Introduction
Like most companies, Liulishuo has experienced a growth in business traffic and an increase in backend services. The business gateway, as the entry point for all services, plays a crucial role. With the development of the business, the architecture and operation of the business gateway have been continuously evolving, aiming to provide more stable services while allowing for safer and more controllable changes to the business gateway, as well as facilitating future expansions and updates to enhance operational flexibility. Currently, Liulishuo is achieving this flexibility by transforming the gateway layer into K8s. This article will briefly introduce the “past and present” of Liulishuo’s gateway and backend business architecture, leading into the K8s transformation process of the gateway layer, serving as a reference for interested readers. (Note: The business of Liulishuo is mainly deployed in the cloud, and the cloud resource terminology used in this article is based on Alibaba Cloud environment.)
1. Initial Architecture of the Business Gateway and Backend Services
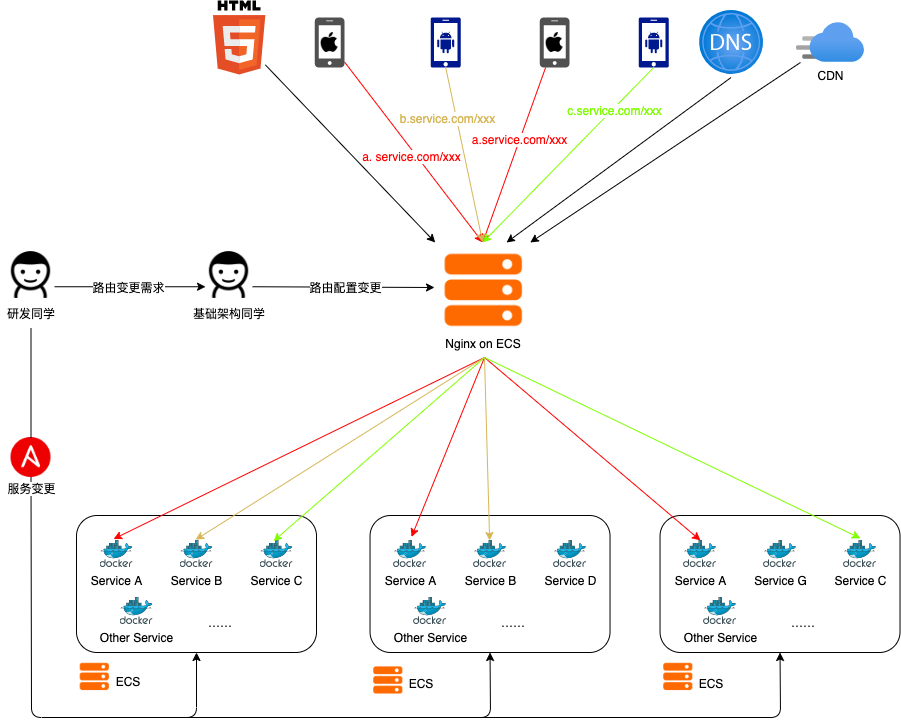
The K8s transformation of the gateway was not achieved overnight. In the early stages, Liulishuo had relatively low traffic and simple business forms. The business gateway layer adopted the simplest single-point Nginx deployment architecture; backend services were deployed on different ECS instances using Docker, and the corresponding IP + Port were configured in Nginx’s virtual server through upstream — all client requests were directed to a single Nginx node, which forwarded requests to the corresponding backend services through layer 7 proxying. When there was a need for routing changes or traffic switching, the infrastructure team would log into the Nginx server and modify the configuration files, as shown in the figure below.
2. Problems and Risks
As the number of users increased, business traffic began to grow, and backend services became increasingly complex, corresponding problems and risks were also exposed.
There are mainly three points:
1. It is evident that Nginx has a single point of failure risk, and a single Nginx instance is insufficient to support the growing business traffic; 2. The increase in backend components and frequent changes, while updates, scheduling, and deployment of Docker services are still done manually with Ansible, making it inconvenient in complex scenarios; 3. Frequent routing configuration changes have trapped the infrastructure team in a tedious cycle of uncreative configuration changes, and logging into servers to execute configuration changes is untraceable and prone to errors.
3. Major Architectural Evolution: Kong + K8s + Custom K8s Controller
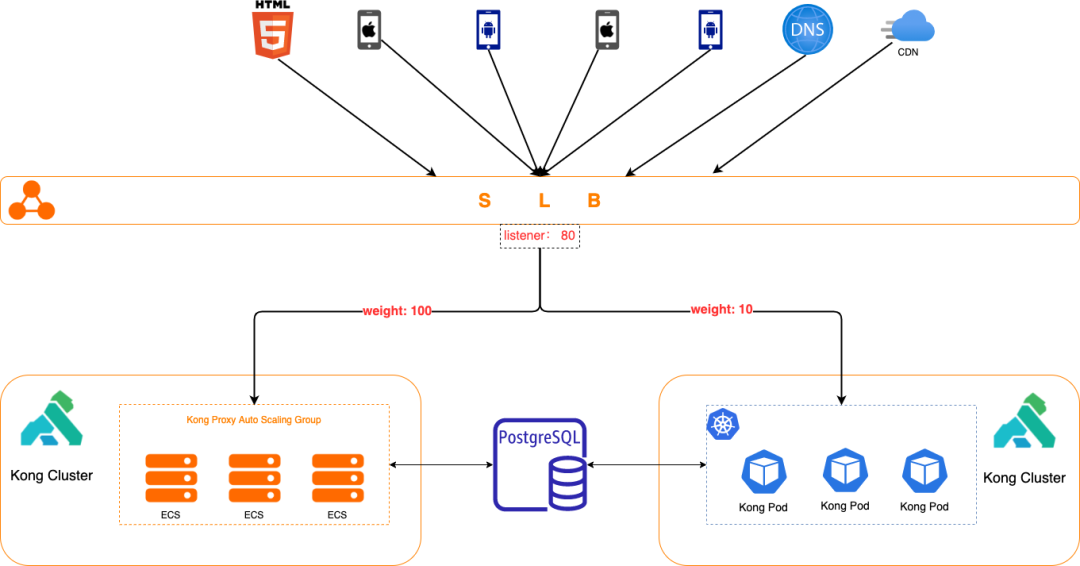
Regarding Problem 1, it can be resolved by deploying Nginx in an ASG (Auto Scaling Group) and using SLB; Regarding Problem 2, we chose to migrate backend services to K8s, using K8s for container orchestration and exposing services with NodePort Service, while we developed a CD deployment tool based on ArgoCD for self-service deployment by developers; Regarding Problem 3, traceability of changes can be addressed through GitOps practices, but the infrastructure team still has to directly handle routing change requests from all business units and manually modify Nginx routing configurations; especially after Nginx is deployed to ASG, the NodePort Service ports are dynamic. The core reason is that the update method for Nginx routing configurations is file-based, which is not conducive to automation. Even with Ansible for bulk modifications and reloads, it still requires frequent modifications to a lengthy Nginx configuration by the infrastructure team. After research, we chose Kong API Gateway to replace Nginx. Kong, based on OpenResty, is a cloud-native, efficient, and scalable distributed API gateway, with its core value lying in high performance and scalability. In DB mode, Kong stores routes in a database for use by multiple Kong instances; unlike Nginx, which updates routes by modifying files, Kong provides a RESTful API for route configuration. These features enable the possibility of automated route configuration. Since backend services had gradually migrated to K8s, we naturally thought of utilizing K8s’ List-Watch mechanism to implement an automatic route configuration controller. It listens for changes in Ingress and Service across the entire cluster, automatically generates routing information, and calls Kong’s RESTful API to update the routing configuration; combined with the CD system, developers can modify Ingress and Service configuration files for self-service route updates.
The updated architecture and process are illustrated below, taking the deployment of an Nginx welcome page as an example:
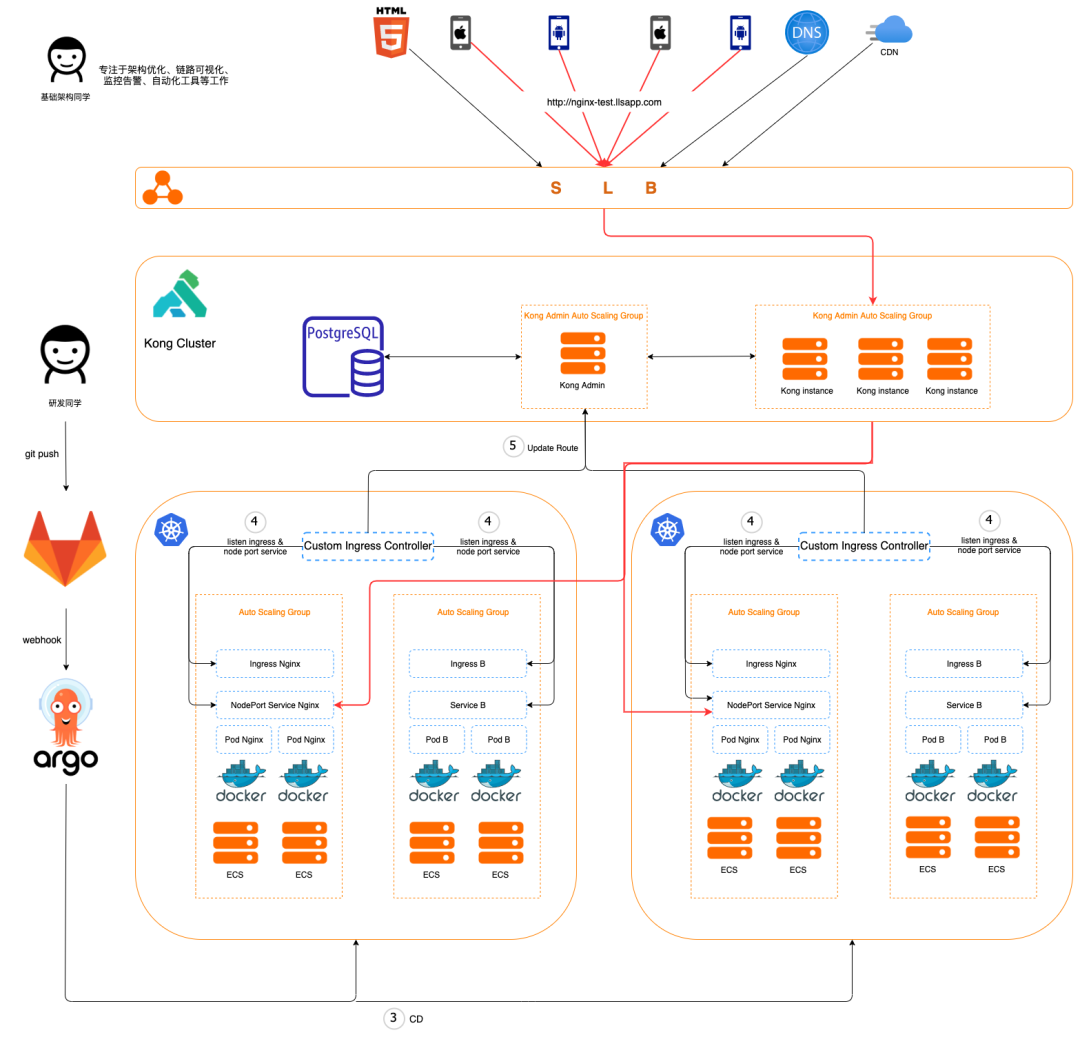
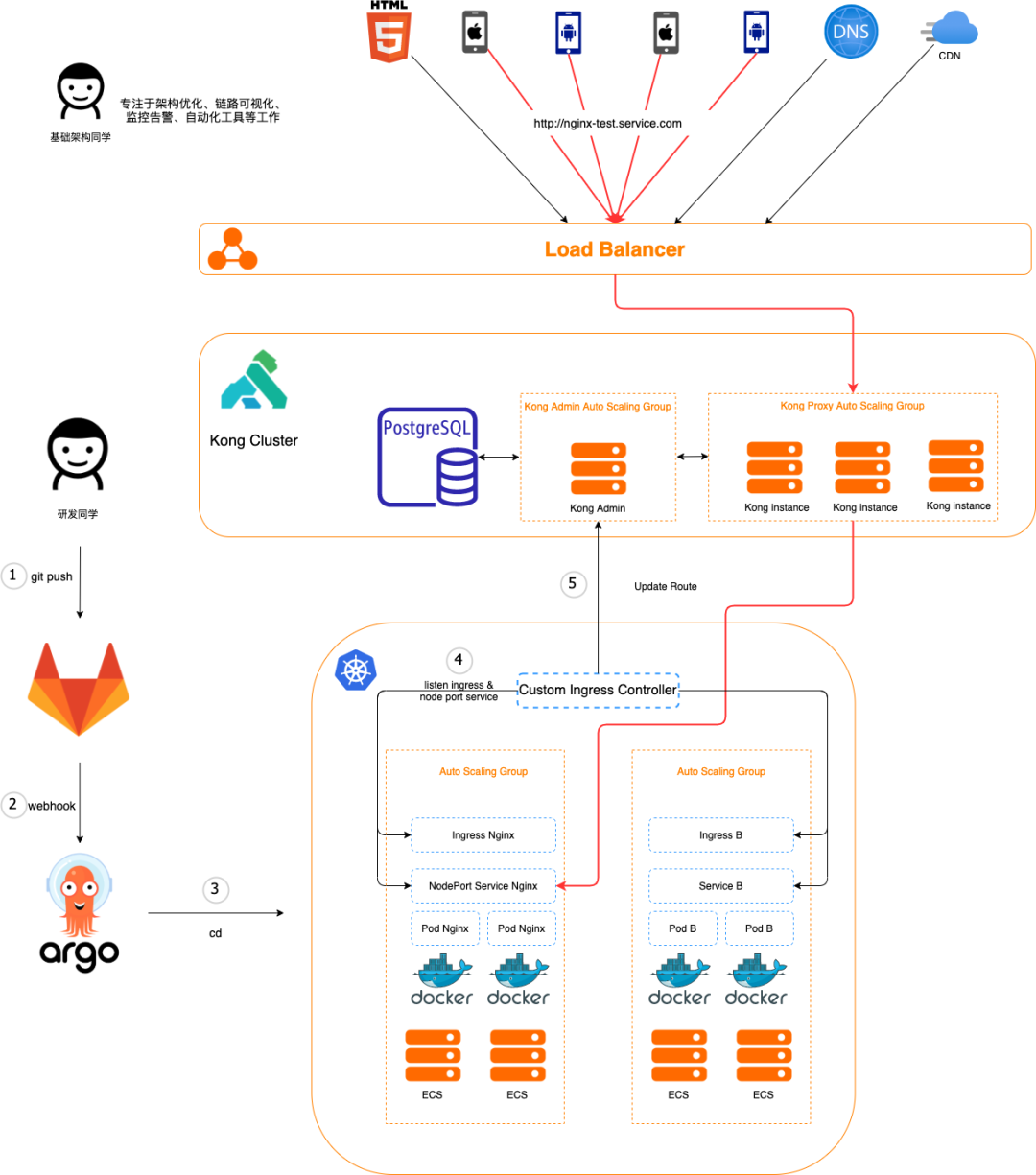 1. Developers use our auto-generation tool developed based on Jsonnet to make simple modifications to configuration items, generating the required K8s yaml files for the application, including Ingress and NodePort Service; then they can git push to Gitlab, after which everything is handled by the automation process; 2. The yaml is pushed to Gitlab for auditing, and a webhook is triggered to call the ArgoCD API; 3. Once the ArgoCD API is triggered, it deploys the application in the target K8s cluster based on the yaml file; 4. After Ingress and Service are deployed to the target K8s cluster, the custom routing controller within the cluster will listen for changes to the corresponding Ingress and Service; 5. The custom routing controller generates routing configurations based on the annotation, host, and path field values in the Ingress, along with the corresponding NodePort Service port information, and calls Kong’s API to update the routing in Kong. At this point, attentive readers may wonder: why not use the official K8s Ingress Controller and instead implement a custom routing controller? This is because, in the production environment, we have multiple K8s environments for disaster recovery. The custom routing controller not only handles routing updates but also manages service circuit breaking across clusters; additionally, we can further extend custom functionalities when necessary. The actual multi-cluster architecture is shown in the figure below.
1. Developers use our auto-generation tool developed based on Jsonnet to make simple modifications to configuration items, generating the required K8s yaml files for the application, including Ingress and NodePort Service; then they can git push to Gitlab, after which everything is handled by the automation process; 2. The yaml is pushed to Gitlab for auditing, and a webhook is triggered to call the ArgoCD API; 3. Once the ArgoCD API is triggered, it deploys the application in the target K8s cluster based on the yaml file; 4. After Ingress and Service are deployed to the target K8s cluster, the custom routing controller within the cluster will listen for changes to the corresponding Ingress and Service; 5. The custom routing controller generates routing configurations based on the annotation, host, and path field values in the Ingress, along with the corresponding NodePort Service port information, and calls Kong’s API to update the routing in Kong. At this point, attentive readers may wonder: why not use the official K8s Ingress Controller and instead implement a custom routing controller? This is because, in the production environment, we have multiple K8s environments for disaster recovery. The custom routing controller not only handles routing updates but also manages service circuit breaking across clusters; additionally, we can further extend custom functionalities when necessary. The actual multi-cluster architecture is shown in the figure below.
4. The Journey of Kong K8s Transformation for the Business Gateway
At this point, developers can fully self-service their application releases and routing changes, while the infrastructure team can focus on architecture optimization, link visualization, monitoring alerts, automation tool development, and other tasks.
Later, during the maintenance of the Kong at the business gateway layer, several pain points were discovered:
- ASG scaling still takes some time, usually 2-5 minutes. During daily peaks or sudden surges in business traffic, there is latency in the immediate scaling strategy;
- Despite the support of automation tools like Packer and Terraform, the process of updating configurations for Kong itself is still relatively heavy — we need to update Kong’s configuration → recreate the Kong EC2 virtual machine image → perform rolling updates on instances in the ASG;
- Rollback response is slow. Combining points 1 and 2, if an error occurs during the update process, rolling back to the normal configuration of Kong is still time-consuming;
- The controllable update strategy is not detailed enough.
Although some of the above issues can be addressed through certain features of the cloud’s Auto Scaling Group product and by integrating with the cloud API to develop automation platforms, the characteristics of Auto Scaling Group products differ among cloud vendors, and the exposed APIs vary as well. Whether from the cloud interface usage or integrating with cloud APIs to create automation tools, the costs are relatively high. After the “major architectural evolution,” as we became more familiar with K8s, we found that we could use K8s Deployment and HPA to address the operational pain points of the Kong at the business gateway layer, making the maintenance of the gateway layer lighter, safer, and more controllable. During the K8s transformation of the gateway layer, three main questions need to be confirmed:
1. Will the call chain latency increase? 2. Can the kong-proxy Pod stop gracefully? 3. How to switch smoothly?
4.1. Link Stress Testing
If there is an unacceptable increase in latency after Kong’s K8s transformation, then there is no need to proceed further. To test whether the link latency increases after K8s transformation, we containerized Kong and deployed it on a dedicated K8s in the cloud, aligning the network environment, machine specifications, and other aspects with the existing ASG architecture’s gateway layer for link stress testing.
To maximize the objective reflection of the call link’s latency, the service being tested in the business Kubernetes cluster should be as lightweight and as simple as possible; therefore, the service being tested is the Nginx welcome page.
After seven days of continuous stress testing, the P95 and P99 results of link latency indicate that under aligned conditions, the K8s-transformed Kong did not affect the overall link latency.
| Kong in ASG 7 days P99 & P95 (2021-09-18 14:30~2021-09-25 14:30) | |
|---|---|
| host | nginx-test.llstest.com |
| 7 days P99 | 0.005s |
| 7 days P95 | 0.004s |
| Kong in K8s 7 days P99 & P95 (2021-09-28 10:15~2021-10-04 10:15) | |
|---|---|
| host | nginx-test.llstest.com |
| 7 days P99 | 0.005s |
| 7 days P95 | 0.004s |
4.2. Can It Stop Gracefully?
The graceful stopping of the Kong Pod refers to whether existing services (especially long connection services) will be interrupted during the deletion of the Pod, such as manually deleting the Pod for a restart, rolling updates of the Kong Deployment, HPA scaling, or automatic scaling of the cloud K8s cluster.
4.2.1. Overview of Pod Termination Lifecycle
When a Pod is terminated normally, it goes through the following five lifecycle stages:
1. The Pod is set to Terminating status and is removed from the corresponding Service’s Endpoints list.
At this point, the Pod status displayed by kubectl get pods is Terminating; the Pod only stops receiving new traffic, while the containers running in the Pod are unaffected.
2. Execute preStop hook
The preStop hook is a special command or HTTP request sent to the containers in the Pod. If the application cannot gracefully stop by receiving the SIGTERM signal, this hook can be used to trigger a graceful stop.
3. SIGTERM signal is sent to the Pod
At this point, Kubernetes sends the SIGTERM signal to the containers in the Pod. This signal informs the containers that they will soon be shut down.
4. Kubernetes waits for the grace period
At this point, Kubernetes waits for a specified time, known as the termination grace period, which defaults to 30 seconds. It is important to note that the countdown of the termination grace period occurs concurrently with the preStop hook and SIGTERM signal; Kubernetes does not wait for the preStop hook to complete. If the application completes its shutdown and exits before the termination grace period is over, Kubernetes will immediately proceed to the next step; if the Pod typically takes longer than 30 seconds to shut down, ensure to increase the termination grace period by adjusting the terminationGracePeriodSeconds parameter value, for example, increasing it to 60 seconds:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: busybox
terminationGracePeriodSeconds: 605. Send SIGKILL signal to the Pod and remove it
If the containers are still running after the grace period, Kubernetes will send a SIGKILL signal to forcefully delete them. At this point, all Kubernetes objects are also cleaned up.
4.2.2. Kong’s Graceful Stopping Method
Simply execute the graceful stopping command:
Usage: kong quit [OPTIONS]
Gracefully quit a running Kong node (Nginx and other configured services) in the given prefix directory. This command sends a SIGQUIT signal to Nginx, meaning all requests will finish processing before shutting down. If the timeout delay is reached, the node will be forcefully stopped (SIGTERM).
Options:
-p,--prefix (optional string) prefix Kong is running at
-t,--timeout (default 10) timeout before forced shutdown
-w,--wait (default 0) wait time before initiating the shutdown
$ kong quit -p ${PREFIX_DIR} -t ${TIMEOUT}4.2.3. Implementation of Kong Pod’s Graceful Stopping
Combining 4.2.1 and 4.2.2, the implementation of Kong Pod’s graceful stopping is now clear: during the preStop hook phase of the Pod termination lifecycle, execute Kong’s graceful stopping command, and reasonably set the timeout for Kong’s graceful stopping and the Pod’s graceful stopping grace period, to achieve graceful stopping of Kong in K8s. The terminationGracePeriodSeconds starts counting down when the Pod enters the terminating state, representing the maximum time the Pod will wait before being killed. Therefore, when setting the grace period, the value of terminationGracePeriodSeconds must be greater than the timeout value in Kong’s graceful stopping command. The key configuration is shown in the following example Yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: kong-proxy
labels:
app: kong
name: kong-proxy
namespace: kong-proxy
spec:
replicas: 2
selector:
matchLabels:
app: kong
name: kong-proxy
template:
metadata:
annotations:
prometheus.io/scrape: "true"
labels:
name: kong-proxy
app: kong
spec:
containers:
- name: kong-proxy
image: our.registry.com/fake-repo-here/cutom-kong-docker:version
imagePullPolicy: Always
command: ["start_command"]
args: ["some", "args", "at", "here"]
ports:
- name: http-proxy
containerPort: 80
# start of readiness probe & liveness probe
readinessProbe:
exec:
command: ["kong_health_check.sh"]
initialDelaySeconds: 8
livenessProbe:
exec:
command: ["kong_liveness_check.sh"]
periodSeconds: 10
# end of readiness probe & liveness probe
workingDir: /you_guess
resources:
requests:
memory: "1Gi"
cpu: "1"
limits:
memory: "2Gi"
cpu: "2"
# Graceful shutdown settings - Timeout in Kong container level
lifecycle:
preStop:
exec:
command: ["kong", "quit", "-p", "/kong/prefix/path", "-t", "2700"]
# Graceful shutdown settings - Timeout in Kong container level
nodeSelector:
app: kong
tolerations:
- key: app
operator: Equal
value: kong
effect: NoSchedule
# Graceful shutdown settings - Timeout in pod level
terminationGracePeriodSeconds: 3600Additionally, it is important to note that at least two kong-proxy Pods must be deployed. The reason is that if there is only one kong-proxy Pod, when that Pod enters the terminating state, new incoming traffic through the K8s Service will not be directed to this Pod but will be allocated to the newly created Pod; however, the new Pod requires startup time, and during the period before it is running, the service will be unavailable, resulting in 50X errors. If there are two or more kong-proxy Pods, when one Pod enters the terminating state, traffic will immediately be directed to another available Pod, and once the new Pod is created, traffic will be redistributed to the new Pod. Testing has shown that with a reasonable grace period set, when the Kong Pod enters the terminating state, existing long connection services, such as long-running HTTP requests and websocket services, are not affected; new incoming request traffic will be automatically scheduled to the normally running Pods by K8s. Only after the long connection services complete their requests will the Pod be terminated; when HPA scales down or the cluster scales down, the Pods still adhere to this termination lifecycle, thus still being able to stop gracefully.
4.3. Smooth Switching
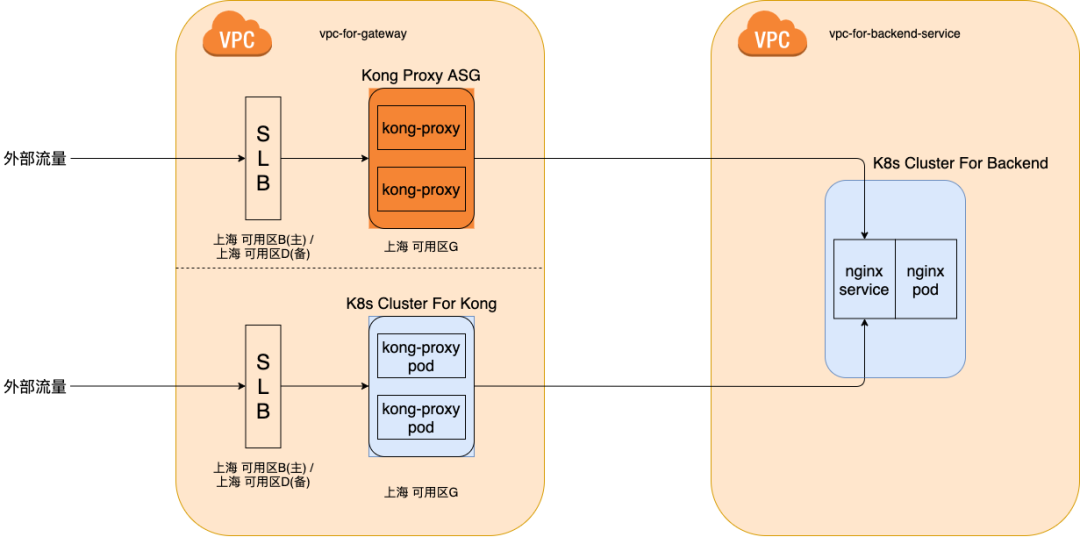
The requirement for smooth switching is that the entry point of the traffic should not change; traffic should gradually be released to Kong in K8s, and if any issues are detected, traffic can be quickly switched back to the Kong in ASG architecture. The K8s LoadBalancer type Service is very suitable for this scenario, as it can expose Pod services through annotations, setting up the existing SLB in the cloud. Taking the configuration file of LoadBalancer type Service in Alibaba Cloud ACK as an example:
# Add kong-proxy pod to the same virtual server group as Kong in ASG
apiVersion: v1
kind: Service
metadata:
annotations:
# Specify the existing load balancer id
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-id: lb-loadbalancer-id-that-currently-used
# Set the target virtual server group ID and the service port number to forward traffic to the servers in the group
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-vgroup-port: rsp-virtual-server-port:80
# Set the traffic weight to the Pod
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-weight: "10"
# Set not to override existing listener configurations
# service.beta.kubernetes.io/alicloud-loadbalancer-force-override-listeners: 'false'
labels:
app: kong-proxy
name: kong-proxy
name: kong-proxy
namespace: kong-proxy
spec:
ports:
- name: http-proxy
port: 80
protocol: TCP
targetPort: 80
selector:
app: kong
name: kong-proxy
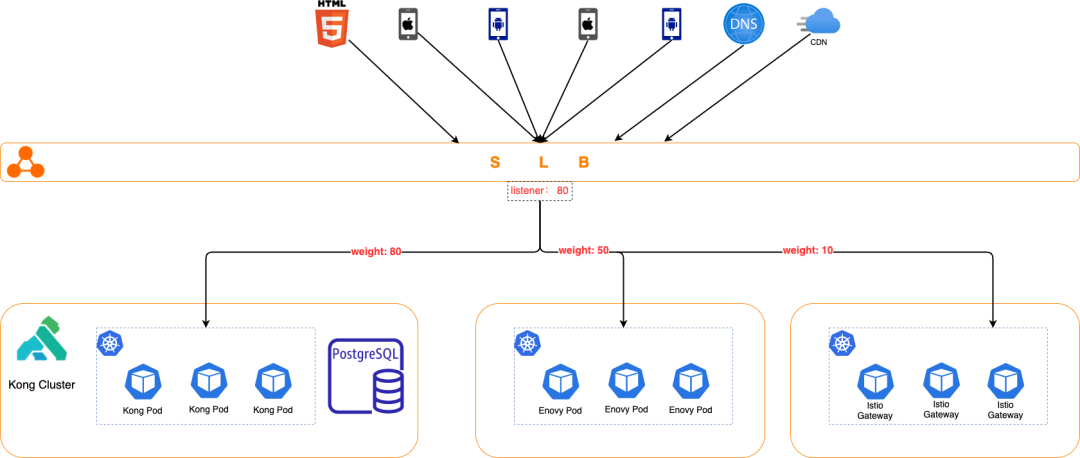
type: LoadBalancerBy this method, the Kong Pod is connected to the existing SLB to provide services, and the architecture is illustrated below. At this point, both Kong in ASG and Kong in K8s architectures can run simultaneously in the environment, and the architecture switching and quick rollback plan in case of issues are simplified to switching the target server weights on the SLB.
5. Conclusion
Liulishuo has now completed the K8s transformation of the business gateway Kong. Through CronHPA, we can achieve daily pre-scaling of Kong Pod instances before business peaks arrive; when K8s’ computing resources are insufficient, we can automatically scale cluster nodes through the cloud’s Cluster Auto Scaler; updates to Kong’s configurations or versions are also lighter, combined with existing GitOps processes and CD systems, the infrastructure team only needs to update the Dockerfile and related configuration files, then git push to trigger automatic image builds and rolling updates of the gateway without interrupting the business; through the parameters provided in the Deployment controller, we can flexibly customize the rolling update or rollback strategies for Kong Pods. Compared to before, maintenance of the gateway layer has become easier, safer, and more reliable.
While K8s transformation of the gateway layer is underway, Liulishuo’s backend business K8s has also gradually integrated Istio; leveraging the advantages brought by K8s LoadBalancer type Service and cloud LB, we plan to smoothly replace the Kong at the gateway layer with Istio Gateway in the future to enhance overall link observability.