Background
This article is derived from a previous Weibo post I made:

However, the purpose of writing this article is not to help everyone prepare for interviews, but to use this question to introduce basic knowledge of computers and the internet, allowing readers to understand how they are interconnected.
For ease of understanding, I will break down the entire process into six questions.
First Question: What Happens from Inputting a URL to the Browser Receiving It?
From Touchscreen to CPU
First is the “input URL”; most people’s first reaction would be the keyboard, but to keep up with the times, I will introduce the interaction of touchscreen devices here.
A touchscreen is a type of sensor, most of which are currently based on capacitive technology. Previously, they were directly overlaid on the display, but recently three technologies have emerged that are embedded within the display: the first is the In-cell technology used in the iPhone 5, which reduces thickness by 0.5 mm; the second is the On-cell technology used by Samsung; and the third is the OGS full lamination technology favored by domestic manufacturers. For specific details, you can read this article: http://www.igao7.com/news/201406/in-cell-on-cell-ogs.html.
When a finger touches this sensor, some electrons are transferred to the finger, causing a voltage change in that area. The touchscreen controller chip can calculate the touched position based on this change and then send the signal to the CPU’s pins via a bus interface.
Taking the Nexus 5 as an example, it uses the Synaptics S3350B touchscreen controller, and the bus interface is I²C. Below is an example of the connection between the Synaptics touchscreen and the processor:
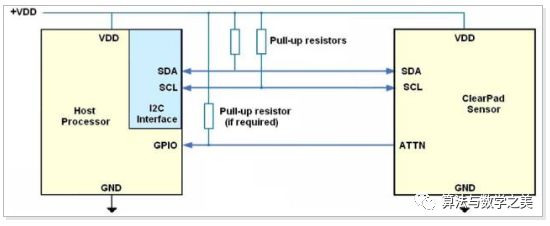
On the left is the processor, and on the right is the touchscreen controller. The SDA and SCL connections in the middle are the I²C bus interface.
Processing Inside the CPU
The CPU in mobile devices is not a standalone chip but is integrated with other chips like the GPU, referred to as SoC (System on Chip).
As mentioned earlier, the connection between the touchscreen and the CPU is similar to most internal connections in computers, which communicate through electrical signals, specifically voltage changes, as shown in the timing diagram below:

Under clock control, these currents pass through MOSFET transistors, which contain N-type and P-type semiconductors. The voltage can control the opening and closing of the circuit, and these MOSFETs form CMOS, which then implements logic gates such as AND, OR, and NOT, allowing for calculations like addition and shifting, as shown in the overall diagram below (from “Computer Architecture”):
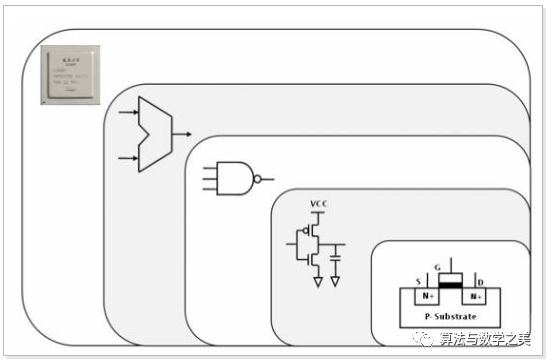
In addition to calculations, the CPU also requires storage units to load and store data, which are generally implemented using flip-flops, known as registers.
These concepts are quite abstract, and I recommend reading “How to Build an 8-Bit Computer” http://www.instructables.com/id/How-to-Build-an-8-Bit-Computer/, where the author builds an 8-bit computer using transistors, diodes, capacitors, etc., supporting simple assembly instructions and output. Although modern CPUs are much more complex, the basic principles remain the same.
Additionally, I am also just starting to learn about CPU chip implementation, so I won’t mislead anyone here. Interested readers should refer to the recommended books at the end of this section.
From CPU to Operating System Kernel
As mentioned earlier, the touchscreen controller sends electrical signals to the corresponding pins on the CPU, which then triggers the CPU’s interrupt mechanism. In the case of Linux, each external device has an identifier known as the Interrupt Request (IRQ) number, which can be viewed in the /proc/interrupts file. Below are some results from the Nexus 7 (2013):
shell@flo:/ $ cat /proc/interrupts CPU0 17: 0 GIC dg_timer 294: 1973609 msmgpio elan-ktf3k 314: 679 msmgpio KEY_POWER
Since the Nexus 7 uses the ELAN touchscreen controller, the elan-ktf3k in the results is the interrupt request information for the touchscreen, where 294 is the interrupt number and 1973609 is the number of triggers (a finger click generates two interrupts, while a swipe can generate hundreds).
To simplify, we will not consider priority issues here. Taking an ARMv7 architecture processor as an example, when an interrupt occurs, the CPU stops the currently running program, saves the current execution state (such as the PC value), enters IRQ state, and then jumps to the corresponding interrupt handler. This program is generally implemented by third-party kernel drivers, such as the driver source code for the Nexus 7 mentioned earlier, located here: touchscreen/ektf3k.c.
This driver reads the position data sent over the I²C bus and records the touchscreen press coordinates using methods like input_report_abs in the kernel. Finally, the input submodule in the kernel writes this information into the /dev/input/event0 device file. For example, below is the information generated by a touch event:
130|shell@flo:/ $ getevent -lt /dev/input/event0[ 414624.658986] EV_ABS ABS_MT_TRACKING_ID 0000835c[ 414624.659017] EV_ABS ABS_MT_TOUCH_MAJOR 0000000b[ 414624.659047] EV_ABS ABS_MT_PRESSURE 0000001d[ 414624.659047] EV_ABS ABS_MT_POSITION_X 000003f0[ 414624.659078] EV_ABS ABS_MT_POSITION_Y 00000588[ 414624.659078] EV_SYN SYN_REPORT 00000000[ 414624.699239] EV_ABS ABS_MT_TRACKING_ID ffffffff[ 414624.699270] EV_SYN SYN_REPORT 00000000
From Operating System GUI to Browser
As mentioned earlier, the Linux kernel has completed the abstraction of hardware, and other programs only need to listen for changes in the /dev/input/event0 file to know what touch operations the user has performed. However, if every program did this, it would be too cumbersome, so graphical operating systems typically include a GUI framework to facilitate application development, such as the well-known X under Linux.
However, Android does not use X but has implemented its own GUI framework. One of its services, EventHub, listens to files in the /dev/input/ directory using epoll and then passes this information to Android’s Window Manager Service, which looks up the corresponding app based on the position information and calls its listener functions (such as onTouch, etc.).
Thus, we have answered the first question, but due to time constraints, many details have been omitted. Interested readers are recommended to read the following books for further study.
Further Learning
-
Computer Architecture
-
Computer Architecture: A Quantitative Approach
-
Computer Organization and Design: The Hardware/Software Interface
-
Code
-
Introduction to CPU Design
-
Operating System Concepts
-
ARMv7-A Architecture Reference Manual
-
Linux Kernel Design and Implementation
-
Mastering Linux Device Driver Development
Second Question: How Does the Browser Send Data to the Network Card?
From Browser to Browser Kernel
As mentioned earlier, the operating system GUI passes input events to the browser. During this process, the browser may perform some preprocessing. For example, Chrome estimates the website corresponding to the input characters based on historical statistics. For instance, if “ba” is input, it may find that there is a 90% chance of visiting “www.baidu.com,” so it starts establishing a TCP connection and even rendering before the user presses Enter. There are many other strategies involved; interested readers are recommended to read “High Performance Networking in Chrome” http://aosabook.org/en/posa/high-performance-networking-in-chrome.html.
Next, after inputting the URL and pressing “Enter,” the browser checks the URL, first determining the protocol. If it is HTTP, it processes it as a web request. It also performs a security check on the URL and then directly calls the corresponding method in the browser kernel, such as the loadUrl method in WebView.
In the browser kernel, it first checks the cache, then sets the UA and other HTTP information, and then calls the network request methods for different platforms.
It is important to note that the browser and the browser kernel are different concepts. The browser refers to Chrome, Firefox, etc., while the browser kernel refers to Blink, Gecko, etc. The browser kernel is only responsible for rendering, while the GUI and cross-platform network connections are implemented by the browser.
Sending HTTP Requests
Since the underlying implementation of the network is related to the kernel, this part needs to be handled differently for different platforms. From the application layer perspective, it mainly does two things: querying the IP through DNS and sending data through sockets. Next, I will introduce these two aspects.
DNS Query
Applications can directly call the getaddrinfo() method provided by Libc to perform DNS queries.
DNS queries are actually based on UDP. Here, we will understand its lookup process through a specific example. Below are the results obtained using the command dig +trace fex.baidu.com (some parts omitted):
; <<>> DiG 9.8.3-P1 <<>> +trace fex.baidu.com;; global options: +cmd. 11157 IN NS g.root-servers.net.. 11157 IN NS i.root-servers.net.. 11157 IN NS j.root-servers.net.. 11157 IN NS a.root-servers.net.. 11157 IN NS l.root-servers.net.;; Received 228 bytes from 8.8.8.8#53(8.8.8.8) in 220 mscom. 172800 IN NS a.gtld-servers.net.com. 172800 IN NS c.gtld-servers.net.com. 172800 IN NS m.gtld-servers.net.com. 172800 IN NS h.gtld-servers.net.com. 172800 IN NS e.gtld-servers.net.;; Received 503 bytes from 192.36.148.17#53(192.36.148.17) in 185 msbaidu.com. 172800 IN NS dns.baidu.com.baidu.com. 172800 IN NS ns2.baidu.com.baidu.com. 172800 IN NS ns3.baidu.com.baidu.com. 172800 IN NS ns4.baidu.com.baidu.com. 172800 IN NS ns7.baidu.com.;; Received 201 bytes from 192.48.79.30#53(192.48.79.30) in 1237 msfex.baidu.com. 7200 IN CNAME fexteam.duapp.com.fexteam.duapp.com. 300 IN CNAME duapp.n.shifen.com.n.shifen.com. 86400 IN NS ns1.n.shifen.com.n.shifen.com. 86400 IN NS ns4.n.shifen.com.n.shifen.com. 86400 IN NS ns2.n.shifen.com.n.shifen.com. 86400 IN NS ns5.n.shifen.com.n.shifen.com. 86400 IN NS ns3.n.shifen.com.;; Received 258 bytes from 61.135.165.235#53(61.135.165.235) in 2 ms
This shows a step-by-step narrowing down of the lookup process. First, the DNS server set on the local machine (8.8.8.8) queries the DNS root node for the domain server responsible for the .com zone, then queries one of the servers responsible for .com to find the server responsible for baidu.com, and finally queries one of the baidu.com domain servers for the address of fex.baidu.com.
You may find that when querying certain domain names, the results differ from the above, as you may see a strange server returning results ahead of time…
For convenience of description, many different situations have been ignored here, such as 127.0.0.1 actually going through the loopback, which has nothing to do with the network card device; for example, Chrome pre-queries 10 domain names you might visit when the browser starts; and the influence of the Hosts file and TTL (Time to Live).
Sending Data via Socket
Once the IP address is obtained, data can be sent using the Socket API, choosing either TCP or UDP protocol. The specific usage will not be introduced here; I recommend reading “Beej’s Guide to Network Programming”.
HTTP commonly uses the TCP protocol, and since the specific details of the TCP protocol are widely available, I will not introduce them here. Instead, I will discuss the TCP Head-of-line blocking issue: suppose the client sends three TCP segments numbered 1, 2, and 3. If the packet numbered 1 is lost during transmission, even if packets 2 and 3 have already arrived, they must wait because the TCP protocol requires order. This issue is even more severe under HTTP pipelining, as HTTP pipelining allows multiple HTTP requests to be sent through one TCP connection. For example, if two images are sent, the data for the second image may have been fully received, but it still has to wait for the data of the first image to arrive.
To address the performance issues of the TCP protocol, the Chrome team proposed the QUIC protocol last year, which is based on UDP for reliable transmission. Compared to TCP, it can reduce many round-trip times and includes features like Forward Error Correction. Currently, most Google products, including Google Plus, Gmail, Google Search, Blogspot, and YouTube, use QUIC, which can be discovered through the chrome://net-internals/#spdy page.
Although currently only Google uses QUIC, I believe it has great potential because optimizing TCP requires upgrading the system kernel (such as Fast Open).
Browsers have a connection limit for the same domain, usually around 6. I previously thought that increasing this connection limit would improve performance, but in fact, it does not. The Chrome team conducted experiments and found that changing it from 6 to 10 actually decreased performance. There are many factors contributing to this phenomenon, such as the overhead of establishing connections and congestion control issues. Protocols like SPDY and HTTP 2.0, despite using only one TCP connection to transmit data, perform better and can also implement request prioritization.
Additionally, since HTTP requests are in plain text format, the HTTP text can be directly analyzed in the TCP data segment. If it is found…
Socket Implementation in the Kernel
As mentioned earlier, the cross-platform library of the browser sends data by calling the Socket API. So how is the Socket API implemented?
Taking Linux as an example, its implementation can be found here: socket.c. Currently, I am not very familiar with it, so I recommend readers to check out the Linux kernel map http://www.makelinux.net/kernel_map/, which marks the key path functions, making it easier to learn the implementation from the protocol stack to the network card driver.
Specific Examples of Lower-Level Network Protocols
Next, if I continue to introduce the IP protocol and MAC protocol, many readers may get confused, so this section will use Wireshark to explain through specific examples. Below is the network data captured when I requested the Baidu homepage:
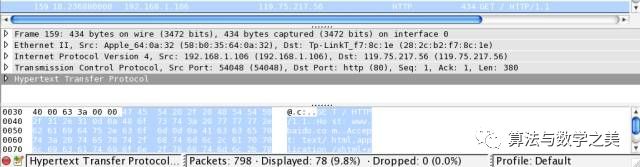
At the bottom is the actual binary data, and in the middle are the parsed field values. You can see that the bottom part is the HTTP protocol (Hypertext Transfer Protocol). There are 54 bytes (0x36) before HTTP, which is the overhead brought by the lower-level network protocols. Next, we will analyze these protocols.
Above HTTP is the TCP protocol (Transmission Control Protocol), and its specific content is shown in the diagram below:
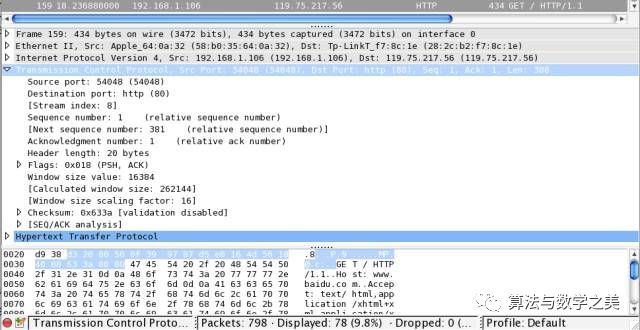
From the binary data at the bottom, we can see that the TCP protocol is added before the HTTP text. It has 20 bytes, which define the local port (Source port) and destination port (Destination port), sequence number (Sequence Number), window size, and other information. Below is a complete introduction to each part of the TCP protocol data:
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| Source Port | Destination Port |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| Sequence Number |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| Acknowledgment Number |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| Data | |U|A|E|R|S|F| || Offset| Reserved |R|C|O|S|Y|I| Window || | |G|K|L|T|N|N| |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| Checksum | Urgent Pointer |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| Options | Padding |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| data |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
The specific functions of each field will not be introduced here. Interested readers can read RFC 793 and combine packet analysis to understand.
It is important to note that the TCP protocol does not contain IP address information, as this is defined in the previous layer, the IP protocol, as shown in the diagram below:
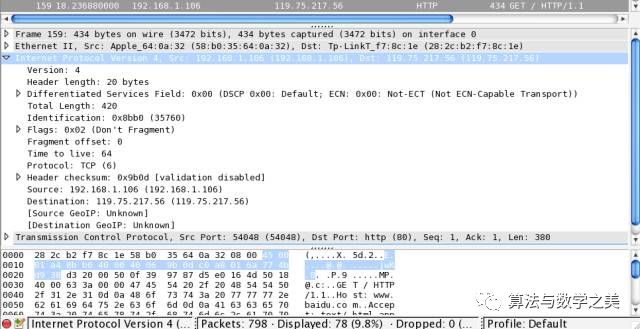
The IP protocol is also in front of TCP, and it also has 20 bytes, indicating the version number (Version) as 4, source (Source) IP as 192.168.1.106, and destination (Destination) IP as 119.75.217.56. Therefore, the most important function of the IP protocol is to determine the IP address.
Since the target IP address can be viewed in the IP protocol, if certain specific IP addresses are found, some routers will…
However, relying solely on the IP address is insufficient for communication, as the IP address is not bound to a specific device. For example, your laptop’s IP may be 192.168.1.1 at home but change to 172.22.22.22 at work. Therefore, a fixed address is needed for lower-level communication, which is the MAC (Media Access Control) address. Each network card has a fixed and unique MAC address assigned at the factory.
Thus, the MAC protocol is next, which has 14 bytes, as shown below:
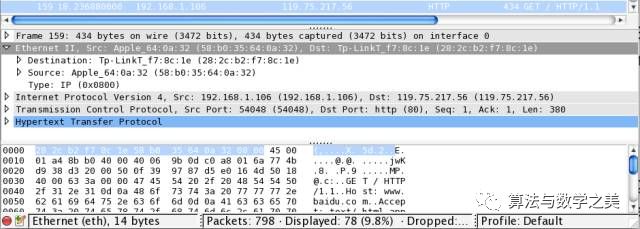
When a computer joins the network, it needs to inform other network devices of its IP and corresponding MAC address through the ARP protocol, so that other devices can find the corresponding device using the IP address.
The topmost Frame represents the packet capture number from Wireshark and is not a network protocol.
Further Learning
-
Computer Networking: A Top-Down Approach with Internet Features
-
Computer Networking
-
The Definitive Guide to Web Performance
Third Question: How is Data Sent from the Local Network Card to the Server?
From Kernel to Network Adapter (Network Interface Card)
As mentioned earlier, after calling the Socket API, the kernel will encapsulate the data into the lower-level protocol stack and then activate the DMA controller, which will read data from memory and write it to the network card.
Taking the Nexus 5 as an example, it uses the Broadcom BCM4339 chip for communication, and the interface is similar to that of an SD card using SDIO. However, the details of this chip are not publicly available, so I will not discuss it here.
Connecting to Wi-Fi Router
The Wi-Fi network card needs to communicate with the outside world through a Wi-Fi router. The principle is based on radio waves, where current changes generate radio waves, a process known as “modulation.” Conversely, radio waves can cause electromagnetic field changes, resulting in current changes, and this principle allows the information in the radio waves to be interpreted, known as “demodulation.” The frequency of these changes per unit time is referred to as frequency, and currently, Wi-Fi uses two frequency bands: 2.4 GHz and 5 GHz.
Within the same Wi-Fi router, since the frequencies used are the same, conflicts may occur when multiple devices are used simultaneously. To solve this problem, Wi-Fi employs a method called CSMA/CA, which simply means confirming whether the channel is in use before transmitting data.
Similarly, 2G/3G/LTE, which is also based on radio principles, encounters similar issues, but it does not use the exclusive scheme like Wi-Fi. Instead, it uses frequency division (FDMA), time division (TDMA), and code division (CDMA) for multiplexing. The specific details will not be elaborated here.
Taking the Xiaomi router as an example, it uses the BCM 4709 chip, which consists of an ARM Cortex-A9 processor and flow hardware acceleration. Using hardware chips can avoid operations like operating system interrupts and context switching, thus improving performance.
The operating system in the router can be developed based on OpenWrt or DD-WRT, but I am not very familiar with the specific details, so I will not elaborate.
Since internal network devices have IP addresses like 192.168.1.x, which cannot be directly accessed from the outside, the router modifies the relevant addresses and ports during the routing process. This operation is called NAT mapping.
Finally, home routers are generally connected to the carrier’s network via twisted pair cables.
Routing within the Carrier Network
Data sent over twisted pair cables to the carrier network will pass through many intermediate routers. Readers can use the traceroute command or online visualization tools to view the IPs and locations of these routers.
When data reaches these routers, they extract the destination address prefix from the packet and look up the corresponding output link in the internal forwarding table. But how is this forwarding table obtained? This is the most important routing algorithm in routers, and there are many options available. I am not very familiar with this area, but it seems that the Wikipedia entry lists them comprehensively.
Transmission Between Backbone Networks
For long-distance data transmission, fiber optic cables are typically used as the medium. Fiber optics operate based on total internal reflection of light. Using fiber optics requires a dedicated transmitter to convert electrical signals into light through electroluminescence (e.g., LED). Compared to the previously mentioned radio waves and twisted pair cables, fiber optic signals have much stronger anti-interference capabilities and consume much less power.
Since data is transmitted based on light, the transmission speed depends on the speed of light. The speed of light in a vacuum is nearly 300,000 kilometers per second, but due to the refractive index of the fiber cladding being 1.52, the actual speed of light is around 200,000 kilometers per second. The distance from Beijing Capital Airport to Guangzhou Baiyun Airport is 1967 kilometers, which means it takes about 10 milliseconds to reach. This means that if you are in Beijing and the server is in Guangzhou, you will have to wait at least 20 milliseconds for the data to be sent to the server and back. The actual situation is expected to be 2-3 times longer due to the time taken for processing at various routing nodes. For example, I tested an IP in Guangzhou and found an average latency of 60 milliseconds.
This latency is something that current technology cannot solve (unless a method faster than light is found). It can only be reduced by using CDNs to shorten transmission distances or minimizing serial round-trip requests (such as the three-way handshake required to establish a TCP connection).
IDC Internal Network
Data transmitted via fiber optics will eventually reach the IDC server room, entering the IDC internal network. At this point, the traffic can first be mirrored through a splitter for security checks and analysis, and can also be used for…
The bandwidth cost here is very high, calculated based on peak values, at a price of over 100,000 RMB per month per Gbps (note that this refers to bits, not bytes). In Beijing, the price is above 100,000 RMB, and general websites use between 1G to 10G.
Next, the data in the fiber will enter the cluster switch and then be forwarded to the top switch of the rack, finally sending the data to the servers in the rack through the ports of this switch. You can refer to the diagram below (from Open Compute):
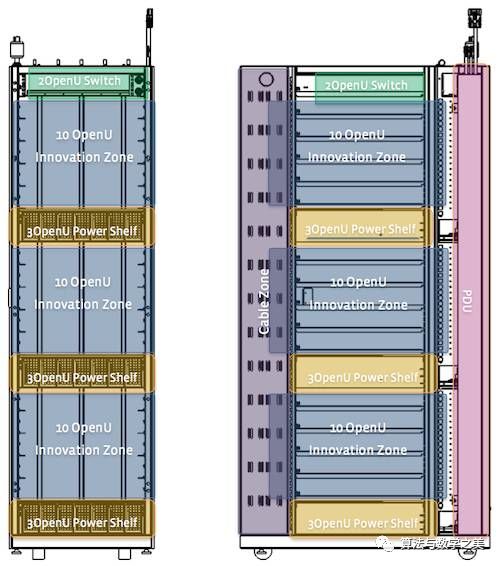
The left side of the diagram shows the front view, and the right side shows the side view, where the top is reserved for the switch.
Previously, the internal implementation of these switches was closed, and related manufacturers (such as Cisco, Juniper, etc.) used specific processors and operating systems, making it difficult for external control. Sometimes manual configuration was even required. However, in recent years, with the popularity of OpenFlow technology, open switch hardware has emerged, such as Intel’s network platform. I recommend interested readers to check out their videos, as they are much clearer than textual descriptions.
It is important to note that the switches mentioned in general networking books only have layer 2 (MAC protocol) functionality, but the switches in the IDC generally have layer 3 (IP protocol) functionality, so there is no need for dedicated routing.
Finally, since the CPU processes electrical signals, the light signals in the fiber must first be converted into electrical signals using related devices through the photoelectric effect before entering the server’s network card.
Server CPU
As mentioned earlier, data has reached the server’s network card. The network card will copy the data to memory (DMA) and then notify the CPU through an interrupt. Currently, the server-side CPU is mostly Intel Xeon, but in recent years, some new architectures have emerged. For example, in the storage field, Baidu uses ARM architecture to increase storage density because ARM consumes much less power than Xeon. In the high-performance field, Google is currently trying to develop servers based on the POWER architecture CPU, with the latest POWER8 processor capable of executing 96 threads in parallel, which should be very helpful for high-concurrency applications.
Further Learning
-
The Datacenter as a Computer
-
Open Computer
-
Software-Defined Networking
-
Wireless Communication Explained
Fourth Question: What Processing Does the Server Perform After Receiving Data?
To avoid repetition, I will not introduce the operating system again but will directly enter the backend service process. Due to the many technical choices in this area, I will only introduce a few common public parts.
Load Balancing
Requests may first pass through a load balancer machine before entering the actual application server. Its role is to distribute requests reasonably across multiple servers while also providing attack prevention features.
There are many implementations of load balancing, including hardware-based F5, LVS on the operating system transport layer (TCP), and reverse proxies (also known as layer 7 proxies) implemented at the application layer (HTTP). Next, I will introduce LVS and reverse proxies.
There are many strategies for load balancing. If the multiple servers behind it have balanced performance, the simplest method is to loop through them one by one (Round-Robin). Other strategies will not be introduced here; you can refer to the algorithms in LVS.
LVS
The role of LVS is to present only one IP to the outside world, while in reality, this IP corresponds to multiple machines, hence it is also called a Virtual IP.
The previously mentioned NAT is also a working mode in LVS. In addition, there are DR and TUNNEL modes, but I will not elaborate on them here, as their disadvantage is that they cannot cross network segments. Therefore, Baidu developed its own BVS system.
Reverse Proxy
Reverse proxies work at the HTTP level, and specific implementations can be based on HAProxy or Nginx. Since reverse proxies can understand the HTTP protocol, they can perform many functions, such as:
-
Performing many unified processes, such as attack prevention strategies, web scraping prevention, SSL, gzip, automatic performance optimization, etc.
-
Application layer traffic distribution strategies can be implemented here, such as directing requests for the /xx path to server A, requests for the /yy path to server B, or conducting small traffic tests based on cookies.
-
Caching and displaying friendly 404 pages when backend services go down.
-
Monitoring whether backend services are abnormal.
-
⋯⋯
Nginx’s code is written very well, and there is much to learn from it. Readers interested in high-performance server development should definitely take a look.
Processing in the Web Server
After the request passes through the load balancer, it will enter the corresponding web server, such as Apache, Tomcat, Node.js, etc.
Taking Apache as an example, upon receiving a request, it will hand it over to a separate process for processing. We can handle it by writing Apache extensions, but this is too cumbersome, so generally, we will call scripting languages like PHP for processing. For example, under CGI, HTTP parameters are placed into environment variables, and then a PHP process is started for execution, or FastCGI is used to pre-start the process.
(I will introduce the processing in Node.js separately when I have time later.)
Entering Backend Languages
As mentioned earlier, the web server will call backend language processes to handle HTTP requests (this statement is not entirely correct, as there are many other possibilities). Next is the processing of backend languages. Currently, most backend languages are based on virtual machines, such as PHP, Java, JavaScript, Python, etc. However, this topic is very broad and difficult to explain clearly. Readers interested in PHP can read my previous article introducing HHVM, which covers many foundational concepts of virtual machines.
Web Frameworks
If your PHP is only used to create a simple personal homepage, there is no need to use a web framework. However, as the code increases, it becomes increasingly difficult to manage, so most websites are developed based on a web framework. Therefore, when the backend language is executed, it first enters the code of the web framework, which then calls the implementation code of the application.
There are many optional web frameworks, and I will not introduce them all here.
Reading Data
This part will not be elaborated on, as there are too many options, from simple file reading and writing to data middleware.
Further Learning
-
Understanding Nginx
-
Analyzing Python Source Code
-
Understanding the Java Virtual Machine
-
Database System Implementation
Fifth Question: How Does the Browser Process Data After the Server Returns It?
As mentioned earlier, after the server processes the request, the result will be sent back to the client’s browser over the network. From this section onward, I will introduce the processing of data received by the browser. It is worth mentioning that there is a good article on this topic, “How Browsers Work,” so I do not want to repeat much of the content and will focus on the parts that the article overlooks.
From 01 to Characters
When the HTML returned by the HTTP request reaches the browser, if it is gzipped, it will first be decompressed. The next important question is to know what its encoding is. For example, the character “中” in UTF-8 encoding is actually “11100100 10111000 10101101,” which is “E4 B8 AD,” while in GBK it is “11010110 11010000,” which is “D6 D0.” How can the browser know the file’s encoding? There are many judgment methods:
-
User settings, where the browser can specify the page encoding.
-
In the HTTP protocol.
-
In the tag’s charset attribute value.
-
For JS and CSS.
-
For iframes.
If none of these places specify it, the browser will have difficulty processing it, as it will see it as a bunch of “0” and “1.” For example, in UTF-8, “中文” has 6 bytes, but if interpreted as GBK, it could be misinterpreted as “涓枃,” which are three characters. How can the browser know whether it is “中文” or “涓枃”?
However, a normal person can easily recognize that “涓枃” is incorrect because these three characters are too uncommon. Therefore, some have thought of detecting encoding by judging common characters, such as Mozilla’s UniversalCharsetDetection, but this method has a high misjudgment rate, so it is better to specify the encoding.
Thus, subsequent text operations are based on “characters”. One Chinese character is one character, and there is no need to care about whether it is 2 bytes or 3 bytes.
Loading External Resources
(To be supplemented, there are scheduling strategies here)
Executing JavaScript
(I will introduce this separately later. I recommend everyone to look at the post compiled by R last year, which contains a lot of related information. Additionally, I spoke about performance optimization in JavaScript engines two years ago, although some of the content may be outdated, it is still worth a look.)
From Characters to Images
The most complex part of 2D rendering is text display. Although it seems simple to find the glyph corresponding to a character, this works well for Chinese and English, where one character corresponds to one glyph. However, it does not work for Arabic, which has connected forms.
(I will introduce this separately later, as it is very complex.)
Cross-Platform 2D Drawing Libraries
Different operating systems provide their own graphic drawing APIs, such as Quartz under Mac OS X, GDI under Windows, and Xlib under Linux, but they are not compatible with each other. Therefore, to support cross-platform drawing, Chrome uses the Skia library.
(I will introduce this separately later, as the internal implementation of Skia involves too many layers of calls, and directly discussing the code may not be suitable for beginners.)
GPU Composition
(I will introduce this separately later. Although simply put, it relies on textures, it also requires discussing OpenGL and GPU chips, which is a lengthy topic.)
Further Learning
This section is what I am most familiar with, and as a result, I want to spend more time writing it well. Therefore, I will publish it later. In the meantime, you can check out the following sites:
-
Chromium
-
Mozilla Hacks
-
Surfin’ Safari
Sixth Question: How Does the Browser Display the Page?
As mentioned earlier, the browser has rendered the page into an image. The next question is how to display this image on the screen.
Framebuffer
Taking Linux as an example, the most direct way to control the screen in an application is to write the image bitmap into the /dev/fb0 file. This file is actually a mapping of a memory area, which is called the Framebuffer.
It is important to note that under hardware acceleration, such as OpenGL, this does not go through the Framebuffer.
From Memory to LCD
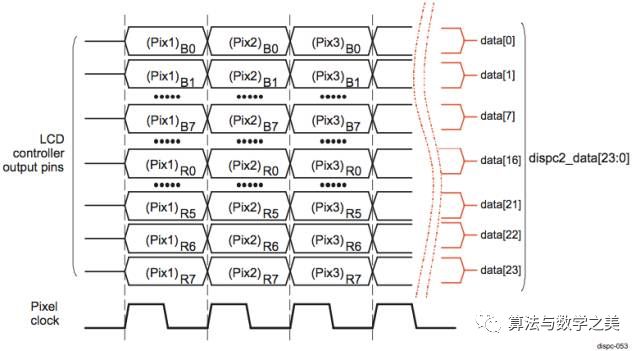
In the SoC of mobile phones, there is usually an LCD controller. When the Framebuffer is ready, the CPU will notify the LCD controller through the AMBA internal bus. The controller then reads the data from the Framebuffer, performs format conversion, gamma correction, and other operations, and finally sends it to the LCD display through interfaces like DSI and HDMI.
Taking the OMAP5432 as an example, the following diagram shows one of its supported parallel data transmission methods:
LCD Display
Finally, let me briefly introduce the principle of LCD display.
First, to make the human eye see, light must enter, either through reflection or from a light source. For example, the E-ink screen used in Kindle does not emit light by itself, so it must be read in a well-lit area. Its advantage is low power consumption, but it has too many limitations, so almost all LCDs come with a light source.
Currently, LCDs typically use LEDs as light sources. When an LED is connected to power, the positive and negative electrons combine under the influence of voltage, releasing photons and producing light. This physical phenomenon is called electroluminescence, which was also mentioned when discussing fiber optics.
Below is what the iPod Touch 2 looks like when disassembled (from Wikipedia):

In the image above, you can see six LEDs, which are the light sources for the entire screen. These light sources will reflect the light output to the screen.
In addition to light sources, color is also needed. In LEDs, the usual method is to use color filters to convert LED light into different colors.
Additionally, directly using three colors of LEDs is also feasible, which avoids the photon waste caused by filtering and reduces power consumption. This method is very suitable for small screens like smartwatches, and the LuxVue company acquired by Apple uses this method. Interested readers can study its patents.
Each physical pixel on an LCD screen is actually composed of red, green, and blue color points, each of which can be controlled individually. Below is a magnified view of this situation (from Wikipedia):

From the image above, when all three color filters are fully lit, it appears white, and when all are off, it appears black. If you look closely, you can also see that some points are not completely black, which is the anti-aliasing effect on the font.
By varying the brightness of these three colors, a wide range of colors can be produced. If each color point can produce 256 levels of brightness, it can generate 256 * 256 * 256 = 16,777,216 colors.
Not all monitors can achieve 256 levels of brightness. When selecting a monitor, one parameter is the 8-Bit or 6-Bit panel. An 8-Bit panel can physically achieve 256 levels of brightness, while a 6-Bit panel can only achieve 64 levels, requiring frame rate control technology to reach 256 levels.
How are the brightness levels of these color points controlled? This is done through liquid crystals, which have the property of rotating when current passes through, thereby blocking some light. By controlling the voltage, the rotation of the liquid crystals can be controlled, thus controlling the brightness of the color points. Currently, TFT controllers are commonly used in mobile phone screens, with IPS panels being the most famous among them.
Most of the filtered light will directly enter the eyes, while some light will also enter the eyes after diffuse reflection or specular reflection on other surfaces, combined with ambient light. Accurately calculating how much light reaches the eyes is an integral problem, and interested readers can study physics-based rendering.
Once the light enters the eyes, the next step falls into the realm of biology, so we will conclude here.
Further Learning
-
Computer Graphics, 3rd Edition: Principles and Practices
-
Interactive Computer Graphics
Content Omitted in This Article
For ease of writing, many lower-level implementation details have been omitted in the previous introduction, such as:
-
Memory-related
-
Heap, where there are many allocation strategies, such as the implementation of malloc.
-
Stack, function calls, which have been well covered in many excellent articles or books.
-
Memory mapping, dynamic library loading, etc.
-
Queues are ubiquitous, but these details and principles are not very relevant.
-
-
Various caches
-
CPU caches, operating system caches, HTTP caches, backend caches, etc.
-
-
Various monitoring
-
Many logs are saved for subsequent analysis.
-
FAQ
Based on feedback from Weibo, some questions are frequently asked, so I will answer them here collectively. If there are other questions, please ask in the comments.
Q:What is the use of learning all this? It is not necessary at all.
A:Computers are the most powerful tools of humanity. Don’t you want to understand how they work?
Q:Knowing a little about everything is not as good as mastering one thing, right?
A:I completely agree. Initially, you should focus on mastering a specific field, and then expand your knowledge to surrounding areas. This will also give you a deeper understanding of your original field.
Q:Isn’t this just cultivating a bunch of interview experts who will be against themselves?
A:This article is actually written quite superficially, and each part can be further elaborated.
Q:This question is exhausting. It could take days to answer.
A:Haha, you exposed yourself, the question is just a means to uncover talents like you.
Discussion from Everyone
Thank you very much for the participation and discussion from all the experts. Here are some of the responses collected.
@WOODHEAD笨笨:The request is sent to the local router, the ISP router, and the bypass analyzes whether the address is illegal. The connection is interrupted, and the browser innocently displays that the webpage does not exist. In severe cases, someone may come to check.
caoz: This is my interview question! There is another question: Users report that our website is slow. What possibilities are there, and how to troubleshoot?
@caoz:It is well written, but there are still some omissions, such as ARP spoofing? The well-known GFW blocking strategy, and a URL does not correspond to just one request; there are multiple requests queuing and addressing. Additionally, CDN, intelligent DNS resolution mechanisms, etc. //@ZRJ-: http://t.cn/8smHpMF From click to presentation — a detailed explanation of an HTTP request I wrote in my junior year… ah.
@唐福林:Keeping up with the times, the question should now be: What happens from opening the app to refreshing the content? If it feels slow, how to locate the problem and how to solve it?
@寒冬winter: In response to @Ivony: This question excels in distinguishing candidates, covering a wide range of knowledge points. Even those who do not understand can answer a few sentences, while experts can freely elaborate based on their areas of expertise, from URL specifications, HTTP protocols, DNS, CDN, to browser streaming parsing, CSS rule construction, layout, paint, onload/domready, JS execution, JS API binding…
@JS小组:[Haha] The editor remembered that it seems I was asked this question by the most beautiful front-end sister @sherrie_wong during my early career. I then said everything I knew, from browser parsing, sending requests, the 7-layer network model, to TCP three-way handshake, routing, switching, DNS, to the server. Whether it needs to interact with the file system or database, and then distributed computing like Hadoop… I talked too much.
@莴怖熵崴箔:This is a rogue question. I also want to ask what happens from when you press a key on the keyboard to when a character appears on the screen. Hint: Imagine you are an electron. Oh, wait, what is an electron?
@寒冬winter:http://t.cn/zH20bR1 http://t.cn/zH20bR1 I wrote the first two parts before, but then I neglected it…
@ils传言:Do not mention how many revolutions the power plant generator has made! //@Philonis高: Do not submit the working principles of the switch and router! //@南非蜘蛛: Discussing from the perspective of the 7-layer protocol would be more comprehensive. This question can only be answered by full-stack engineers.
@耸肩的阿特拉斯阁下:DNS resolves the URL to IP/Port, the browser connects and sends a GET request to this address, the web server (nginx, apache) receives the request, calls the dynamic language (php, etc.) through CGI and other interface protocols, the dynamic language connects to the database to query the corresponding data and process it, then feedbacks to the browser, which parses the feedback page, processes it through HTML, JavaScript, CSS, and finally presents it on the screen… Each detail could probably fill 800 pages of a book.
@一棹凌烟:This type of interview question is actually simple and effective in system domain recruitment. There is another similar one: What happens from when you press a character key on the keyboard to when it is displayed in the terminal of a virtual machine?
@智慧笨蛋: Indeed, it can be discussed from different dimensions, mainly depending on the granularity. The part about the optical network, from Wi-Fi decryption to NAT, to inter-network switching, IP packets mapping in Ethernet packets, etc., could fill a book.
/@乔3少:Open up and discuss all internet-related knowledge that can be reflected, such as DNS, browser caching, TCP connections, HTTP responses, the working principles of web services, browser responses and rendering, etc. I just listed the security threats I thought of on my notebook, which is very interesting!
Finally
Careful readers should have noticed that there is hidden content in this article. Please find it…
————
Editor ∑Gemini
Source: The Beauty of Algorithm Mathematics
☞ Interesting Stories of Taylor’s Theorem
☞ Qiu Chengdong: Talking about Differential Geometry
☞ How Leibniz Came Up with Calculus? (Part 1)
☞ The Physical Meaning of Linear Dependence and Rank
☞ What Do You Think is the Ugliest Formula in Mathematical History?
☞ Terence Tao Talks About What Good Mathematics Is
☞ Tian Yuandong: The Use of Mathematics (Part 2)
☞ You Definitely Didn’t Expect That Mathematicians Are So Rogue, They Use Violent Proofs When They Disagree
☞ The Five Most Powerful Doctoral Theses in the World
☞ What Surprising Coincidences Exist in Mathematics?
☞ Algorithms at Work! A Tsinghua Graduate Professor Was Robbed of His Car in the U.S., and the Police Were Helpless, So He Used a “Greedy Algorithm” to Retrieve It
☞ A Strange Article in Academic History: How to Use Mathematics to Catch a Lion
☞ Reflections from a NTU Professor: The Most Difficult Lesson We Didn’t Teach Students
☞ MIT Graduate Student Study Guide — How to Be a Graduate Student
☞ Sharing Mathematics, Common Sense, and Luck — A Lecture by Investment Master James Simons at MIT in 2010
The Beauty of Algorithm Mathematics WeChat Official Account Welcomes Contributions
Articles related to mathematics, physics, algorithms, computers, programming, etc. will be compensated upon adoption.
Submission Email: [email protected]