Click the “Deephub Imba“, follow the public account, and don’t miss out on great articles!!
Zephyr utilizes dDPO, significantly improving intent alignment and AI feedback (AIF) preference data, following steps similar to InstructGPT.

Training Method
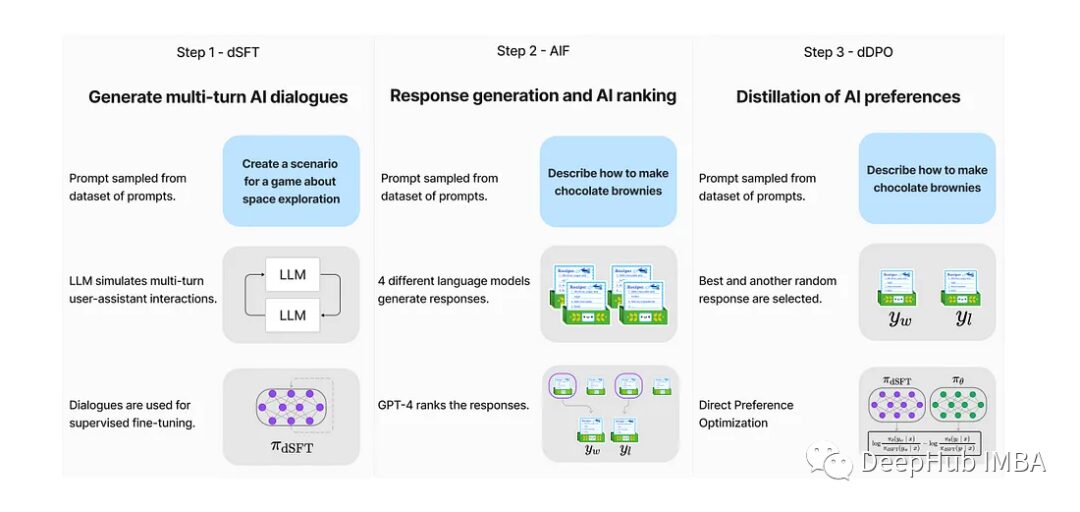
Distilled Supervised Fine-Tuning (dSFT)
Starting from the original LLM, it is first trained to respond to user prompts, traditionally done through SFT. However, by accessing a teacher language model, a dataset can be built through iterative self-prompting, where the teacher is used to respond to instructions and improve them based on the responses. Distillation is performed via SFT. The endpoint is the final dataset, C = {(x1, y1), …, (xJ, yJ)}.
AI Feedback (AIF)
Human feedback provides additional signals to calibrate the LLM. The Ultra Feedback method feeds prompts into multiple models, evaluated by the teacher model to score their responses. The final feedback dataset D consists of these triplets (x, yw, yl), where yw is the highest-scoring response and yl is a randomly lower-scoring prompt.
Distilled Direct Preference Optimization (dDPO)
The goal is to improve the student model (πdSFT) by optimizing the preference model, aimed at ranking preferred answers against low-quality ones.
Starting from the dSFT version of the model, the dSFT model (forward-only) calculates the probabilities of (x, yw) and (x, yl). The dDPO model calculates the probabilities of (x, yw) and (x, yl). Finally, the target is computed and backpropagated for updates.
Model Details
All fine-tuning experiments were conducted on Mistral 7B.
Two dialogue datasets were distilled from open and proprietary models:
UltraChat consists of 14,700 multi-turn dialogues generated by GPT-3.5-TURBO, covering 30 topics and 20 different types of text materials. After applying truecasing heuristics to fix grammatical errors and several filters to remove undesirable model responses, the dataset contains about 200k examples.
UltraFeedback consists of 64k prompts, each with four LLM responses, scored by GPT-4 based on instruction adherence, honesty, and usefulness.
SFT models are trained for one to three rounds. DPO models are also trained for one to three rounds. The final ZEPHYR-7B model is initialized based on the SFT model.
Evaluation Metrics
dDPO improves chat functionality
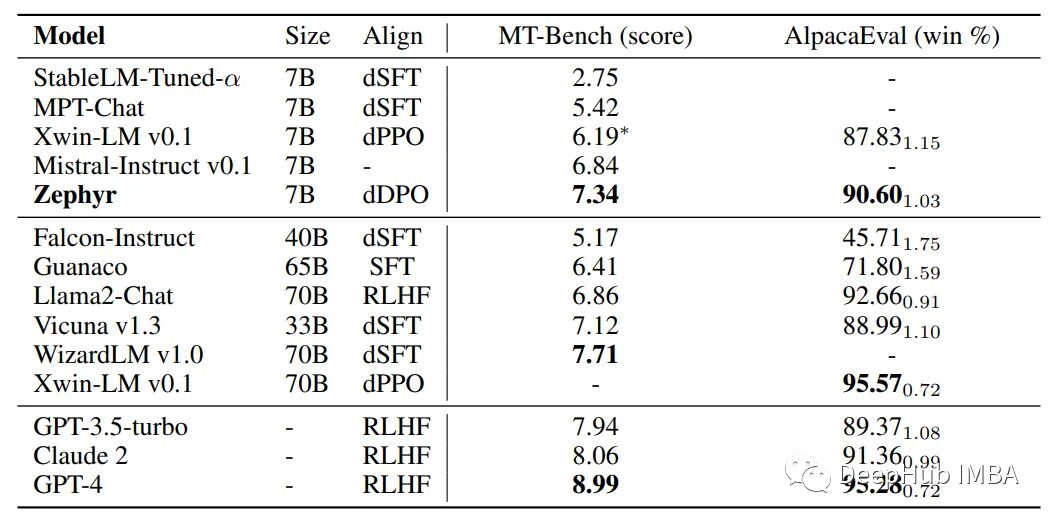
Compared to other 7B models, Zephyr-7B demonstrates superior performance in MT-Bench and AlpacaEval benchmarks.
In both benchmarks, it significantly outperforms other dSFT models, with Zephyr-7B closely scoring against large open models like Llama2-Chat 70B, with differences not exceeding two standard deviations.
dDPO enhances Academic Task performance
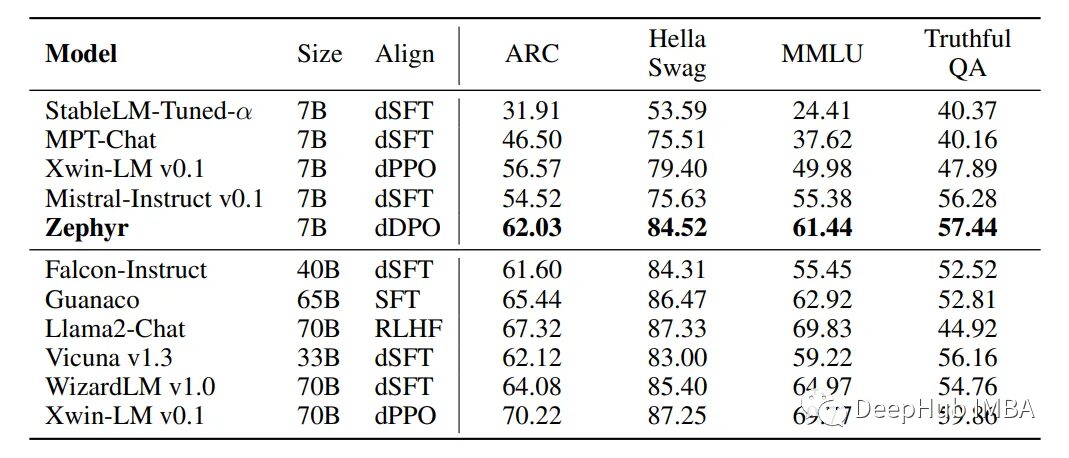
Zephyr outperforms all other 7B models, including dSFT models and Xwin-LM dPPO models. Model size is a significant factor influencing results; larger models perform better on knowledge-intensive tasks. However, Zephyr achieves performance comparable to 40B models in certain aspects.
Is Preference Optimization Necessary?
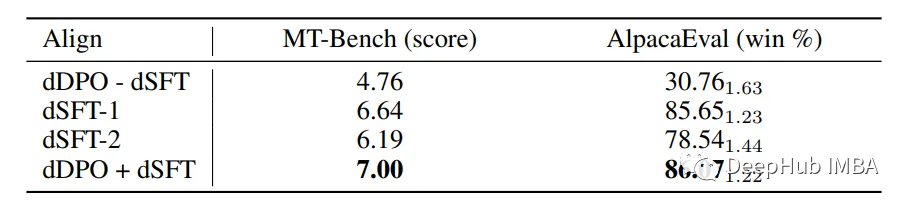
dDPO – dSFT performs one round of fine-tuning on the base model directly using UltraFeedback.
dSFT-1 fine-tunes the base model for one round using SFT on UltraChat.
dSFT-2 first applies dSFT-1, then performs another SFT on the top-ranked dialogues from superfeedback.
dDPO + dSFT first applies dSFT-1, then performs one round of DPO training on ultrafeback.
It can be seen that without the initial SFT step (dSFT), the model performs poorly and cannot effectively learn from feedback. dSFT significantly improves the model’s scores in both chat benchmark tests. Running dSFT directly on feedback data (dSFT-2) does not yield significant performance improvements. Combining dDPO and dDSFT in the complete Zephyr model can greatly enhance performance in both benchmark tests.
Zephyr 7B α vs Zephyr 7B β
dSFT was initially run on the entire UltraChat corpus, resulting in Zephyr 7B α. However, the authors later found that the chat model tended to respond with incorrect capitalization and phrases like “I have no personal experience” even to very simple questions.
To address these issues in the training data, truecasing heuristics were applied to fix grammatical errors (which accounted for about 5% of the dataset), along with several filters to focus on usefulness and remove undesirable model responses. The resulting dataset contains about 200k samples, which were used to train the Zephyr 7B β model.
Zephyr achieves a very small but effective model by applying various training methods, providing strong support for future research directions. For those interested, please refer to the original paper:
https://arxiv.org/abs/2310.16944

If you like it, please follow:
 Give it a look! You are the best!
Give it a look! You are the best!