
Source: Hardware-Software Integration
Author: Chaobowx
1 What Are Large Chips?
1.1 Classification Based on Operating System Standards
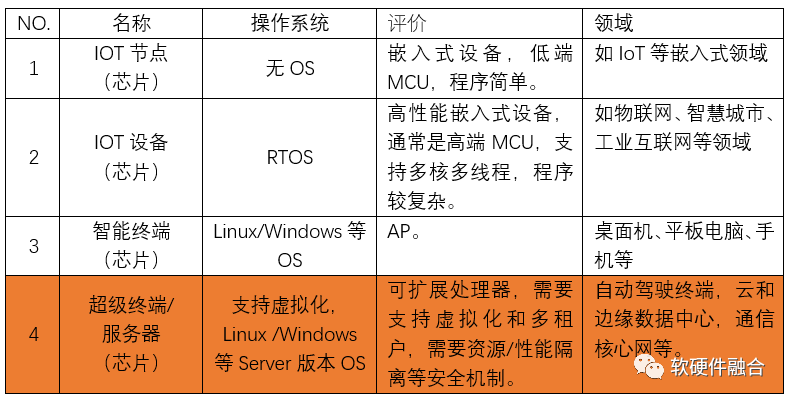
Thus, we can have a straightforward standard for large chips:
-
They need to support operating systems and virtualization (virtualization includes different levels such as virtual machines, containers, functions, etc.);
-
They need to support virtualization resource partitioning;
-
They need to support isolation of systems, resources, and performance;
-
They need to support software across hardware platforms, including hardware interface abstraction and live migration.
Large chips need to support many capabilities traditionally found at the software level at the hardware level, such as programmability, scalability, adaptability, software cross-platform compatibility, and high availability.
1.2 The Role of Various Engines/Processors

The above image shows the functional hierarchy of systems running on computers (servers), generally divided into two levels:
-
The infrastructure layer supporting applications, such as networking, storage, virtualization, file systems, databases, etc.;
-
The application layer. The application layer can also be further divided. Many applications are performance-sensitive and require hardware acceleration. Therefore, the application can be divided into two parts:
-
The hardware-accelerated part of the application, which tends to change more significantly than the infrastructure, thus requiring relatively flexible acceleration platforms like GPU, FPGA, etc., while ASIC is not very suitable.
-
The non-accelerated part of the application, which varies widely, often requires a sufficiently general and flexible runtime platform like CPU.
CPU
If the entire system does not have high performance requirements, the CPU can handle it. The best practice is to run everything, whether in the infrastructure layer or the accelerated and non-accelerated parts of the application, on the CPU.
However, due to the failure of Moore’s Law based on CPUs, they are gradually unable to handle all computing tasks in the system, leading to a chain reaction. This is why the three classifications in the above image exist, along with various targeted hardware acceleration platforms.
No matter how optimized or improved, the CPU, as the core processing engine (which could be an independent CPU chip or an embedded CPU core), still plays the most critical role.
In the future, the CPU will mainly handle the non-accelerated computing parts of the application layer and the overall control and management of the system. Although the CPU may not be the main force in computing, it remains the core of management and control.
GPU
The GPU is more suitable for flexible acceleration at the application layer, partly due to the general computing capabilities of GPGPU, which achieves a good balance in scene coverage and performance improvement. Coupled with the support of development frameworks/ecosystems like CUDA, the GPU is undoubtedly the main platform for accelerated application layers.
DPU
The DPU is positioned for (accelerated) processing at the infrastructure layer, such as virtualization, networking, storage, security, and integration of IaaS services. The DPU requires many ASIC/DSA-level acceleration engines and collaboration with embedded CPUs to perform better at the infrastructure layer, thereby better supporting the upper-level work of CPUs and GPUs.
The DPU can be seen as the “workhorse” of the entire system, undertaking the most arduous and challenging tasks, but its value is perceived as lower than that of CPUs and GPUs. Currently, the challenges faced by the DPU mainly manifest in:
-
The complexity of tasks. Due to performance requirements, it must translate business logic into circuits, making DPU development significantly more challenging and labor-intensive compared to CPUs and GPUs.
-
The relatively low value. DPUs are typically positioned as assistants to CPUs, responsible for offloading some heavy, lower-value tasks from the CPU. Thus, their value is lower than that of CPUs and GPUs.
-
Passive collaboration. The DPU needs to collaborate with the CPU and GPU, but this collaboration is often passive. The DPU’s implementation requires the “involvement” of the CPU and GPU, making it significantly challenging to deploy.
-
Differences in customer demands and business iterations require the DPU to closely align with user needs, integrating deeper user requirements into the chip. However, doing so leads to fragmented scenes, limiting the scenarios the DPU can cover. The high R&D costs of large chips make it difficult for them to be commercially viable.
AI Chips
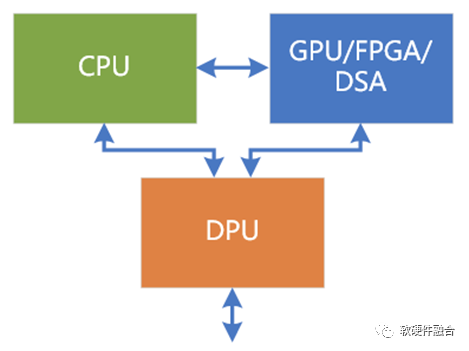
AI chips, also known as AI-DSA, are positioned similarly to GPUs. Generally, in a small physical space of a server, there is usually only one type of acceleration card, meaning that AI and GPUs are mutually exclusive, competing for the same physical slot.
The heterogeneous computing of CPU+xPU is typically divided into three categories:
-
CPU+GPU, CPU+FPGA, and CPU+DSA.
-
If high versatility is required and broad scene coverage is needed, GPUs are typically chosen. For example, in AI training scenarios, although GPUs are not the most efficient platform, the rapid updates of AI training algorithms make GPUs more suitable than AI-DSA.
-
If high performance is required and the algorithms are relatively certain, DSA architectures are more suitable, such as some decoding and encoding VPUs, and AI inference scenarios.
-
FPGAs lie somewhere in between.
Although AI-DSAs have broad applications and are performance-sensitive, scenarios such as cloud, edge, and autonomous driving are more comprehensive. AI is one of the fields for computing acceleration, thus independent AI chips will inevitably have a smaller scale of deployment compared to more flexible computing platforms like GPUs, and even less than CPUs and DPUs.
HPU
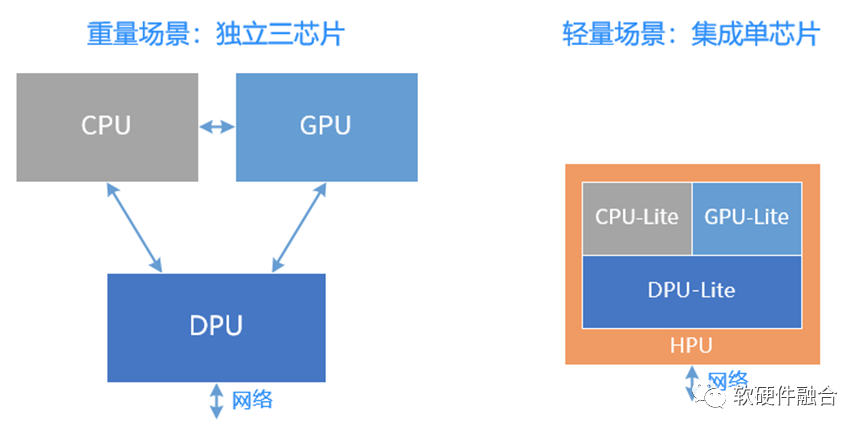
The HPU is a Hyper-heterogeneous Processing Unit, integrating the functions of CPUs, GPUs, and DPUs into a comprehensive chip:
-
The maturity of chiplet packaging technology makes mixed architectures for hyper-heterogeneous computing possible, providing a solid foundation for HPU in terms of processes and packaging.
-
It covers various scenarios, including enterprise servers, edge servers, and storage servers, accounting for about 90% of the entire server scale. This type of server scenario requires relatively lightweight computing, making a single integrated chip sufficient.
-
In contrast, cloud computing business servers are absolutely heavyweight scenarios, requiring independent chips of CPU, GPU, and DPU to form a large system. This scenario accounts for only about 10% of server scale.
Hyper-heterogeneous computing requires innovative architectures: it is essential to clarify that HPU cannot simply be an integration of CPUs, GPUs, and DPUs; rather, it must optimize the entire system’s data interactions to make them more sufficient and efficient (higher bandwidth, lower latency, etc.).
2 The Underlying Logic of Large Chips
2.1 Various Fields and Scenarios Are Essentially Computation
The IaaS layer of cloud computing has four basic service categories:
-
First is computing. Here, computing refers narrowly to the computing environment or platform we provide to users, while networking, storage, and security are the invisible computations to users.
-
A large system where individual computers are interconnected through networks, with computing nodes being computers (or servers), and networking nodes also being computers. Computing and networking usually have distinct boundaries. However, when both sides hit bottlenecks, they find that computational methods can solve networking problems (many network devices and systems are gradually cloudifying); computing increasingly requires the participation of network devices, which have become part of computing clusters.
-
In the vast interconnected system, storage can be viewed as both temporary and persistent. For instance, memory retains its data and programs during a task’s execution, but becomes temporary upon shutdown. This also includes local storage, which is persistent on servers but temporary when viewed in the context of distributed storage across the entire data center. Storage serves as the input, output, and temporary holding of intermediate results for computation.
-
Security permeates every aspect of computing, networking, and storage. It can be viewed as an environment and mechanism that constrains all aspects of computing, networking, and storage.
-
Virtualization is the organizational method of the entire architecture, better organizing the hardware and software of these four components to flexibly and conveniently provide various computing, networking, storage, and security services.
Data-centric, driven by data flow to drive computation:
-
However, data-centric computation cannot be encapsulated in network data flows, as computation still needs to be exposed to users, who must have control over everything;
-
Data-centric computation must expose data flow-driven computation to upper-level user applications, and to achieve better performance, it is necessary to “define everything in software and accelerate everything in hardware.”
All system operations are based on computation, which can be simply summarized as input, computation, and output. Whether narrow computation or virtualization, networking, storage, and security, all can be categorized into a broader definition of computation.
Everything is computation (or everything is for computation)!
2.2 Macro Computing Power Composed of Performance, Scale, and Utilization
The total macro computing power = performance x quantity (scale) x utilization.
Computing power is jointly composed of performance, scale, and utilization, which are interdependent and indispensable:
-
Some computing power chips may achieve explosive performance but neglect the chip’s generality and usability, resulting in low sales and small deployment scale, making it impossible to truly enhance macro computing power.
-
Some computing enhancement solutions focus on scale investment, which has some effect but does not fundamentally solve the future demand for a significant increase in computing power.
-
Some solutions enhance computing power utilization through resource pooling and sharing across different boundaries, but do not change the essence of the performance bottleneck of current computing power chips.
Performance, scale, and utilization are macro and micro; pulling one hair can move the whole body. A narrow view leads to bias; we must consider multiple factors for collaborative design while also macro-managing computing power issues.
2.3 Core Contradiction: Performance vs. Flexibility
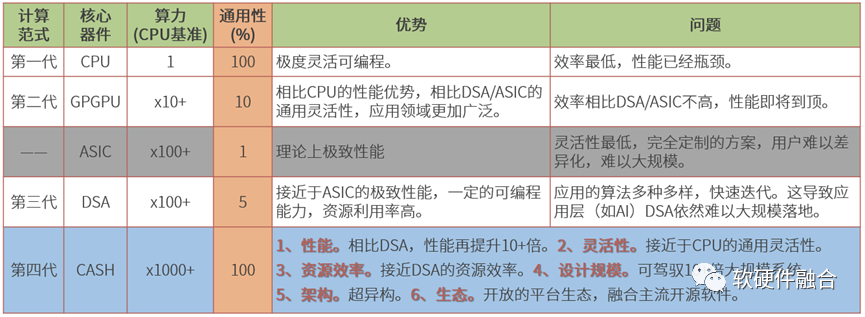
Performance and flexibility are the core contradictions in large chips:
-
CPUs have great flexibility but poor performance. In data center scenarios, if performance is met, the usual server’s main computing chip is still the CPU. Unfortunately, the CPU has reached its performance bottleneck.
-
GPUs can balance performance and flexibility well and are widely used in many heterogeneous computing scenarios.
-
ASICs are completely unusable in complex computing scenarios like data centers due to their extremely low flexibility.
-
While DSAs have improved flexibility compared to ASICs, they still cannot meet the flexibility requirements for application acceleration, such as in AI training scenarios, where DSAs face challenges, and this area is still primarily dominated by GPUs. However, DSAs can better meet some algorithm acceleration needs at the infrastructure level, such as networking DSA scenarios and some AI inference scenarios.
CASH (Compute and Hardware Integration Architecture) is a type of hyper-heterogeneous computing architecture defined by us, achieving “team combat and complementary advantages” through the collaboration of multiple processing engines to balance performance and flexibility.
3 Common Challenges Faced by Large Chips
3.1 Challenge 1: Complex Large Systems Require Higher Flexibility than Performance
There is a classic question: SOCs are very popular at the terminal level, but why do data center servers still rely on CPUs?
The more complex the scenario, the higher the requirements for system flexibility. The CPU’s dominance as the main computing platform in cloud computing has its rationale, reflected in four aspects:
-
Hardware flexibility. Software applications iterate rapidly, and the hardware processing engines supporting software must be able to support these iterations well. The CPU, due to its flexible basic instruction programming characteristics, is the most suitable processing engine for cloud computing.
-
Hardware universality. Cloud computing providers purchase hardware servers and find it challenging to predict which types of tasks these servers will run. The best approach is to use completely general servers. The CPU’s absolute universality makes it the optimal choice for cloud computing scenarios.
-
Hardware utilization. The foundation of cloud computing technology is virtualization, which partitions resources to achieve resource sharing, thereby increasing resource utilization and reducing costs. Only CPUs can achieve very friendly hardware-level virtualization support, thus enabling higher resource utilization. Other hardware acceleration platforms, relatively speaking, struggle to achieve high resource utilization, limiting their performance advantages.
-
Hardware consistency. In cloud computing data centers, software and hardware need to be decoupled. The same software entity may migrate across different hardware entities, and similarly, the same hardware entity must run different software entities. This places high demands on the consistency of hardware platforms.
Given that performance meets requirements, the CPU undoubtedly becomes the best choice for data center computing platforms.
Unfortunately, the current performance of CPUs does not meet requirements. When CPU performance fails to meet expectations, innovative hardware is needed for performance acceleration. How to achieve significant performance improvements while maintaining compatibility with the generality, flexibility, programmability, and usability constraints of traditional CPUs has become a significant challenge.
3.2 Challenge 2: How to Significantly Enhance Overall Performance?
We have previously discussed that performance and the complexity of unit instructions are positively correlated. The simpler the instructions, the relatively lower the performance; the more complex the instructions, the relatively better the performance. However, with simple instructions, we can freely combine various application programs for different scenarios; with complex instructions, the engine’s coverage of fields and scenarios becomes narrower.
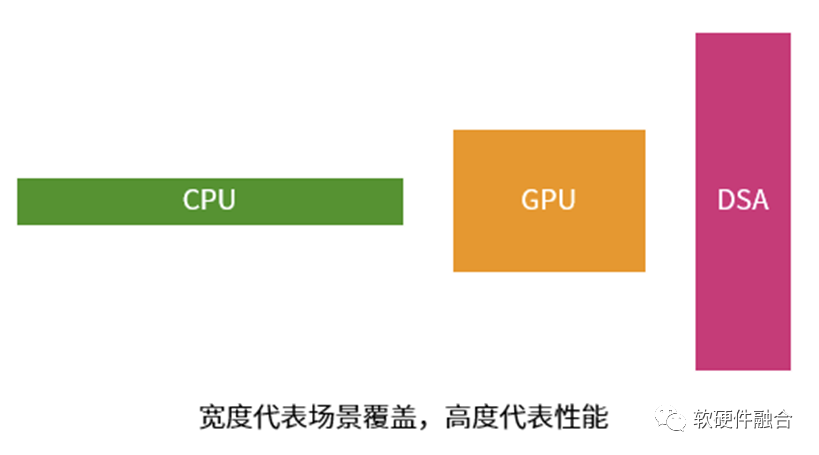
As shown in the above image:
-
CPUs have the poorest performance but can cover almost all computing scenarios, making them the most general processors;
-
DSAs can achieve good performance in specific fields. However, if the covered fields have rapidly updating algorithms or the scope is too narrow to support the large-scale deployment of high-performance chips, such DSA chips are unlikely to be commercially viable.
-
GPUs lie in between.
CPU software is created through the basic instruction combinations needed for business logic; to enhance performance, hardware acceleration essentially solidifies business logic into hardware circuits. While solidifying business logic into circuits improves performance, it constrains the chip’s scenario coverage. Currently, many computing power chip designs are trapped in a paradox: the more performance is optimized, the narrower the scenario coverage; the narrower the scenario coverage, the lower the chip’s shipment volume; lower shipment volume means that the one-time R&D costs cannot be covered, making the commercial logic unsustainable and hindering further R&D.
In AI, for instance, the current difficulties in deploying AI chips stem from the emphasis on deeply understanding algorithms and integrating them into chips. However, due to the diversity of AI algorithms and their rapid iterations, AI chips have struggled to achieve large-scale deployment, with R&D costs in the hundreds of millions being hard to amortize. Thus, as it stands, the commercial logic for AI chips remains unviable.
AI chips have already maximized the performance limits currently achievable; in the future, L4/L5 level autonomous driving chips will require tenfold or hundredfold increases in computing power; achieving the good experience required for the metaverse will necessitate thousandfold or ten-thousandfold increases in computing power. How to ensure that the chip’s scenario coverage remains as universal and comprehensive as that of CPUs while also achieving rapid performance enhancements of tenfold, hundredfold, or even thousandfold is a challenge that high-performance chips must face.
3.3 Challenge 3: Horizontal and Vertical Variability of Business
Horizontal variability refers to the detail differences in similar businesses between different customers, while vertical variability refers to the long-term iterative differences in a single user’s business.
Different users’ businesses exhibit variability; even within a large company, different teams may have inconsistent business requirements for the same scenario. Moreover, even for the same customer, rapid software updates can lead to swift changes in business logic that outpace hardware chip updates (software iterations typically happen every 3-6 months, while chip iterations take 2-3 years, considering the 4-5 year lifecycle of chips).
To address horizontal and vertical variability, the industry has several notable approaches:
-
Some chip manufacturers provide what they believe to be the optimal business logic acceleration solutions based on their understanding of the scenarios. However, from the user’s perspective, this can lose their uniqueness and creativity. Users may need to modify their business logic, which carries significant risks and creates strong dependencies on chip companies.
-
Some large customers develop their chips tailored to their unique scenarios, which can enhance their competitive edge. However, large customers are often composed of many different small teams, leading to persistent differences in business scenarios. Additionally, the long-term iterative differences in a single business still need to be considered. Custom chips may be commercially viable, but they must consider the technical aspects of general chip design.
-
Third-party generic solutions. “Teaching a man to fish” is better than “giving a man a fish”; through generic designs, we can ensure a certain degree of hardware-software decoupling in every field. Chip companies provide a “generic” hardware platform, allowing users to achieve business differentiation through programming, enabling users to maintain control.
3.4 Challenge 4: High One-Time Costs of Chips
3.5 Challenge 5: Macro Computing Power Requires Chips to Support Large-Scale Deployment
Performance and flexibility are contradictory; many performance-optimized chip design solutions significantly enhance performance while reducing the chip’s generality, flexibility, and usability, thereby lowering the chip’s scenario and user coverage. This leads to a small deployment scale for the chips.
A small deployment scale means that no matter how high the performance of a single chip, it becomes meaningless.
Therefore, a comprehensive chip platform needs to consider how to improve the macro scale deployment of chips while enhancing chip performance: it must consider the scenario coverage of the chip; it must consider the user coverage of the chip; it must consider the horizontal and vertical variability of the chip’s functionality.
Only by balancing performance with broader user and scenario coverage can large chips achieve scalable deployment, thereby significantly enhancing macro computing power.
3.6 Challenge 6: Integration of Computing Platforms
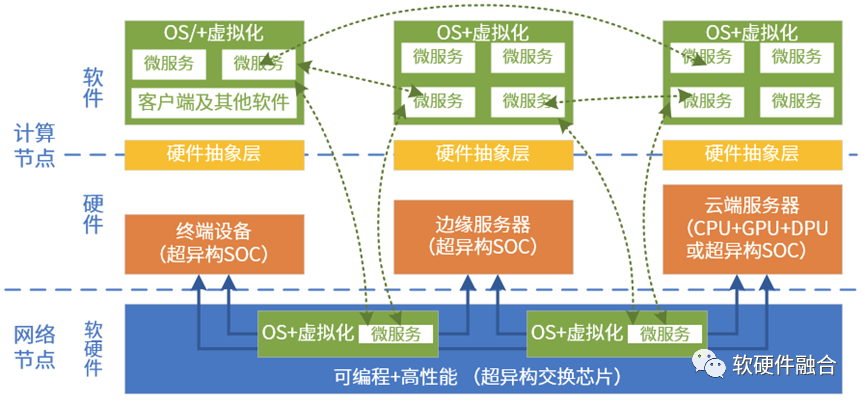
Computing power needs to be pooled, and this pooling is not limited to data center-based x86 CPU computing power; it requires:
-
Computing power needs to cross different CPU architectures, integrating the computing power of mainstream architectures like x86, ARM, and RISCv into one pool;
-
Computing power needs to integrate different types of processing engines, such as combining the computing power of CPUs, GPUs, FPGAs, and DSAs into one pool;
-
Computing power also needs to integrate hardware platforms from different vendors, pooling computing resources provided by various vendors into one pool;
-
Computing power needs to span different locations, deploying across cloud, edge, and on-premises, pooling these computing resources into one pool.
Cloud-edge integration means pooling all computing resources together to truly achieve adaptive software execution across cloud, edge, and on-premises. The challenge lies in how to build a unified and open hardware platform and system stack.
3.7 Challenge 7: High Barriers to Ecosystem Development
Large chips must be platformized and require a development framework to form a development ecosystem. However, the high barriers to frameworks and ecosystems, which require long-term accumulation, make it very challenging for small companies.
The RISC-V CPU is thriving, with many companies, especially startups, recognizing the open-source philosophy and value of RISC-V. The collective effort is driving the vigorous development of the RISC-V open ecosystem.
In the future, as computing further shifts towards heterogeneous and hyper-heterogeneous computing, with more architectures and platforms emerging, open-source will no longer be optional but a necessity. If not open-source, it will lead to complete fragmentation of computing resources, making it impossible to pool computing power or achieve cloud-edge integration.
Open-source is an inevitable choice for building large chip platforms and ecosystems.
3.8 Challenge 8: (User Perspective) Macro Cross-Platform Challenges with No Platform Dependence
From the chip manufacturer’s perspective, providing customers with chips and supporting software, followed by SDKs and development toolkits, seems adequate. However, from the user’s perspective, the situation is different. Users’ software applications are entirely decoupled from hardware platforms.
Taking VM computing virtualization as an example, users’ VMs need to be able to migrate in real-time across different hardware platforms, which necessitates hardware platform consistency. Typically, hardware consistency is achieved through virtualization, which abstracts a standard hardware platform for upper-level VMs, allowing VMs to run across different architectures of hardware servers. As CPU performance hits a bottleneck, virtualization-related stacks have gradually sunk into hardware acceleration, necessitating direct exposure of hardware interfaces to business VMs, which requires native support for consistency in hardware architecture/interfaces.
Native support for consistency in hardware architecture/interfaces means that chip platforms from different manufacturers provide the same architecture and interfaces, enabling software to easily migrate across various hardware platforms from different manufacturers. If a manufacturer provides a proprietary architecture/interface hardware platform, users will develop a strong dependency on that platform. Furthermore, the more personalized platforms chosen, the more fragmented the user’s data center becomes, complicating the overall operation and management of the cloud.
Reprinted content represents only the author’s views
Not the position of the Institute of Semiconductors, Chinese Academy of Sciences
Editor: Qian Niao
