The AI field can be described as rapidly evolving.
Last Friday, a software developer named Georgi Gerganov developed a tool called “llama.cpp” that can run Meta’s new GPT-3 level AI large language model LLaMA locally on Mac laptops.
This is another demonstration of running LLaMA-7B and whisper.cpp on a single M1 Pro MacBook:
Shortly after, someone figured out how to run LLaMA on Windows. Then someone demonstrated running LLaMA on a Pixel 6 phone, and subsequently on a Raspberry Pi (although it runs very slowly).
If this momentum continues, we might soon see pocket-sized competitors to ChatGPT.
But let’s calm down first, because we are not there yet, at least not today. But no one knows what tools will debut next week.
Since the launch of ChatGPT, some people have been frustrated with the inherent limitations of the AI model, which prevent it from discussing sensitive topics as deemed by OpenAI. This has led to dreams of developing an open-source large language model (LLM) that anyone can run locally, without censorship and without having to pay API fees to OpenAI.
Open-source solutions do exist (like GPT-J), but they require a lot of GPU memory and storage space. Other open-source alternatives cannot provide GPT-3 level performance on off-the-shelf consumer hardware.
That’s when LLaMA shines, with parameters ranging from 7 billion to 65 billion.
LLaMA made an exciting claim: its smaller models can match OpenAI’s GPT-3 in output quality and speed, which is the base model supporting ChatGPT.
But there is a problem: Meta released the open-source LLaMA code, but it only provided “weights” (the trained “knowledge” stored in the neural network) to qualified researchers.
Meta’s restrictions on LLaMA did not last long, as on March 2, someone leaked LLaMA’s weights on BitTorrent.
Since then, development work around LLaMA has sprung up like mushrooms after rain.
Independent AI researcher Simon Willison compared this situation to the open-source image synthesis model Stable Diffusion released last August.
Here is a blog post he wrote:“I think the Stable Diffusion moment last August sparked a whole new wave of interest in generative AI, which was then propelled by the release of ChatGPT at the end of November.
For large language models (the technology behind ChatGPT itself), this Stable Diffusion highlight moment is happening again. This morning, I ran a GPT-3 level language model on my own laptop for the first time!
AI technology is already amazing. It will become much more amazing in the future.”
Running GPT-3 usually requires multiple data center-level A100 GPUs (the weights of GPT-3 are also not publicly available), but LLaMA has made a splash because it can run on a single powerful consumer-grade GPU. And now, with the optimization using a technique called quantization to reduce model size, LLaMA can run on M1 Macs or smaller consumer-grade NVIDIA GPUs.
This field is evolving so fast that it can sometimes be hard to keep up with the latest trends.For example, based on the timeline listed by Willison in a Hacker News comment, here are some key events related to LLaMA:
• February 24, 2023: Meta AI announced LLaMA.
• March 2, 2023: Someone leaked the LLaMA model via BitTorrent.
• March 10, 2023: Georgi Gerganov developed llama.cpp, which can run on M1 Mac.
• March 11, 2023: Artem Andreenko ran LLaMA 7B on a Raspberry Pi 4 with 4GB of memory (very slowly), 10 seconds/token.
• March 12, 2023: LLaMA 7B ran on the node.js execution tool NPX.
• March 13, 2023: Someone ran llama.cpp on a Pixel 6 phone, also very slowly.
• March 13, 2023: Stanford University released Alpaca 7B, a fine-tuned version of LLaMA 7B that “behaves similarly to OpenAI’s text-davinci-003” but can run on much weaker hardware.
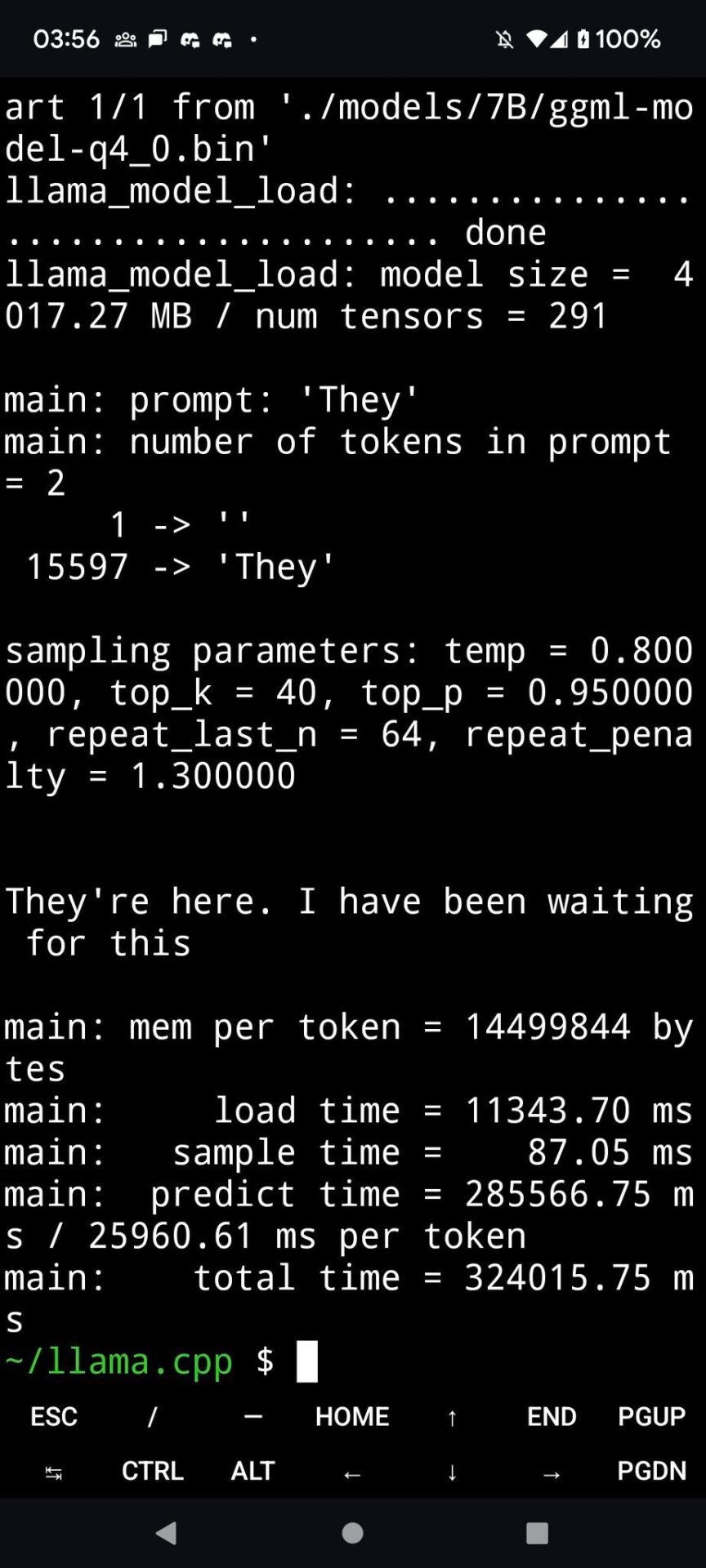
IT media arstechnica obtained LLaMA weights and ran the 7 billion parameter version on an M1 Macbook Air according to Willison’s instructions, and it ran quite fast. You can invoke it as a script via the command line, and LLaMA does its best to complete in a reasonable manner.
This screenshot shows the actual use of LLaMA 7B on a MacBook Air running llama.cpp.
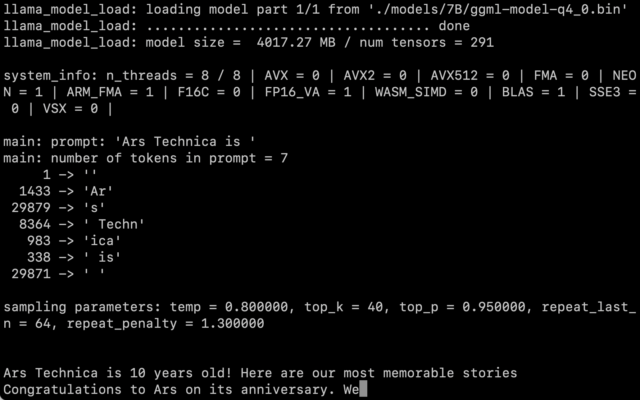
Image source:Benj Edwards / Ars Technica
There remains the question of how much the quantization affects output quality. In arstechnica’s tests, running LLaMA 7B on a MacBook Air at 4-bit quantization was quite impressive, but still could not compare to ChatGPT. Better prompting techniques could very well yield better results.
Moreover, once everyone has access to the code and weights, optimizations and fine-tuning will quickly follow, although LLaMA is still subject to some fairly strict usage terms.
Stanford University’s Alpaca released today proves that fine-tuning (additional training with specific goals) can enhance performance, and it hasn’t been long since LLaMA was released.
At the time of writing, running LLaMA on a Mac is still a technically challenging operation. You must install Python and Xcode and be familiar with using the command line.
Willison provides detailed step-by-step guidance for anyone wanting to give it a try. But as developers continue to write code, this situation may change quickly.
References: https://arstechnica.com/information-technology/2023/03/you-can-now-run-a-gpt-3-level-ai-model-on-your-laptop-phone-and-raspberry-pi/