In multithreaded programming, there are two issues to pay attention to: one is data races, and the other is memory execution order.
What is a data race?
First, let’s look at what a data race is and what problems it can cause.
#include <iostream>
#include <thread>
int counter = 0;
void increment() {
for (int i = 0; i < 100000; ++i) {
// ++counter actually consists of 3 instructions
// 1. int tmp = counter;
// 2. tmp = tmp + 1;
// 3. counter = tmp;
++counter;
}
}
int main() {
std::thread t1(increment);
std::thread t2(increment);
t1.join();
t2.join();
std::cout << "Counter = " << counter << "\n";
return 0;
}
In this example, we have a global variable counter, and two threads are incrementing it simultaneously. Theoretically, the final value of counter should be 200000. However, due to the presence of a data race, the actual value of counter may be less than 200000.
This is because ++counter is not an atomic operation; the CPU breaks ++counter into three instructions: first reading the value of counter, then incrementing it, and finally writing the new value back to counter. The diagram is as follows:
Thread 1 Thread 2
--------- ---------
int tmp = counter; int tmp = counter;
tmp = tmp + 1; tmp = tmp + 1;
counter = tmp; counter = tmp;
Both threads may read the same counter value, then both increment it by 1, and then write the new value back to counter. Thus, the two threads effectively complete only one + operation, which is the essence of a data race.
How to resolve data races
C++11 introduced std::atomic<T>, which allows a variable to be declared as std::atomic<T>. By using the relevant interfaces of std::atomic<T>, atomic read and write operations can be achieved.
Now let’s modify the above counter example using std::atomic<T> to resolve the data race issue.
#include <iostream>
#include <thread>
#include <atomic>
// std::atomic<T> can only be initialized using bruce-initialization.
// std::atomic<int> counter{0} is ok,
// std::atomic<int> counter(0) is NOT ok.
std::atomic<int> counter{0};
void increment() {
for (int i = 0; i < 100000; ++i) {
++counter;
}
}
int main() {
std::thread t1(increment);
std::thread t2(increment);
t1.join();
t2.join();
std::cout << "Counter = " << counter << "\n";
return 0;
}
We changed int counter to std::atomic<int> counter, using the ++ operator of std::atomic<int> to achieve atomic increment operations.
std::atomic provides several common interfaces for atomic read and write operations, and memory_order is used to specify the memory order, which we will discuss later.
// Atomic write value
std::atomic<T>::store(T val, memory_order sync = memory_order_seq_cst);
// Atomic read value
std::atomic<T>::load(memory_order sync = memory_order_seq_cst);
// Atomic increment
// counter.fetch_add(1) is equivalent to ++counter
std::atomic<T>::fetch_add(T val, memory_order sync = memory_order_seq_cst);
// Atomic decrement
// counter.fetch_sub(1) is equivalent to --counter
std::atomic<T>::fetch_sub(T val, memory_order sync = memory_order_seq_cst);
// Atomic bitwise AND
// counter.fetch_and(1) is equivalent to counter &= 1
std::atomic<T>::fetch_and(T val, memory_order sync = memory_order_seq_cst);
// Atomic bitwise OR
// counter.fetch_or(1) is equivalent to counter |= 1
std::atomic<T>::fetch_or(T val, memory_order sync = memory_order_seq_cst);
// Atomic bitwise XOR
// counter.fetch_xor(1) is equivalent to counter ^= 1
std::atomic<T>::fetch_xor(T val, memory_order sync = memory_order_seq_cst);
What is memory order?
Memory order refers to the execution order of memory read and write operations in concurrent programming. This order can be optimized by the compiler and processor, which may differ from the order in the code, known as instruction reordering.
Let’s illustrate what instruction reordering is with an example. Suppose we have the following code:
int a = 0, b = 0, c = 0, d = 0;
void func() {
a = b + 1;
c = d + 1;
}
In this example, the statements a = b + 1 and c = d + 1 are independent; they have no data dependency. If the processor executes these two statements in the order of the code, it must wait for a = b + 1 to finish before starting c = d + 1.
However, if the processor can reorder the execution of these two statements, it can execute them simultaneously, thus improving the execution efficiency of the program. For example, if the processor has two execution units, it can assign a = b + 1 to the first execution unit and c = d + 1 to the second execution unit, allowing both statements to be executed simultaneously.
This is the benefit of instruction reordering: it can fully utilize the processor’s execution pipeline and improve the execution efficiency of the program.
However, in a multithreaded scenario, instruction reordering can cause some problems. Let’s look at the following example:
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<bool> ready{false};
std::atomic<int> data{0};
void producer() {
data.store(42, std::memory_order_relaxed); // Atomically update data's value, but does not guarantee memory order
ready.store(true, std::memory_order_relaxed); // Atomically update ready's value, but does not guarantee memory order
}
void consumer() {
// Atomically read ready's value, but does not guarantee memory order
while (!ready.load(memory_order_relaxed)) {
std::this_thread::yield(); // Do nothing, just yield CPU time slice
}
// When ready is true, atomically read data's value
std::cout << data.load(memory_order_relaxed); // 4. Consumer thread uses data
}
int main() {
// Launch a producer thread
std::thread t1(producer); // Launch a consumer thread
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}
In this example, we have two threads: a producer (producer) and a consumer (consumer).
The producer first modifies the value of data to a valid value, such as 42, and then sets the value of ready to true, notifying the consumer that it can read the value of data.
We expect that when the consumer sees ready as true, it should read the value of data, which should be a valid value, in this case, 42.
However, the actual situation is that when the consumer sees ready as true, it may still read the value of data as 0. Why?
On one hand, this may be caused by instruction reordering. In the producer thread, data and ready are two unrelated variables, so the compiler or processor may reorder data.store(42, std::memory_order_relaxed); to execute after ready.store(true, std::memory_order_relaxed);, causing the consumer thread to first read ready as true, but data is still 0.
On the other hand, it may be caused by inconsistent memory order. Even if the instructions in the producer thread are not reordered, the CPU’s multi-level cache may cause the consumer thread to still see the value of data as 0. We can illustrate this with the following diagram, which shows how this relates to the CPU’s multi-level cache.
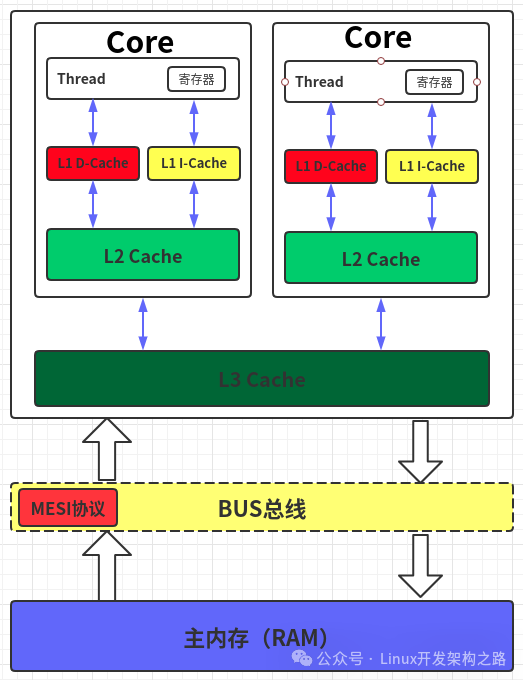
Each CPU core has its own L1 Cache and L2 Cache. The producer thread modifies the values of data and ready, but modifies the values in the L1 Cache. The L1 Cache of the producer thread and the consumer thread are not shared, so the consumer thread may not see the values modified by the producer thread in a timely manner. Synchronizing CPU Cache is a complex task; after the producer updates data and ready, it also needs to write the values back to memory according to the MESI protocol and synchronize the values of data and ready in other CPU cores’ caches, ensuring that each CPU core sees consistent values of data and ready. The order in which data and ready are synchronized to other CPU caches is also not fixed; it may synchronize ready first and then data, in which case the consumer thread will see ready as true first, but data has not yet been synchronized, so it still sees 0.
This is what we refer to as the problem of inconsistent memory order.
To avoid this problem, we need to insert a memory barrier between the update operations of data and ready in the producer thread, ensuring that the updates of data and ready are not reordered, and that the update of data occurs before the update of ready.
Now let’s modify the above example to resolve the issue of inconsistent memory order.
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<bool> ready{false};
std::atomic<int> data{0};
void producer() {
data.store(42, std::memory_order_relaxed); // Atomically update data's value, but does not guarantee memory order
ready.store(true, std::memory_order_release); // Ensure that the update of data occurs before the update of ready
}
void consumer() {
// Ensure to read ready's value first, then read data's value
while (!ready.load(memory_order_acquire)) {
std::this_thread::yield(); // Do nothing, just yield CPU time slice
}
// When ready is true, atomically read data's value
std::cout << data.load(memory_order_relaxed); // 4. Consumer thread uses data
}
int main() {
// Launch a producer thread
std::thread t1(producer); // Launch a consumer thread
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}
We made two changes:
-
We changed ready.store(true, std::memory_order_relaxed); in the producer thread to ready.store(true, std::memory_order_release);, which prevents all operations before ready from being reordered to after ready, ensuring that the write operation of data is completed before the write operation of ready. On the other hand, it ensures that the memory synchronization of data is completed before the memory synchronization of ready, ensuring that when the consumer thread sees the new value of ready, it can also see the new value of data.
-
We changed the consumer thread’s while (!ready.load(memory_order_relaxed)) to while (!ready.load(memory_order_acquire)), preventing all operations after ready from being reordered to before ready, ensuring that the read operation of ready is completed before the read operation of data;
Now let’s take a look at all the values and effects of memory_order:
-
memory_order_relaxed: Only ensures that the operation is atomic, does not guarantee any memory order, which can lead to the problems in the above producer-consumer example.
-
memory_order_release: Used for write operations, such as std::atomic::store(T, memory_order_release), which inserts a StoreStore barrier before the write operation, ensuring that all operations before the barrier do not get reordered to after the barrier, as shown in the following diagram:
+ | | | No Moving Down |
+-----v---------------------+
| StoreStore Barrier |
+---------------------------+
-
memory_order_acquire: Used for read operations, such as std::atomic::load(memory_order_acquire), which inserts a LoadLoad barrier after the read operation, ensuring that all operations after the barrier do not get reordered to before the barrier, as shown in the following diagram:
+---------------------------+
| LoadLoad Barrier |
+-----^---------------------+ | | | No Moving Up | | +
-
memory_order_acq_rel: Equivalent to a combination of memory_order_acquire and memory_order_release, inserting both a StoreStore barrier and a LoadLoad barrier. Used for read-write operations, such as std::atomic::fetch_add(T, memory_order_acq_rel).
-
memory_order_seq_cst: The strictest memory order, based on memory_order_acq_rel, ensuring that all threads see the same order of memory operations. This may be difficult to understand, so let’s look at an example of when memory_order_seq_cst is needed:
#include <thread>
#include <atomic>
#include <cassert>
std::atomic<bool> x = {false};
std::atomic<bool> y = {false};
std::atomic<int> z = {0};
void write_x() {
x.store(true, std::memory_order_seq_cst);
}
void write_y() {
y.store(true, std::memory_order_seq_cst);
}
void read_x_then_y() {
while (!x.load(std::memory_order_seq_cst))
;
if (y.load(std::memory_order_seq_cst)) {
++z;
}
}
void read_y_then_x() {
while (!y.load(std::memory_order_seq_cst))
;
if (x.load(std::memory_order_seq_cst)) {
++z;
}
}
int main() {
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join(); b.join(); c.join(); d.join();
assert(z.load() != 0); // will never happen
}
In this example, after the completion of threads a, b, c, and d, we expect that the value of z is not equal to 0, meaning that at least one of the threads read_x_then_y and read_y_then_x will execute ++z. To ensure this expectation holds, we must use memory_order_seq_cst for the read and write operations of both x and y, ensuring that all threads see the same order of memory operations.
How to understand this? Let’s assume we replace all memory_order_seq_cst with memory_order_relaxed; the possible execution order would be as follows:
-
Thread A: write_x() executes, x is set to true.
-
Thread B: write_y() executes, y is set to true.
-
Thread C: read_x_then_y() reads x as true, but due to memory_order_relaxed not guaranteeing global visibility, y.load() may still read false.
-
Thread D: read_y_then_x() reads y as true, but similarly, x.load() may still read false.
If we use memory_order_seq_cst, then threads C and D will see the same values of x and y.
Thus, we can understand why memory_order_seq_cst incurs the greatest performance overhead; compared to other memory orders, it effectively disables the CPU Cache.
memory_order_seq_cst is commonly used in multi-producer – multi-consumer scenarios, such as in the above example where write_x and write_y are both producers, modifying x and y simultaneously, while read_x_then_y and read_y_then_x are both consumers, reading x and y simultaneously, and these two consumers need to synchronize x and y in the same memory order.
Address: https://blog.csdn.net/sinat_38293503/article/details/134612152