Click on the above“Beginner’s Guide to Vision” to choose to add a Star or “Pin”
Heavyweight content delivered first time
This article is reprinted from | New Machine Vision
In SLAM research, we usually need to test the performance of various solutions on different datasets. Below we mainly test the performance of six visual SLAM solutions listed in Table 1, assessing their accuracy and robustness in different scenarios and requirements, and provide the final solution selection.
[Due to time, venue, and other reasons, we have consolidated previous test results and attached links here. Thank you to the experts for their sharing!]
**
Selection of open-source SLAM solutions:
**
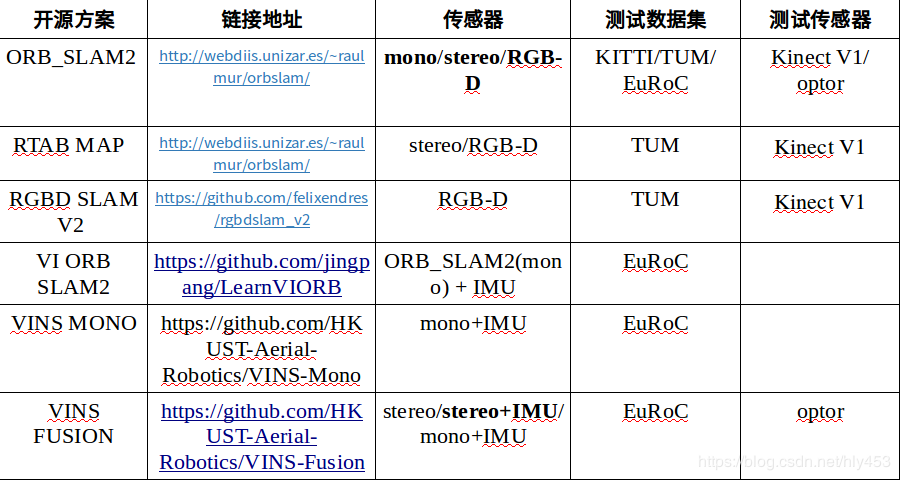
**
Datasets:
**

Detection process: Kinect generates a map [the map mainly includes keyframes (including camera pose, camera intrinsic parameters, ORB features), 3D map points (3D positions in space, normal directions, ORB descriptors), bag of words vectors, co-viewing, etc.] → Save the map → Load the map and relocalize
Disadvantages: 1. It cannot solve practical problems. It is based on feature point methods, and the generated map is sparse, only meeting localization needs without providing many functions such as navigation, obstacle avoidance, interaction, etc. Moreover, it currently does not have the functionality to save and read maps for relocalization.
2. It is greatly affected by lighting and dynamic objects such as vehicles and pedestrians.
Future work: Optimize trajectories and loop closure for front-end data, dense mapping.
[Personal note: 1. Save sparse map’s MapPoint and KeyFrame in .bin format; 2. If saved in pcd format, the relationship between keyframes and keypoints cannot be maintained… i.e., the map information saved in pcd is incomplete.]
Reference blog: https://blog.csdn.net/Darlingqiang/article/details/80689123
Implementation principle: Achieved by a tightly coupled method, recovering scale through monocular + IMU.
Objective: AR
Overall framework:
1. Measurement Preprocessing: Preprocessing of observation data, including image data tracking and IMU data pre-integration;
2. Initialization: Initialization, including pure visual initialization and visual-inertial joint initialization;
3. Local Visual-Inertia BA and Relocalization: Local BA joint optimization and relocalization, including a sliding window-based BA optimization model;
4. Loop detection and Global Pose Graph Optimization: Loop detection; global graph optimization, optimizing only the global poses;

Code interpretation:
The VINS code mainly consists of two files:
1. feature_tracker receives images and uses the KLT optical flow algorithm for tracking.
2. vins_estimate contains front-end preprocessing of camera and IMU data (i.e., the pre-integration process), monocular-inertial joint initialization (online calibration), sliding window-based BA joint optimization, global graph optimization, and loop detection.
VINS mainly consists of two nodes:
1. One node calculates the front end, which is feature_tracker_node.cpp.
2. The other node calculates the back end, which is estimator_node.cpp.

Reference link: http://www.liuxiao.org/2018/02/vi-orb-slam2-与-vins-对比实验/
Main indicators: Root mean square error
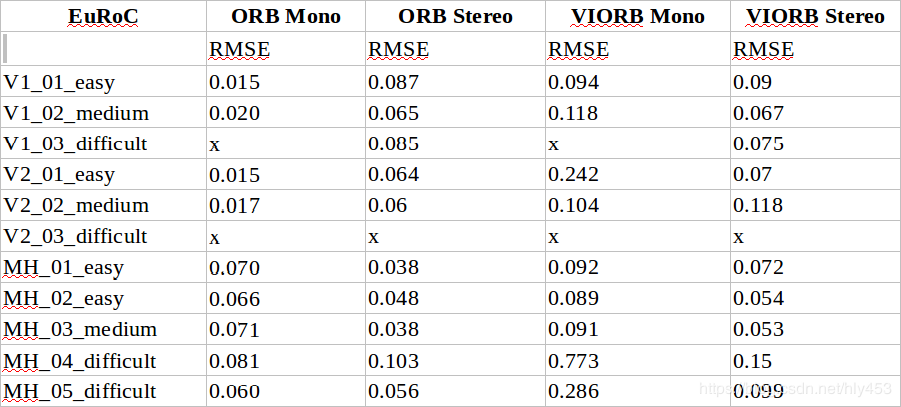
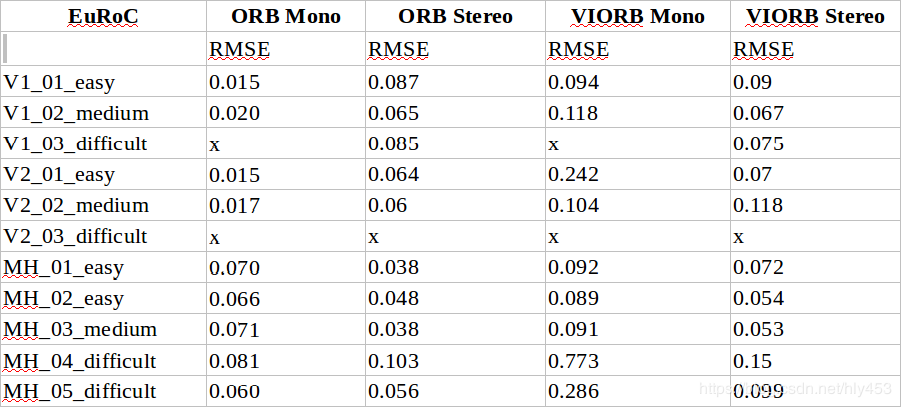
Experimental results:
1. Comparison of ORB and VI ORB
From the table, we can see:
1) Stereo VIO performs better and is more stable than monocular VIO;
2) The optimization of original VO has been quite thorough, but the addition of IMU error terms has introduced more instability in the optimization results; the versions with IMU are less accurate than the original stereo version.
2. Comparison of VI ORB and VINS Mono (with loop closure enabled)
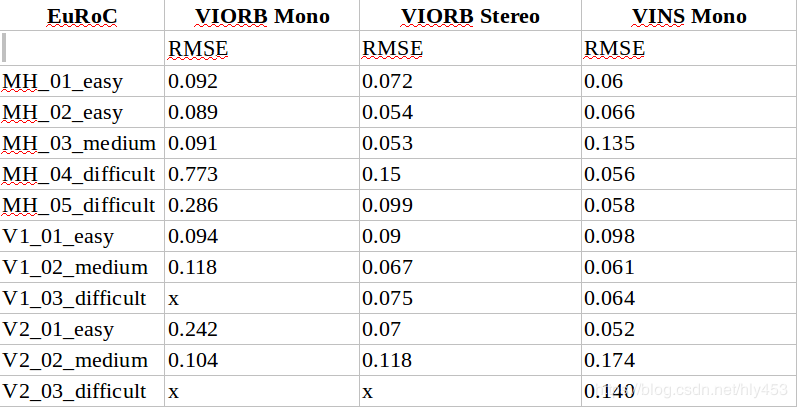
From the table, we can see:
1) The accuracy of VINS Mono is slightly higher than that of VIORB Mono/Stereo;
2) VI ORB cannot completely run through all test sets, especially in the final stages of the fast-moving V2_03_difficult test set, where it tends to lose track; whereas VINS Mono, using optical flow tracking, is less prone to losing track.
3. Comparison of VI ORB and VINS Mono (with loop closure disabled)
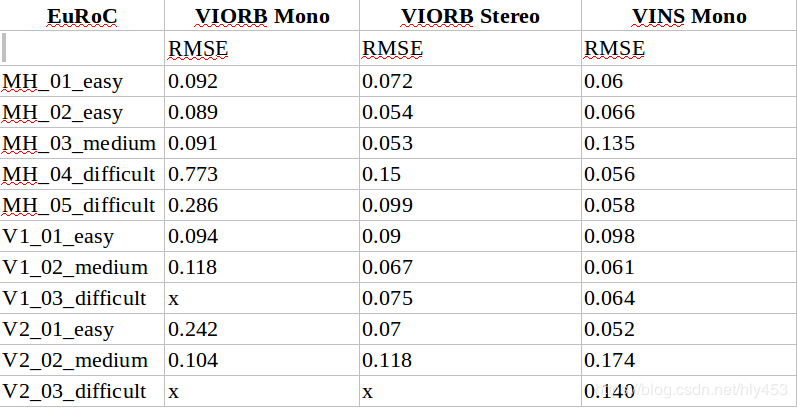
From the table, we can see:
VINS Mono is highly dependent on loop closure; its performance significantly decreases when loop closure is disabled.
4. Experimental Summary
1) Without loop closure, the accuracy of VINS Mono is slightly lower than that of VIORB; with loop closure, the accuracy difference between the two is minimal.
2) Since the open-source version of VIORB is not the official implementation, there are many differences from the official version, making it impossible to test the performance of the real official VIORB; however, it can be seen that the introduction of IMU in the VI ORB SLAM2 framework mainly helps to reduce losses during fast motion, but the accuracy is similar to or slightly lower than VO.
3) VINS Mono, which uses optical flow as the front end, has better robustness than VIORB, which uses descriptors as the front end, and is less likely to lose track during fast motion. Therefore, in scenarios such as drones, VINS should be a better choice than VIORB; for scenarios requiring high accuracy and larger scenes with slower motion, VIORB /ORB is still more suitable.
4) Regardless of whether IMU is introduced, stereo vision will have a certain improvement in accuracy and robustness; VINS Fusion shows improved performance compared to VINS Mono; {Accuracy – slow, stereo; Robustness – fast}
5) Aside from the significant differences in the front end (such as optical flow vs. ORB, sliding window vs. local map), although both use pre-integration, there are also significant differences in the back-end algorithms and implementations (differences in Lie algebra and quaternion parameterization, integration methods, g2o vs. ceres implementations, etc.), making the reasons for performance differences quite complex.
5. Comparison of VI ORB-SLAM Initialization and VINS Initialization (Transplanting the VI ORB-SLAM Initialization Method into VINS)
Reference link: https://blog.csdn.net/u012348774/article/details/81414264
Core idea:
A comprehensive comparison of various public monocular VIO algorithms (MSCKF, OKVIS, ROVIO, VINS-Mono, SVO+MSF, and SVO+GTSAM);
Testing various monocular VIO algorithms on multiple embedded platforms (Laptop, Intel NUC, UP Board, ODROID) and analyzing the performance of the algorithms;
3. Selected the EuRoC MAV dataset.
Conclusion: SVO+MSF is the most computationally efficient algorithm, while VINS-Mono has the highest state estimation accuracy, with ROVIO falling in between.
Recommended link: https://blog.csdn.net/huanghaihui_123/article/details/86518880
Release date: Hong Kong University of Science and Technology, January 12, 2019
Versions:
(1) Monocular + IMU
(2) Pure stereo
(3) Stereo + IMU
(4) Stereo + IMU + GPS
Compared to VINS Mono:
Compared to VINS Mono, the main addition is the global_fusion package, which integrates GPS and visual IMU positioning results. The code structure has changed, with the previous pose_graph node renamed to loop_fusion, and the previous feature_track node merged into the vins_estimator. The residual terms in vins_estimator have increased significantly, mainly due to the increase in visual residual terms.
Advantages: Can initialize while stationary; scale information does not necessarily rely entirely on IMU (with stereo), avoiding scale ambiguity; robustness is clearly superior in stereo compared to monocular;
Disadvantages: Due to visual mismatches and other reasons, the accuracy of stereo may be slightly worse than that of monocular.
[Personal note: Using VINS Fusion to run the KITTI pure stereo dataset, the output results include a vio.txt pose file, but this does not include loop closure; the loop closure data is in a separate vio_loop.csv file, which contains only loop closure frames and has a different data format from the true trajectory, not 12 columns. How to merge the loop closure data from vio_loop.csv into the unlooped vio.txt data and then plot the overall trajectory estimate after closure?]
Overview: Unlike other visual SLAM solutions, it provides an appearance-based localization and mapping solution that is time and scale-independent, optimizing online loop closure detection in large environments, mainly by using computational weights to ensure that only a limited number of localization points participate in loop closure detection; however, global localization points can also be accessed if needed.
Process: Start -> Feature extraction and matching -> Calculate visual odometry for each pair of frames -> Optimize the results -> Local map -> Motion state estimation -> Pose graph -> Bag of words model -> Similarity computation -> End
Feature points: Use the bag of words method to create image signatures, extracting SURF features from images based on OpenCV to obtain visual words.
Mapping methods: 1. Octomap (3D occupancy grid map)
2. Dense point cloud map
3. 2D occupancy grid map
ROS node: Input: 1. TF (position of the sensor relative to the robot base)
2. Odometry
3. Camera input with calibration information
Output: 1. Map Data and Graph
Advantages: 1. Suitable for online mapping requirements in long-term and large-scale environments
2. Good robustness in odometry with low drift
3. Good robustness in localization
4. Practical and simple map generation
5. Provides software packages
Disadvantages: 1. The solution is commercialized, making secondary development difficult.
Reference: https://blog.51cto.com/remyspot/1784914
Overview: The system front end is visual odometry, extracting features from each frame’s RGB, calculating descriptors, using RANSAC+ICP to estimate motion between two frames, and proposing an EMM (Environmental Measurement Model) to determine whether the motion estimate is acceptable, with back-end loop closure detection based on G2O’s pose graph optimization.
Feature points: 1. SIFT by GPU (best overall performance)
2. SURF by CPU (OpenCV)
3. ORB by CPU (OpenCV) (better accuracy and real-time performance)
Mapping method: Octomap (suitable for navigation; easy to update; space-efficient storage)
Advantages: 1. Easier for secondary development, can continue to develop based on it
Disadvantages: 1. Relatively poor real-time performance, camera must move slowly
Reference: http://www.cnblogs.com/voyagee/p/7027076.html
System construction:
1. RGBD_SLAM V2 is a very comprehensive and excellent system, integrating image features, optimization, loop closure detection, point cloud, octomap, and other technologies in the SLAM field;
2. RTAB-Map is currently the best RGBD SLAM.
Development: RGBD_SLAM2 is suitable for beginners in RGBD SLAM and can continue to develop based on it.
RTAB-MAP has a higher difficulty for secondary development (the famous Google Tango (see how to evaluate Google’s Project Tango and what black technologies are involved in Google Project Tango) uses RTAB-Map for SLAM).
Real-time performance: The disadvantage of RGBD_SLAM2 is that its algorithm does not perform well in real-time; the camera must move slowly,
RTAB-MAP reduces the number of nodes needed for graph optimization and loop closure detection through STM/WM/LTM memory management mechanisms, ensuring real-time performance and accuracy in loop closure detection, capable of running in extremely large scenes.
Loop closure detection: RGBD-SLAM V2: When the camera moves quickly, there will be significant map overlap.
RTAB-MAP: Relatively stable, but still unstable.
Personal: In actual operation, RGBD SLAM V2 uses point cloud representation, which consumes memory, and after a long time, the number of point clouds in 3D space increases, causing noticeable lag in the display; however, the result details are well represented.
In actual operation, RTAB-MAP runs smoothly, but uses a 3D occupancy grid map representation, and the details are also well represented.
System construction: RTAB-MAP: A comprehensive framework that supports joint mapping, establishing maps that include 3D dense point clouds and 2D grid maps (can directly obtain binary programs from ROS).
ORB-SLAM: Only meets localization needs and cannot provide many functions such as navigation, obstacle avoidance, and interaction.
Code readability: RTAB-MAP: Poor, basically encapsulated.
ORB-SLAM: Good readability.
Applications: RTAB-MAP: Suitable for SLAM applications.
ORB-SLAM: Suitable for research use.
Computational load: RTAB-MAP: Memory management methods have relatively low computational load.
ORB-SLAM: The three-thread structure requires calculating ORB features for each image, resulting in high time and computational load.
Loop closure detection: RTAB-MAP: Loop closure detection only accesses a limited number of localization points.
ORB-SLAM: Excellent loop closure detection algorithms ensure that ORB-SLAM2 effectively prevents cumulative errors and can quickly recover after losing track, which many existing SLAM systems do not adequately address. To achieve this, ORB-SLAM2 must load a large ORB dictionary before running.
1: Processing of Visual and IMU Front-End Data
① Feature point extraction (feature detection) + matching feature points based on descriptors
orbslam, okvis
Advantages: Because there are descriptors, it is very convenient to maintain the map (including relocalization, loop closure, global optimization).
Especially for indoor environments, when there are many co-visibility relationships visually, this method can greatly improve localization accuracy and local stability. Indoor mobile robots are recommended to use this method.
Disadvantages: Each frame image needs to extract a number of descriptors for feature points, wasting time; during tracking, if the motion is too fast (resulting in image blur), it is relatively easy to fail tracking, while optical flow performs better.
② Feature point extraction + optical flow tracking
vins, svo initialization
Advantages: Simple and efficient, tracking is more robust.
Disadvantages: It is not easy to build a global map; visual constraints rely only on keyframes within the sliding window.
For example, the loop closure and relocalization of vins require extracting feature points and descriptors separately; however, the back end is well done.
③ Direct method
lsdslam, dso
Advantages: Robust in low-texture conditions.
Disadvantages: It is not easy to maintain a global map, is greatly affected by lighting, and cannot be used in high-precision maps, etc.
For the IMU front end:
IMU front ends generally use pre-integration methods, and the difference from integration is that pre-integration considers gravity. IMU pre-integration mainly updates the five state variables (p, v, q, ba, bg) of the IMU between two image frames’ Jacobian and covariance.
PS: To avoid having to recalculate the integration every time the pose changes in nonlinear optimization.
Now, when changing the pose (velocity, displacement, rotation quaternion concerning the world coordinate system), the terms within the pre-integration remain unchanged.
When changing ba, bg (acceleration and gyroscope bias), the pre-integration terms can be updated using first-order Taylor expansion.
Jacobian is the identity matrix, mainly to obtain first-order approximations of p, v, q; covariance is a zero matrix, mainly to obtain the weights of IMU error terms.
IMU initial value determination: Generally determined using visual information from vins mono, etc.
2: Back-End Optimization
Filtering: No need for marginalization, relocalization is difficult. Because no iteration is needed, the speed is slightly faster.
**Optimization:** Requires marginalization (which is time-consuming), relocalization is easy. Iterative optimization, speed is slightly slower.
VINS-Mono is similar to OKVIS, optimizing a sliding window of keyframes based on a nonlinear optimizer, with robust corner associations between frames. In the system initialization phase, various sensors are fused using a loosely coupled method; during relocalization, sensors are fused using a tightly coupled method. Before optimization, IMU pre-integration is also used to reduce computational load. In addition, VINS provides pose graph optimization based on 4DoF and loop closure detection.
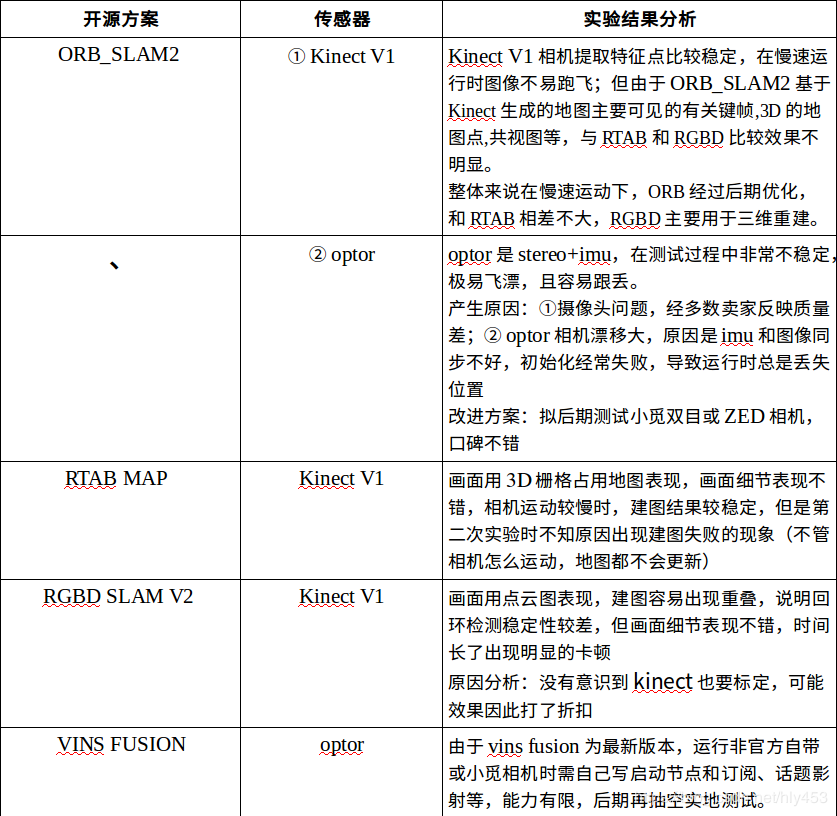
Based on the above research, considering resources and other factors, I preliminarily include ORB_SLAM2, VINS FUSION, RTAB MAP, and LSD SLAM in the follow-up research, planning to spend another two weeks on camera selection and physical scene testing. I hope to present the current research results and encourage mutual learning and progress!
The author is CSDN blogger “lark_ying”
Original link: https://blog.csdn.net/hly453/java/article/details/88983123
 End
End 
Discussion Group
Welcome to join the public account reader group to exchange with peers. Currently, there are WeChat groups for SLAM, three-dimensional vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions etc. (will gradually be subdivided in the future), please scan the WeChat number below to join the group, and note: “nickname + school/company + research direction”, for example: “Zhang San + Shanghai Jiao Tong University + Visual SLAM”. Please follow the format for notes, otherwise, you will not be approved. After successful addition, you will be invited to the relevant WeChat group based on your research direction. Please do not send advertisements in the group, otherwise you will be removed from the group. Thank you for your understanding~

