Models via Unified Diffusion and Autoregression.
【Embodied Intelligence Heart】 Technical Exchange Group

【Embodied Intelligence Heart】 Knowledge Planet
Embodied Intelligence Heart Knowledge Planet is the first developer community for embodied intelligence in China, and also the most professional and largest communication platform, with nearly 1000 people. It mainly focuses on embodied intelligence-related datasets, open-source projects, embodied simulation platforms, large models, visual language models, reinforcement learning, embodied intelligence perception localization, robotic arm grasping, pose estimation, policy learning, wheeled + robotic arm, biped robots, quadruped robots, large model deployment, end-to-end, planning and control and other directions. The planet has summarized nearly 40+ open-source projects, nearly 60+ embodied intelligence-related datasets, industry-leading embodied simulation platforms, full-stack learning routes for reinforcement learning, embodied intelligence perception learning routes, embodied intelligence interactive learning routes, visual language navigation learning routes, tactile perception learning routes, multi-modal large model understanding learning routes, multi-modal large model generation learning routes, applications of large models and robots, robotic arm grasping pose estimation learning routes, policy learning routes for robotic arms, biped and quadruped robot open-source solutions, embodied intelligence and large model deployment and other directions, covering all mainstream directions of embodied intelligence today.
Scan to join the planet and enjoy the following exclusive services:
1. Be the first to grasp academic progress and industrial application related to embodied intelligence; 2. Exchange work and job-related questions with industry leaders; 3. A good learning and communication environment to meet more peers in the same industry; 4. Recommendations for job positions related to embodied intelligence, connecting enterprises in real-time; 5. Industry opportunity exploration, investment, and project docking;
