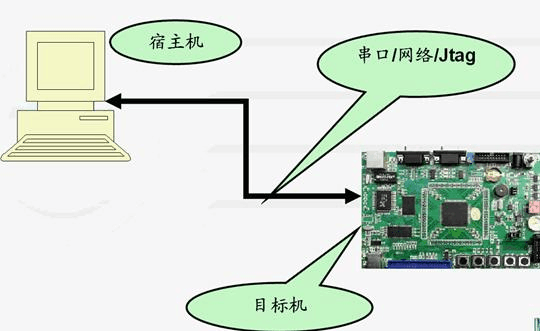
The host machine (Host Machine) usually refers to the computer used for developing and compiling embedded software. The host machine is typically a high-performance desktop or laptop that runs standard operating systems such as Windows, Linux, or macOS. The main functions of the host machine include:
Development Environment:The host machine has various development tools installed, such as compilers, debuggers, version control systems, etc., for writing, compiling, and debugging embedded software.
Cross Compilation:The host machine has a cross-compiler installed that can generate code that runs on the target embedded hardware, even if the architecture of the host machine differs from that of the target hardware.
Emulation and Simulation:The host machine can be used to run software emulators or hardware simulators to simulate the behavior of embedded hardware, allowing software development and testing without actual hardware.
File Transfer and System Programming:The host machine can be used to transfer compiled software to the embedded device through various methods (such as FTP, SCP, serial port, USB, etc.) and perform system programming.
Remote Debugging:The host machine can connect to the embedded device for remote debugging to find and fix issues while the device is running.
Project Management:The host machine can run project management tools, such as Make, CMake, etc., to automate the build process and improve development efficiency.
The host machine is an indispensable part of embedded Linux development, providing a complete development environment that allows developers to work on embedded system development in a relatively comfortable and familiar environment.
The target machine (Target Machine) or target device (Target Device) refers to the hardware platform that ultimately runs the embedded software. This is typically an embedded system that may include one or more processors, memory, storage devices, input/output interfaces, and other necessary hardware components. The characteristics of the target machine typically include:
Specialization:The target machine is usually designed for specific applications or tasks, with its hardware configuration and functions tailored to meet these specific needs.
Resource Constraints:Compared to the host machine, the target machine often has more limited computational resources, such as processing power, memory size, and storage space.
Power Consumption Constraints:Many embedded devices need to operate at low power, so the design of the target machine considers energy efficiency.
Real-time Requirements:Some embedded systems need to meet real-time requirements, responding to external events or requests within specified time limits.
Miniaturization:The target machine often needs to be miniaturized to fit specific physical space or mobility requirements.
Cost Sensitivity:Cost is an important consideration in the design of the target machine, as it directly impacts the product’s market competitiveness.
Operating System:The operating system running on the target machine is usually a Linux version optimized for embedded environments, which may include features of real-time operating systems (RTOS).
Interfaces and Communication:The target machine typically has various communication interfaces, such as serial ports, USB, Ethernet, wireless communication, etc., to facilitate data exchange with other devices or networks.
Security:In some applications, the target machine needs to have certain security features to protect data from unauthorized access.
Environmental Adaptability:The target machine may need to operate reliably under extreme temperature, humidity, or other environmental conditions.
During the embedded Linux development process, developers need to use a cross-compilation toolchain on the host machine to compile software, ensuring that the generated software can run correctly on the target machine. Additionally, developers also need to consider the hardware characteristics and limitations of the target machine to ensure software compatibility and performance.
Cross compilation (Cross-Compilation) is a compilation process that allows developers to compile code on one type of computer (the host machine) that can be executed on another type of computer (the target machine). In embedded Linux development, cross-compilation is especially important because the processor architecture and operating system of embedded devices are usually different from those of the host machine used by the developer.
Here are some key points of cross-compilation:
Different Architectures for Host and Target Machines:The host machine may be an x86 architecture PC, while the target machine may be an ARM architecture embedded device. The cross-compiler can generate executable files suitable for the target machine architecture.
Cross Compiler:A cross-compiler is a compiler specifically designed to generate code for the target machine architecture. It usually includes the cross-compiler frontend (such as GCC) and the library files for the target machine.
Library Compatibility:During cross-compilation, it is necessary to use library files compatible with the target machine. These library files are usually the runtime libraries of the target machine’s operating system, providing the functions and resources required for program execution.
Toolchain:The cross-compilation toolchain refers to a complete set of tools used for cross-compilation, including compilers, linkers, debuggers, etc. These tools work together to compile source code into binary files executable on the target machine.
Binary Compatibility:The binary files generated by cross-compilation can only run on the target machine and cannot be executed directly on the host machine.
Optimization:The cross-compiler can optimize code generation based on the characteristics of the target machine, producing more efficient code.
Debugging:During cross-compilation, developers can use debugging tools on the host machine to debug programs on the target machine, which often requires remote debugging tools or emulators.
Dependency Management:During cross-compilation, it is necessary to ensure that all dependent libraries and header files are prepared for the target machine to avoid compatibility issues.
Configuration Files:Cross-compilation usually requires specific configuration files that specify the architecture of the target machine, operating system type, compiler options, and other information.
Automated Build:In complex projects, automated build systems (such as Make, CMake) can be used to manage the cross-compilation process, simplifying the development workflow.
Cross debugging (Cross Debugging) refers to the process of debugging programs running on another architecture computer (the target machine) on a computer of one architecture (usually the host machine). In embedded Linux development, this typically involves debugging programs running on ARM or other architecture embedded devices on an x86 architecture PC.
The key components of cross debugging usually include:
Cross Compiler:Used to compile code on the host machine that can run on the target machine.
GDB (GNU Debugger):A powerful debugging tool that can be used to debug program execution.
gdbserver:A small debugging server that runs on the target machine, allowing GDB to debug through remote connection.
Host Machine:The computer running GDB, usually a high-performance PC.
Target Machine:The hardware platform that ultimately runs the embedded software, i.e., the embedded device.
The general steps of cross debugging are as follows:
Prepare Debugging Environment:Install the cross-compiler and GDB on the host machine while deploying gdbserver on the target machine.
Compile Program with Debug Information:Use the cross-compiler to compile the target program, ensuring that it includes debug information (e.g., using the-goption).
Start gdbserver:Run gdbserver on the target machine, specifying the port to listen on and the program to debug.
Run GDB:Start GDB on the host machine and load the corresponding debug symbols and libraries.
Connect to gdbserver:Use GDB’starget remotecommand to connect to gdbserver running on the target machine.
Set Breakpoints and Step Through:Set breakpoints in GDB, step through the program, and perform debugging.
View and Modify Variables:During debugging, view and modify the values of variables to analyze program behavior.
Cross debugging allows developers to debug on a resource-rich host machine while observing and controlling program execution on the target machine, which is crucial for the development and troubleshooting of embedded systems. Using GDB and gdbserver for cross debugging is a common practice that allows for more flexible and efficient debugging processes through network connections.
The bootloader is a critical software component in embedded systems, responsible for executing a series of initialization operations when the device starts and booting the system to an operating system (such as Linux) or other types of execution environments. Here are some of the main functions and features of the bootloader:
Hardware Initialization:The bootloader runs first at system startup, initializing hardware devices, including memory, CPU, bus, storage devices, input/output interfaces, etc.
Memory Configuration:The bootloader sets up memory mapping to ensure that system memory and any additional memory resources (such as RAM, ROM, Flash, etc.) are correctly recognized and configured.
Driver Loading: In some systems, the bootloader is also responsible for loading necessary hardware drivers so that the operating system can control hardware devices.
Environment Setup:The bootloader sets the system environment, including clock, power management, peripheral configuration, etc.
Boot Loader:The core function of the bootloader is to load and start the operating system. It typically reads the operating system kernel image from storage devices (such as hard drives, solid-state drives, flash memory, etc.) and loads it into memory.
Error Detection:The bootloader may also include error detection and handling mechanisms to ensure that the system can recover from abnormal states.
User Interaction:Some bootloaders provide a simple user interface or command-line interface, allowing users to select different boot options, such as entering recovery mode, safe mode, or different operating systems.
Update Mechanism:The bootloader itself may also be updatable to support new hardware or fix known issues.
Security: In some systems, the bootloader is responsible for implementing secure boot policies to ensure that only verified software can be loaded and executed.
Low-level Operations:The bootloader typically runs at the lowest privilege level of the system, as it needs to access and control hardware resources.
In embedded Linux systems, common bootloaders include U-Boot, Barebox, RedBoot, etc. These bootloaders are usually open-source and can be customized based on specific hardware platforms and requirements. The bootloader is an essential part of the system startup process, ensuring that the system can boot correctly and securely.
U-Boot is a widely used open-source bootloader in embedded Linux systems, its full name is Universal Boot Loader. The main functions of U-Boot include:
Hardware Initialization:U-Boot runs first at system startup, responsible for initializing hardware devices, including CPU, memory, Flash, serial ports, networks, etc.
Support for Multiple Architectures: U-Boot supports multiple processor architectures, such as ARM, MIPS, PowerPC, x86, etc., reflecting its “Universal” characteristics.
Booting Operating Systems: U-Boot supports not only booting embedded Linux systems but also booting embedded operating systems such as NetBSD, VxWorks, QNX, RTEMS, ARTOS, LynxOS, Android, etc.
Rich Command Line Interface: U-Boot provides a command-line interface, allowing users to control and operate hardware devices, execute various tasks, and debug. Supported commands include but are not limited to printenv, setenv, saveenv, ping, md, mw, etc., which are used to view environment variables, set environment variables, save environment variables, detect network connectivity, view memory address values, modify memory address values, etc.
Support for Network Functions: U-Boot supports network booting, allowing the kernel and file system to be downloaded over the network for remote updates and debugging.
File System Operations: U-Boot can access ext2/3/4 and fat file system devices, supporting file reading, writing, and erasing operations.
Portability: U-Boot has good portability, can be ported to multiple development boards, and supports source code-level modifications and customizations.
System Deployment Functionality: U-Boot can complete the programming and downloading of the entire system (including uboot, kernel, rootfs, etc.) onto Flash.
Hardware Management: U-Boot implements some control capabilities for hardware, such as drivers for serial ports, networks, storage devices, etc., to control these hardware during flashing or startup.
Lifecycle Management: The lifecycle of U-Boot starts from the automatic startup at power-on until the kernel is started. Once U-Boot has started the kernel, its task is complete, and control of the system is handed over to the operating system.
The design goals of U-Boot are to remain compact, fast, simple, portable, configurable, debuggable, user-friendly, maintainable, elegant, and open-source, with detailed descriptions of these principles available on its official website. These features make U-Boot the de facto standard bootloader in embedded Linux systems.
A virtual machine (Virtual Machine, abbreviated as VM) is a virtual computer system that simulates a complete hardware system function through software, running on a computer. Virtual machines allow a physical computer to run multiple operating systems, each running in its own virtual machine environment, independently without interfering with each other. Here are some key characteristics of virtual machines:
Hardware Simulation:Virtual machines simulate the functions of hardware devices such as CPU, memory, hard disk, graphics card, network interface through software.
Operating System Isolation: Each virtual machine can install different operating systems, running independently in a virtual environment without affecting each other.
Resource Allocation: Virtual machines allow users to customize the hardware resources allocated to each virtual environment, such as the number of CPU cores, memory size, disk space, etc.
Quick Deployment: Virtual machines can be created and deleted quickly within minutes, facilitating rapid deployment of new development and testing environments.
Flexibility: Virtual machines can migrate between different physical machines and run on different operating systems, offering high flexibility.
Consistency: Virtual machines provide a consistent runtime environment, making software porting and testing easier.
Security: Virtual machines offer a degree of isolation, which can be used for security research and malware analysis without affecting the host machine.
Snapshot Feature: Many virtual machine software provide snapshot features, allowing the current state of the virtual machine to be saved for later recovery or rollback.
Network Functions: Virtual machines can simulate network devices, allowing communication between virtual machines and between virtual machines and external networks.
Performance Overhead: The performance of virtual machines is usually lower than that of systems running directly on physical hardware, as hardware operations need to be simulated through software, resulting in some performance overhead.
In embedded Linux development, virtual machines are often used to simulate the target hardware environment for software development, testing, and debugging. Developers can install Linux distributions on virtual machines, configure development tools, and simulate the hardware characteristics of embedded devices, allowing development work to be conducted without actual hardware. Common virtual machine software includes VMware, VirtualBox, KVM, etc.
The Network File System (Network File System, abbreviated as NFS) is a distributed file system protocol that allows users and programs to access files stored on remote servers as if they were accessing files on local storage. NFS is a popular network protocol widely used in Unix-like systems, including embedded Linux systems. Here are some key features of NFS:
Remote File Access:NFS allows clients to access the file system on the server over the network as if these files were stored locally.
Transparency: For users and applications, accessing files mounted via NFS is no different from accessing local files.
Cross-Platform: NFS supports multiple operating systems, including different versions of Unix and Linux, as well as Windows systems.
Data Consistency: The NFS protocol ensures that remote file access is consistent, even in cases where network issues or server problems cause connection interruptions.
Data Caching: To improve performance, NFS clients cache data obtained from the server. This means that subsequent accesses to the same file may read directly from the local cache instead of fetching from the server each time.
File Locking: NFS supports file locking mechanisms to ensure data consistency when multiple users or processes access files simultaneously.
Network Performance: NFS is designed for high-speed network environments, such as local area networks (LAN), to minimize network latency and bandwidth consumption.
Simple Configuration: In Linux systems, the mount command can easily mount remote NFS shares to the local file system.
Security: NFS can be configured with permissions and authentication mechanisms to control access to remote files.
Application Scenarios: NFS is suitable for scenarios that require centralized storage and file sharing, such as data centers, research institutions, multimedia processing, and embedded systems.
In embedded Linux systems, NFS can be used for various purposes, such as:
As a file sharing mechanism during development and testing, allowing developers to easily access and modify code and data stored on remote servers.
As a way to boot the system, by mounting remote file systems via NFS to start embedded devices, which is very useful during system debugging and updates.
For storing large files, such as audio, video, or map data, which may not fit in the local storage of embedded devices.
NFS is a powerful tool that enhances the flexibility and scalability of embedded Linux systems by providing seamless access to remote files.
Bash (Bourne Again SHell) is a widely used command-line interpreter and scripting language, written by Brian Fox for the GNU project as a free software replacement for the Bourne Shell (sh). Bash is the default command-line interface for Linux operating systems and most Unix systems. Here are some key features of Bash:
Command Interpreter:Bash acts as a command interpreter, receiving user-inputted commands and executing them.
Scripting Language: Bash is also a high-level scripting language that allows users to write complex scripts to automate operating system tasks.
Compatibility: Bash is compatible with the Bourne Shell (sh) and can run most sh scripts, but adds many new features and enhancements.
Command History: Bash supports command history, allowing users to review and re-execute previously entered commands.
Command Completion: Bash provides command and filename completion, improving the usability of the command line.
Pipes and Redirection: Bash supports the pipe (|) operator, allowing multiple commands to be connected, with the output of one command used as the input for another. It also supports input/output redirection, allowing users to control the input and output of commands.
Wildcards: Bash supports wildcards (such as * and ?), allowing users to specify filenames using pattern matching.
Variables and Parameters: Bash allows users to define and use variables and handle parameters passed to scripts.
Control Structures:Bash provides rich control structures, such as if statements, loops (for, while, until), and case statements for writing complex logic.
Functions:Bash allows defining functions to organize code and reuse code snippets.
Input/Output:Bash scripts can read input and write output, interacting with users or other programs.
Signal Handling:Bash supports signal handling, allowing scripts to respond to operating system signals.
Built-in Commands:Bash provides many built-in commands, such as cd, echo, pwd, etc., to perform common tasks without additional programs.
Environment Configuration:Bash scripts are often used to configure user environments, such as ~/.bashrc and ~/.bash_profile files.
In embedded Linux systems, Bash is often used as the default command-line interface, allowing users to interact directly with the system, execute commands, and write and run scripts. The flexibility and powerful scripting capabilities of Bash make it an important tool for system administration, task automation, and development work.
Dash (Debian Almquist Shell) is a Unix shell, an enhanced version of Almquist Shell, written by Jan Nijtmans. Dash is adopted by the Debian project for its smaller size and higher speed and is also the default implementation of /bin/sh in Ubuntu. Dash adheres to POSIX standards, meaning it is designed to run on POSIX-compliant systems and has some limitations, such as not supporting certain advanced features and scripting syntax found in Bash.
Some major differences between Dash and Bash include:
Function Definitions:Bash supports defining functions using thefunctionkeyword, while Dash does not support thefunctionkeyword, instead using a function definition style without any keyword.
Select Statement:Bash supports theselectstatement, while Dash does not support it, requiring alternative methods such aswhileloops andcasestatements to be used instead.
Brace Expansion:Bash supports brace expansion, such asecho {1..5}, while Dash does not support this feature.
Here Document:Bash supports Here documents, while Dash does not support them, requiring alternative methods to achieve similar functionality.
Arrays:Bash supports arrays, including associative arrays, while Dash does not support arrays.
Process Substitution:Bash supports process substitution, such as<(command)or>(command), while Dash does not support it.
Arithmetic Expansion:Bash supports arithmetic operations using$((expression)), while Dash does not support certain operators like++and—.
Test Command:Bash supports[[ … ]]as an enhanced version of the test command, while Dash does not support it and can only use the basictestcommand or[ … ].
Due to its small size and speed, Dash is often used to execute scripts, especially during system startup and initialization processes, which can speed up boot times. However, for development environments requiring complex scripts and advanced features, Bash is usually the better choice. In embedded Linux development, developers may choose between Dash and Bash as needed for the appropriate shell environment.