
On-Demand Optimizing Deep Learning Model Based on Edge Computing*
Shan Bowei, Zhang Rongtao
(Chang’an University, Xi’an, Shaanxi 710064)
*Fund Project: Shaanxi Province Natural Science Basic Research Program “Research on Arithmetic Code Data Compression Model Based on Deep Learning” (2021JM-188)
Abstract In response to the poor real-time performance of cloud server-centered deep learning models, this paper proposes an on-demand optimizing deep learning model based on edge computing. The model adaptively allocates and prunes deep learning models to terminal devices and edge servers based on communication bandwidth and latency constraints to maximize computational accuracy. Simulation results show that this algorithm has a stronger computational advantage compared to simply deploying the deep learning model on terminal devices or edge servers.
KeywordsDeep Learning; Edge Computing; Latency Constraints
doi:10.3969/j.issn.1006-1010.20220529-0001
Classification Number: TN929 Document Code: A
Article Number: 1006-1010(2022)09-0020-04
Citation Format: Shan Bowei, Zhang Rongtao. On-Demand Optimizing Deep Learning Model Based on Edge Computing[J]. Mobile Communications, 2022, 46(9): 20-23.
Shan Bowei, Zhang Rongtao. On-Demand Optimizing Deep Learning Model Based on Edge Computing[J]. Mobile Communications, 2022, 46(9): 20-23.
1. Introduction
Deep learning technology has received widespread attention in recent years and has been applied to many fields. To meet the enormous computational resources required by deep learning, the traditional model is to deploy Deep Neural Networks (DNN) in cloud computing centers, while mobile devices send the data generated to the cloud for computation, only obtaining the computation results. This model can cause significant latency when network bandwidth is limited, affecting real-time performance. The current solution is to adopt an edge computing model, where cloud computing capabilities are pushed down to the edge of the network, deploying deep learning models on edge devices closer to terminal devices for computation and communication, thereby better meeting real-time computing needs. Although edge intelligent models have many advantages over cloud intelligence, research has shown that they are still very sensitive to available communication bandwidth. Experiments in literature [14] indicate that when bandwidth decreases from 1 Mbps to 50 kbps, the latency of DNN on edge servers increases from 0.123 s to 2.317 s.
To address the above issues, this paper proposes an on-demand optimizing deep learning model based on edge computing, building on the author’s previous work. The main contributions include: (1) Simulating mobile devices and edge servers using a Xilinx Zynq 7000S system and a PC system respectively, employing the classic VGG-16 deep learning model for image classification on the CIFAR-10 dataset; (2) Providing an optimization algorithm that maximizes classification accuracy based on available bandwidth, available computational resources, and latency constraints; (3) Using an early exit mechanism to achieve on-demand accelerated DNN. This work references the ideas in literature [14], but unlike literature [14], it presents a unified optimization algorithm for both slow and rapid bandwidth variations and verifies the accuracy and complexity of the algorithm under different bandwidth conditions.
1. Model and Algorithm
The overall architecture of the model is shown in Figure 1. The model first deploys the DNN to the edge server and terminal device in an offline state, then optimizes the DNN under varying bandwidth environments based on given latency requirements, maximizing computational accuracy.
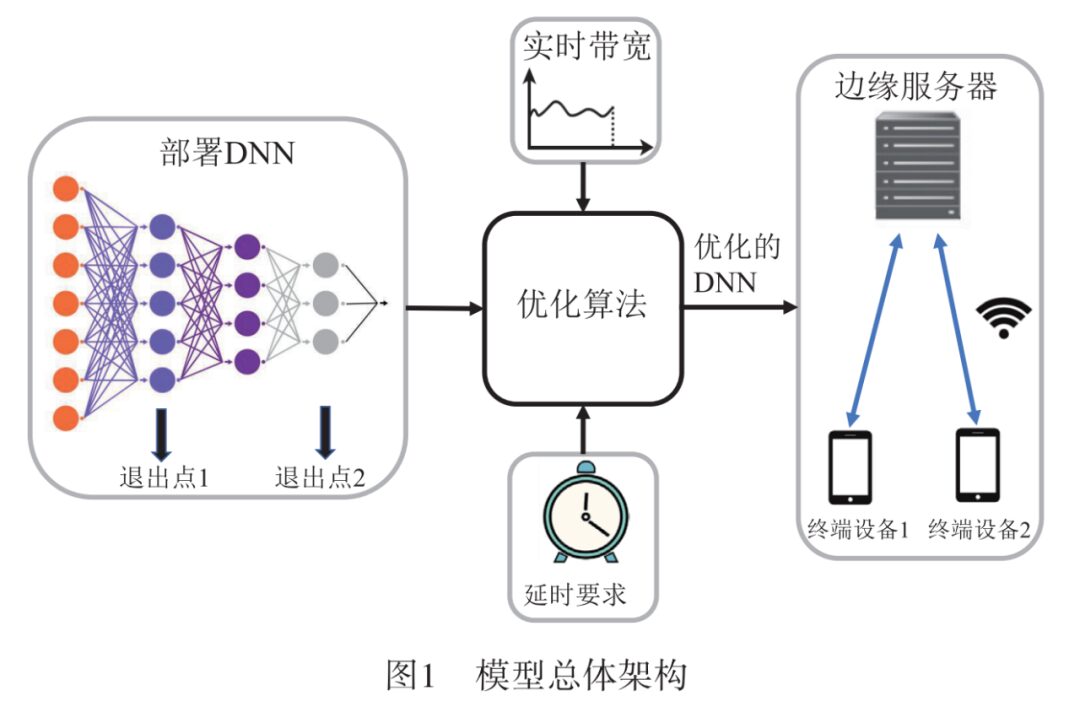
1.1 Offline Deployment of DNN
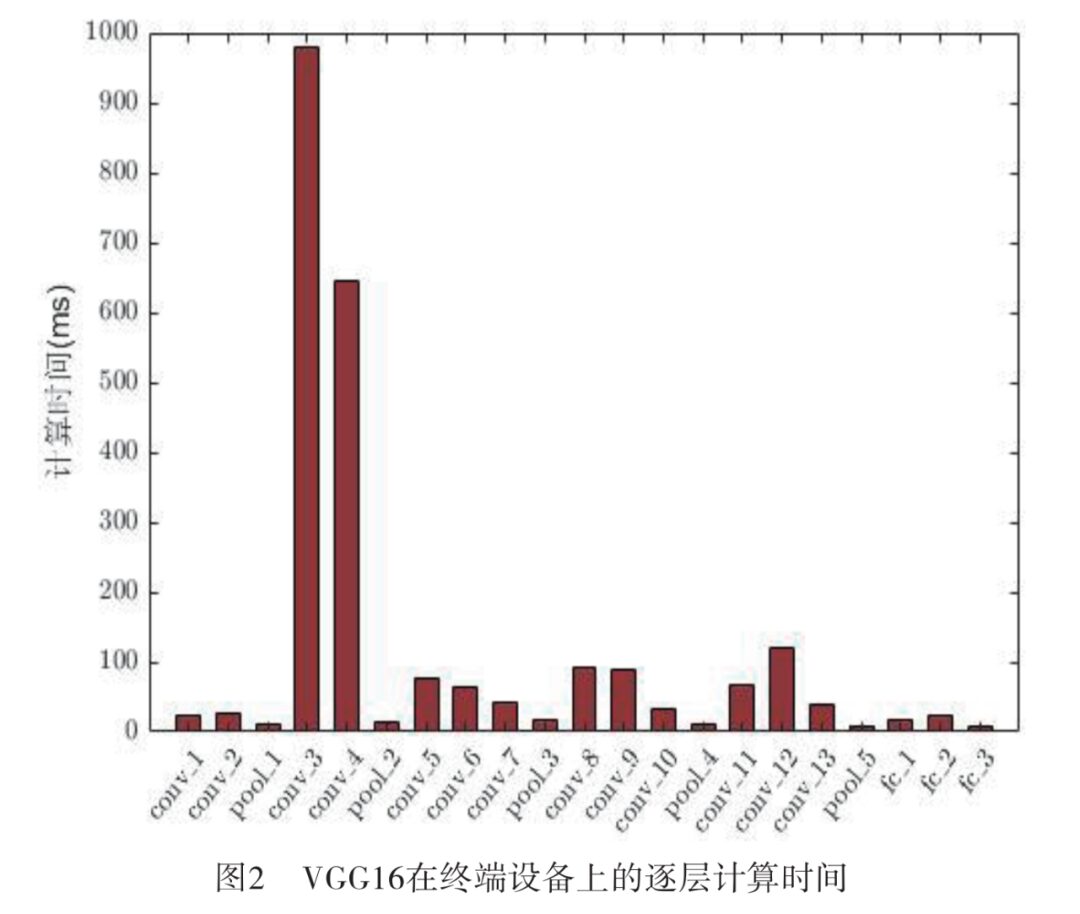
The work of offline deployment of DNN mainly includes two aspects: first, analyzing the computation time of each layer of the DNN. Taking VGG16 as an example, VGG16 is a deep neural network that takes a 224×224 RGB image as input, containing 13 convolutional layers, 5 max-pooling layers, 3 fully connected layers, and 1 soft-max layer. Deploying VGG16 on the terminal device Xilinx Zynq 7000S, the computation time of each layer of VGG16 is shown in Figure 2, where it can be seen that there are significant differences in computation times across layers. To meet the requirement of adjusting computation time on demand, the idea of BranchyNet is referenced, which trains VGG16 into a DNN model with multiple exit points; the earlier the exit point, the smaller the computation time and the lower the computation accuracy, while the later the exit point, the larger the computation time and the higher the computation accuracy.
1.2 Optimization Algorithm
Based on the offline deployment of DNN in Section 1.1, the optimization algorithm searches for the optimal DNN exit points based on bandwidth and latency requirements between the edge server and terminal devices, in order to achieve maximum computational accuracy under the above requirements. Let the DNN model have w exit points, denoted as {e1, e2, …, ew}, where the i-th exit point ei has Ni layers, and Oj is the output of the j-th layer. Let LDj be the predicted computation time of the j-th layer on the device, and LSj be the predicted computation time of the j-th layer on the server, with input data I and bandwidth B. The optimization algorithm can be expressed as the following optimization formula:
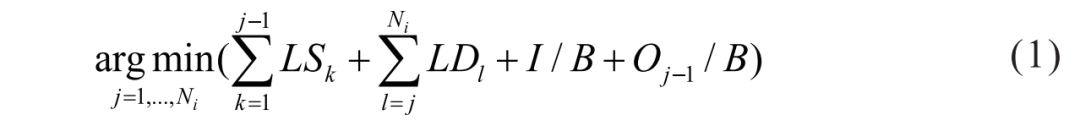
The algorithm searches all i and j until it finds the optimal exit point. If none of the exit points can meet the latency requirement for the preset latency, the optimization fails. When the DNN is completely deployed on the terminal device, j=0, LSj=0, I/B=0, Oj-1/B=0; when the DNN is completely deployed on the edge server, j=Ni, LDj=0, Oj-1/B=0. From the algorithm in (1), it can be seen that if more resource factors need to be considered in the future, such as memory constraints, bandwidth fluctuations, and other deep learning models, these constraints can easily be incorporated into the optimization algorithm. It should be noted that this model assumes that when the computational power of the DNN on the terminal device cannot meet the latency requirement, the computational power on the edge server can help share the task.
The above optimization algorithm can be summarized as Algorithm 1:


2. Model Validation and Results
To validate the effectiveness of the proposed model, a PC and Xilinx Zynq 7000S device were used to simulate the edge server and terminal device, conducting simulation experiments.
2.1 Parameter Settings
The PC used has a 6-core Intel 3.2 GHz CPU and 16 GB RAM, while the Xilinx Zynq 7000S has an ARM Cortex-A9 CPU and 1 GB RAM; detailed hardware parameters can be found in literature [18]. To generate different bandwidth states, a synthetic bandwidth tracker provided by Oboe was used to produce bandwidth variations from 0 to 4 Mbps, with a minimum change interval of 200 bps. Using the BranchyNet framework, VGG16 was trained on the CIFAR-10 dataset for image classification. The training ultimately achieved 4 exit points, located at the 8th, 12th, 14th, and 16th layers of the VGG16 network.
2.2 Experimental Results
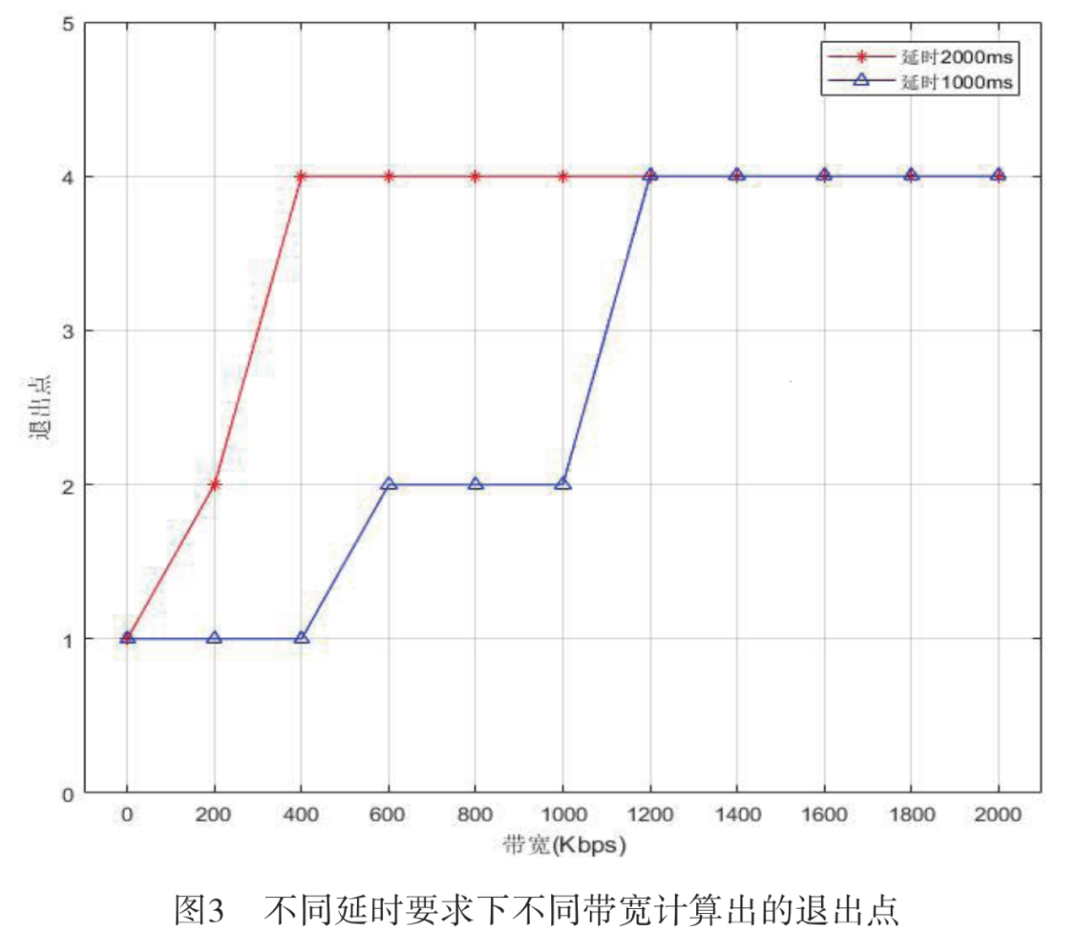
First, the latency requirements were set at 1,000 ms and 2,000 ms respectively, with bandwidth varying from 0 to 2 Mbps in steps of 200 kbps. The optimal exit points provided by the optimization algorithm under different settings are shown in Figure 3. It can be observed that under both latency conditions, the exit points increase with bandwidth, indicating that at lower bandwidths, it is necessary to exit early to meet latency requirements, thus sacrificing accuracy. When bandwidth exceeds 1,200 kbps, the exit points reach their maximum, resulting in the highest accuracy. Comparing the two latency constraints, it can be seen that the exit curve for 2,000 ms rises more rapidly than for 1,000 ms, due to the more relaxed latency constraints allowing for later exits at smaller bandwidths.
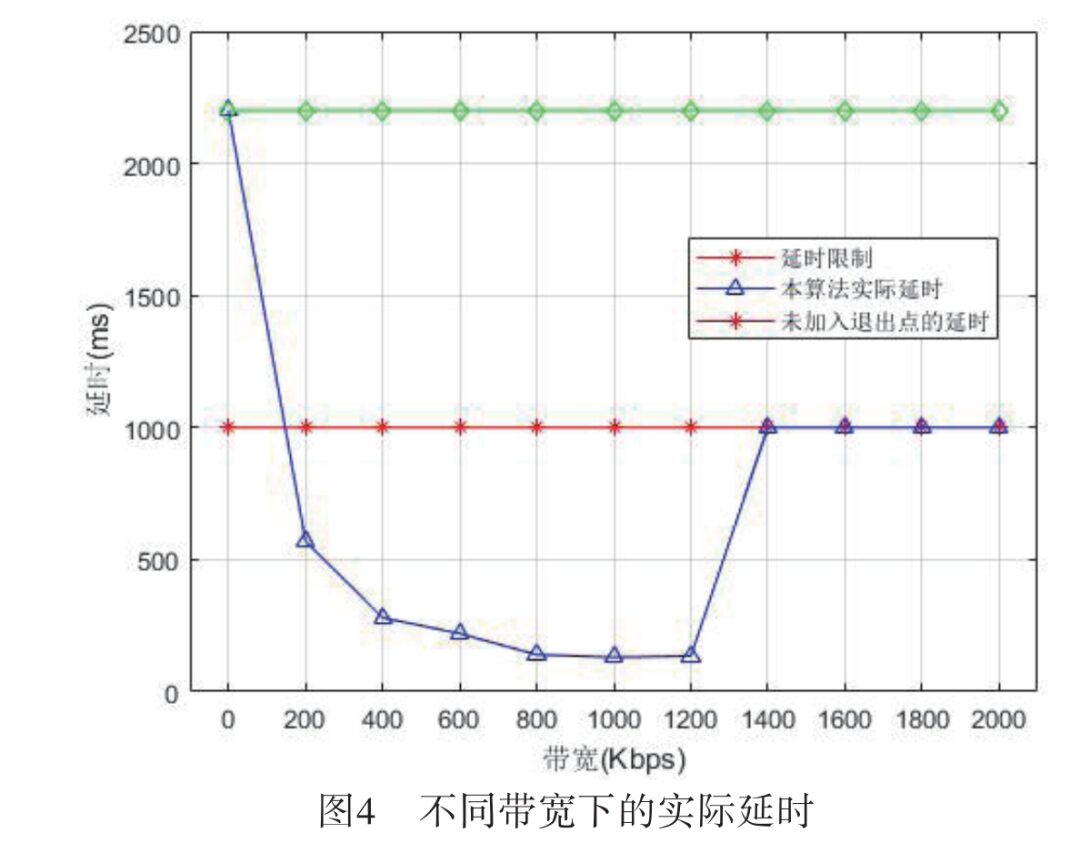
To further verify the model, the actual latency values of the optimization algorithm with varying bandwidth are shown in Figure 4, along with a comparison of the results of this algorithm and the algorithm without exit points. With a latency limit of 1,000 ms, the actual latency caused by the algorithm initially is very large at low bandwidths, then rapidly decreases as bandwidth increases slightly, remaining far below the limit due to early exits. When bandwidth exceeds 1,400 kbps, the actual latency matches the latency limit and remains unchanged as bandwidth increases, while the algorithm without exit points results in a latency of 2,200 ms, failing to meet the latency requirements.
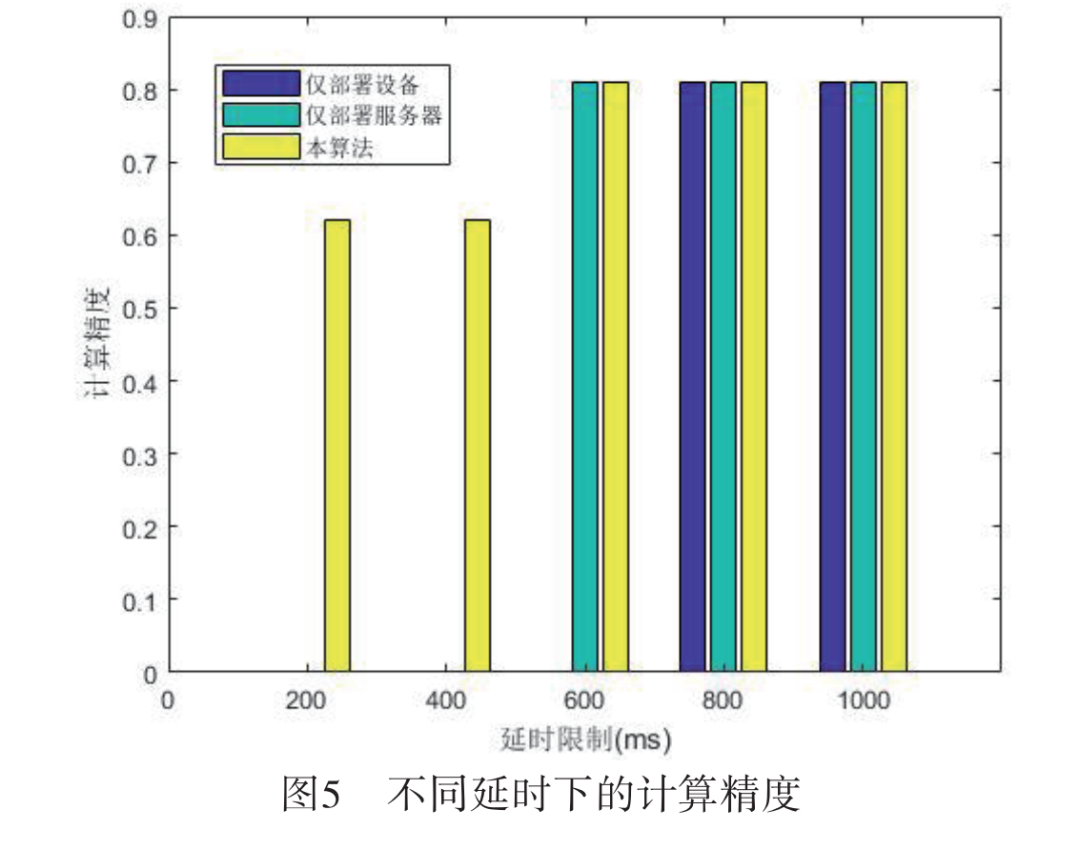
Three comparison experiments were conducted: (1) Deploying DNN only on the terminal device; (2) Deploying DNN only on the edge server; (3) Using this algorithm to deploy DNN on both the terminal and server simultaneously. The experiments were conducted under latency limits set at 200 ms, 400 ms, 600 ms, 800 ms, and 1,000 ms, with the DNN classification accuracy studied in the three cases. The experimental results in Figure 5 indicate that when the latency limit is 200 ms and 400 ms, the stringent latency requirements cause both the terminal-only and server-only deployment cases to fail to complete the computation, while this algorithm still manages to compute at lower accuracy; when all exit points in Algorithm 1 cannot meet the conditions, it is defined as unable to complete computation. When the latency limit is set at 600 ms, only the server deployment and this algorithm can complete the computation; when the latency limit exceeds 800 ms, all three algorithms can complete the computation. This indicates that even under stringent bandwidth conditions, the computational accuracy of this algorithm surpasses that of deploying solely on the terminal device or solely on the edge server.
3. Conclusion
This paper presents a deep learning model in the context of edge servers and terminal devices, which maximizes computational accuracy while considering factors such as network bandwidth constraints and latency requirements. Thus, it effectively addresses the poor real-time performance and high latency drawbacks of pure edge computing models. The model’s computational performance under different bandwidth and latency requirements was validated through numerical simulations using a PC to simulate the edge server and Xilinx Zynq 7000S to simulate the terminal device.
In future research, the DNN model VGG16 presented in this paper can be extended to more deep learning models, allowing for broader applications of this model in practical engineering fields.