It has been a month since my apprentice left, and the more I look at his code, the more frustrated I become. Not only are there no comments, but the programming style is uniquely distinctive. As a software developer, one cannot avoid reading others’ code, which inevitably involves the programming standards of a language. Although standards are not rigid requirements of the language itself, they have become a convention among users of each language. Recently, I organized a good set of coding standards online to share.
Code written according to programming standards at least provides a pleasant reading experience, especially for those with obsessive-compulsive tendencies. On the other hand, a unified programming style can reduce errors and facilitate later maintenance.
1. Clarity First
Clarity is an essential characteristic of programs that are easy to maintain and refactor. Code is primarily meant to be read by humans; good code should be able to be read aloud like an article.
2. Simplicity is Beautiful
Simplicity means being easy to understand and implement. The longer the code, the harder it is to comprehend, and the more likely it is to introduce errors during modification. The more code written, the more places there are for errors, which means lower reliability. Therefore, we advocate writing concise and clear code to enhance reliability. Obsolete code (unused functions and global variables) should be removed promptly, and duplicate code should be extracted into functions whenever possible.
3. Choose the Right Style, Consistent with Existing Code
The benefits of sharing a common style among all product owners far outweigh the costs of unification. Under the guidance of existing coding standards in the company, carefully organizing code to make it as clear as possible is a very important skill. When refactoring/modifying code of a different style, a wise approach is to continue writing code according to the existing style of the current code or use formatting tools to convert it to the company’s internal style.
1. Header Files
Principle 1.1: Header files should contain declarations of interfaces, not implementations.
Explanation: Header files are the external interfaces of modules or units. They should contain declarations for external use, such as function declarations, macro definitions, type definitions, etc.
Principle 1.2: Header files should have a single responsibility.
Explanation: Overly complex header files and complex dependencies are the main reasons for long compilation times. Many existing codes have large header files with too many responsibilities, and coupled with circular dependencies, it may lead to including dozens of header files just to use a macro in a .c file.
Principle 1.3: Header files should include stable dependencies.
Explanation: The inclusion relationship of header files is a form of dependency. Generally, unstable modules should depend on stable modules, so that when unstable modules change, they do not affect (compile) stable modules.
Rule 1.1: Each .c file should have a corresponding .h file with the same name for declaring publicly accessible interfaces.
Explanation: If a .c file does not need to expose any interfaces, it should not exist, unless it is the entry point of the program, such as the file containing the main function.
Rule 1.2: Circular dependencies between header files are prohibited.
Explanation: Circular dependencies between header files occur when a.h includes b.h, b.h includes c.h, and c.h includes a.h, causing any modification to one header file to require recompiling all code that includes a.h/b.h/c.h.
In contrast, if there is a unidirectional dependency, such as a.h including b.h, b.h including c.h, and c.h not including any header files, modifying a.h will not cause recompilation of source code that includes b.h/c.h.
Rule 1.3: .c/.h files must not include unnecessary header files.
Explanation: In many systems, the inclusion relationships of header files are complex. Developers may include all conceivable header files for convenience, or some products may simply release a god.h that includes all header files for use by various project teams. This short-sighted approach leads to further deterioration of the entire system’s compilation time and creates significant maintenance challenges for future developers.
Rule 1.4: Header files should be self-contained.
Explanation: Simply put, self-contained means that any header file can be compiled independently. If a file includes a header file and needs to include another header file to work, it increases communication barriers and adds unnecessary burdens to users of that header file.
Rule 1.5: Always write internal #include guards.
Explanation: Multiple inclusions of a header file can be avoided through careful design. If this cannot be achieved, a mechanism must be implemented to prevent the header file’s content from being included more than once.
Note: Not prefixing the macro with an underscore, i.e., using FILENAME_H instead of _FILENAME_H, is because identifiers starting with _ and __ are generally reserved for system or standard library use. Some static analysis tools may issue warnings if globally visible identifiers start with an underscore.
When defining include guards, the following rules should be followed:
1) Use unique names for guards;
2) Do not place code or comments before or after the protected section.
Rule 1.6: Defining variables in header files is prohibited.
Explanation: Defining variables in header files will lead to multiple definitions due to the header file being included by other .c files.
Rule 1.7: Interfaces provided by other .c files should only be used through included header files; using extern to access external function interfaces or variables in .c files is prohibited.
Explanation: If a.c uses the foo() function defined in b.c, it should declare extern int foo(int input); in b.h and use foo in a.c by including <b.h>. It is prohibited to directly write extern int foo(int input); in a.c to use foo, as this approach can lead to inconsistencies between declaration and definition when foo changes. This is a common mistake we make for convenience.
Rule 1.8: Do not include header files within extern “C”.
Explanation: Including header files within extern “C” can lead to nested extern “C”, and Visual Studio has limitations on the nesting level of extern “C”. Too many nested levels will result in compilation errors.
Suggestion 1.1: A module usually contains multiple .c files, and it is recommended to place them in the same directory, with the directory name being the module name. To facilitate external users, it is recommended that each module provide a .h file named after the directory.
Suggestion 1.2: If a module contains multiple sub-modules, it is recommended that each sub-module provide an external .h file named after the sub-module.
Suggestion 1.3: Header files should not use non-standard extensions, such as .inc.
Suggestion 1.4: Maintain a unified order of header file inclusion for the same product.
2. Functions
Principle 2.1: A function should accomplish only one task.
Explanation: A function that implements multiple functionalities creates significant difficulties for development, usage, and maintenance.
Principle 2.2: Duplicate code should be extracted into functions whenever possible.
Explanation: Extracting duplicate code into functions can reduce maintenance costs.
Rule 2.1: Avoid overly long functions; new functions should not exceed 50 lines (excluding empty and comment lines).
Explanation: This rule applies only to newly added functions; for existing functions, it is recommended not to increase the number of lines of code.
Rule 2.2: Avoid excessive nesting of code blocks in functions; new functions should not have more than 4 levels of nested code blocks.
Explanation: This rule applies only to newly added functions; for existing code, it is recommended not to increase the nesting level.
Rule 2.3: Reentrant functions should avoid using shared variables; if necessary, they should be protected through mutual exclusion (disabling interrupts, semaphores).
Rule 2.4: The responsibility for checking parameter validity should be uniformly defined within the project team/module, whether it is the caller or the interface function. By default, it is the caller’s responsibility.
Rule 2.5: All error return codes from functions should be comprehensively handled.
Rule 2.6: Design functions with high fan-in and reasonable fan-out (less than 7).
Explanation: Fan-out refers to the number of other functions directly called (controlled) by a function, while fan-in refers to how many higher-level functions call it. As shown in the figure:
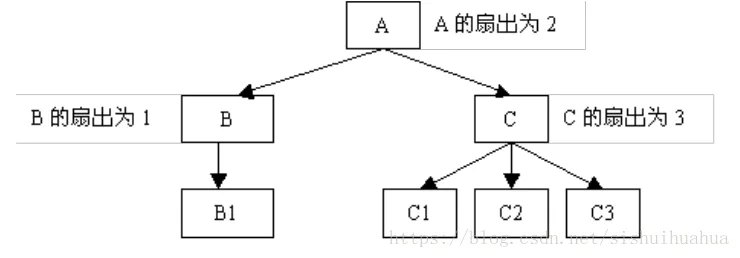
Rule 2.7: Obsolete code (unused functions and variables) should be removed promptly.
Suggestion 2.1: Use const for parameters that do not change.
Explanation: Unchanging values are easier to understand, track, and analyze. Using const as the default option will be checked at compile time, making the code more robust and secure.
Suggestion 2.2: Functions should avoid using global variables, static local variables, and I/O operations; unavoidable cases should be centralized.
Suggestion 2.3: Check the validity of all non-parameter inputs to functions, such as data files, public variables, etc.
Explanation: Function inputs mainly consist of two types: parameter inputs and global variables/data file inputs, i.e., non-parameter inputs. Before using input parameters, functions should perform validity checks.
Suggestion 2.4: The number of parameters for functions should not exceed 5.
Suggestion 2.5: Avoid using variable-length parameter functions except for printing functions.
Suggestion 2.6: All functions declared and defined within the source file should be marked with the static keyword unless they are externally visible.
3. Identifier Naming and Definition
The following naming styles are currently commonly used:
Unix-like style: words are in lowercase letters, separated by underscores, e.g., text_mutex, kernel_text_address.
Windows style: mixed case letters, words are concatenated, with the first letter of each word capitalized. However, Windows style can be awkward when dealing with capitalized proper nouns, for example, naming a function that reads RFC text as ReadRFCText looks less clear than the Unix-like read_rfc_text.
Principle 3.1: Identifiers should be named clearly and meaningfully, using complete words or commonly understood abbreviations to avoid misunderstandings.
Principle 3.2: Avoid using abbreviations for words other than common general abbreviations, and do not use Pinyin.
Suggestion 3.1: Maintain a unified naming style within the product/project team.
Suggestion 3.2: Avoid using numerical identifiers in names unless logically necessary.
Suggestion 3.3: Do not prefix identifiers with module, project, product, or department names.
Suggestion 3.4: Maintain the same naming style for identifiers in platform/driver adaptation code as for the platform/driver.
Suggestion 3.5: When refactoring/modifying parts of the code, maintain consistency with the original naming style.
Suggestion 3.6: Use lowercase characters for file naming.
Rule 3.2: Global variables should have a “g_” prefix.
Rule 3.3: Static variables should have an “s_” prefix.
Rule 3.4: Single-byte variable names are prohibited, but defining i, j, k as local loop variables is allowed.
Suggestion 3.7: Avoid using Hungarian notation.
Explanation: Variable naming should indicate the meaning of the variable, not its type. Adding type indications before variable names reduces readability; a more troublesome issue is that if the variable’s type definition changes, all places using that variable need to be modified.
Suggestion 3.8: Use a noun or adjective + noun structure for variable naming.
Suggestion 3.9: Function names should be based on the action the function performs, generally using a verb or verb + noun structure.
Suggestion 3.10: Function pointers should follow the function naming rules except for the prefix.
Rule 3.5: For defining constants such as numbers or strings, it is recommended to use all uppercase letters with underscores between words (the same applies to enumerations).
Rule 3.6: Except for special identifiers like header files or compilation switches, macro definitions should not start or end with an underscore.
4. Variables
Principle 4.1: A variable should have only one function; do not use a variable for multiple purposes.
Principle 4.2: Structures should have a single function; do not design overly comprehensive data structures.
Principle 4.3: Avoid or minimize the use of global variables.
Rule 4.1: Prevent local variables from having the same name as global variables.
Rule 4.2: Structures used in communication must pay attention to byte order.
Rule 4.3: It is strictly prohibited to use uninitialized variables as right values.
Suggestion 4.1: Ensure that only one module or function can modify or create a global variable, preventing multiple different modules or functions from modifying or creating the same global variable.
Suggestion 4.2: Use interface-oriented programming, accessing data through APIs: if data from this module needs to be exposed to external modules, provide interface functions to set and get it, while ensuring mutual exclusion for accessing global data.
Suggestion 4.3: Initialize variables before their first use, with the initialization location as close to the usage location as possible.
Suggestion 4.4: Clearly define the initialization order of global variables to avoid cross-module initialization dependencies.
Explanation: During system startup, when using global variables, consider when the global variable is initialized. The timing relationship between using global variables and initializing them must be analyzed clearly; otherwise, the consequences can often be trivial yet disastrous.
Suggestion 4.5: Minimize unnecessary default type conversions and forced conversions.
Explanation: When performing forced type conversions, the meaning of the data and the values after conversion may change, and if these details are not carefully considered, it can lead to hidden dangers.
5. Macros and Constants
Rule 5.1: When using macro definitions for expressions, use complete parentheses.
Explanation: Macros are simply code replacements and do not evaluate parameters like functions before passing them.
Rule 5.2: Place multiple expressions defined by macros within curly braces.
Explanation: A better approach is to write multiple statements in a do while(0) format.
Rule 5.3: When using macros, parameters must not change.
Rule 5.4: Do not use magic numbers directly.
Explanation: The disadvantages of using magic numbers include: code is difficult to understand; if a meaningful number is used in multiple places, modifying that value can be costly. Using names that clearly indicate physical states or meanings can increase information and provide a single maintenance point.
Suggestion 5.1: Use functions instead of macros whenever possible unless necessary.
Explanation: Macros have some obvious disadvantages compared to functions: macros lack type checking and are not as strictly checked as function calls.
Suggestion 5.2: It is recommended to use const definitions instead of macros for constants.
Suggestion 5.3: Avoid using statements that change program flow, such as return, goto, continue, break, etc., in macro definitions.
6. Quality Assurance
Principle 6.1: Prioritize code quality assurance.
(1) Correctness refers to the program achieving the functional requirements of the design.
(2) Simplicity refers to the program being easy to understand and implement.
(3) Maintainability refers to the ability to modify the program, including error correction, improvement, and adaptation to changes in new requirements or functional specifications.
(4) Reliability refers to the probability that the program will successfully run according to design requirements under given time intervals and environmental conditions.
(5) Testability refers to the ability of the software to discover, isolate, and locate faults, as well as the ability to design and execute tests within certain time and cost constraints.
(6) Code performance efficiency refers to occupying as few system resources as possible, including memory and execution time.
(7) Portability refers to the ability to modify the system to run outside the originally designed specific environment.
(8) Personal expression/personal convenience refers to individual programming habits.
Principle 6.2: Always be aware of confusing operators, such as certain symbol characteristics and calculation priorities.
Principle 6.3: Understand the memory allocation methods of the compilation system, especially the memory allocation rules for different types of variables, such as where local variables are allocated and where static variables are allocated.
Principle 6.4: Pay attention not only to interfaces but also to implementations.
Explanation: This principle may seem contrary to the “interface-oriented” programming philosophy, but implementations often affect interfaces. The functionality that a function can achieve is not only related to the parameters passed by the caller but is often constrained by other implicit constraints, such as physical memory limitations, network conditions, and specific considerations of the “abstraction gap principle”.
Rule 6.1: Memory operations that go out of bounds are prohibited.
The following measures can help avoid memory out-of-bounds:
Array sizes should consider the maximum case to avoid insufficient space allocation.
Avoid using dangerous functions like sprintf / vsprintf / strcpy / strcat / gets for string operations; use relatively safe functions like snprintf / strncpy / strncat / fgets instead.
When using memcpy/memset, ensure that the length does not go out of bounds.
For strings, consider the final ‘\0’ to ensure all strings end with ‘\0’.
When performing pointer arithmetic, consider the length of the pointer type.
Check array indices.
Use sizeof or strlen to calculate the length of structures/strings, avoiding manual calculations.
The following measures can help avoid memory leaks:
Check memory at exception exit points, ensuring that all resources such as timers/file handles/sockets/queues/semaphores/GUI are released.
When deleting structure pointers, they must be deleted in order from the bottom up.
When using pointer arrays, ensure that each element pointer in the array has been released before releasing the array.
Avoid duplicate memory allocations.
Be cautious when using macros with return or break statements, ensuring that resources have been released beforehand.
Check that each member in the queue has been released.
Rule 6.3: Referencing already released memory space is prohibited.
The following measures can help avoid referencing already released memory space:
After releasing memory, set the pointer to NULL; perform a non-null check before using memory pointers.
When tightly coupled modules call each other, carefully consider their calling relationships to prevent already deleted objects from being reused.
Avoid operating on memory that has already sent messages.
The address of automatic storage objects should not be assigned to other objects that continue to exist after the first object has ceased to exist (objects with larger scopes or static objects or objects returned from a function).
Rule 6.4: Prevent off-by-one errors during programming.
Explanation: Such errors are generally caused by mistakenly writing “<=” as “<” or “>=” as “>”, leading to serious consequences in many cases. Therefore, be cautious in these areas during programming. After completing the program, thoroughly check these operators. Pay attention to the boundary values when using variables.
Suggestion 6.1: Memory allocated within functions should be released before the function exits.
Many functions allocate memory and store it in data structures; comments should be added at the allocation point to indicate where it will be released.
Suggestion 6.2: If statements should preferably include else branches; be cautious with statements that do not have else branches.
Suggestion 6.3: Avoid abusing goto statements.
Explanation: Goto statements can disrupt the structure of the program, so unless absolutely necessary, it is best not to use goto statements.
Suggestion 6.4: Always be aware of whether expressions may overflow or underflow.
7. Program Efficiency
Principle 7.1: Improve code efficiency while ensuring the correctness, simplicity, maintainability, reliability, and testability of the software system.
Principle 7.2: Improve efficiency through optimization of data structures and program algorithms.
Suggestion 7.1: Move calculations of invariant conditions outside of loops.
Suggestion 7.2: For large multi-dimensional arrays, avoid jumping back and forth when accessing array members.
Suggestion 7.3: Create resource libraries to reduce the overhead of allocating objects.
Suggestion 7.4: Change frequently called “small functions” to inline functions or macros.
8. Comments
Principle 8.1: Excellent code can self-explain and be easily understood without comments.
Explanation: Excellent code can be easily understood without comments; comments cannot improve bad code. Code that requires many comments often has bad smells and needs refactoring.
Principle 8.2: Comments should be clear, precise, and unambiguous to prevent ambiguity.
Principle 8.3: Comments should explain the functionality and intent of the code, i.e., comments should clarify intentions that the code cannot directly express, rather than repeating descriptions of the code.
Rule 8.1: When modifying code, maintain all comments surrounding the code to ensure consistency between comments and code. Unused comments should be deleted.
Rule 8.2: The file header should be commented, listing copyright information, version number, generation date, author name, employee number, content, functional description, relationships with other files, modification logs, etc. The comments in header files should also include a brief description of function functionality.
Rule 8.3: Comments at function declarations should describe function functionality, performance, and usage, including input and output parameters, return values, reentrancy requirements, etc.; at definitions, provide detailed descriptions of function functionality and implementation points, such as brief steps of implementation, reasons for implementation, design constraints, etc.
Rule 8.4: Global variables should have detailed comments, including explanations of their functionality, value ranges, and access considerations.
Rule 8.5: Comments should be placed above or to the right of the code, not below. If placed above, they should be separated from the code above by a blank line and indented the same as the code below.
Rule 8.6: For case statements under switch statements, if a special situation requires processing one case before entering the next case, a clear comment must be added after the case statement and before the next case statement.
Rule 8.7: Avoid using abbreviations in comments unless they are industry-standard or standardized within the subsystem.
Rule 8.8: Maintain a unified comment style within the same product or project team.
Suggestion 8.1: Avoid inserting comments in the middle of a line of code or expression.
Suggestion 8.2: Comments should consider program readability and appearance; if the language used is a mix of Chinese and English, it is recommended to use more Chinese unless very fluent and accurate English can be expressed. For foreign employees, the product should determine the comment language.
Suggestion 8.3: The comment format for file headers, function headers, global constants, variables, and type definitions should adopt a tool-recognizable format.
Explanation: Adopting a tool-recognizable comment format, such as Doxygen format, facilitates the export of comments to form help documentation.
9. Formatting and Style
Rule 9.1: Program blocks should be written in an indented style, with each level of indentation being 4 spaces.
Explanation: Currently, various editors/IDEs support automatic conversion of TAB to space input; this feature should be enabled and configured. If the editor/IDE has a feature to display TABs, it should also be enabled to facilitate timely correction of input errors.
Rule 9.2: There must be blank lines between relatively independent program blocks and after variable declarations.
Rule 9.3: A statement should not be too long; if it cannot be split, it should be written on multiple lines. The product can determine how many characters are appropriate for line breaks.
When breaking lines, the following suggestions apply:
Increase indentation by one level when breaking lines to improve code readability;
Break new lines at low-priority operators; operators should also be placed at the beginning of the new line;
When breaking lines, it is recommended to keep a complete statement on one line, rather than breaking based on character count.
Rule 9.4: Multiple short statements (including assignment statements) should not be written on the same line; only one statement should be written per line.
Rule 9.5: Statements such as if, for, do, while, case, switch, and default should occupy one line.
Rule 9.6: When performing equal operations on two or more keywords, variables, or constants, spaces should be added before and after the operators; for non-equal operations, if it is a closely related immediate operator (such as ->), no space should be added after.
Suggestion 9.1: There should be a space between the comment symbol (including ‘/’, ‘//’, ‘/*’) and the comment content.
Suggestion 9.2: Code that is closely related in the source program should be kept as close as possible.
10. Expressions
Rule 10.1: The value of an expression should be the same under any order of operations allowed by the standard.
Suggestion 10.1: Avoid using function calls as parameters for another function, as it is detrimental to debugging and reading the code.
Suggestion 10.2: Assignment statements should not be written in if statements or used as function parameters.
Suggestion 10.3: Assignment operators should not be used in expressions that produce boolean values.
11. Code Editing and Compilation
Rule 11.1: Use the highest warning level of the compiler, understand all warnings, and eliminate all warnings by modifying code rather than lowering the warning level.
Rule 11.2: In product software (project teams), unify compilation switches, static check options, and corresponding warning elimination strategies.
Rule 11.3: The configuration of local build tools (such as PC-Lint) should be consistent with continuous integration.
Rule 11.4: Use version control (configuration management) systems to timely check in code built locally, ensuring that the checked-in code does not affect successful builds.
Suggestion 11.1: Be cautious when using the block copy feature provided by the editor for programming.
12. Testability
Principle 12.1: Modules should be clearly divided, interfaces should be clear, coupling should be low, and there should be clear inputs and outputs; otherwise, implementing unit tests will be difficult.
Explanation: The implementation of unit tests depends on:
Clear, complete, and stable definitions of module interfaces;
Clear acceptance criteria for module functionality (including: preconditions, inputs, and expected results);
Key states and key data within the module can be queried and modified;
There is a unique entry for the atomic functionality of the module;
There is a unique exit for the atomic functionality of the module;
Dependencies are handled centrally: global variables related to the module should be minimized or encapsulated in some form.
Rule 12.1: Within the same project or product team, there should be a unified set of debugging switches and corresponding printing functions prepared for integration testing and system debugging, along with detailed documentation.
Rule 12.2: Within the same project or product team, debugging print logs should have unified regulations.
Explanation: Unified debugging log records facilitate integration testing, specifically including:
Unified log categories and log levels;
Log output content and format can be configured and changed via command line, network management, etc.;
Logs should be recorded at critical branches; it is recommended not to record logs within atomic functions, as it makes locating issues difficult;
Debugging log records should include file/module names, code line numbers, function names, called function names, error codes, and the environment in which the error occurred.
Rule 12.3: Use assertions to record internal assumptions.
Rule 12.4: Assertions should not be used to check runtime errors.
Explanation: Assertions are used to check whether internal programming or design meets assumptions; they cannot handle situations that may occur and must be handled. For example, when a module receives messages from other modules or links, it must check the validity of the messages; this process is normal error checking and cannot be implemented with assertions.
Suggestion 12.1: Prepare methods and channels for unit testing and system fault injection testing.
13. Security
Principle 13.1: Check user inputs.
Explanation: Do not assume that user inputs are all valid, as it is difficult to guarantee that there are no malicious users. Even legitimate users may produce illegal inputs due to misuse or operational errors. User inputs usually need to be validated for safety, especially in the following scenarios:
User inputs as loop conditions
User inputs as array indices
User inputs as size parameters for memory allocation
User inputs as format strings
User inputs as business data (e.g., as command execution parameters, assembling SQL statements, or persisting in a specific format)
If user data is not validated for legality in these cases, it can lead to issues such as DOS, memory overflows, format string vulnerabilities, command injections, SQL injections, buffer overflows, and data corruption.
The following measures can be taken to check user inputs:
For user inputs as numbers, perform range checks.
For user inputs as strings, check string lengths.
For user inputs as format strings, check for the keyword “%”.
For user inputs as business data, check and escape keywords.
Rule 13.1: Ensure all strings are NULL-terminated.
Explanation: In C language, ‘\0’ serves as the string terminator, i.e., the NULL terminator. Standard string handling functions (such as strcpy(), strlen()) rely on the NULL terminator to determine the length of the string. Incorrectly using NULL to terminate strings can lead to buffer overflows and other undefined behaviors.
To avoid buffer overflows, relatively safe string operation functions that limit character counts are often used instead of dangerous functions, such as:
Using strncpy() instead of strcpy()
Using strncat() instead of strcat()
Using snprintf() instead of sprintf()
Using fgets() instead of gets()
These functions truncate strings that exceed specified limits, but be aware that they do not guarantee that the target string will always be NULL-terminated. If there is no NULL character in the first n characters of the source string, the target string will not be NULL-terminated.
Rule 13.2: Avoid writing strings with unclear boundaries into fixed-length arrays.
Explanation: Strings with unclear boundaries (such as those from gets(), getenv(), scanf()) may exceed the target array length, and directly copying them into fixed-length arrays can easily lead to buffer overflows.
Rule 13.3: Avoid integer overflows.
Explanation: An integer overflow occurs when an integer is increased beyond its maximum value, and an integer underflow occurs when it is decreased below its minimum value. Both signed and unsigned numbers can overflow.
Rule 13.4: Avoid sign errors.
Explanation: Sometimes, converting from signed integers to unsigned integers can lead to sign errors. Sign errors do not lose data, but the data loses its original meaning.
When converting signed integers to unsigned integers, the highest-order bit loses its function as a sign bit. If the signed integer’s value is non-negative, the converted value remains unchanged; if the signed integer’s value is negative, the converted result is usually a very large positive number.
Rule 13.5: Avoid truncation errors.
Explanation: Converting a larger integer type to a smaller integer type, when the original value exceeds the representable range of the smaller type, will cause truncation errors, where the lower bits of the original value are retained while the higher bits are discarded. Truncation errors can lead to data loss. Using truncated variables for memory operations can likely cause issues.
Rule 13.6: Ensure format characters match parameters.
Explanation: When using formatted strings, be careful to ensure that format characters match the parameters, preserving quantity and data types. Mismatches between format characters and parameters can lead to undefined behaviors. In most cases, incorrect formatted strings can cause the program to terminate abnormally.
Rule 13.7: Avoid using user inputs as part or all of the format string.
Explanation: When calling formatted I/O functions, do not directly or indirectly use user inputs as part or all of the format string. If an attacker has partial or complete control over a format string, there are risks of process crashes, viewing stack contents, rewriting memory, or even executing arbitrary code.
Rule 13.8: Avoid using strlen() to calculate the length of binary data.
Explanation: The strlen() function is used to calculate the length of a string; it returns the number of characters before the first NULL terminator. Therefore, be cautious when using strlen() with content read by file I/O functions, as this content may be binary or text.
Rule 13.9: Use int type variables to receive return values from character I/O functions.
Rule 13.10: Prevent command injection.
Explanation: The C99 function system() executes a specified program/command by calling a system-defined command interpreter (such as UNIX’s shell, Windows’ CMD.exe). Similar functions include POSIX’s popen().
14. Unit Testing
Rule 14.1: Write unit test cases to verify the correctness of software design/coding while writing code or before writing code.
Suggestion 14.1: Unit tests should focus on the behavior of units rather than their implementation, avoiding tests that target functions.
Explanation: The unit being tested should be viewed as a whole. Based on actual resources, progress, and quality risks, balance code coverage, stubbing workload, the difficulty of supplementing test cases, and the stability of the object being tested. Generally, it is recommended to focus on testing modules/components and to avoid testing individual functions whenever possible. Although sometimes a single test case can only focus on testing a specific function, our focus should be on the function’s behavior rather than its specific implementation details.
15. Portability
Rule 15.1: Do not define, redefine, or undefine reserved identifiers, macros, and functions in the standard library/platform.
Suggestion 15.1: Avoid using statements closely related to hardware or operating systems, and use recommended standard statements to improve software portability and reusability.
Suggestion 15.2: Avoid using embedded assembly unless necessary to meet special requirements.
Explanation: Embedded assembly in programs generally has a significant impact on portability.
From C Language Plus