Click “Developer Technology Frontline“, select “Star🔝”
Looking|Star|Message, True Love
 Author: billpchen, Frontend Developer at Tencent
Author: billpchen, Frontend Developer at Tencent
After the HTTP/2 standard was published in 2015, most mainstream browsers supported this standard by the end of that year. Since then, with advantages such as multiplexing, header compression, and server push, HTTP/2 has gained increasing favor among developers. Unbeknownst to us, HTTP has now evolved to its third generation. This article, based on the practice of integrating HTTP/3 into Interest Tribe, discusses the principles of HTTP/3 and how to access it in business.
1. Principles of HTTP/3
1.1 History of HTTP
Before introducing HTTP/3, let’s briefly look at the history of HTTP to understand the background of HTTP/3’s emergence.

With the development of network technology, HTTP/1.1, designed in 1999, can no longer meet the demands. Therefore, Google designed SPDY based on TCP in 2009. Later, the SPDY development team pushed for SPDY to become an official standard, but it ultimately failed. However, the SPDY development team participated throughout the process of formulating HTTP/2, referencing many of SPDY’s designs, so we generally consider SPDY to be the predecessor of HTTP/2. Both SPDY and HTTP/2 are based on TCP, which has inherent efficiency disadvantages compared to UDP. Thus, in 2013, Google developed a transport layer protocol called QUIC based on UDP, hoping it could replace TCP to make web transmission more efficient. Following a proposal, the Internet Engineering Task Force officially renamed HTTP based on the QUIC protocol (HTTP over QUIC) to HTTP/3.
1.2 Overview of the QUIC Protocol
TCP has always been a crucial protocol at the transport layer, while UDP has remained relatively obscure. When asked about the differences between TCP and UDP in interviews, responses regarding UDP are often brief. For a long time, UDP has been perceived as a fast but unreliable transport layer protocol. However, sometimes a flaw can also be an advantage. QUIC (Quick UDP Internet Connections) is based on UDP, precisely because of UDP’s speed and efficiency. At the same time, QUIC integrates and optimizes the advantages of TCP, TLS, and HTTP/2. A diagram can clearly illustrate their relationships.

So what is the relationship between QUIC and HTTP/3? QUIC is a transport layer protocol designed to replace TCP and SSL/TLS. Above the transport layer, there is the application layer, where well-known application layer protocols such as HTTP, FTP, IMAP, etc., can theoretically run on top of QUIC. The HTTP protocol running on QUIC is referred to as HTTP/3, which is the meaning of “HTTP over QUIC, i.e., HTTP/3”.
Therefore, to understand HTTP/3, one cannot bypass QUIC. Below, we will mainly explore several important features to deepen our understanding of QUIC.
1.3 Zero RTT Connection Establishment
A diagram can vividly illustrate the differences in connection establishment between HTTP/2 and HTTP/3.
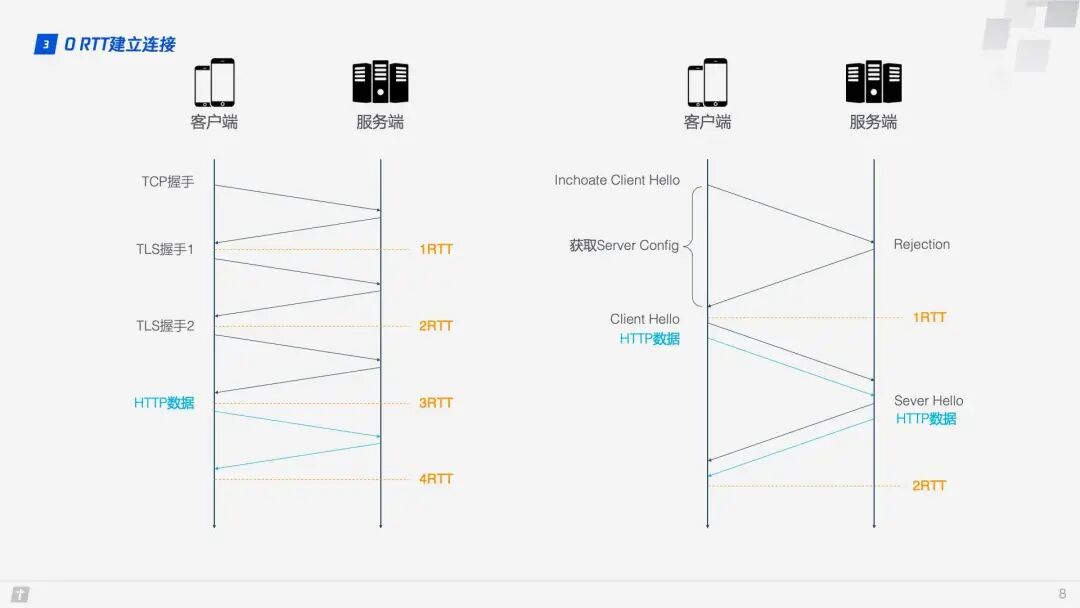
HTTP/2 connections require 3 RTTs. If session reuse is considered, meaning caching the symmetric key derived from the first handshake, it still requires 2 RTTs. Furthermore, if TLS is upgraded to 1.3, then an HTTP/2 connection requires 2 RTTs, and considering session reuse, it requires 1 RTT. Some may argue that HTTP/2 does not necessarily require HTTPS, and the handshake process can be simplified. This is true; the HTTP/2 standard does not require HTTPS. However, in practice, all browser implementations require HTTP/2 to be based on HTTPS, making encrypted connections essential. In contrast, HTTP/3 requires only 1 RTT for the first connection, and subsequent connections can achieve 0 RTT, meaning the first packet sent from the client to the server contains request data, a feat that HTTP/2 cannot match. What is the principle behind this? Let’s take a closer look at the QUIC connection process.
Step 1: During the first connection, the client sends an Inchoate Client Hello to the server to request a connection;
Step 2: The server generates g, p, a, calculates A based on g, p, and a, then places g, p, and A into the Server Config and sends a Rejection message back to the client;
Step 3: Upon receiving g, p, and A, the client generates b, calculates B based on g, p, and b, and computes the initial key K based on A, p, and b. After calculating B and K, the client encrypts the HTTP data using K and sends it to the server along with B;
Step 4: The server receives B, generates the same key as the client using a, p, and B, and decrypts the received HTTP data using this key. For further security (forward secrecy), the server updates its random number a and public key, generates a new key S, and sends the public key back to the client via the Server Hello message, along with the HTTP response data;
Step 5: Upon receiving the Server Hello, the client generates a new key S consistent with the server, and all subsequent transmissions use S for encryption.
Thus, QUIC takes a total of 1 RTT from requesting a connection to officially receiving HTTP data. This 1 RTT is mainly to obtain the Server Config. If the client caches the Server Config for subsequent connections, it can directly send HTTP data, achieving 0 RTT connection establishment.
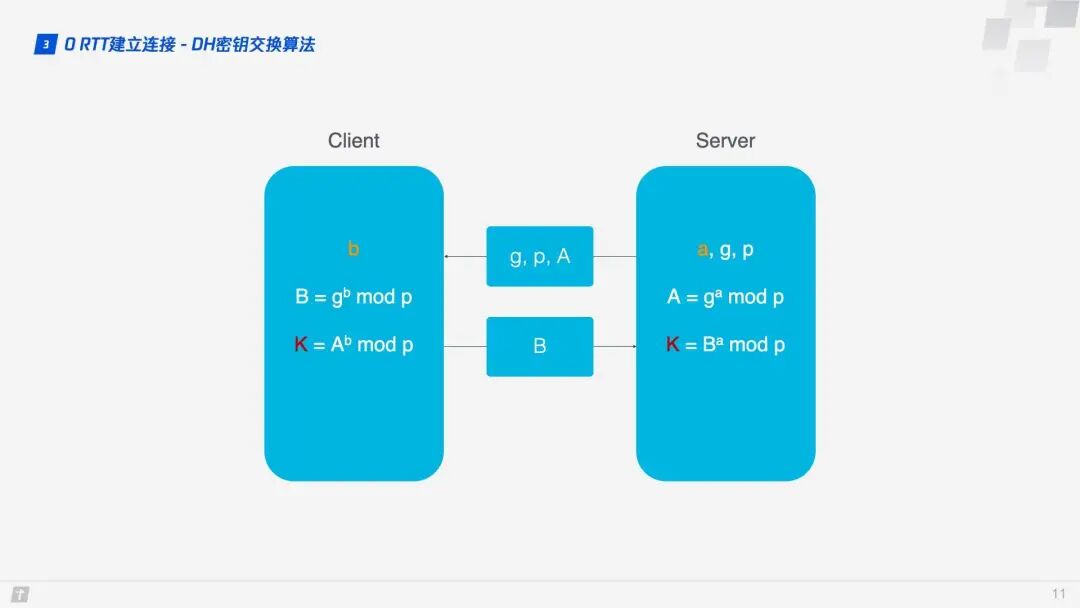
Here, the DH key exchange algorithm is used. The core of the DH algorithm is that the server generates three random numbers a, g, and p, where a is kept private, and g and p are transmitted to the client. The client generates one random number b. Through the DH algorithm, both the client and server can compute the same key. During this process, a and b do not participate in network transmission, greatly enhancing security. Since p and g are large numbers, even if p, g, A, and B transmitted over the network are intercepted, current computing power cannot crack the key.
1.4 Connection Migration
TCP connections are based on a four-tuple (source IP, source port, destination IP, destination port). When switching networks, at least one of these factors changes, leading to a change in the connection. When a connection changes, if the original TCP connection is still used, it will result in a connection failure, necessitating a wait for the original connection to time out before re-establishing a connection. This is why we sometimes find that when switching to a new network, even if the new network is in good condition, the content still takes a long time to load. If implemented well, a new TCP connection can be established immediately upon detecting a network change. However, even so, establishing a new connection still takes several hundred milliseconds.
QUIC connections are not affected by the four-tuple. When any of these four elements change, the original connection can still be maintained. How is this achieved? The principle is simple: QUIC connections do not use the four-tuple as an identifier but instead use a 64-bit random number known as the Connection ID. As long as the Connection ID remains unchanged, the connection can be maintained even if the IP or port changes.
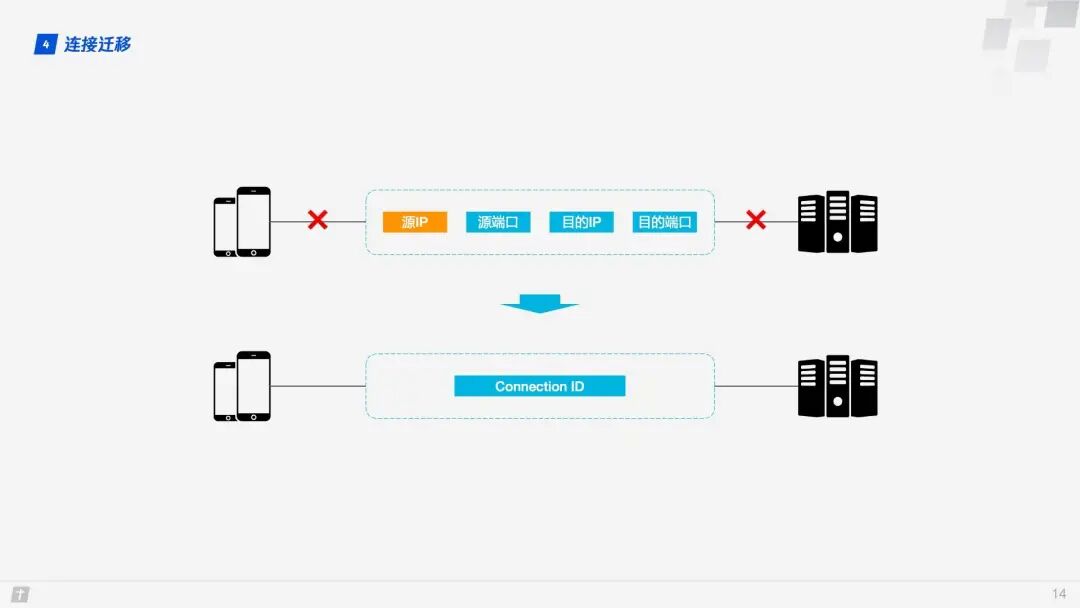
1.5 Head-of-Line Blocking / Multiplexing
Both HTTP/1.1 and HTTP/2 suffer from head-of-line blocking issues. So, what is head-of-line blocking?
TCP is a connection-oriented protocol, meaning that after sending a request, it must receive an ACK message to confirm that the other party has received the data. If each request must wait for the ACK message of the previous request before sending the next one, the efficiency is undoubtedly very low. Later, HTTP/1.1 introduced the Pipelining technique, allowing multiple requests to be sent simultaneously over a single TCP connection, significantly improving transmission efficiency.
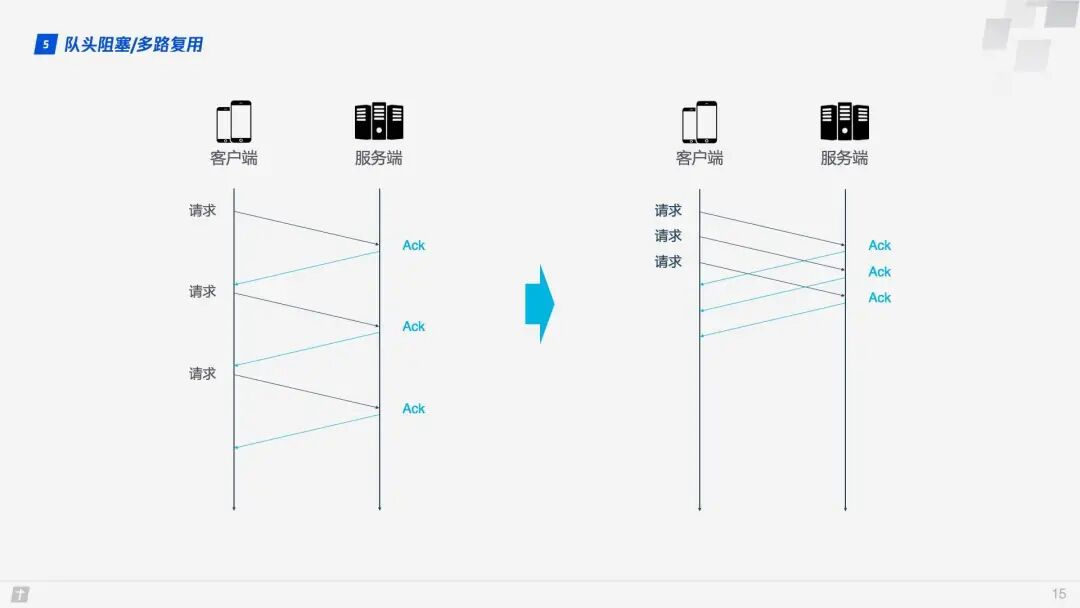
In this context, let’s discuss the head-of-line blocking in HTTP/1.1. In the diagram below, a single TCP connection transmits 10 requests simultaneously. The first, second, and third requests have been received by the client, but the fourth request is lost. As a result, requests five through ten are blocked and must wait for the fourth request to be processed before they can be handled, wasting bandwidth resources.
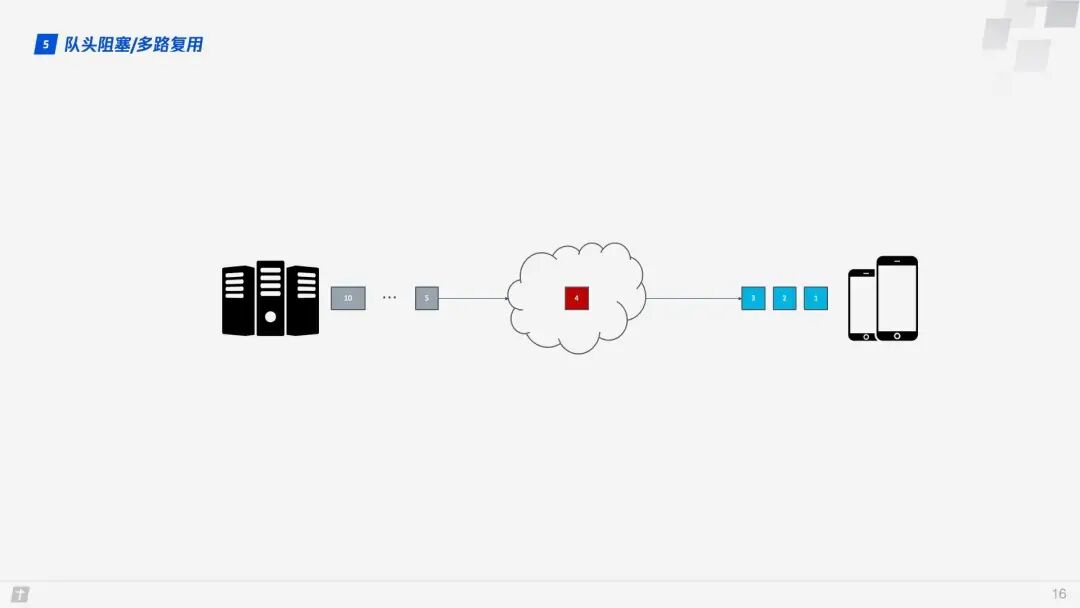
Therefore, HTTP generally allows each host to establish six TCP connections, which can better utilize bandwidth resources, but the head-of-line blocking issue still exists within each connection.
HTTP/2’s multiplexing solves the aforementioned head-of-line blocking problem. Unlike HTTP/1.1, where the next request’s data packets can only be transmitted after all data packets of the previous request have been transmitted, in HTTP/2, each request is split into multiple frames and transmitted simultaneously over a single TCP connection. Thus, even if one request is blocked, it does not affect other requests. As shown in the diagram below, different colors represent different requests, and blocks of the same color represent frames that have been split from the request.
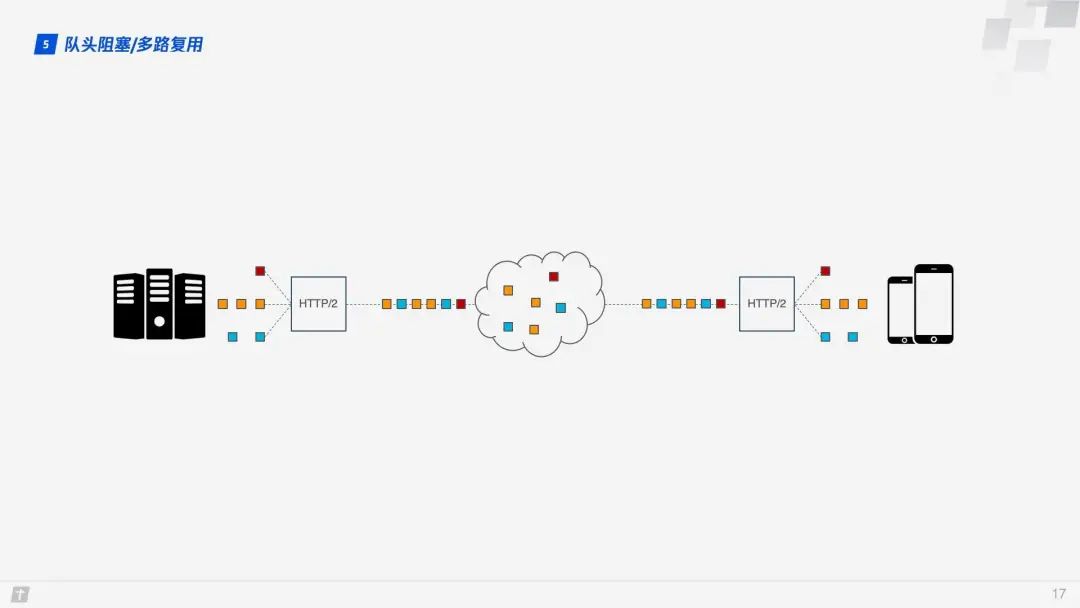
However, the story does not end here. Although HTTP/2 can solve blocking at the “request” granularity, the underlying TCP protocol still has inherent head-of-line blocking issues. Each request in HTTP/2 is split into multiple frames, and frames from different requests combine to form streams. A stream is a logical transmission unit over TCP, allowing HTTP/2 to achieve the goal of sending multiple requests simultaneously over a single connection. For example, if four streams are sent simultaneously over a single TCP connection, and Stream1 is successfully delivered, but the third frame of Stream2 is lost, TCP processes data in strict order, requiring the first sent frame to be processed first. This means that the sender must retransmit the third frame, and although Streams 3 and 4 have been received, they cannot be processed, causing the entire connection to be blocked.
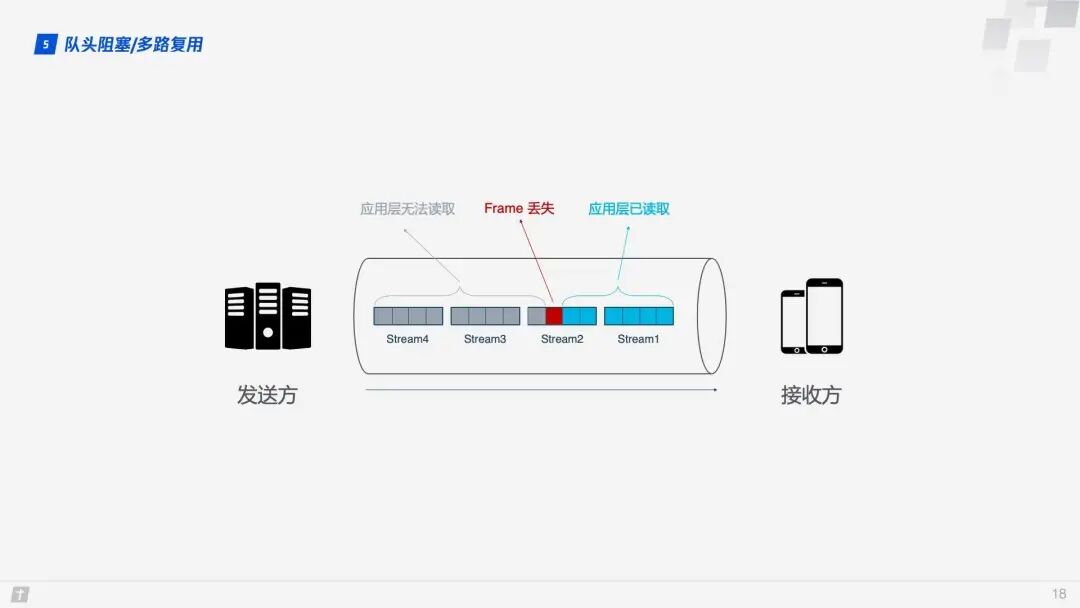
Moreover, since HTTP/2 must use HTTPS, and the TLS protocol used by HTTPS also has head-of-line blocking issues, TLS organizes data based on records, grouping a bunch of data together (i.e., a record) for encryption. After encryption, the data is split into multiple TCP packets for transmission. Generally, each record is 16K, containing 12 TCP packets. If any one of these 12 TCP packets is lost, the entire record cannot be decrypted.
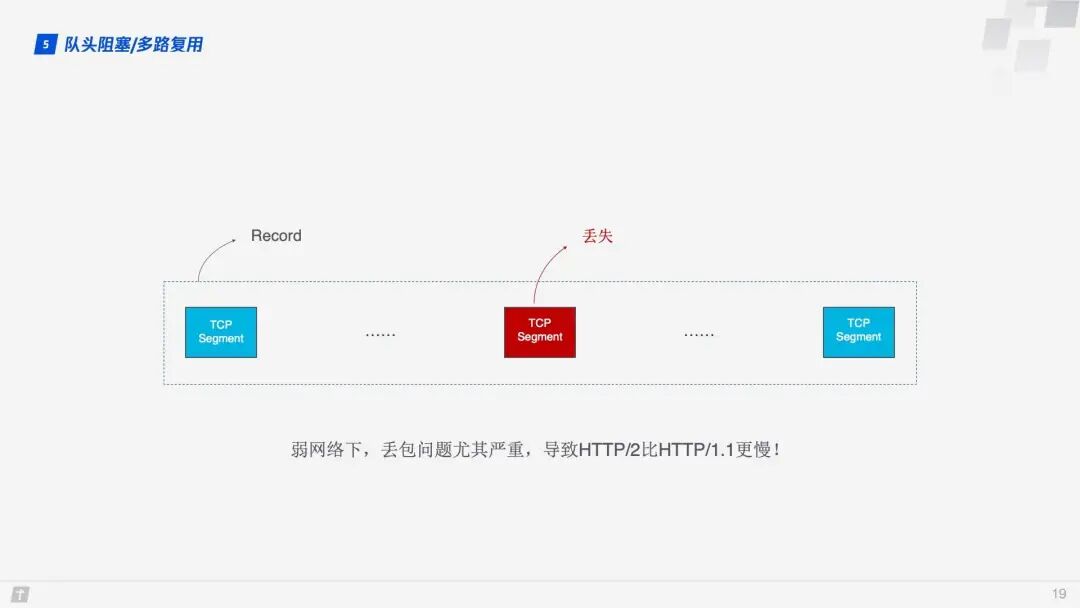
Head-of-line blocking can cause HTTP/2 to be slower than HTTP/1.1 in weak network environments where packet loss is more likely!
So how does QUIC solve the head-of-line blocking problem? There are two main points.
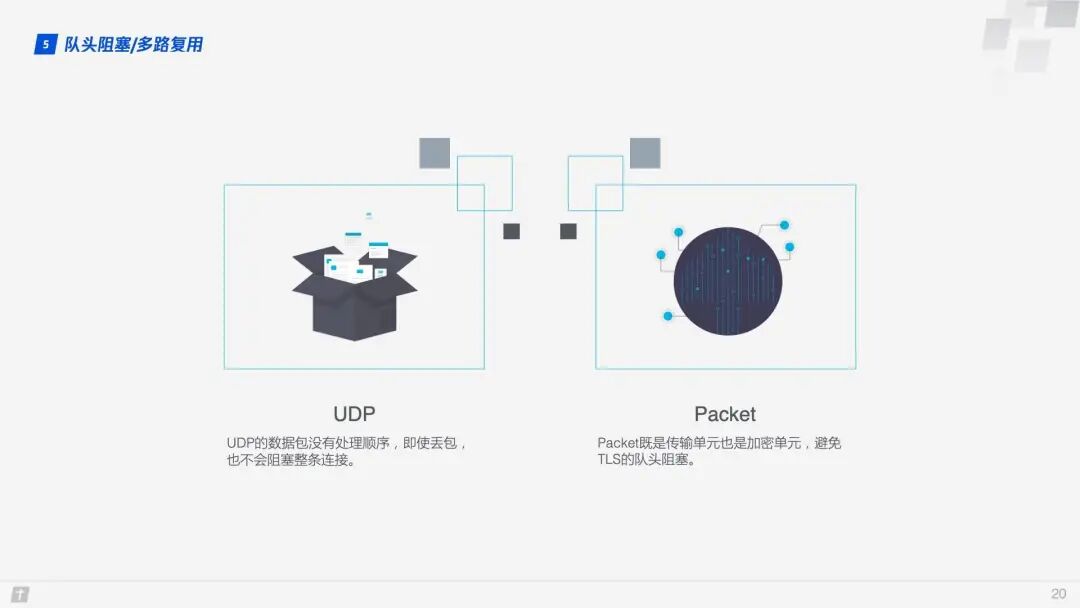
- QUIC’s transmission unit is a packet, and the encryption unit is also a packet. The entire encryption, transmission, and decryption process is based on packets, which avoids the head-of-line blocking issues of TLS;
- QUIC is based on UDP, where packets are not processed in order at the receiving end. Even if one packet is lost in the middle, it does not block the entire connection, and other resources can be processed normally.
1.6 Congestion Control
The purpose of congestion control is to prevent too much data from flooding the network at once, causing it to exceed its maximum capacity. QUIC’s congestion control is similar to TCP but has made improvements on this basis. Therefore, let’s briefly introduce TCP’s congestion control.
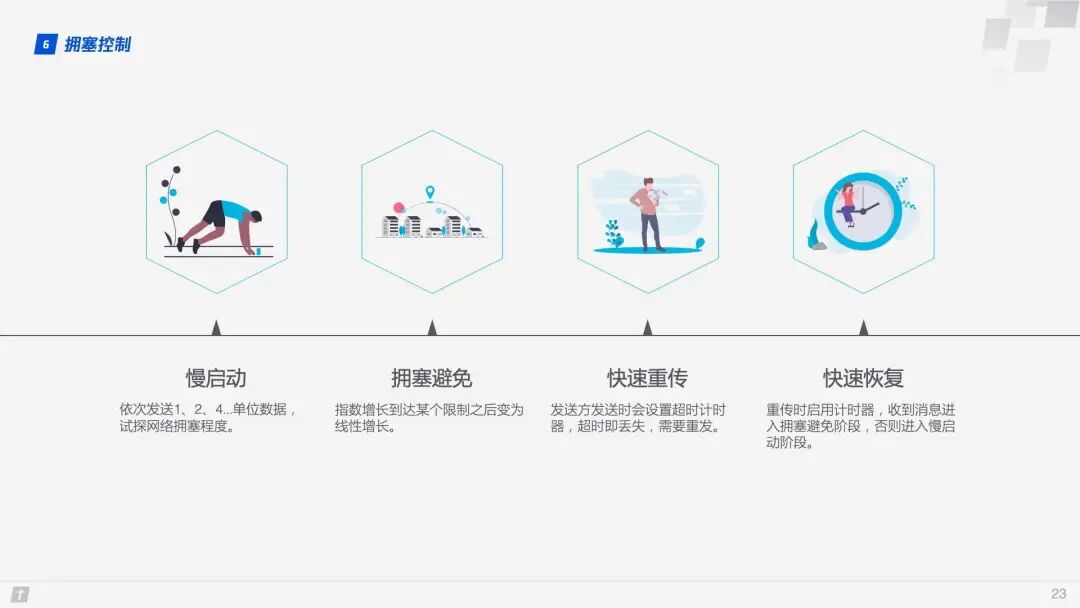
TCP congestion control consists of four core algorithms: slow start, congestion avoidance, fast retransmit, and fast recovery. Understanding these four algorithms provides a general understanding of TCP’s congestion control.
- Slow Start: The sender sends one unit of data to the receiver. After receiving confirmation from the other party, it sends two units of data, then four, eight, and so on, growing exponentially. This process continuously probes the network’s congestion level, and exceeding a threshold can lead to network congestion;
- Congestion Avoidance: Exponential growth cannot be infinite. After reaching a certain limit (the slow start threshold), the growth changes from exponential to linear;
- Fast Retransmit: The sender sets a timeout timer for each transmission. If the timeout occurs, it is assumed that the data is lost and needs to be retransmitted;
- Fast Recovery: Based on the fast retransmit, when the sender retransmits data, it also starts a timeout timer. If it receives a confirmation message, it enters the congestion avoidance phase; if it still times out, it returns to the slow start phase.
QUIC reimplements the TCP Cubic algorithm for congestion control and has made several improvements on this basis. Below are some features of QUIC’s improved congestion control.
1.6.1 Hot Plugging
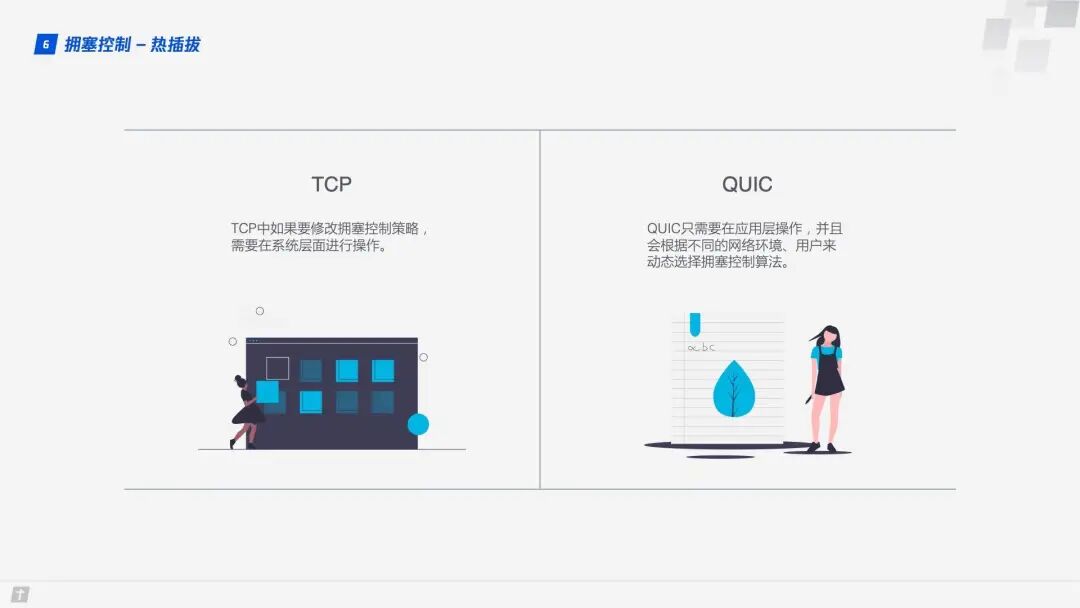
In TCP, modifying the congestion control strategy requires system-level operations. In QUIC, changing the congestion control strategy only requires application-level operations, and QUIC dynamically selects the congestion control algorithm based on different network environments and users.
1.6.2 Forward Error Correction (FEC)
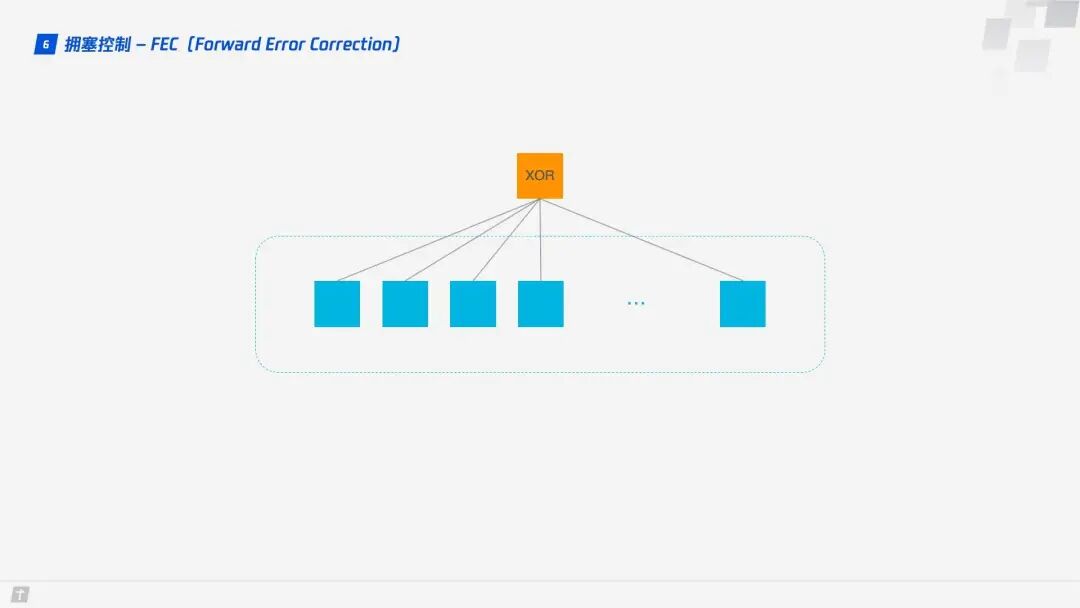
QUIC uses Forward Error Correction (FEC) technology to increase the protocol’s fault tolerance. A segment of data is split into 10 packets, and each packet undergoes an XOR operation. The result of this operation is transmitted as an FEC packet along with the data packets. If, unfortunately, one data packet is lost during transmission, the missing packet’s data can be inferred from the remaining nine packets and the FEC packet, greatly enhancing the protocol’s fault tolerance.
This is a solution that aligns with current network technology. At this stage, bandwidth is no longer the bottleneck for network transmission; round-trip time is. Therefore, new network transmission protocols can appropriately increase data redundancy to reduce retransmission operations.
1.6.3 Monotonically Increasing Packet Number
To ensure reliability, TCP uses Sequence Numbers and ACKs to confirm whether messages arrive in order, but this design has flaws.
When a timeout occurs, the client initiates a retransmission. Later, it receives an ACK confirmation message, but since the ACK message for the original request and the retransmission request is the same, the client is left confused, not knowing whether this ACK corresponds to the original request or the retransmission request. If the client assumes it is the ACK for the original request, but it is actually the case on the left, the calculated sample RTT will be too large; if the client assumes it is the ACK for the retransmission request, but it is actually the case on the right, it will lead to a sample RTT that is too small. The terms in the diagram include RTO, which refers to the Retransmission TimeOut, and is very similar to the familiar RTT (Round Trip Time). Sample RTT affects RTO calculations, and accurately grasping the timeout duration is crucial; both too long and too short are inappropriate.
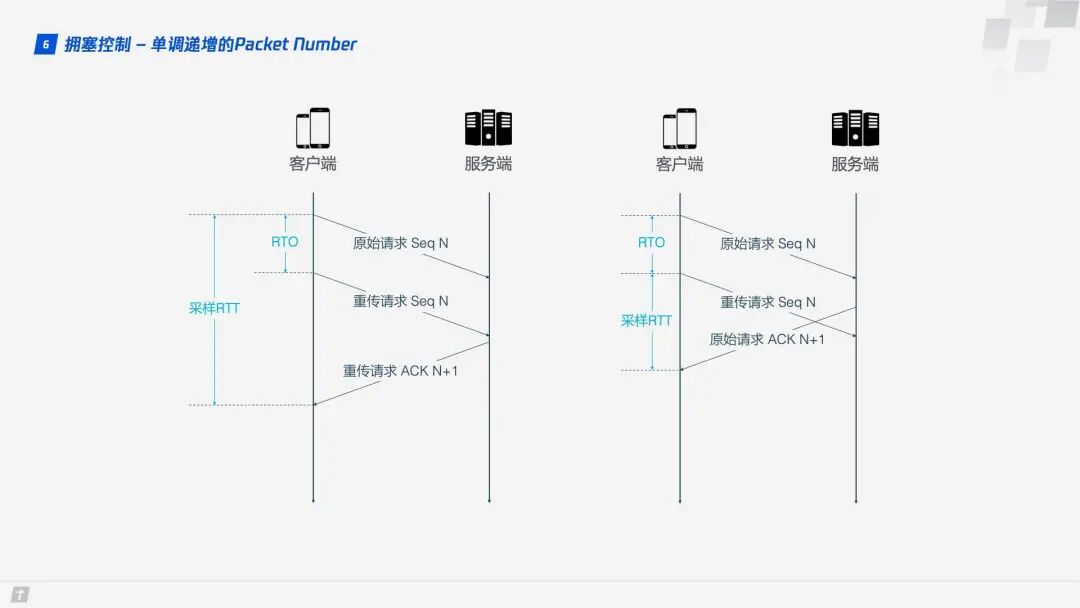
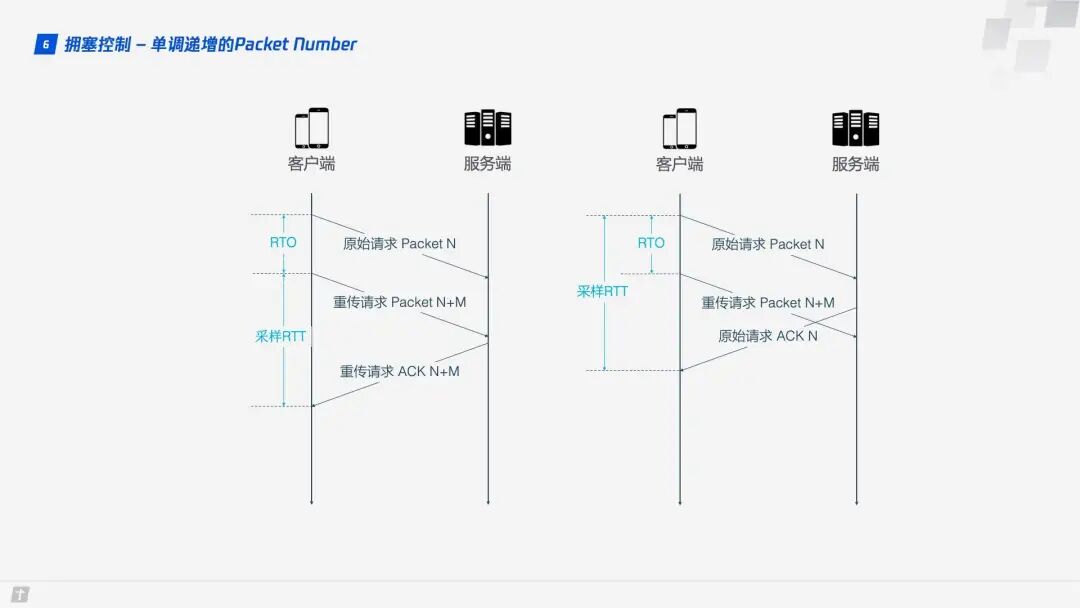
QUIC resolves the ambiguity issue mentioned above. Unlike Sequence Numbers, Packet Numbers are strictly monotonically increasing. If Packet N is lost, the retransmission will not use N as the identifier but a larger number, such as N + M. This way, when the sender receives the confirmation message, it can easily determine whether the ACK corresponds to the original request or the retransmission request.
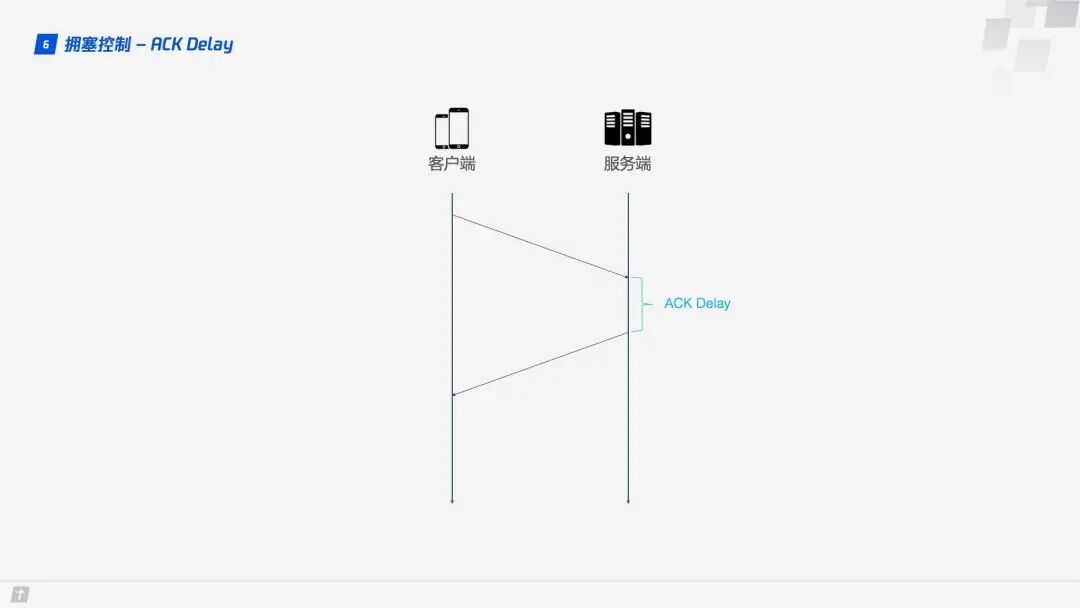
1.6.4 ACK Delay
TCP does not consider the delay between the receiver receiving data and sending the confirmation message when calculating RTT, as shown in the diagram below. This delay is known as ACK Delay. QUIC takes this delay into account, making RTT calculations more accurate.
1.6.5 More ACK Blocks
Generally, the receiver should send an ACK reply after receiving a message from the sender to indicate that the data has been received. However, sending an ACK reply for every single data packet is cumbersome, so typically, the receiver does not reply immediately but waits until multiple data packets are received before responding. TCP SACK provides a maximum of three ACK blocks. However, in some scenarios, such as downloading, the server only needs to return data, but according to TCP’s design, an ACK must be returned for every three data packets received. In contrast, QUIC can carry up to 256 ACK blocks. In networks with high packet loss rates, more ACK blocks can reduce retransmissions and improve network efficiency.

1.7 Flow Control
TCP performs flow control on each TCP connection, which means that the sender should not send data too quickly, allowing the receiver to keep up; otherwise, data overflow and loss may occur. TCP’s flow control is mainly implemented through a sliding window. It can be seen that congestion control mainly regulates the sender’s sending strategy but does not consider the receiver’s receiving capacity, while flow control complements this aspect.
QUIC only needs to establish one connection, over which multiple streams can be transmitted simultaneously. This is akin to having a road with warehouses at both ends, with many vehicles transporting goods along the road. QUIC’s flow control has two levels: connection level and stream level, similar to controlling the total flow on the road to prevent too many vehicles from flooding in at once, and also ensuring that no single vehicle carries too much cargo at once, which could overwhelm the processing capacity.
So how does QUIC implement flow control? Let’s first look at the flow control of a single stream. When a stream has not yet transmitted data, the receive window (flow control receive window) is the maximum receive window (flow control receive window). As the receiver receives data, the receive window gradually shrinks. Among the received data, some have been processed, while others have not yet been handled. In the diagram below, the blue blocks represent processed data, while the yellow blocks represent unprocessed data, which causes the stream’s receive window to shrink.
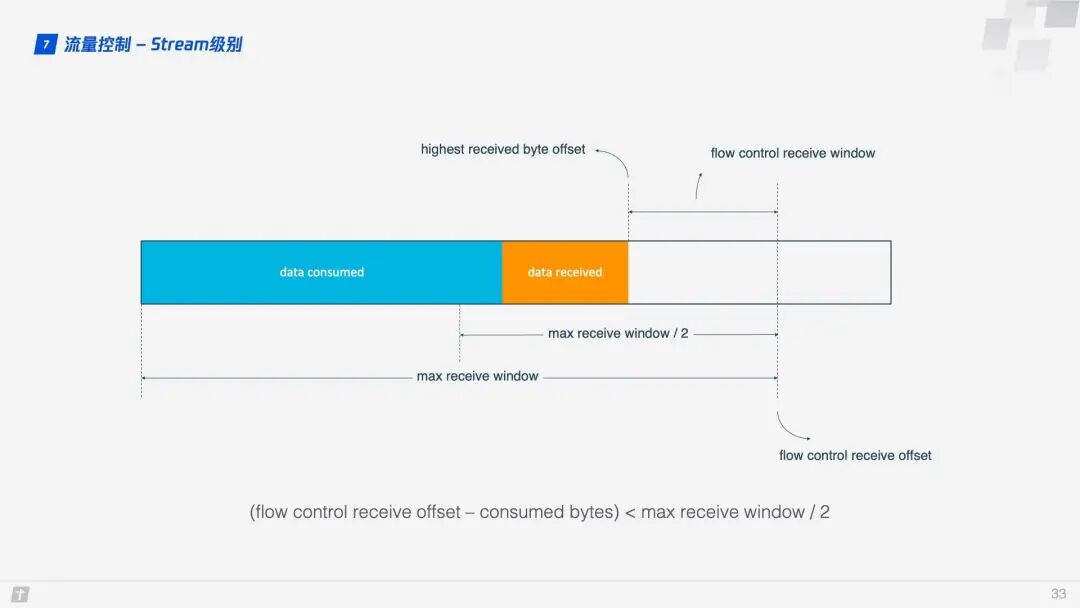
As data continues to be processed, the receiver can handle more data. When (flow control receive offset – consumed bytes) < (max receive window / 2), the receiver will send a WINDOW_UPDATE frame to inform the sender that it can accept more data. At this point, the flow control receive offset will shift, and the receive window will increase, allowing the sender to send more data to the receiver.
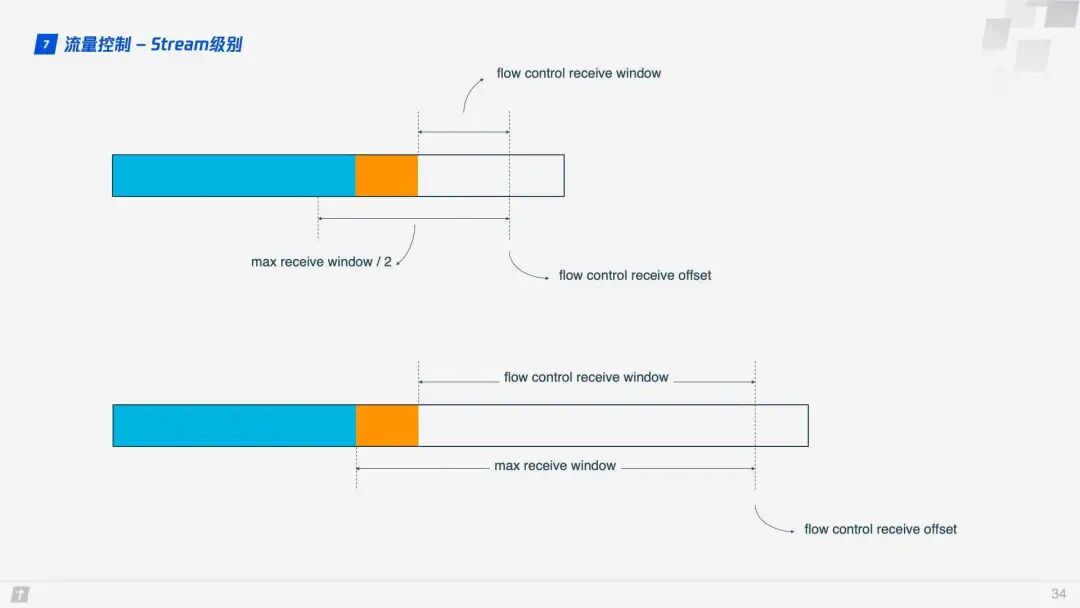
Stream-level flow control has limited effectiveness in preventing the receiver from receiving too much data; it requires the assistance of connection-level flow control. Understanding stream flow control makes it easy to understand connection flow control. In a stream, the receive window (flow control receive window) = maximum receive window (max receive window) – received data (highest received byte offset), while for a connection: the receive window = Stream1 receive window + Stream2 receive window + … + StreamN receive window.
2. Summary
QUIC discards the burdens of TCP and TLS, is based on UDP, and draws on and improves the experiences of TCP, TLS, and HTTP/2 to implement a secure, efficient, and reliable HTTP communication protocol. With excellent features such as 0 RTT connection establishment, smooth connection migration, virtually eliminating head-of-line blocking, improved congestion control, and flow control, QUIC achieves better performance than HTTP/2 in most scenarios.
A week ago, Microsoft announced the open-sourcing of its internal QUIC library — MsQuic, and will fully recommend the QUIC protocol to replace TCP/IP.
The future of HTTP/3 is promising.

END

 Click to view
Click to view