On December 24, a paper from East China Normal University, Midea Air Conditioning, and Shanghai University titled “Diffusion-VLA: Scaling Robot Foundation Models via Unified Diffusion and Autoregression” was published.
DiVLA is a framework that seamlessly combines autoregressive models with diffusion models to learn visual motion strategies. The core of the method is the prediction of the next token, enabling the model to effectively reason about the user’s query in the context of the current observation. Subsequently, an additional diffusion model is introduced to generate robust action outputs. To enhance strategy learning through self-reasoning, a reasoning injection module is introduced, which integrates reasoning phrases directly into the strategy learning process. The entire framework is simple, flexible, and easy to deploy and upgrade.
Extensive experiments with multiple real robots validate the effectiveness of DiVLA. The tests include a challenging factory classification task, in which DiVLA successfully classified targets, including those not seen during training. The reasoning module enhances interpretability, allowing observers to understand the model’s thought process and identify potential reasons for strategy failures. Furthermore, DiVLA was tested on a zero-shot picking task, achieving an accuracy of 63.7% on 102 previously unseen targets. The method demonstrates strong robustness to visual variations (e.g., distractors and new backgrounds) and can easily adapt to new instances. Additionally, DiVLA can follow new instructions and maintain conversational abilities. Moreover, DiVLA is data-efficient and has fast reasoning speeds. Finally, the model scales from 2B to 72B parameters, improving generalization capabilities with the increase in model size.
Autoregressive models dominate in large language models, operating by sequentially predicting discrete tokens, where the generation of each token relies on the previous one. This approach has also impacted robotics, leading to the development of visual-language-action (VLA) models that treat action prediction as a next-token prediction (NTP) task. Although these models (i.e., RT-2 [9] and Open-VLA [26]) have achieved significant success, they face inherent limitations. Firstly, discretizing continuous action data into fixed-size tokens disrupts the coherence and precision of actions. Secondly, NTP is inherently inefficient for action generation, especially in real-time robotic applications where performance is crucial.
Autoregressive models. Predicting the next token has been viewed as a key method for achieving general artificial intelligence, as it has succeeded in training language models [1, 4, 47–49]. RT-2 [9] was the first to apply next-token prediction to robotic learning, predicting actions by converting continuous actions into discrete tokens to learn robotic movements. Building on this, OpenVLA [26] introduced an open-source, improved, smaller version of RT-2 [9] using a similar approach, while ECoT [64] developed a thinking chain method.
Meanwhile, the success of diffusion models in content generation [15, 16, 36, 38, 43] has led to a surge in their use for learning visual motion strategies [10] over the past two years. By modeling action sequence generation as a noise denoising process, many methods have shown outstanding performance in operational tasks. Compared to NTP-based VLA models, this approach better captures the multimodal nature of robotic actions and can generate sequences more quickly. However, despite the advantages of diffusion models in strategy learning, they lack the reasoning capabilities necessary for effectively solving complex tasks, which are a significant improvement in LLMs.
Diffusion models. Diffusion models have become dominant in the field of visual generation. Diffusion strategies [10] extend the application of diffusion models to robotic learning, demonstrating their effectiveness in handling multimodal action distributions. Subsequent work has advanced diffusion strategies [5, 6, 11, 30, 39, 42, 50, 51, 55, 71] by applying them to 3D settings [24, 62, 66, 68], scaling them [74], improving their efficiency [21, 56], and introducing architectural innovations. For example, TinyVLA [57] integrates diffusion models with lightweight visual language models, while pi0 [7] generates actions using flow matching instead of diffusion.
Robot foundation models. Existing studies [3, 8, 9, 12, 14, 20, 22, 75] utilize RL [19, 32, 41, 45, 63, 65, 67] and LLM [2, 18, 23, 29, 40, 58, 73] to separate multimodal understanding from embodied control. Another study utilizes pre-trained visual language models (VLM) and fine-tunes them directly on robotic data [9, 26, 57, 64].
Unified autoregressive models and image generation. Recent work has focused on unifying multimodal understanding and image generation. These efforts include generating images using autoregressive methods [28, 33, 46, 52, 54], generating text using diffusion models, or combining both methods into a unified model [13, 31, 59, 70], such as Show-O [61], Transfusion [72], and Vila-U [60].
This raises the question: can the advantages of both be combined, particularly the reasoning capabilities of autoregressive models and the robustness of high-frequency action generation provided by diffusion models?
Given any interleaved sequences of images, text, and video, the images are first encoded into dense visual features using SigLIP [69]. These encodings are then converted into a fixed number of N visual embeddings through a Transformer. Notably, typical visual inputs in robotic learning often include multiple camera views. To manage this, a shared SigLIP visual backbone is applied to each view, followed by connecting the generated visual tokens.
For visual language processing, using the Qwen2-VL [53] visual language model, there are three sizes: 2B, 7B, and 72B parameters. The VLM backbone is initialized with publicly released checkpoints. Any other pre-trained VLM can also be used as a backbone since separating visual language understanding from action generation makes the overall architecture flexible to accommodate advanced new models.
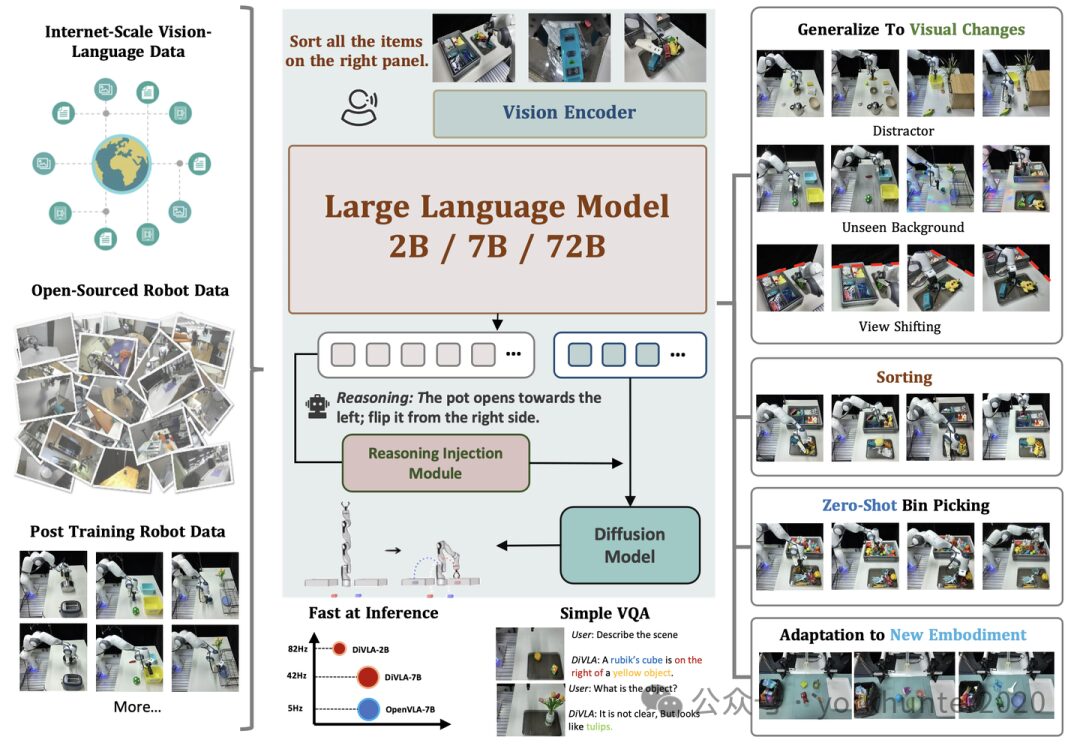
Action decoder. The visual and instruction embeddings are decoded into actions using the SD model. Specifically, a set of tokens is generated with LLM, and these tokens are used as conditional inputs for action decoding into the diffusion model. The architecture follows the design of standard DP [10] with randomly initialized model weights. This component also incorporates reasoning from LLM. An MLP layer is added to the last layer of the action decoder to predict the robot’s joint space. If multiple embodiments evolve, a new MLP layer can be initialized for training and evaluation instead of duplicating individual action decoders [34]. This step ensures that knowledge from pre-trained data is retained, allowing for rapid adaptation to new embodiments.
Reasoning injection module. The core of the method lies in explicitly introducing reasoning into the visual-language-action (VLA) model. Unlike most autoregressive VLAs that require recursive setups (converting reasoning outputs into inputs for subsequent model runs), this method proposes a more efficient and streamlined reasoning integration. By embedding reasoning directly into the strategy model, it avoids the computational and operational complexities of iterative input-output loops, achieving faster and more seamless reasoning integration. The reasoning injection module operates by extracting the final embedding from the tokenized output of the reasoning component and directly injecting it into the strategy model through Feature-wise Linear Modulation (FiLM) [37]. This injection technique is inspired by methods in RT-1 [8] and YAY [44], which are capable of adjusting the layers of the strategy network based on reasoning signals. This process is termed “injection” because, in the design, the strategy network primarily focuses on action-specific tokens, while the reasoning module plays a supportive enhancing role, providing contextual depth without dominating the main decision-making process. This approach ensures that reasoning is not only present but actively utilized during the training of the strategy model.
Pre-trained with OXE [35] and Droid [25] datasets. DiVLA-2B and DiVLA-7B are pre-trained with Droid data. For DiVLA-72B, both OXE and Droid are used for pre-training. The original Droid data contains only robotic actions, some paired with observations and language instructions. This data contains only robotic actions, some paired with observations and language-instruction pairs. To enhance the model’s language generalization capabilities, GPT-4o is utilized to automatically convert this data into a form that includes reasoning. Therefore, the network architecture remains consistent during both pre-training and fine-tuning phases.

For the baseline, a unified training strategy is followed to ensure consistency. For OpenVLA, the original implementation using a single camera is followed. Tests are also conducted using three camera views, where each view is processed through the same visual encoder and its output is connected for further processing. The performance of multiple camera views has improved. For example, for the sorting task, the average success rate increased from 32.3% to 45.3%. Most existing works only report OpenVLA baselines with a single camera view. More details can be referenced in TinyVLA [57]. Pre-trained weights of OpenVLA are used to fine-tune the model on the dataset with a learning rate of 2e-5. For diffusion strategies, DistilBERT is used to encode language instructions, adopting a similar approach to YAY [44]. All models are trained for the same number of epochs, and only the final checkpoints are evaluated. To ensure fair comparisons, checkpoint selection is avoided.
Fast reasoning speed is crucial for deploying VLA models in practical applications. However, as the size and complexity of models increase, their reasoning speed on server-grade hardware often significantly declines. To address this challenge and improve model performance, the models are deployed on the vLLM framework [27]. This approach utilizes optimized infrastructure to maximize reasoning efficiency.
Avoid using action chunking techniques, such as data scaling laws [30] and π0 [7], because while action chunking can improve reasoning speed, it adversely affects generalization performance. Another key observation is that the model’s performance significantly declines when evaluated at lower bit precision (e.g., 8-bit and 4-bit). This is consistent with findings in OpenVLA, which emphasize the performance fluctuations caused by quantization. These results suggest that current VLA models may require specially designed quantization methods to maintain performance while achieving fast reasoning speeds at low precision.