
Our discussion on HTTP performance is based on the simplest model, which is the HTTP performance of a single server. Of course, this also applies to large-scale load-balanced clusters, as these clusters are composed of multiple individual HTTP servers. Additionally, we exclude scenarios where the client or server itself is overloaded or where different I/O models are used in the HTTP protocol implementation. We also ignore the DNS resolution process and the inherent flaws in web application development.
From the perspective of the TCP/IP model, HTTP operates over the TCP layer, so the performance of HTTP largely depends on the performance of TCP. If it is HTTPS, we also need to consider the TLS/SSL layer. However, it is certain that the performance of HTTPS is worse than that of HTTP; the more layers there are, the more significant the performance loss.
Under the aforementioned conditions, the most common factors affecting HTTP performance include:
-
TCP connection establishment, which is the three-way handshake phase
-
TCP slow start
-
TCP delayed acknowledgment
-
Nagle’s algorithm
-
Accumulation of TIME_WAIT and port exhaustion
-
Server-side port exhaustion
-
Server-side HTTP process reaching the maximum number of open files
TCP Connection Establishment
Typically, if the network is stable, establishing a TCP connection does not consume much time and the three-way handshake process is completed within a reasonable time frame. However, since HTTP is stateless and operates as a short connection, once an HTTP session is accepted, the TCP connection is terminated. A webpage usually has many resources, which means multiple HTTP sessions will occur. Compared to HTTP sessions, the TCP three-way handshake for establishing connections can seem too time-consuming. However, existing connections can be reused to reduce the number of TCP connection establishments.
TCP Slow Start
TCP congestion control measures[1] limit the maximum transmission speed during the initial transmission phase after a TCP connection is established. If data transmission is successful, the transmission speed will gradually increase. This is known as TCP slow start. Slow start limits the number of IP packets[2] that can be transmitted at any given moment. Why is there a slow start? It is primarily to prevent the network from collapsing due to large-scale data transmission. A crucial aspect of data transmission on the internet is the router, which is not very fast. Additionally, many traffic flows on the internet may require routing. If the amount of data arriving at a router at a given time far exceeds the amount it can send, the router will drop packets when its local cache is exhausted. This behavior is known as congestion, and if a router experiences this situation, it can affect many links, potentially leading to widespread outages. Therefore, either party in a TCP communication needs to perform congestion control, and slow start is one of the algorithms or mechanisms for congestion control.Imagine a scenario where we know that TCP has a retransmission mechanism. If a router in the network experiences widespread packet loss due to congestion, the sender’s TCP stack will detect this situation and initiate the TCP retransmission mechanism. Moreover, the affected sender is not the only one; many sender TCP stacks will start retransmitting, which means sending more packets on an already congested network, effectively adding fuel to the fire.
From the above description, we can conclude that even in a normal network environment, the sender of HTTP messages establishing a TCP connection for each request will be affected by slow start. Given that HTTP is a short connection that disconnects after a session ends, it can be imagined that when a client initiates an HTTP request and has just retrieved a resource from a web page, the HTTP connection disconnects before the TCP slow start process is completed. The subsequent resources of the web page will need to establish new TCP connections, and each TCP connection will go through the slow start phase, which significantly impacts performance. Therefore, to improve performance, we can enable HTTP persistent connections, also known as keep-alive.
Additionally, we know that TCP has a window concept, which exists on both the sender and receiver sides. The window serves to ensure that the sender and receiver manage packets in an orderly manner; furthermore, based on this order, multiple packets can be sent to improve throughput. The window size can also be adjusted to prevent the sender from sending data faster than the receiver can receive it. While the window resolves the rate issue between the two parties, the data must pass through other network devices. How does the sender know the router’s receiving capacity? This is where congestion control comes into play.
TCP Delayed Acknowledgment
First, we need to understand what acknowledgment means. It refers to the sender sending a TCP segment to the receiver, and the receiver must return an acknowledgment indicating receipt. If the sender does not receive this acknowledgment within a certain time, it must retransmit the TCP segment.
Acknowledgment messages are usually small, meaning that one IP packet can carry multiple acknowledgment messages. To avoid sending too many small messages, the receiver will wait to see if there is other data sent to it before returning the acknowledgment. If there is, it will send the acknowledgment and data together in one TCP segment. If there is no other data to send within a certain time, usually 100-200 milliseconds, the acknowledgment will be sent in a separate packet. The purpose of this is to minimize network load.
A simple analogy is logistics: if a truck has a capacity of 10 tons, you would want it to be as full as possible when traveling from City A to City B, rather than sending it off immediately with just a small package.
Therefore, TCP is designed not to return an ACK acknowledgment immediately upon receiving a data packet. It typically accumulates acknowledgments for a period of time. If there is additional data in the same direction, it will send the previous ACK acknowledgment back together. However, it cannot wait too long; otherwise, the other party may assume a packet loss has occurred, triggering a retransmission.
Different operating systems have different approaches to whether to use and how to use delayed acknowledgment. For example, Linux can enable or disable it; disabling it means acknowledging each packet as it arrives, which is also known as fast acknowledgment mode.
It is important to note that whether to enable or set a specific number of milliseconds also depends on the scenario. For instance, in online gaming scenarios, immediate acknowledgment is crucial, while SSH sessions can utilize delayed acknowledgment.
For HTTP, we can disable or adjust TCP delayed acknowledgment.
Nagle’s Algorithm
This algorithm is also designed to improve the utilization of IP packets and reduce network load. It involves small packets and full-sized packets (according to Ethernet standards, an MTU of 1500 bytes is considered a full-sized packet; anything smaller is a non-full-sized packet). However, no matter how small a small packet is, it cannot be less than 40 bytes, as the IP header and TCP header each occupy 20 bytes. If you send a 50-byte small packet, it means the effective data is too little. Just like delayed acknowledgment, small packets are not a significant issue in a local area network but can impact wide area networks.
This algorithm means that if the sender currently has packets sent but not yet acknowledged in the TCP connection, and if the sender has more small packets to send, it cannot send them immediately but must hold them in the buffer until the previously sent packets are acknowledged. Once acknowledged, the sender will collect the small packets in the buffer and assemble them into one packet for sending. This means that the faster the receiver returns ACK acknowledgments, the faster the sender can send data.
Now let’s discuss the issues that arise when combining delayed acknowledgment and Nagle’s algorithm. It is easy to see that due to delayed acknowledgment, the receiver will accumulate ACK acknowledgments for a period of time, and during this time, the sender will not receive ACKs and thus will not continue sending the remaining non-full-sized data packets (data is divided into multiple IP packets, and the number of packets the sender needs to send is unlikely to be an exact multiple of 1500 bytes; it is highly probable that some data at the end will be small-sized IP packets). This highlights the contradiction here. Such issues in TCP transmission can affect transmission performance, and since HTTP relies on TCP, it naturally affects HTTP performance. Typically, we disable this algorithm on the server side. We can disable it at the operating system level or set TCP_NODELAY in the HTTP program to disable it. For example, in Nginx, you can use<span>tcp_nodelay on;</span> to disable it.
Accumulation of TIME_WAIT and Port Exhaustion[3]
This refers to the client side or the party that actively closes the TCP connection. Although the server can also initiate a closure, we are discussing HTTP performance here. Due to the nature of HTTP connections, it is usually the client that actively closes the connection.
The client initiates an HTTP request (this refers to a request for a specific resource, not opening a so-called homepage, which has many resources and thus leads to multiple HTTP requests). After this request ends, the TCP connection will disconnect, and the connection on the client side will enter a state called TIME_WAIT. The duration from this state to final closure typically takes 2MSL[4]. We know that the client accesses the server’s HTTP service using its own randomly high port to connect to the server’s port 80 or 443 to establish HTTP communication (which is essentially TCP communication). This means that it consumes the available port numbers on the client side. Although the client releases this random port after disconnecting, during the 2MSL duration from TIME_WAIT to truly CLOSED, that random port cannot be used (if the client initiates another HTTP access to the same server). One of the purposes is to prevent dirty data on the same TCP socket. From the above conclusion, we can see that if the client’s HTTP access to the server is too frequent, it may lead to a situation where the speed of port usage exceeds the speed of port release, ultimately resulting in an inability to establish connections due to a lack of available random ports.
As mentioned earlier, it is usually the client that actively closes the connection.
In “TCP/IP Illustrated, Volume 1, Second Edition,” page 442, the last paragraph states that for interactive applications, the client usually performs the active close operation and enters the TIME_WAIT state, while the server usually performs the passive close operation and does not directly enter the TIME_WAIT state.
However, if the web server has keep-alive enabled, it will also actively close the connection when the timeout duration is reached. (I am not saying that “TCP/IP Illustrated” is incorrect; rather, it primarily discusses TCP and does not introduce HTTP, and it states that this is usually the case, not always.)
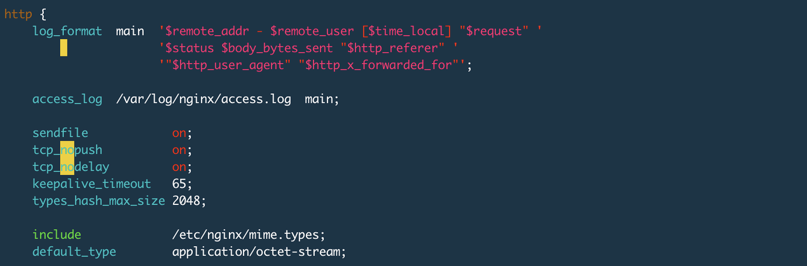
I tested using Nginx and set<span>keepalive_timeout 65s;</span> in the configuration file. The default setting for Nginx is 75s, and setting it to 0 disables keep-alive, as shown in the image below:
Next, I accessed the default homepage provided by Nginx using the Chrome browser and monitored the entire communication process with a packet capture tool, as shown in the image below:
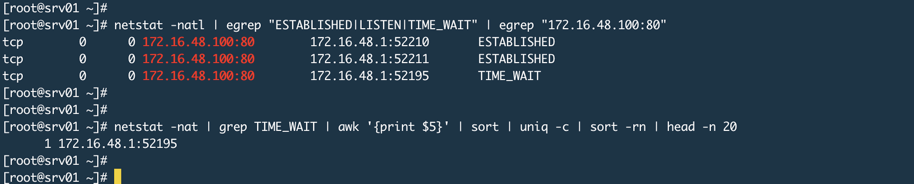
From the above image, it can be seen that after the effective data transmission is completed, there is a communication marked with Keep-Alive, and after 65 seconds without requests, the server actively disconnects. In this case, you will see the TIME_WAIT state on the Nginx server.
Server-Side Port Exhaustion
Some may ask how Nginx, which listens on ports 80 or 443, can experience port exhaustion when clients are connecting to this port. As shown in the image below (ignoring the TIME_WAIT in the image, which is caused by the keepalive_timeout setting in Nginx as mentioned above).
Actually, it depends on the working mode of Nginx. We typically use Nginx in proxy mode, which means that the actual resources or data are on the backend web application, such as Tomcat. The characteristic of proxy mode is that the proxy server acts on behalf of the user to fetch data from the backend. In this case, Nginx acts as a client to the backend server, and it will use random ports to initiate requests to the backend. The range of available random ports can be viewed using the command<span>sysctl net.ipv4.ip_local_port_range</span>.
Considering the previously discussed delayed acknowledgment, Nagle’s algorithm, and the role of Nginx as a client connecting to the backend using random ports, there is a risk of server-side port exhaustion. If the speed of releasing random ports is slower than the speed of establishing connections with the backend, this situation may arise. However, this generally does not occur; at least in my company’s Nginx, I have not observed this phenomenon. This is because, firstly, static resources are mostly on CDN; secondly, most backend operations are REST interfaces for user authentication or database operations, which are generally fast if there are no bottlenecks on the backend. However, if the backend does have a bottleneck and scaling or restructuring costs are high, when facing a large number of concurrent requests, you should implement rate limiting to prevent the backend from being overwhelmed.
Server-Side HTTP Process Reaching Maximum Open File Count
We have mentioned that HTTP communication relies on TCP connections, and a TCP connection is a socket. For Unix-like systems, opening a socket is equivalent to opening a file. If there are 100 requests connecting to the server, once the connections are successfully established, the server will open 100 files. However, the number of files that a process can open in a Linux system is limited<span>ulimit -f</span>. If this value is set too low, it can also affect HTTP connections. For Nginx or other HTTP programs running in proxy mode, typically, one connection will open two sockets, thus occupying two files (except when hitting Nginx’s local cache or when Nginx directly returns data). Therefore, the number of files that can be opened by the process of a proxy server should also be set higher.
Persistent Connections (Keepalive)
First, we need to understand that keepalive can be set at two levels, and the significance of these two levels is different. TCP keepalive is a mechanism for probing activity, such as the heartbeat information we often refer to, indicating that the other party is still online. The sending of this heartbeat information occurs at intervals, meaning that the TCP connection must remain open. HTTP keep-alive, on the other hand, is a mechanism for reusing TCP connections to avoid frequent establishment of TCP connections.Therefore, it is crucial to understand that TCP keepalive and HTTP keep-alive are not the same thing.
HTTP Keep-Alive Mechanism
Non-persistent connections will disconnect the TCP connection after each HTTP transaction is completed, and the next HTTP transaction will require re-establishing the TCP connection. This is clearly not an efficient mechanism. Therefore, in HTTP/1.1 and the enhanced version of HTTP/1.0, it is allowed for HTTP to keep the TCP connection open after a transaction ends, so that subsequent HTTP transactions can reuse this connection until the client or server actively closes it. Persistent connections reduce the number of TCP connection establishments and maximize the avoidance of traffic limitations caused by TCP slow start.
Looking at the image, the<span>keepalive_timeout 65s</span> setting enables the HTTP keep-alive feature and sets the timeout duration to 65 seconds. Another important option is<span>keepalive_requests 100;</span>, which indicates the maximum number of HTTP requests that can be initiated on the same TCP connection, with the default being 100.
In HTTP/1.0, keep-alive is not used by default. The client must include the<span>Connection: Keep-alive</span> header in the HTTP request to attempt to activate keep-alive. If the server does not support it, keep-alive will not be used, and all requests will proceed in the conventional manner. If the server supports it, the response header will also include<span>Connection: Keep-alive</span>.
In HTTP/1.1, keep-alive is used by default unless explicitly stated otherwise; all connections are persistent. If a connection needs to be closed after a transaction, the HTTP response header must include<span>Connection: Close</span> header; otherwise, the connection will remain open. However, connections cannot remain open indefinitely; idle connections must also be closed, just like the Nginx setting that keeps idle connections open for a maximum of 65 seconds, after which the server will actively close the connection.
TCP Keepalive
In Linux, there is no unified switch to enable or disable TCP keepalive functionality. To check the system’s keepalive settings, use<span>sysctl -a | grep tcp_keepalive</span>. If you have not modified it, on CentOS systems, it will display:
net.ipv4.tcp_keepalive_intvl = 75 # Interval between two probes in seconds
net.ipv4.tcp_keepalive_probes = 9 # Probe frequency
net.ipv4.tcp_keepalive_time = 7200 # Time interval for probing, in seconds, which is 2 hours
According to the default settings, the overall meaning is that probing occurs every 2 hours. If the first probe fails, it will probe again after 75 seconds. If all 9 probes fail, the connection will be actively closed.
To enable TCP keepalive on Nginx, there is a directive called<span>listen</span>, which is used in the server block to set the port on which Nginx listens. It also has other parameters for setting socket properties. Here are some settings:
# Enable TCP keepalive using system defaults
listen 80 default_server so_keepalive=on;
# Explicitly disable TCP keepalive
listen 80 default_server so_keepalive=off;
# Enable TCP keepalive, set to probe every 30 minutes, using system default settings for intervals, total of 10 probes; this setting will override the system defaults
listen 80 default_server so_keepalive=30m::10;
Whether to set this so_keepalive in Nginx depends on the specific scenario. Do not confuse TCP keepalive with HTTP keep-alive; Nginx not enabling so_keepalive does not affect your HTTP requests using the keep-alive feature. If there are load balancing devices between the client and Nginx or between Nginx and the backend server, and both requests and responses pass through this load balancing device, you need to pay attention to this so_keepalive. For example, in LVS’s direct routing mode, it is not affected because responses do not pass through LVS, but in NAT mode, you need to be cautious because LVS maintains TCP sessions for a certain duration. If this duration is shorter than the time it takes for the backend to return data, LVS will disconnect the TCP connection before the client has received the data.

(Copyright belongs to the original author, please delete if infringed)