When we click on a URL and it is displayed in our browser, what exactly happens in the computer and over the network during this process?
Server Starts Listening
The story actually does not begin when we enter a URL in the browser’s address bar or click on a link; it traces back to when the server starts its listening service. At some unknown time, an ordinary blade server in a data center is powered on, and the operating system starts. As the operating system becomes ready, the server starts the HTTP service process. This HTTP service daemon could be Apache or Nginx; regardless, this HTTP service process begins to locate the www folder on the server, typically found at /var/www, and then starts some auxiliary modules, such as PHP, or connects to the PHP FPM management process using FastCGI. It then requests a TCP connection from the operating system, binds to port 80, calls the accept function, and starts silently listening for requests that may come from anywhere on Earth, ready to respond at any moment.
At this point, typically, there should also be a database server in the data center, perhaps a caching server as well. For websites with huge traffic, the dynamic script interpreter might even run on a separate physical machine. For medium to small sites, all of these services might even run on a single physical machine, with their listening relationships in place. Regardless, they are ready and waiting for tasks.
Client Browser Sends Request
1. Parsing the URL
2. Is it a URL or a search keyword?
When the protocol or hostname is invalid, the browser will pass the text entered in the address bar to the default search engine. In most cases, when passing text to the search engine, the URL will carry a specific string of characters to inform the search engine that this search is coming from this specific browser.
3. Convert Non-ASCII Unicode Characters
-
The browser checks whether the input contains characters that are not a-z, A-Z, 0-9, – or .
-
Here, the hostname is google.com, so there are no non-ASCII characters; if there were, the browser would use Punycode encoding for the hostname part.
4. Check HSTS List
-
The browser checks its built-in “preloaded HSTS (HTTP Strict Transport Security)” list, which includes sites that the browser should only connect to using HTTPS.
-
If the site is on this list, the browser will use HTTPS instead of HTTP; otherwise, the initial request will be sent using HTTP.
-
Note that even if a site is not on the HSTS list, it can still request that the browser use HSTS policy for accessing it. After the browser sends the first HTTP request to the site, the site will respond with a request for the browser to only use HTTPS for future requests. However, this first HTTP request may expose the user to downgrade attack threats, which is why modern browsers come pre-loaded with HSTS lists.
5. DNS Query
-
Browser Cache Query: The browser checks if the domain name is in the cache (to view the cache in Chrome, open chrome://net-internals/#dns).
-
Local Hosts Query: If not in the cache, it calls the gethostbyname library function (which varies across operating systems) to query. The gethostbyname function first checks if the domain name is in the local Hosts file before attempting DNS resolution.
-
Send DNS Query Request: If gethostbyname does not have a cached record for this domain name and does not find it in hosts, it will send a DNS query request to the DNS server. The DNS server is provided by the network communication stack, usually the local router or the ISP’s caching DNS server.
-
Query Local DNS Server
-
If the DNS server and our host are in the same subnet, the system will perform an ARP query on the DNS server according to the following ARP process.
-
If the DNS server and our host are in different subnets, the system will perform an ARP query on the default gateway according to the following ARP process.
6. ARP Process
To send an ARP (Address Resolution Protocol) broadcast, we need a target IP address, and we also need to know the MAC address of the interface used to send the ARP broadcast.
-
First, check the ARP cache. If the cache hits, we return the result: Target IP = MAC. If the cache does not hit:
-
Check the routing table to see if the target IP address is in a subnet in the local routing table. If yes, use the interface connected to that subnet; otherwise, use the interface connected to the default gateway.
-
Query the MAC address of the selected network interface.
We send a layer 2 (data link layer in the OSI model) ARP request:
ARP Request:
|
1 2 3 4 |
Sender MAC: interface:mac:address:here Sender IP: interface.ip.goes.here Target MAC: FF:FF:FF:FF:FF:FF (Broadcast) Target IP: target.ip.goes.here |
Depending on the hardware type connecting the host and router, there are several situations:
-
Direct Connection:
-
If we are directly connected to the router, the router will return an ARP Reply (see below).
-
Hub:
-
If we are connected to a hub, the hub will broadcast the ARP request to all other ports, and if the router is also “connected” among them, it will return an ARP Reply.
-
Switch:
-
If we are connected to a switch, the switch will check the local CAM/MAC table to see which port has the MAC address we are looking for. If not found, the switch will broadcast this ARP request to all other ports.
-
If there is a corresponding entry in the switch’s MAC/CAM table, the switch will send the ARP request to the port with the MAC address we want to query.
-
If the router is also “connected” among them, it will return an ARP Reply.
ARP Reply:
|
1 2 3 4 |
Sender MAC: target:mac:address:here Sender IP: target.ip.goes.here Target MAC: interface:mac:address:here Target IP: interface.ip.goes.here |
Now that we have the IP address of the DNS server or default gateway, we can continue with the DNS request:
-
Use port 53 to send a UDP request packet to the DNS server. If the response packet is too large, TCP will be used instead.
-
If the local/ISP DNS server does not find a result, it will send a recursive query request, querying layer by layer to higher-level DNS servers until it reaches the authoritative server. If found, it will return the result.
7. Establishing a TCP Connection with Three-Way Handshake
When the browser obtains the target server’s IP address and the port number specified in the URL (HTTP’s default port is 80, HTTPS’s default port is 443), it will call the system library function socket to request a TCP stream socket, with parameters AF_INET/AF_INET6 and SOCK_STREAM.
-
This request is first handed over to the transport layer, where it is encapsulated into a TCP segment. The target port is added to the header, and the source port is selected from the dynamic port range within the system kernel (in Linux, it is ip_local_port_range).
-
The TCP segment is sent to the network layer, where an IP header is added containing the target server’s IP address and the local machine’s IP address, encapsulating it into a TCP packet.
-
This TCP packet then enters the link layer, where a frame header is added containing the MAC address of the local built-in network card and the MAC address of the gateway (local router). As mentioned earlier, if the kernel does not know the MAC address of the gateway, it must perform an ARP broadcast to query its address.
At this point, the TCP packet is ready to perform the TCP three-way handshake (after the address resolution is completed, the first step is to perform the three-way handshake, where the client and server only send SYN packets, and after establishing the connection, they respond to the HTTP request).
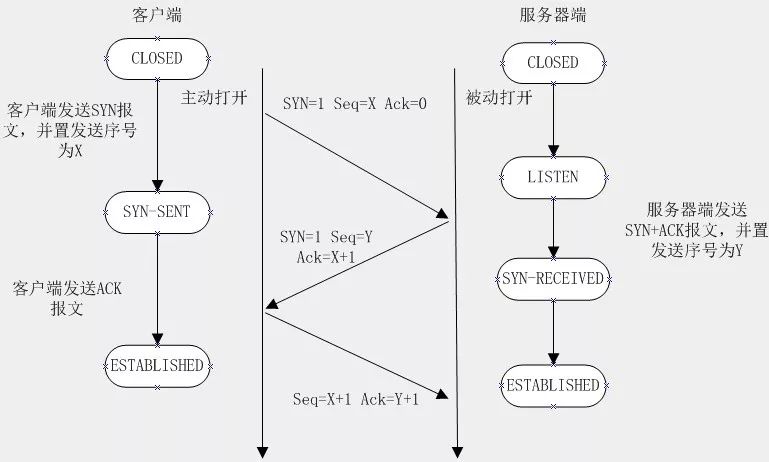
Ultimately, the packet will reach the router managing the local subnet. From there, it will continue through the boundary routers of autonomous systems (AS), other autonomous systems, and finally reach the target server. The routers encountered along the way will extract the target address from the IP datagram header and route the packet correctly to the next destination. The time-to-live (TTL) field in the IP datagram header decreases by 1 with each router it passes through. If the packet’s TTL becomes 0, or if the router drops the packet due to network congestion or other reasons, the packet will be discarded.
8. TLS Handshake
-
The client sends a Client Hello message to the server, which includes its Transport Layer Security (TLS) version, available encryption algorithms, and compression algorithms.
-
The server responds with a Server Hello message, which includes the server’s TLS version, the chosen encryption and compression algorithms, and the server’s public certificate containing the public key. The client uses this public key to encrypt the subsequent handshake process until a new symmetric key is negotiated.
-
The client verifies the server’s certificate against its trusted CA list. If valid, the client generates a pseudo-random number and encrypts it using the server’s public key. This random number will be used to generate a new symmetric key.
-
The server uses its private key to decrypt the previously mentioned random number and generates its own symmetric master key using this random number.
-
The client sends a Finished message to the server, encrypted with the symmetric key, containing a hash value of this communication.
-
The server generates its own hash value, decrypts the information sent by the client, and checks if the two values match. If they do, it sends a Finished message back to the client, also encrypted with the negotiated symmetric key.
-
From this point on, the entire TLS session will use the symmetric key for encryption, transmitting application layer (HTTP) content.
9. HTTP Server Request Processing
HTTPD (HTTP Daemon) processes requests/responses on the server side. The most common HTTPDs are Apache and Nginx commonly used on Linux, as well as IIS on Windows.
-
HTTPD receives the request.
-
The server breaks down the request into the following parameters:
-
HTTP request method (GET, POST, HEAD, PUT, DELETE, CONNECT, OPTIONS, or TRACE). When entering a URL directly in the address bar, the GET method is used.
-
Domain name: google.com
-
Request path/page: / (since we did not request a specific page under google.com, / is the default path).
-
The server verifies that it has configured a virtual host for google.com.
-
The server verifies that google.com accepts the GET method.
-
The server verifies that the user can use the GET method (based on IP address, identity information, etc.).
-
If the server has a URL rewriting module installed (such as Apache’s mod_rewrite and IIS’s URL Rewrite), it will attempt to match the rewriting rules. If matched, the server will rewrite the request according to the rules.
-
The server retrieves the corresponding response content based on the request information. In this case, since the access path is “/”, it will access the homepage file (this rule can be rewritten, but this is the most common).
-
The server will use the specified handler to analyze and process this file. If Google uses PHP, the server will use PHP to parse the index file and capture the output, returning the PHP output result to the requester.
After the request enters the processing function, if the content that the client requests to view is dynamic, the processing function will correspondingly retrieve data from the data source. This place usually has a cache, such as Memcached, to reduce the pressure on the database. If an ORM framework is introduced, the processing function can directly ask the ORM framework for data, allowing the ORM framework to decide whether to use the cache in memory or retrieve data from the database. Caches usually have an expiration time, and the ORM framework will also store a copy of the retrieved data in memory cache.
The ORM framework is responsible for translating object-oriented requests into standard SQL statements and sending them to the backend database. Taking MySQL as an example, when an SQL query comes in, the database itself also has a cache, but the database’s cache is generally accessed using SQL language hashes. This means that for the cache to hit, the queried fields and methods must be the same, and the query parameters must also be exactly identical to use the database’s own query cache. The SQL query goes through the query cache and then reaches the query analyzer, where the database decides which field’s index to use based on the index establishment of the searched data table and the characteristics of the SQL language itself. It is worth noting that even if a data table has indexes established on multiple fields, for a single SQL statement, only one index can be used, so it is important to analyze which index is the most efficient. Generally, SQL optimization is also a crucial aspect at this point.
After the SQL returns the result set to the database, the ORM framework converts the results into model objects, and the ORM framework performs some logical processing to send the prepared data to the view layer’s rendering engine for rendering. The rendering engine is responsible for managing templates, friendly display of fields, and other tasks such as handling multiple languages. For the lifecycle of a request in MVC, after the view layer prepares the page, it is sent back to the HTTP server from the dynamic script interpreter, where the HTTP server adds a response header to the body, encapsulating it into a standard HTTP response packet and sending it back to the client browser via TCP/IP protocol.
10. Client Rendering
-
Check HTTP response status code.
-
Encoding parsing.
-
Construct DOM tree.
-
Based on CSS styles and DOM tree, construct rendering tree. After all the hard work, the response we requested finally reaches the client’s browser. Once the response arrives at the browser, the browser first checks the status code. If it starts with 200, it can proceed directly to the rendering process. If it starts with 300, it needs to look for the location field in the response header and redirect according to this location. A redirect counter needs to be enabled to avoid circular redirects between two or more pages. If the redirect count becomes too high, the browser will report an error and stop. If it starts with 400 or 500, the browser will also display an error page.
Once a correct 200 response is received, the next issue is encoding parsing for multiple languages. The response header is a text of standard ASCII character set, which is manageable, but the response body is essentially a byte stream. How does the browser handle this byte stream? First, the browser will look for the encoding field specified in the response header. If present, it will parse the characters according to the specified encoding. If not, the browser will use some intelligent methods to guess and determine which character set should be used to decode this byte stream. Notes related to this can be found here: browser encoding determination.
After resolving the character set issue, the next step is to construct the DOM tree. In the case of properly nested and standardized HTML language, this XML-like language can easily construct a DOM tree. However, for the vast number of non-standard pages on the internet, different browsers should have their own fault tolerance mechanisms to handle them. The constructed DOM is essentially an abstract logical tree. During the process of constructing the DOM tree, if it encounters JavaScript code wrapped in script tags, it will send the code to the JavaScript engine to execute. If it encounters CSS code wrapped in style tags, it will be saved for later rendering. If it encounters tags that reference external files, such as img, the browser will initiate a new HTTP request to fetch this file based on the specified URL. It is worth mentioning that for downloads under the same domain, the browser typically allows a limited number of concurrent requests, usually around two. Therefore, if there are many images, for optimization purposes, these images are generally stored on a static file server responsible for responding to requests, thereby reducing the pressure on the main server.
Once the DOM tree is constructed, the next step is to construct the render tree based on the DOM tree and CSS styles. This is the tree that is actually used to render rectangles on the page. For each box on the render tree, parameters such as its x and y coordinates, dimensions, borders, fonts, and shapes need to be determined. Once the render tree is completed, the entire page is ready and can be served.
It should be noted that the steps of downloading the page, constructing the DOM tree, and constructing the render tree are not strictly sequential. To speed up processes and improve efficiency, modern browsers generally advance these steps in parallel. They download data while constructing the DOM tree and begin rendering as soon as some data is available, so users do not have to wait too long.
When the server provides resources (HTML, CSS, JS, images, etc.), the browser performs the following operations:
-
Parsing — HTML, CSS, JS
-
Rendering — Construct DOM tree -> Render -> Layout -> Paint
11. Browser
The function of the browser is to retrieve the resources you want from the server and display them in the browser window. Resources are typically HTML files, but they can also be PDFs, images, or other types of content. The location of resources is determined by the URI (Uniform Resource Identifier) provided by the user.
The method by which the browser interprets and displays HTML files is detailed in the standards of HTML and CSS. These standards are maintained by the W3C (World Wide Web Consortium).
The user interfaces of different browsers are generally quite similar, with many common UI elements:
-
An address bar
-
Back and forward buttons
-
Bookmark options
-
Refresh and stop buttons
-
Home button
-
Browser architecture
The components that make up a browser include:
-
User Interface: The user interface includes the address bar, forward and backward buttons, bookmark menu, and more. Everything you see, except for the requested page, is part of the user interface.
-
Browser Engine: The browser engine is responsible for coordinating the UI and the rendering engine.
-
Rendering Engine: The rendering engine is responsible for displaying requested content. If the requested content is HTML, the rendering engine will parse HTML and CSS and display the content on the screen.
-
Networking Component: The networking component handles network calls, such as HTTP requests, using a platform-independent interface; the lower layer is a specific implementation for different platforms.
-
UI Backend: The UI backend is used to draw basic UI components, such as dropdown lists and windows. The UI backend exposes a unified platform-independent interface that is implemented using the operating system’s UI methods at the lower layer.
-
JavaScript Engine: The JavaScript engine is used to parse and execute JavaScript code.
-
Data Storage: The data storage component is a persistence layer. Browsers may need to locally store various types of data, such as cookies. Browsers also need to support storage mechanisms like localStorage, IndexedDB, WebSQL, and FileSystem.
12. HTML Parsing
The browser rendering engine obtains the requested document from the network layer. Typically, the document is transmitted in chunks of 8kB.
The main job of the HTML parser is to parse the HTML document and generate a parse tree.
The parse tree consists of DOM elements and attributes as nodes. DOM stands for Document Object Model, which is the object representation of the HTML document and also the interface for HTML elements to the outside (such as JavaScript). The root of the tree is the “Document” object. The entire DOM and HTML document have a nearly one-to-one relationship.
Parsing Algorithm
HTML cannot be analyzed using common top-down or bottom-up methods for several reasons:
-
The language itself is “tolerant”.
-
HTML can be incomplete, and for common incompleteness, the browser needs traditional fault tolerance mechanisms to support them.
-
The parsing process requires repetition. For other languages, the source code does not change during parsing; however, for HTML, dynamic code, such as the document.write() method in script elements, can add content to the source code. This means that the parsing process effectively alters the input content.
Because common parsing techniques cannot be used, browsers have created specialized parsers for HTML. The parsing algorithm is detailed in the HTML5 standard specification and mainly consists of two phases: tokenization and tree construction.
After Parsing
After parsing, the browser begins loading external resources (CSS, images, JavaScript files, etc.).
At this point, the browser marks the document as “interactive,” and begins parsing scripts that are in “defer” mode (script files with the defer attribute), which need to be executed after the document has been fully parsed. The document state will then change to “complete” (the DOMContentLoaded event is triggered), and the browser will perform the “load” event (the onload event is triggered).
Note that there will never be a “syntax error” when parsing an HTML page; the browser will fix all errors and continue parsing.
It then executes synchronous JavaScript code.