Linux | Red Hat Certified | IT Technology | Operations Engineer
👇 Join the technical exchange QQ group with 1000 members, note 【Public Account】 for faster approval

Components of a Group
The following are the components of each group, but not every group has a super block, which will be discussed later.
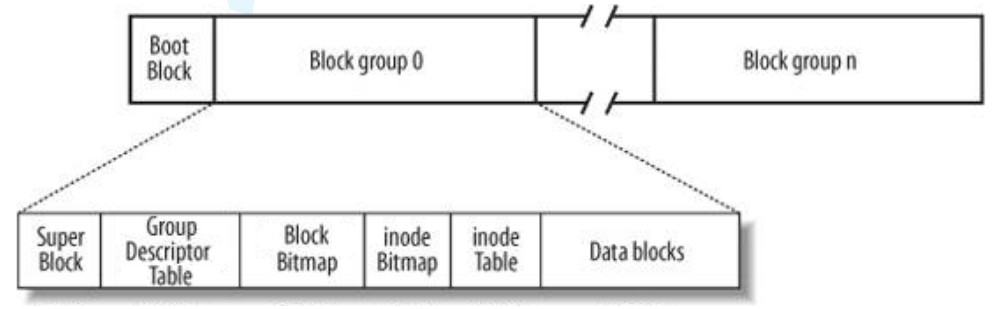
inode table
The inode table is a table used in Linux file systems (such as Ext2, Ext3, Ext4) to store inodes. Each inode is a metadata storage unit for a file or directory, which does not directly store file content but contains file attributes and pointers to data blocks.
Assuming the table above is the inode table, a data block is 4KB, and an inode is 128 bytes, so one data block can store 32 inodes. How are inodes allocated? We can see that there is also a data structure in the group called inode bitmap.
inode bitmap
The inode bitmap is a data structure used in the file system to manage the allocation status of inodes. In Linux file systems (such as Ext2, Ext3, Ext4), the inode bitmap is part of the metadata of the block group, used to track the usage of inodes within a block group.
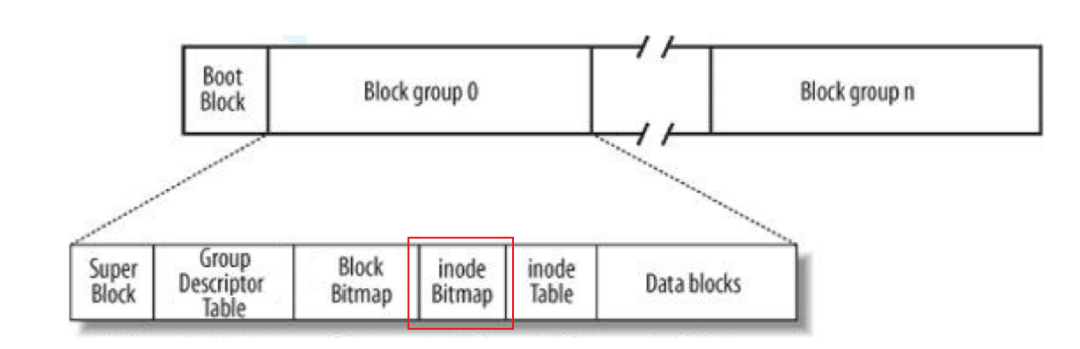
The inode bitmap is specifically used to index the position of the inode table. When allocating inode positions, we first check the inode bitmap for a bit position that is 0. If this position is 0, it indicates that the corresponding position in the inode table is unused. Therefore, when allocating, we find the position that is 0, set it to 1, then locate the inode table corresponding to the inode bitmap and allocate 128 bytes for the inode, filling its attributes into the inode.
data blocks
Data blocks are the basic units for storing file content in a file system. They are used to save the actual data part of files, including text, images, videos, etc.
Data blocks are specifically used to store data within files.
Data blocks are used to store data in units of data blocks. How are data blocks allocated? In the group, there is also a bitmap that manages the usage of data blocks (block bitmap).
block bitmap
The block bitmap is another bitmap data structure used in the file system to manage disk space. It records the usage status of data blocks in the file system and helps the operating system efficiently allocate and release disk space.
The block bitmap works similarly to the inode bitmap. When space needs to be allocated, based on the attributes in the inode, it will look for a suitable position in the block bitmap, set it to 1, then return this block bitmap number to the data blocks, write data to the corresponding position in the data blocks, and finally return this number to the inode table, writing this block bitmap number as an attribute into the inode.
group descriptor table
The Group Descriptor Table is a structure in the file system (especially in file systems like Ext4) that stores important metadata about the file system’s block groups. Each block group contains a portion of data blocks, inodes, data block bitmaps, inode bitmaps, etc. The group descriptor table records the specific locations of these block groups and other necessary management information.
The group descriptor table is used to record the usage of the inode table and data blocks, among other functions.
If we create a file, then there should be a corresponding inode, and this inode needs to be allocated a position in the inode table. After a series of processes, it is allocated, and in the group descriptor table, the count needs to be incremented. If the corresponding file has content, then the record for data blocks also needs to be incremented. If we delete a file, then the corresponding count needs to be decremented.
Now the steps for creating a file are not just about directly looking for a 0 position in the inode bitmap. Now we first check the usage of the inode bitmap in the group descriptor table. If there are remaining inodes, we create an inode for it, then find a 0 position in the inode bitmap, change the corresponding bit to 1, and save the inode into the inode table. The same applies to the data blocks.
super block
The super block is a critical data structure that contains metadata about the file system. It stores basic and management information about the file system, ensuring its effective operation.
The super block, also known as the superblock, is primarily used to record the overall status and basic information of the file system. Not every group has a super block, and there is not just one super block.
**Why is there more than one super block?**
In the file system, there are multiple superblocks mainly to increase the fault tolerance and reliability of the file system. Typically, the file system saves copies of the superblock in different locations to prevent the file system from becoming inaccessible due to disk damage or other hardware failures.

If we store the super block in a separate area at the front, then if this partition crashes, the entire file system will crash. However, if we store the super block in different groups at arbitrary positions, each saving the same super block as a copy, if one group crashes, we only need to copy another super block for recovery.
After understanding the partitioning of each group, let’s discuss the details.
File System
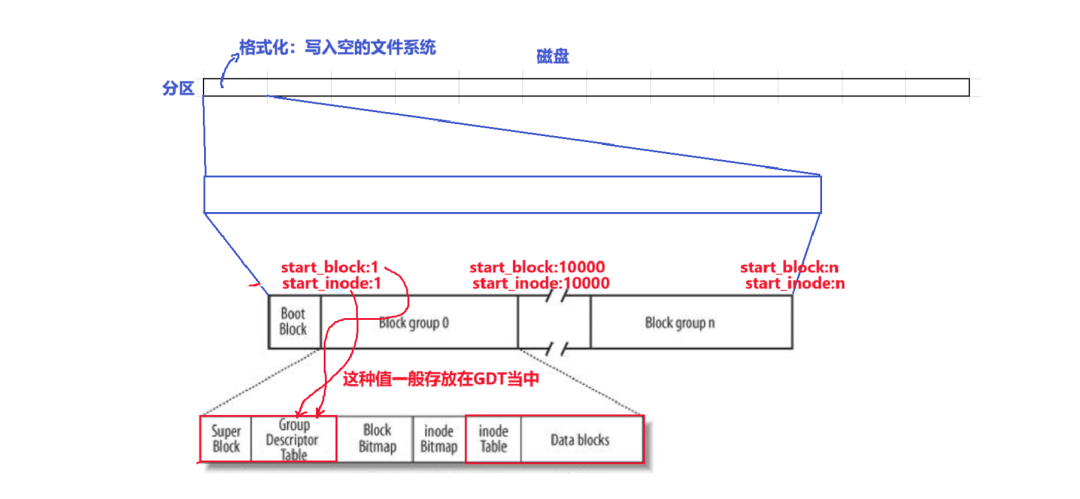
About inodes and blocks
Inodes are partition-based. A partition can have a set of inodes. When allocating inodes, it is only necessary to determine the starting inode of each group. For block numbers, we also only need to record the starting position number of each group. This information is generally recorded in the GDT. When we look for a file, we only need to get the given inode, then find out which group this inode belongs to in the GDT, and after finding out the corresponding group, we only need to look for the inode within that group (note: the inode we get is processed; to get the real inode, we need to subtract the current group’s start_inode from the inode we obtained). We can find the inode according to the inode number, and the inode also has the block number, which can also be used to find the corresponding data blocks.
Question: How are inodes allocated?
Assuming the inode bitmap is 0000 0000 (hypothetically), and the allocated position is 0000 0100, then the allocated position is the third position. For the inode bitmap, this position is 3, but for the inode table, it records 4 because the start_inode is 1. Therefore, adding the starting inode gives 4. If it is in the second group, then allocating the third position would record 10003 in the inode table.
Both inode numbers and block numbers are established globally.
How are inodes and blocks mapped?
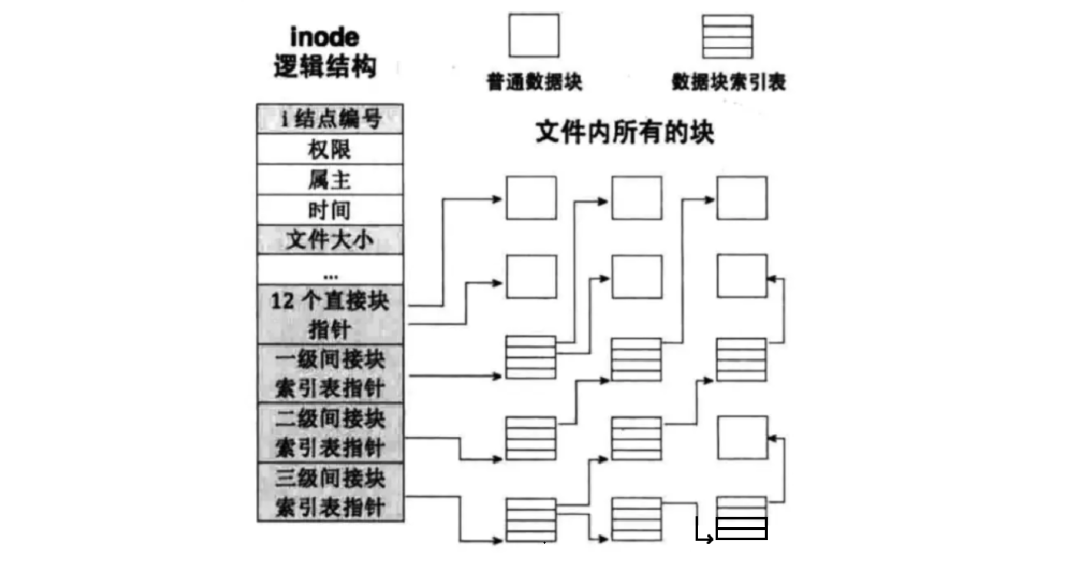
Inodes have 15 pointers mapping to blocks, but are 15 enough?
The answer is yes; there are twelve direct mappings and three indirect mappings.
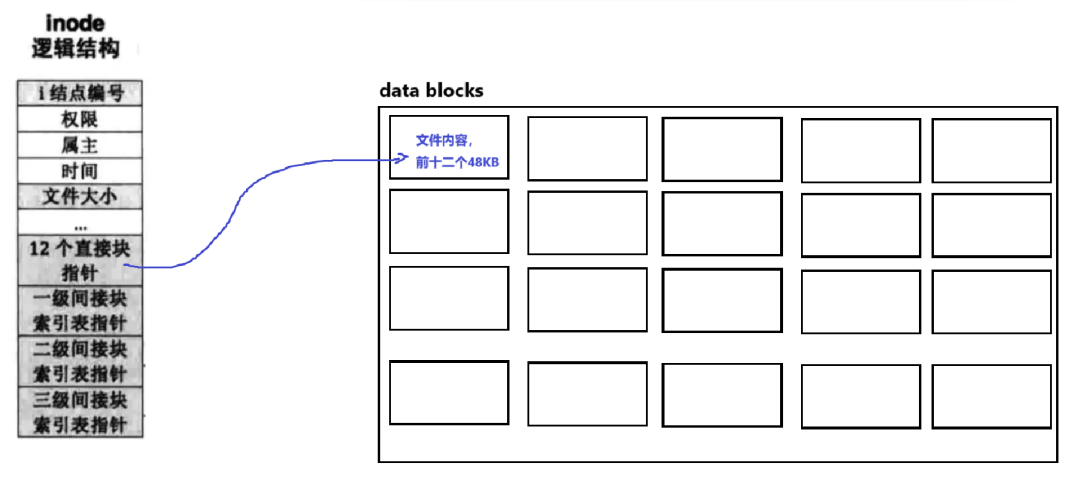
12 direct mappings
Each pointer directly points to the block where the file data is located. The downside is that it is only suitable for small files, but the indexing speed is very fast.
First-level Indirect Index
The inode stores a pointer pointing to this index block, which can point to more data block addresses.
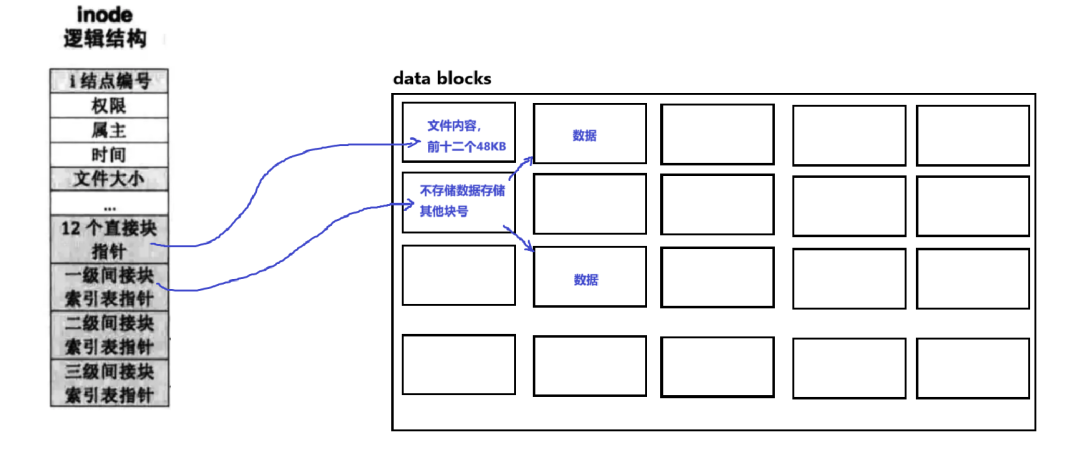
A data block is 4KB, and each address is 4 bytes. There are 4096 bytes in total, so it can index 1024 data blocks. Since each data block is 4KB, 1024 blocks can index 4MB of content.
Second-level Indirect Index
The inode stores a pointer that points to an index block, where each pointer in this index block points to another index block, and these secondary index blocks point to data.
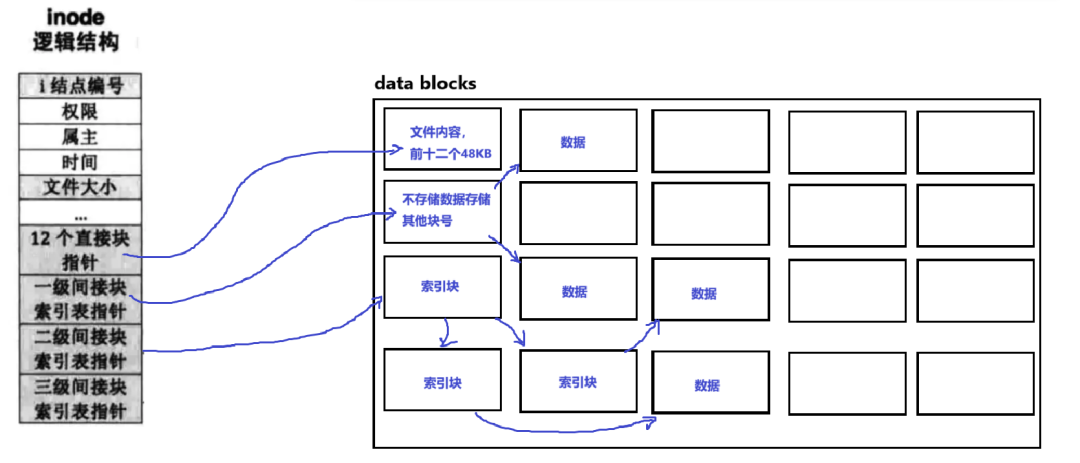
According to the algorithm of first-level indirect indexing, we can calculate how much data can be indexed: 4GB.
Third-level Indirect Index
The inode stores a pointer that points to the first-level index block, which points to the second-level index block, which points to the third-level index block, and the third-level index block finally points to the data.
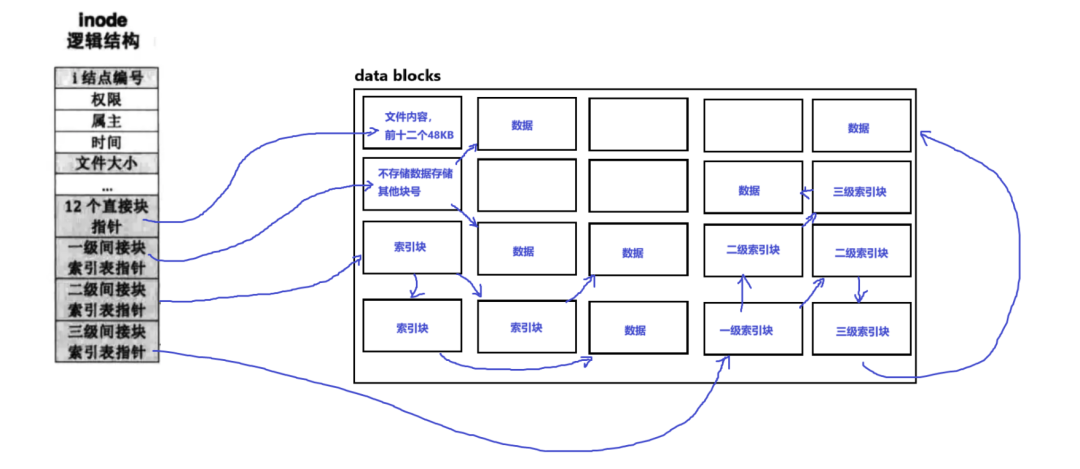
The amount of data that can be indexed by the third-level index is: 16TB (theoretically).
Why is the inode accessed while the file is operated by its name?
In the Linux system, everything is a file, so directories are also files.
A directory = inode + data block = attributes + content, so directories must also have corresponding data blocks. What is stored in the data blocks of a directory?
Linux directories store the mapping relationship between file names and inodes. Since there cannot be files with the same name in the same directory level, the indexing is 1:1 and unique.
Why does Linux do this?

Conclusion
The structural design of the file system aims to efficiently manage data storage and access. Key components such as the inode table, inode bitmap, data blocks, and block bitmap work together to track file data and ensure quick access. The group descriptor table and super block provide metadata for the organization of the file system.
The inode plays an important role in mapping between files and physical data blocks, extending the file system’s management capability for large files through 12 direct pointers, first-level, second-level, and third-level indirect pointers. Accessing files through inodes instead of file names separates the metadata of files from their actual content, allowing the system to efficiently retrieve data even when file names or locations change. This separation design enhances the flexibility and efficiency of the file system, ensuring stability and scalability in file access and management.
For course inquiries, add: HCIE666CCIE
↓ Or scan the QR code below ↓
What technical points and content do you want to see?
You can leave a message below to let Xiaomeng know!