▼Click the card below to follow the public account ▼
In the usual project development process, various problems may arise. Here is an article sharing the thoughts and solutions for common problems.
1. Problem Reproduction
Stably reproducing the problem is essential for correctly locating, solving, and verifying the issue. Generally, the easier it is to reproduce the problem, the easier it is to solve.
1.1 Simulating Reproduction Conditions
Some problems occur under specific conditions, and you only need to simulate the conditions to reproduce the issue. For conditions that depend on external inputs, if the conditions are complex and difficult to simulate, you can consider pre-setting the program to directly enter the corresponding state.
1.2 Increasing Task Execution Frequency
For example, if an exception occurs only after a task has been running for a long time, you can increase the execution frequency of that task.
1.3 Increasing Test Sample Size
If an exception occurs after the program has been running for a long time and the problem is difficult to reproduce, you can set up a testing environment with multiple devices to test simultaneously.
2. Problem Location
Narrow down the scope of investigation to confirm the task, function, or statement that introduced the problem.
2.1 Print LOG
Based on the symptoms of the problem, add LOG output at suspicious code locations to trace the program execution flow and the values of key variables, observing whether they match expectations.
2.2 Online Debugging
Online debugging can serve a similar purpose as printing LOGs. This method is particularly suitable for troubleshooting program crash-type bugs. When the program encounters an exception (HardFault, watchdog interrupt, etc.), you can directly STOP and check the call stack and the values of kernel registers to quickly locate the issue.
2.3 Version Rollback
When using version management tools, you can locate the version that first introduced the problem by continually rolling back and testing. You can then investigate the code changes made in that version.
2.4 Binary Commenting
Binary commenting means commenting out part of the code in a manner similar to binary search to determine whether the problem is caused by the commented-out code.
The specific method is to comment out half of the code unrelated to the problem and check if the problem is resolved. If not, comment out the other half. If resolved, continue to narrow down the range of comments by half, and so on.
2.5 Saving Kernel Register Snapshot
When the Cortex M core encounters an exception, several kernel register values are pushed onto the stack, as shown in the figure:
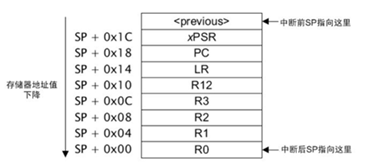
We can write the kernel register values from the stack into a region of RAM that retains default values after a reset. After performing a reset, we can read this information from RAM and analyze it. By checking the PC and LR, we can confirm the function being executed at that time and analyze whether the variables processed by R0-R3 were abnormal, as well as whether a stack overflow might have occurred through SP analysis.
3. Problem Analysis and Handling
Combine the symptoms of the problem with the location of the problematic code to analyze the cause of the issue.
3.1 Program Continues Running
3.1.1 Value Abnormality
3.1.1.1 Software Issues
1. Array Out of Bounds
Writing to an array with an index that exceeds the array length modifies the content at the corresponding address. For example:
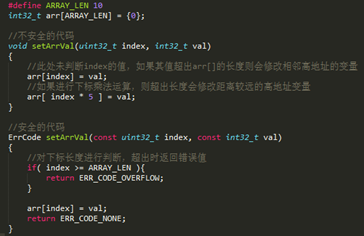
Such issues usually require analysis in conjunction with the map file. By examining the addresses near the modified variable in the map file, you can check if there are unsafe writing operations on that array as shown in the figure and modify them to safe code.
2. Stack Overflow
| 0x20001ff8 | g_val |
|---|---|
| 0x20002000 | Stack Bottom |
| ………… | Stack Space |
| 0x20002200 | Stack Top |
As shown in the figure, this type of issue also requires analysis in conjunction with the map file. Assuming the stack grows from high addresses to low addresses, if a stack overflow occurs, the value of g_val will be overwritten by the values on the stack.
When a stack overflow occurs, analyze the maximum usage of the stack. Too many function call layers, calling functions within interrupt service routines, and declaring large temporary variables within functions can all lead to stack overflow.
To resolve such issues, consider the following methods:
-
During the design phase, allocate memory resources reasonably and set an appropriate size for the stack;
-
Convert larger temporary variables within functions to static variables by adding the “static” keyword or use malloc() for dynamic allocation, placing them on the heap;
-
Change the function calling method to reduce the number of layers.
3. Incorrect Conditional Statements

It is easy to accidentally write the equality operator “==” as the assignment operator “=”, causing the value of the variable being evaluated to change. This type of error does not trigger a compilation error and always returns true.
It is recommended to write the variable to be judged on the right side of the operator so that if mistakenly written as an assignment operator, it will trigger a compilation error. Static code analysis tools can also be used to detect such issues.
4. Synchronization Issues
For example, when operating on a queue, if an interrupt (task switch) occurs during the dequeue operation, and the enqueue operation is performed in the interrupt (switched task), it may corrupt the queue structure. In such cases, interrupts should be disabled during operations (using mutex locks for synchronization).
5. Optimization Issues

In the above program, the intention is to stop executing the foo() function after waiting for the irq interrupt, but due to compiler optimization, flg may be loaded into a register and each time the value in the register is checked without re-reading the value from RAM, causing foo() to continue running even after the irq interrupt occurs. The “volatile” keyword should be added before the declaration of flg to force the value to be fetched from RAM each time.
3.1.1.2 Hardware Issues
1. Chip Bugs
There are bugs in the chip itself that return incorrect values to the microcontroller under certain specific conditions. The program needs to filter out abnormal values from the returned values.
2. Communication Timing Errors

For example, when reading voltage sampling data from two cascaded power management chips Isl78600 simultaneously, the high-end chip will send data to the low-end chip through a daisy chain at fixed intervals, while the low-end chip only has one buffer.
If the microcontroller does not read the data from the low-end chip within the specified time, the new data will overwrite the current data, resulting in data loss. Such issues require careful analysis of the chip’s data manual to strictly meet the timing requirements for chip communication.
3.1.2 Action Abnormalities
3.1.2.1 Software Issues
1. Design Issues
There are errors or omissions in the design that require a redesign of the documentation.
2. Implementation Does Not Match Design
The code implementation does not match the design documentation, requiring unit tests to cover all conditional branches and conducting cross-code reviews.
3. Abnormal State Variables
For example, if the variable that records the current state of the state machine is tampered with, the analysis method for such issues is the same as that for value abnormalities described earlier.
3.1.2.2 Hardware Issues
1. Hardware Failure
The target IC fails to act after receiving control commands, requiring hardware troubleshooting.
2. Communication Anomalies
Communication errors with the target IC prevent proper execution of control commands, necessitating the use of an oscilloscope or logic analyzer to observe communication timing and analyze whether the signals sent are incorrect or subject to external interference.
3.2 Program Crashes
3.2.1 Stopping Execution
3.2.1.1 Software Issues
1. HardFault
The following situations can cause a HardFault:
-
Operating the registers of a peripheral whose clock gate is not enabled;
-
Jumping to a function address that is out of bounds, usually occurring when a function pointer is tampered with; the troubleshooting method is the same as that for value abnormalities;
-
Dereferencing a pointer with alignment issues:
For example, if we declare a structure that requires alignment as follows:

| Address | 0x00000000 | 0x00000001 | 0x00000002 | 0x00000003 |
|---|---|---|---|---|
| Variable Name | Val0 | Val1_low | Val1_high | Val2 |
| Value | 0x12 | 0x56 | 0x34 | 0x78 |
In this case, the address of a.val1 is 0x00000001. If we dereference this address as uint16_t, it will cause a HardFault due to the alignment issue. If it is necessary to manipulate this variable with pointers, memcpy() should be used.
2. Interrupt Service Function Did Not Clear Interrupt Flag
If the interrupt flag is not cleared correctly before exiting the interrupt service function, the program will immediately re-enter the interrupt service function after executing from it, resulting in a “pseudo-dead” phenomenon.
3. NMI Interrupt
During debugging, we encountered a situation where the MISO pin of the SPI was reused for NMI functionality. When the peripheral connected via SPI was damaged, the MISO pin was pulled high, causing the microcontroller to enter the NMI interrupt directly after reset before configuring the NMI pin as SPI functionality, causing the program to hang in the NMI interrupt. In this situation, the NMI functionality can be disabled within the NMI interrupt service function to exit the NMI interrupt.
3.2.1.2 Hardware Issues
1. Oscillator Not Starting
2. Insufficient Power Supply Voltage
3. Reset Pin Pulled Low
3.2.2 Reset
3.2.2.1 Software Issues
1. Watchdog Reset
In addition to resets caused by watchdog timeout, pay attention to the special requirements for watchdog configuration. For example, in the Freescale KEA microcontroller, the watchdog requires an unlock sequence (writing two different values to its registers consecutively) during configuration. This unlock sequence must be completed within 16 bus clocks; otherwise, it will trigger a watchdog reset. Such issues require thorough reading of the microcontroller’s data manual to be aware of similar detail issues.
3.2.2.2 Hardware Issues
1. Unstable Power Supply Voltage
2. Insufficient Power Supply Load Capacity
4. Regression Testing
After resolving the issue, regression testing is necessary to confirm that the problem no longer reproduces and to ensure that modifications do not introduce other issues.
5. Summary of Experience
Summarize the causes of the problem and the methods used to solve it, considering how to prevent similar issues in the future and whether it is worth learning from similar products on the same platform, thereby achieving a lesson learned approach to draw experience from failures.
Original Article: https://www.cnblogs.com/jozochen/p/8541714.html
Disclaimer: