Web scraping made easy! The Scrapy framework helps you say goodbye to the nightmare of “manual” web scraping
Have you ever been troubled by the question – every time you scrape a webpage, do you have to manually write requests, parse, and store? Writing a small scraper is easy, but when the project gets larger, it becomes chaotic?
What do you do when you encounter anti-scraping measures?
The Scrapy framework I am sharing today was born to solve these pain points. It not only allows your scraping code to be well-structured but also comes with a bunch of practical features – it’s simply the Swiss Army knife of the scraping world! I was amazed by its elegant design the first time I used it…
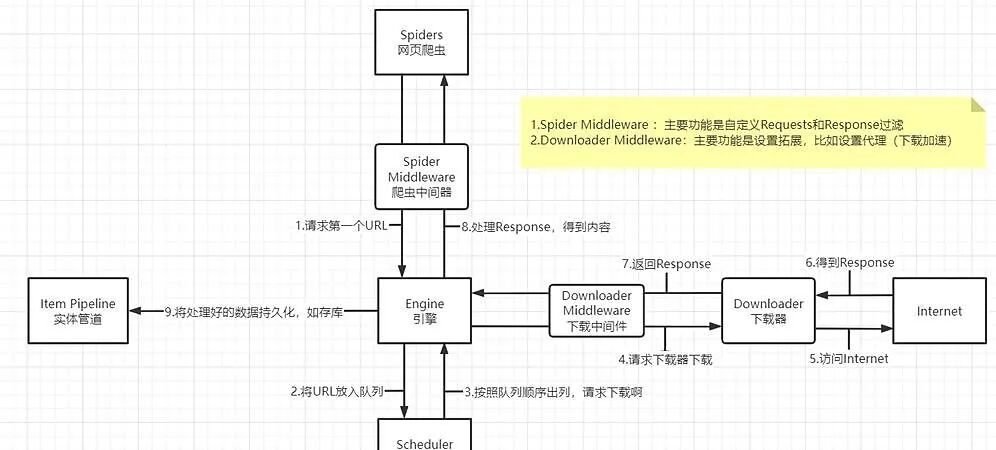
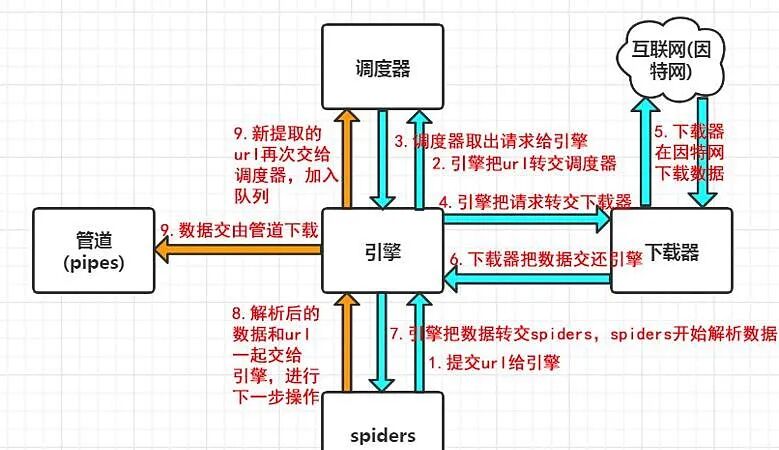
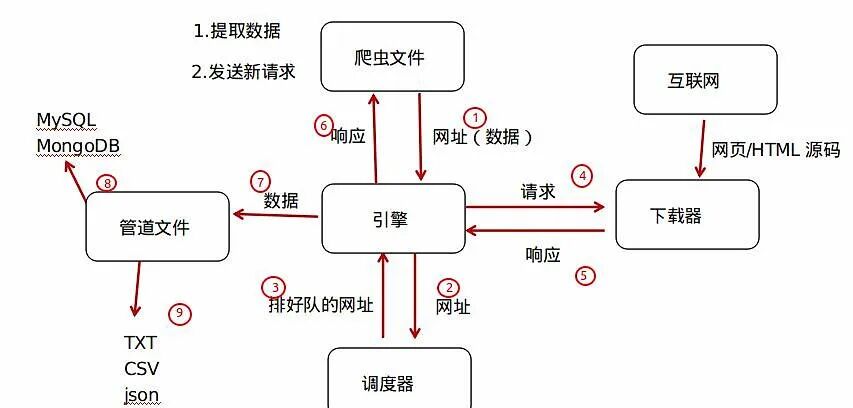
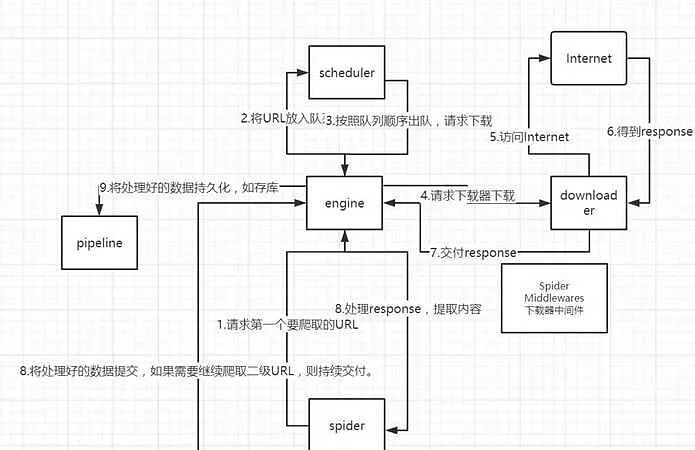
Why choose Scrapy?
Traditional scrapers are often a mixed bag. Requests and parsing are intertwined, and the code becomes increasingly messy.
Scrapy is different – it adopts a component-based design, where each part of the scraper is broken down into independent modules. Network requests? Handled by the Downloader. Content extraction? The Spider component takes care of it. Data storage? The Pipeline handles that.
This design allows you to focus on business logic rather than getting bogged down in technical details.
It also supports a middleware mechanism! You can easily add custom features without modifying the core code – such as changing IPs, adding cookies, or even simulating browser behavior. This pluggable design is incredibly thoughtful.
Environment Setup
Let’s set up the environment:
python run copy # Install Scrapy
pip install scrapy
It’s that simple! – However, Windows users may encounter some dependency issues, so it’s recommended to install pywin32 and twisted first.
Linux and Mac users generally won’t have any issues. After all, Windows is always so unique!
Your First Scrapy Spider
Let’s get practical! We will scrape book information from a book website:
python run copy # Create project
scrapy startproject bookspider
Enter the project directory
cd bookspider
Create a spider
scrapy genspider books “books.toscrape.com”

At this point, Scrapy has already generated a complete project structure for you. Isn’t it much more convenient than creating each file one by one?
Open <span>bookspider/spiders/books.py</span>, and modify it to:
python run copy import scrapy
class BooksSpider(scrapy.Spider):
name = "books"
start_urls = ["http://books.toscrape.com/"]
def parse(self, response):
# Extract all book information
for book in response.css('article.product_pod'):
yield {
'title': book.css('h3 a::attr(title)').get(),
'price': book.css('p.price_color::text').get(),
'rating': book.css('p.star-rating::attr(class)').get().split()[1]
}
# Handle next page
next_page = response.css('li.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)
Isn’t the code surprisingly concise? With just a few lines, we have implemented data extraction and pagination functionality!

Traditional scrapers might require you to manage the URL queue, manually send requests, parse HTML, and track scraping status – but in Scrapy, all of these are elegantly handled by the framework.
Run the spider:
python run copy scrapy crawl books -o books.json
Voila! The data is scraped and automatically saved in JSON format. Cool, right?
Advanced: Adding Custom Settings
In real scenarios, we may need more control:
python run copy # Add in settings.py
USER_AGENT = ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36’
Enable caching to avoid duplicate requests
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 60 * 60 * 24 # One day
Want to control the scraping speed? Set download delay:
python run copy # Random delay of 0.5 to 1.5 seconds
RANDOMIZE_DOWNLOAD_DELAY = True
DOWNLOAD_DELAY = 1
For more complex needs, you can use middleware. For example, to automatically handle redirects:
python run copy # Add in spider
custom_settings = {
'DOWNLOADER_MIDDLEWARES': {
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 543,
}
}
Practical Tips
- Data Cleaning and Transformation
Don’t want to handle data logic in the spider? Use Item Pipeline:
python run copy # pipelines.py
class PricePipeline:
def process_item(self, item, spider):
# Convert price string to float
raw_price = item['price']
item['price'] = float(raw_price.replace('£', ''))
return item
- Handling Login
Need to scrape a website that requires login? FormRequest can help:
python run copy def start_requests(self):
return [scrapy.FormRequest(
"https://example.com/login",
formdata={'username': 'user', 'password': 'pass'},
callback=self.after_login
)]
def after_login(self, response):
# Logic after login
pass
- Concurrency Control
By default, Scrapy will make requests concurrently. Want to be gentler?
python run copy # settings.py
CONCURRENT_REQUESTS = 2 # Only send 2 requests at a time
Project Practice: Book Data Analysis Scraper
A complete scraping project should include data scraping, processing, storage, and analysis. Here’s a practical case:
python run copy # Scraper code
class BookAnalysisSpider(scrapy.Spider):
name = "bookanalysis"
start_urls = ["http://books.toscrape.com/"]
def parse(self, response):
for book in response.css('article.product_pod'):
# Get detail page link
book_url = book.css('h3 a::attr(href)').get()
yield response.follow(book_url, self.parse_book)
# Handle next page
next_page = response.css('li.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)
def parse_book(self, response):
# Extract detailed information
yield {
'title': response.css('div.product_main h1::text').get(),
'price': response.css('p.price_color::text').get(),
'category': response.css('ul.breadcrumb li:nth-child(3) a::text').get(),
'availability': response.css('p.availability::text').getall()[1].strip(),
'description': response.css('div#product_description + p::text').get()
}
Run this scraper, and you will obtain a rich dataset of books! You can analyze popular categories, price distribution, and even perform text analysis – the possibilities are endless!
Conclusion
Scrapy makes web scraping development elegant and efficient. Of course, the learning curve is a bit steep, but the investment is absolutely worth it.
With it, you no longer need to deal with those annoying low-level details, allowing you to focus on what truly matters – the value extraction of data.
I remember when I used to write scrapers, I was always troubled by various trivial issues – how to implement retry mechanisms? How to manage cookies? How to store data? Now, these problems have elegant solutions.
Have you used Scrapy? What interesting challenges have you encountered? Feel free to share your scraping stories in the comments!
Give a thumbs up to let more people know about this powerful scraping framework!