This article collects a series of AIGC content generation and processing, and you can find more exciting articles about AIGC content generation and processing in the service menu of the public account.
Represented by large models, the new round of technological revolution and industrial transformation driven by AI is advancing deeply, and various industries will face tremendous opportunities and disruptive challenges. In the field of content production, AIGC content generation is the key force driving the transformation of new media, and the landing of industry large models will provide new paths for media companies to explore new media technology revolutions.
In this round of AI revolution, AI hardware boards are the core of AI computing power. Without AI hardware computing power support, no matter how large the model is, it is useless. Even the simplest model parameter tuning requires AI computing power boards for support, or it has to rely on open cloud resources, which also ultimately depend on professional AI computing power boards.
At the same time, we also see the shortage of AI computing infrastructure in China. Currently, data centers and cloud computing centers are not built around CPUs, but around GPUs, which require a comprehensive understanding of the importance of GPUs.
This series of articles will detail the rise of AI computing power boards GPU, the leading NVIDIA in AI hardware computing power boards, and the situation of domestic AI computing hardware boards, exploring which will become the domestic alternative to NVIDIA.
In previous articles, we introduced NVIDIA’s GPU development stance, the logic of CUDA cores and programming, as well as the contents of NvLink and NvSwitch, and the InfiniBand infinite bandwidth and its products. These products are from a chip company. In this issue, we will discuss NVIDIA’s SuperPOD cluster product and HGX.
-
01. NVIDIA’s SuperPOD
DGX SuperPOD is a highly integrated supercomputing solution launched by NVIDIA, aimed at providing high-performance artificial intelligence computing capabilities for enterprises and research institutions. This solution allows users to quickly build and deploy large-scale GPU clusters to tackle complex AI and machine learning challenges.
NVIDIA DGX SuperPOD enterprise solutions optimize every component in the system to address the unique needs of multi-node AI infrastructure, solving this scalability issue. Selene, built on the same DGX SuperPOD architecture, is NVIDIA’s own DGX SuperPOD deployment solution and is an outstanding supercomputer in terms of speed and energy efficiency worldwide.
In 2019, NVIDIA built the first generation of SuperPOD systems based on multiple DGX systems, ranking among the top 20 in performance worldwide at a cost and energy consumption far below that of typical supercomputers.
In 2020, NVIDIA unveiled the second generation of SuperPOD. This product not only boasts record-breaking performance but can also be deployed in just three weeks. Its emergence has eliminated the need for months of time to build world-class AI supercomputing clusters. The second generation SuperPOD is built on the DGX A100 system and Mellanox network architecture, proving that the processing time for the world’s most complex language understanding models can be reduced from weeks to within an hour using a single platform.

NVIDIA’s DGX SuperPOD architecture consists of multiple DGX GB200 systems. Each DGX GB200 system contains 36 GB200 accelerator cards, each with 2 Blackwell GPUs, so each DGX GB200 system contains a total of 72 Blackwell GPUs. By default, a DGX SuperPOD consists of 8 DGX GB200 systems. This means that in a standard configuration of a DGX SuperPOD, there are a total of: 8 * 72 = 576. Therefore, a standard configuration of a DGX SuperPOD consists of 576 Blackwell GPUs. It is important to note that DGX SuperPOD is scalable, and theoretically, the scale of the entire cluster can be expanded by adding more DGX GB200 systems. Thus, there may be more GPU nodes in actual deployments. However, in terms of default configuration, it contains 576 GPU nodes.

In traditional building processes, a key task is to plan in advance how large your infrastructure needs to be, and then start building the network architecture until the final goal is reached. While this method can achieve growth, it incurs a lot of upfront costs. Building a traditional data center not only requires a large professional technical team but often takes months to complete, with high costs in time, space, and money.
The new generation of DGX SuperPOD not only has terrifying computing performance but also has greatly improved deployment efficiency. It has been proven that four operators specially allocated by NVIDIA can assemble a DGX A100 cluster consisting of 20 systems in less than an hour, and with Mellanox’s switching capabilities, multiple systems can be easily interconnected to ultimately achieve the scale of a SuperPOD. Additionally, as mentioned earlier, under the same bandwidth, the new generation SuperPOD can save up to 15 times the physical space of data centers compared to traditional CPU clusters.
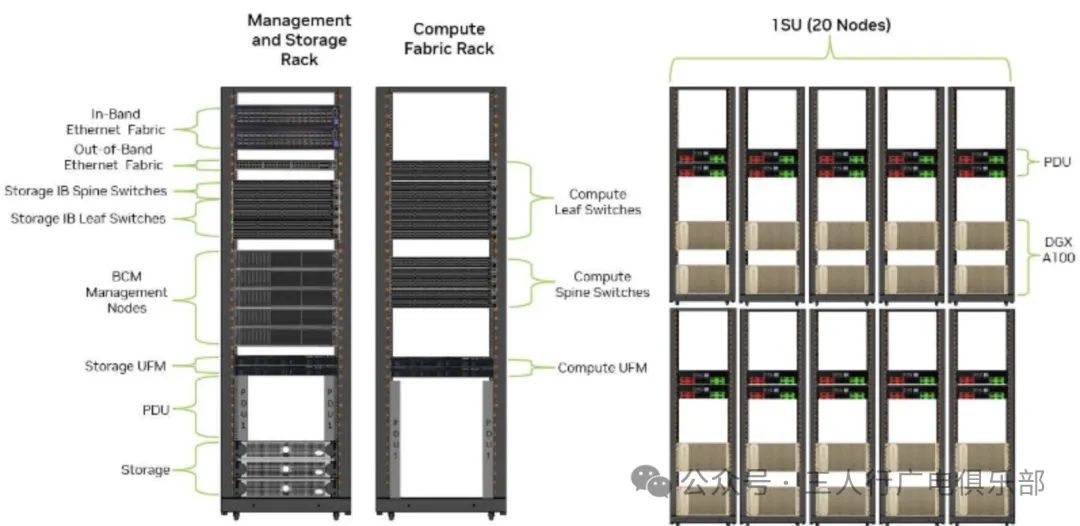
-
02. What is NVIDIA’s HGX?
HGX is NVIDIA’s large-scale GPU accelerator, symbolizing the flexibility and customization of AI hardware solutions. It provides OEM manufacturers with a highly customizable hardware platform that meets specific customer needs for tuning and optimization. The HGX platform emphasizes flexibility, offering a rich selection for various industries and application scenarios.

HGX is a modular AI supercomputing platform with performance comparable to DGX systems. To meet the diverse needs of original equipment manufacturers (OEMs), HGX provides highly customized hardware solutions that precisely match specific customer requirements. It emphasizes flexibility and personalization, allowing customers to freely configure CPU, RAM, storage, and networking to create a tailored optimized system.

HGX is just a computing module, allowing users to add or remove the number of GPUs based on their computational needs. In terms of customization, HGX performs exceptionally well, allowing users to customize the configuration within the machine according to their requirements. In contrast, DGX has less customization, with fixed hardware configurations. HGX is like assembling a computer, while DGX is a complete host.
HGX mainly targets researchers and developers who need a flexible and scalable platform to meet high-performance computing requirements. It is suitable for cloud data centers, high-performance computing, large-scale AI research and development, and customizable infrastructure applications.
DGX is designed for enterprises that require powerful, ready-to-use AI solutions. It is particularly suitable for applications in artificial intelligence and deep learning development, edge computing, healthcare and medical research, as well as content creation and media.
HGX features a modular design with flexible pricing. DGX is a high-end all-in-one solution with a high price tag.
However, the high price of DGX is not absolute. If DGX is overkill for your needs, and you only require 4 GPUs, or 2 GPUs, then DGX is indeed more expensive compared to HGX. But if you need 8 GPUs, then DGX may offer better cost-effectiveness for you.
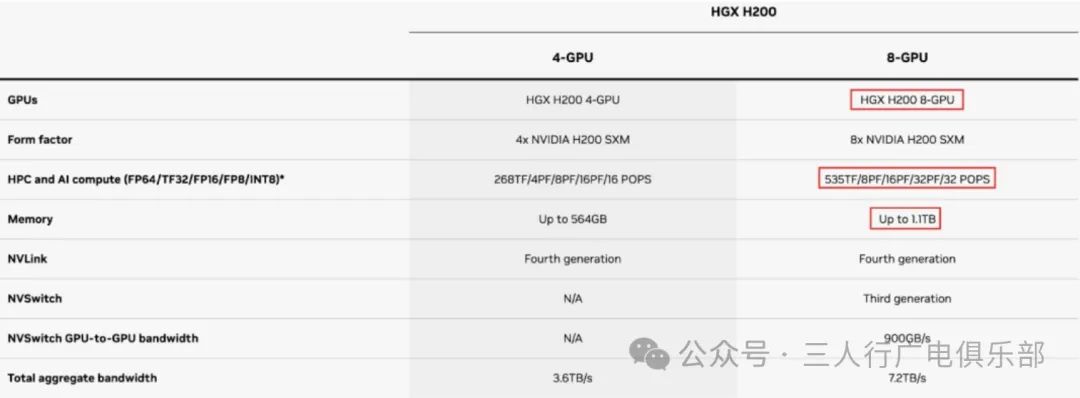
When purchasing HGX, you also need to buy additional CPU, memory, hard drives, etc., which is an extra expense. Additionally, you need to equip operational engineers who understand hardware maintenance.
Taking the H100 as an example, the 4-GPU version of HGX does not support NV Switch, while the 8-GPU version of HGX can support the third-generation NV Switch. NV Switch supports advanced multi-GPU communication within and between servers. In contrast, DGX supports the combination of fourth-generation NVLink and NVSwitch™, providing a connection of 900 GB per second between each GPU in every DGX H100 system.
In summary, with the same number of GPUs, DGX will have stronger computing capability than HGX.
Follow us and give us a thumbs up as it is our motivation for continuous updates.