
This article analyzes the current community and product status of the hot Linux kernel project Large Folios and predicts future trends. The technical content discussed in the article comes from contributions to the community and products from several companies, including Google, OPPO, ARM, Nivida, Samsung, Huawei, and Alibaba.
Authors | Barry Song, Yu Zhao Editors | Meng Yidan
Produced by | CSDN (ID: CSDNnews)
In the Linux kernel, a folio can contain just 1 page or multiple pages. When a folio contains multiple pages, we call it a large folio, and in the Chinese community, we generally refer to it as a large page. Using large folios can potentially bring many benefits, such as:
1. Reduced TLB misses; many hardware supports PMD mapping, allowing a 2MB large folio to occupy a single TLB entry; some hardware supports contiguous PTE mapping, such as ARM64, which allows 16 contiguous pages to occupy only one TLB entry through CONT-PTE.
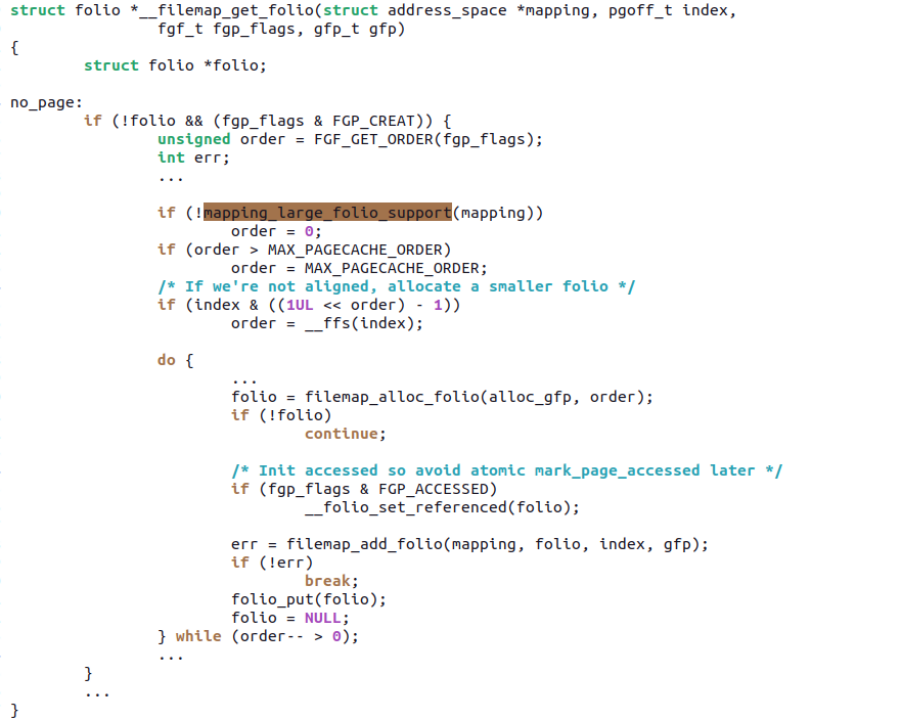
2. Reduced page fault occurrences; for example, after a page fault on a certain PTE in do_anonymous_page(), if a large folio is directly allocated and mapped as a CONT-PTE, the remaining 15 PTEs will no longer incur page faults.
3. Reduced LRU size and memory reclamation costs; recycling based on large folios incurs lower reverse mapping costs than individually processing multiple small folios; try_to_unmap_one() theoretically works the same way.
4. Potential opportunities for compression/decompression in zRAM/zsmalloc at a larger granularity, thereby reducing CPU utilization during compression/decompression and improving compression ratios. For example, compressing a 64KiB large folio as a whole has significant advantages over compressing it into 16 smaller 4KiB folios.
In the entire memory management of the Linux kernel, large folios will coexist with small folios (which only have one page). For instance, on the LRU linked list, the folios hanging on it can be either large or small; the memory in a process’s VMA can be composed of a mix of large and small folios; in the file’s pagecache, different offsets may correspond to either small or large folios.

The Linux community has developed several file systems that support large folios for file pages. These file systems inform the page cache layer through mapping_set_large_folios() that they support large folios:
-
-
-
erofs non-compressed files
-
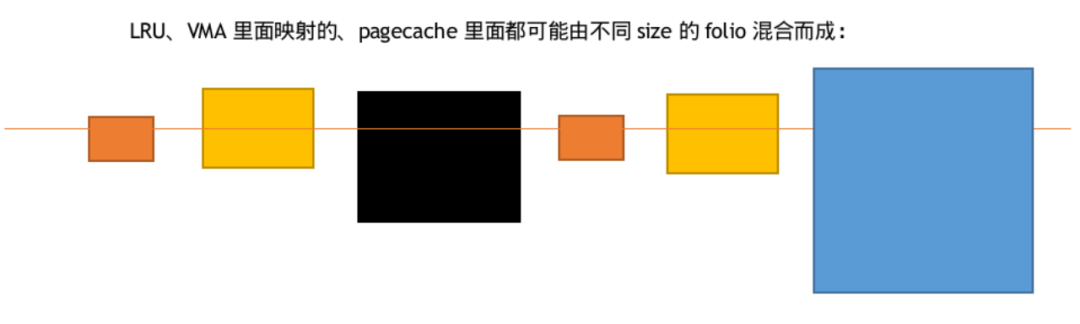
The pagecache layer will take note of this situation, and when mapping_large_folio_support() is true, it allows the allocation of large folios to fill the pagecache’s xarray:
Currently, the file systems that support file page large folios are very limited, so they cannot be used in many industries, such as erofs and f2fs, which are widely used in the mobile industry. We see that Huawei’s Zhang Yi is completing a patchset: ext4: use iomap for regular file’s buffered IO path and enable large folio[1], seeking support for ext4’s iomap and large folios. The performance data provided by Zhang Yi can, in a sense, prove the benefits of file systems supporting large folios:


Anonymous Page Large Folios
Ryan Roberts from ARM is the main initiator of this project and one of the main contributors to the relevant patchsets. Currently, there are several issues related to anonymous page patchsets; some have already been merged, some are iterating in Andrew Morton’s mm tree, and some are still under community discussion or in the budding stage.
1. Multi-size THP for Anonymous Memory by Ryan Roberts (ARM)[2]
This patchset allows the allocation of large folios of various sizes when an anonymous page experiences a page fault. The original THP in the kernel mainly targets PMD-mapped 2MiB sizes. After supporting multiple sizes, we refer to multi-size THP as mTHP. Now, there will be multiple hugepages- subdirectories under /sys/kernel/mm/transparent_hugepage:

For example, if you enable 64KiB large folios:

Then when a PF occurs, do_anonymous_page() can allocate a 64KiB mTHP and set all 16 PTEs at once through set_ptes:
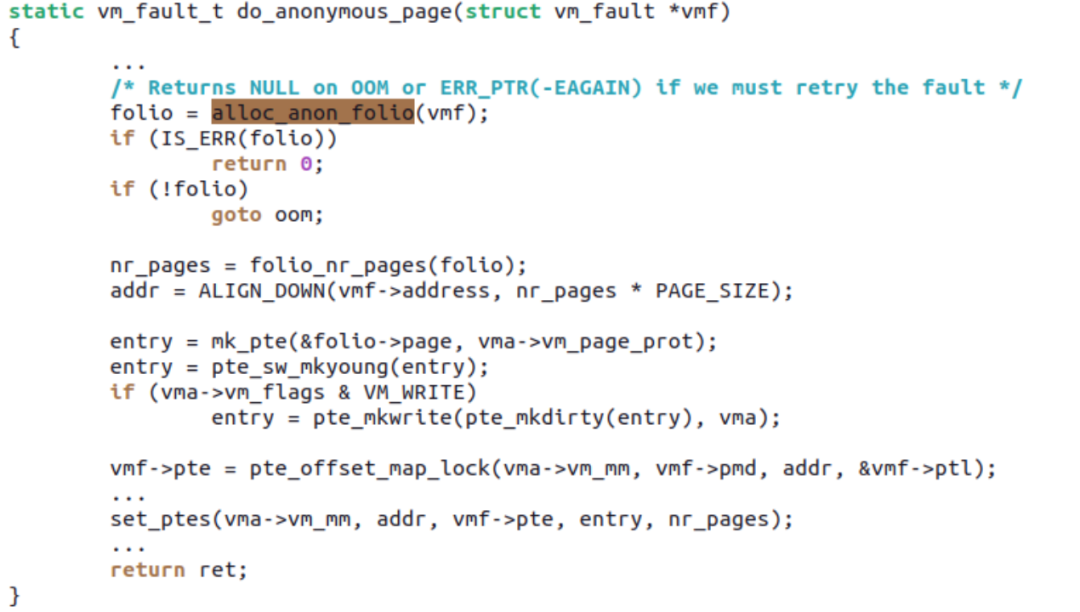
The remaining 15 PTEs will no longer incur PF. Ryan’s patchset maintains ABI compatibility between mTHP and the previous THP, such as the previous MADV_HUGEPAGE and MADV_NOHUGEPAGE still apply to mTHP.
2. Transparent Contiguous PTEs for User Mappings by Ryan Roberts (ARM)[3]
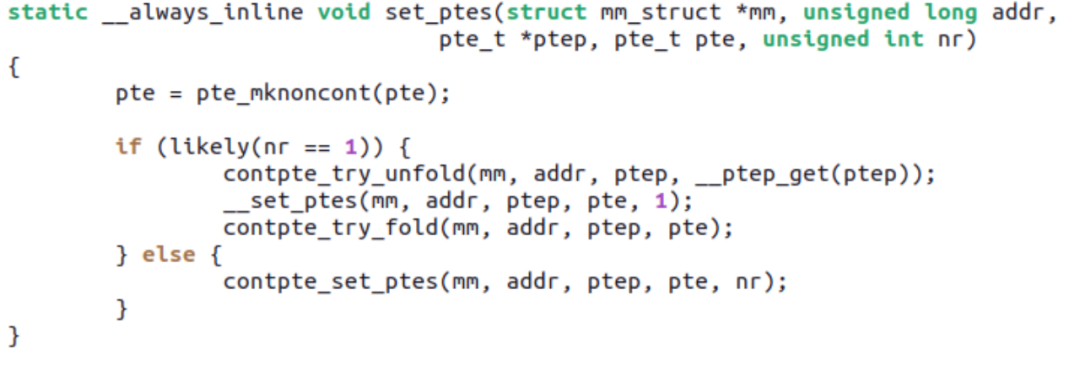
This patchset mainly allows mTHP to automatically use ARM64’s CONT-PTE, meaning that if the PFNs corresponding to 16 PTEs are physically contiguous and naturally aligned, the CONT bit is set so that they occupy only one TLB entry. The brilliance of Ryan’s patchset lies in the fact that the mm core layer does not need to be aware of the existence of CONT-PTE (because not all hardware architectures have this optimization), maintaining complete compatibility of PTE-related APIs with mm, while automatically adding or removing the CONT bit at the implementation level of ARM64 architecture.
For example, if the original 16 PTEs meet the CONT conditions, and someone unmaps one of the PTEs or mprotect changes the attributes of some of the PTEs among the 16, causing CONT to no longer be satisfied, the contpte_try_unfold() called by set_ptes() will automatically unfold the CONT bit:
The adoption of CONT-PTE effectively improves the performance of some benchmarks, such as kernel compilation:

3. Swap-out mTHP without Splitting by Ryan Roberts (ARM)[4]
This patchset modifies vmscan.c to reclaim memory without splitting mTHP into small folios (unless the large folio has already been added to _deferred_list, indicating it is likely to have been partially unmapped), but instead requests multiple swap slots as a whole and writes to the swapfile.
However, there is a problem here; when add_to_swap() requests nr_pages contiguous swap slots as a whole, the swapfile may have fragmented, making it impossible to request them, so it still needs to fall back to splitting:

I believe that the issue of swapfile fragmentation will be an important topic for the community in the future; Chris Li (Google) has some thoughts on Swap Abstraction “the pony”[5], with more discussions likely to take place at the LSF in Salt Lake City in May 2024.
4. mm: support large folios swap-in by Chuanhua Han (OPPO) and Barry Song (OPPO Consultant)[6]
This patchset aims to allow do_swap_page() to directly perform swap-in in the form of large folios, thereby reducing PFs on the do_swap_page() path. Moreover, a more important point is that if the swap-in path does not support mTHP, Ryan Roberts’ previous achievements may result in mTHP being swapped out and then swapped back in as something other than mTHP.
For scenarios like Android and embedded systems where swap-out occurs frequently, losing the advantages of mTHP overnight due to swap-out is quite unreasonable. In theory, there are three possible paths for mTHP support on the swap-in path:
-
Directly hitting a large folio in swapcache
-
Swap-in for synchronous devices on the SWP_SYNCHRONOUS_IO path
-
Swap-in on the swapin_readahead() path for asynchronous devices or when __swap_count(entry) != 1.
Currently, the patchset aims at paths a and b for mobile and embedded scenarios using zRAM, and I believe this patchset will further develop support for path c. Recently, the earliest to be merged may be part of the large folios swap-in for path a: handle refault cases first[7].
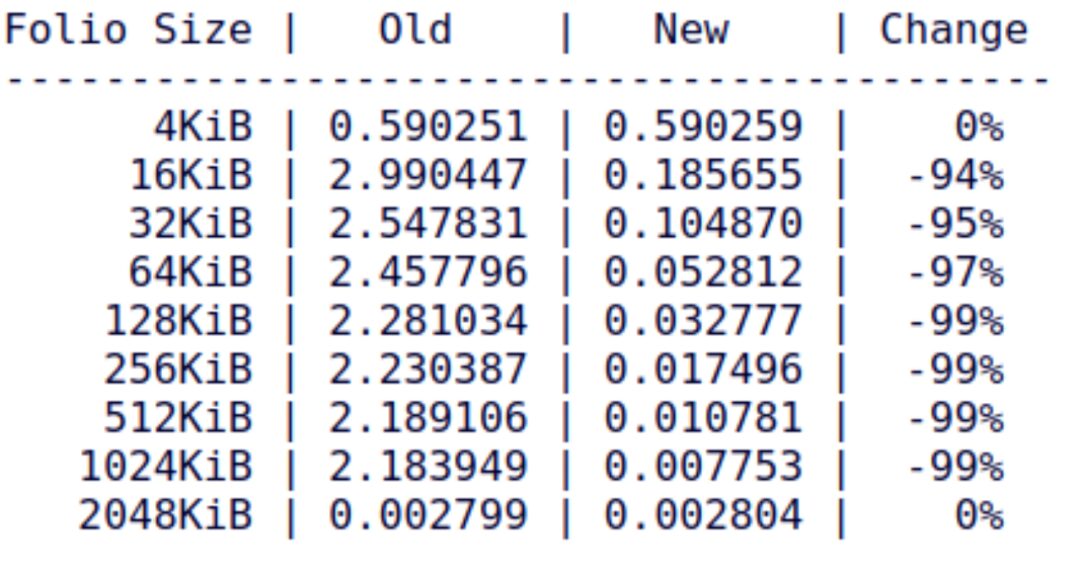
5. mTHP-friendly Compression in zsmalloc and zram based on Multi-pages by Tangquan Zheng (OPPO)[8]
This patchset’s idea is based on performing compression and decompression of anonymous pages at a larger granularity during swap-out/swap-in, which can greatly reduce CPU utilization and improve compression ratios. The cover letter of this patchset presents a set of data showing that for original data, compressing in units of 4KiB and 64KiB significantly reduces time and the size of the compressed data:

Ryan, Chuanhua, Barry, and others’ work allows for large folios to be utilized during swap-out and swap-in, providing a practical foundation for Tangquan’s work. In Tangquan’s work, if zRAM receives a 64KiB mTHP, it can be compressed directly at the 64KiB unit; if zRAM receives a 128KiB mTHP, it can be decomposed into 2 64KiB units for compression (without Tangquan’s work, 128KiB would be compressed as 32 4KiB pages).
6. TAO: THP Allocator Optimizations by Yu Zhao (Google)[9]
This patchset (also a topic at LSF/MM/eBPF) aims to solve the cost of metadata for large folios and the fragmentation issues frequently encountered during allocation. The Buddy allocator typically leads to fragmentation due to immovable memory pages after prolonged system operation with complex applications, making it unable to continue providing contiguous physical memory effectively. If large folio requests fallback to 4KB pages more than 90% of the time, the aforementioned mTHP solutions cannot be realized.
TAO (which is also the English translation of the Chinese word “道”) is designed to focus on optimizing large folios and maintaining ABI compatibility with other kernel components (such as SLAB) without breaking them. To illustrate, 4KB pages are a legacy from decades ago and do not meet the demands of modern high-performance hardware and user-space software; their existence is merely for backward compatibility. Thus, the design of memory management in operating systems should focus on optimizing large folios while managing 4KB pages adequately.
This design’s advantage lies in its convenience. Specifically, TAO can perfectly integrate with MGLRU, achieving targeted reclamation for both 4KB pages and large folios: 4KB page allocation only needs to reclaim from the 4KB page zone; large folio allocation first reclaims from the large folio zone, and if that does not satisfy allocation needs, it can reclaim from the 4KB page zone while also performing compaction. TAO also naturally extends HVO (HugeTLB Vmemmap Optimization) to THP, thereby reducing the overhead of struct page for 2MB THP (to one-eighth of the previous size).
TAO’s concluding section (see the link above) also presents an interesting new concept: thinking about THP in terms of fungibility from finance (meaning the ability to replace one item with another to settle debts). For example, if a user cannot fully utilize the value of a 2MB THP, memory management should exchange this 2MB THP for 512 non-contiguous 4KB pages. This process is termed THP shattering, which seems similar to existing THP splitting, but its essence is to “steal beams to replace columns,” aiming to preserve the original THP for users with real demand without splitting it. This concept may also apply to future 1GB THP. If THP is split, the existing collapse will require allocating a new THP and copying data. While allocation and copying may not be significant issues for 2MB THP, they become unacceptable for future 1GB THP. Thus, the only viable solution is THP recovery, which retains unallocated pages while copying data from already reallocated pages to additional 4KB pages, then reclaiming the original 1GB physical area as THP.
For 2MB THP, the following 2×2 matrix can summarize the above four combinations:

7. THP_SWAP support for ARM64 SoC with MTE by Barry Song (OPPO Consultant)[10]
This patchset addresses the issue of saving and restoring ARM64 MTE tags at the folio level during overall SWPOUT and SWPIN of large folios, allowing ARM64 hardware that supports MTE to benefit from the overall swap-out and swap-in advantages of mTHP.
8.mm: add per-order mTHP alloc and swpout counters by Barry Song (OPPO Consultant)[11]
As mTHP has developed to this point, counting and debugging functions have become a necessity; otherwise, the entire mTHP appears to users as an elusive black box. Barry’s current contribution to the patchset temporarily implements two sets of counts:
1) per-order success and failure rates of mTHP allocation, providing feedback on whether mTHP is still effectively in the system and checking whether buddy fragmentation leads to easy allocation failures for mTHP;
2) per-order mTHP SWPOUT and FALLBACK rates, providing feedback on whether swap partitions are fragmented, leading to easy allocation failures for mTHP swapout due to the need for contiguous swap slots.
The patchset adds a stats directory to each size’s sysfs files, /sys/kernel/mm/transparent_hugepage/hugepages-<size>/stats, to present counts:
anon_allocanon_alloc_fallbackanon_swpoutanon_swpout_fallback
9. Split a folio to any lower order folios by Zi Yan (Nvidia)[12]
Previously, large folios could only be split into order-0 small folios; Zi Yan’s patchset allows them to be transformed into any order. This patchset provides a debugfs interface where a PID and a virtual address range can be written, and the kernel will split the specified range of memory into the specified order of mTHP.
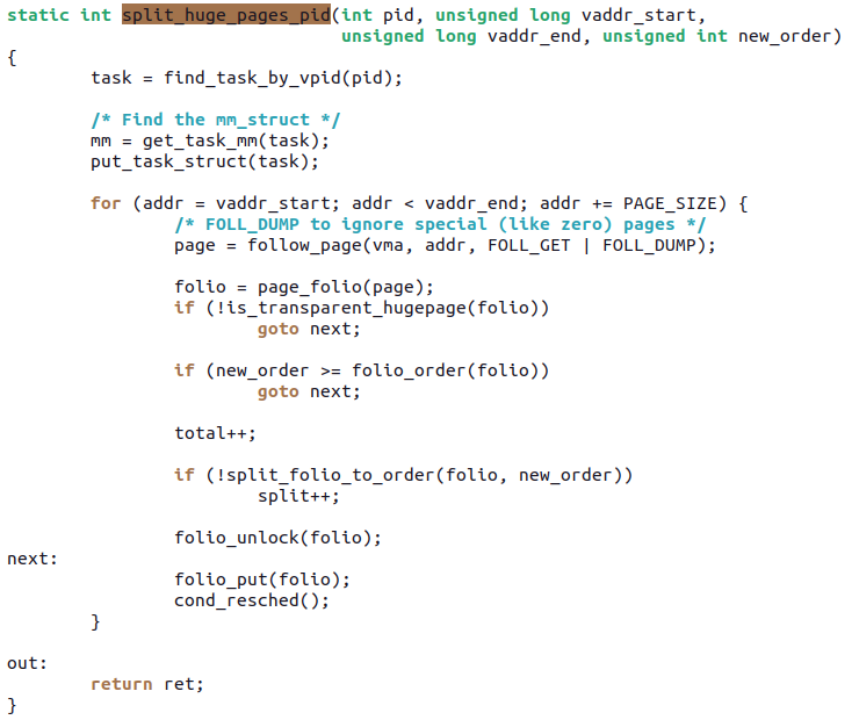
Currently, Zi Yan has demonstrated an application scenario in Pankaj Raghav (Samsung)’s enable bs > ps in XFS patchset[13], where truncating can effectively utilize this split to non-order-0 work:
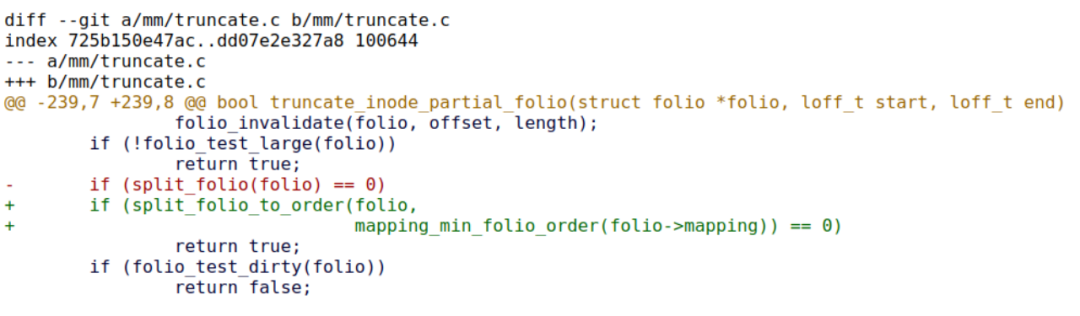
Pankaj Raghav’s work aims to provide support for block sizes > page sizes in XFS, and through Zi Yan’s work, the result remains large folios (lower order but satisfying mapping_min_folio_order requirements).
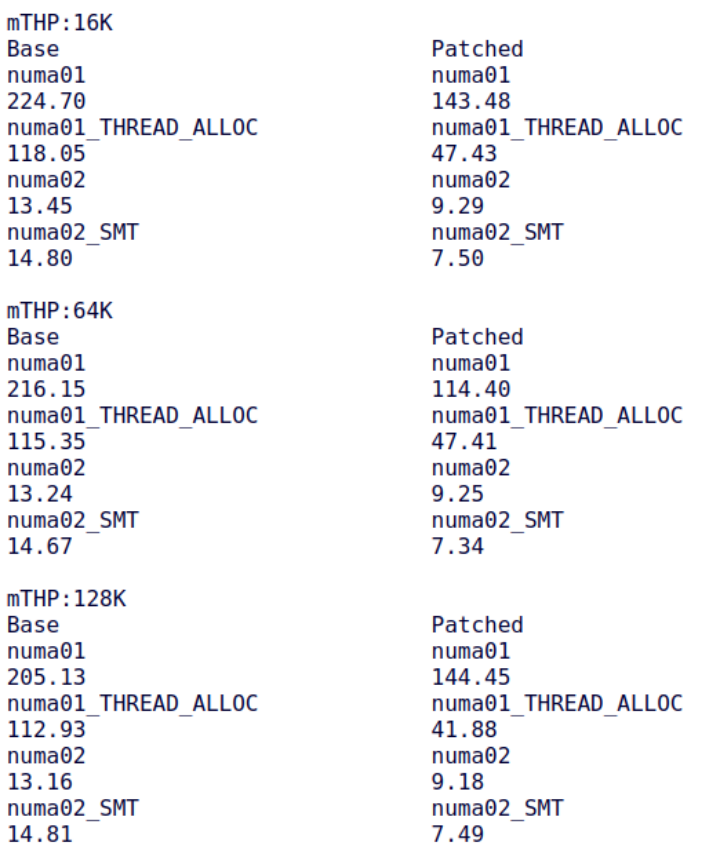
10. Support Multi-size THP NUMA Balancing by Baolin Wang (alibaba)[14]
Baolin’s patchset extends memory migration under NUMA balancing to the mTHP field, allowing mTHP to be scanned and migrated. Because mTHP’s size is larger than that of 4KiB small folios, it is theoretically more prone to false sharing, and frequent migrations can lead to memory ping-ponging across NUMA nodes. Therefore, the algorithm temporarily borrows the PMD-mapped two-stage filter mechanism. Through Baolin’s patchset, performance in autonuma-benchmark has significantly improved:
11. mm/madvise: enhance lazyfreeing with mTHP in madvise_free by kernel enthusiast Lance Yang[15]
This patchset allows mTHP’s MADV_FREE, i.e., lazyfree mechanism, to no longer require splitting folios. Previously, MADV_FREE needed to split large folios, but now it does not, thus dramatically improving the speed of MADV_FREE calls for large folios (the author also believes this will ultimately speed up the reclamation of lazyfree folios in the LRU linked list):

Real Products of Large Folios
As of the moment this article was completed, there are still few mature commercial cases of mTHP in the community. However, OPPO’s mobile phones have implemented dynamic large pages in the kernel versions 4.19, 5.10, 5.15, and 6.1 before the community mTHP project matured, and have deployed them in a large number of mobile phones in 2023.
At the 2023 China Linux Kernel Developers Conference, Chuanhua Han (OPPO) presented the software architecture and benefits of OPPO’s dynamic large page project.
Compared to the various mTHP size supports in community projects, the dynamic large pages deployed in OPPO mobile phones mainly target the 64KiB size that can utilize CONT-PTE. The following diagram illustrates a typical workflow for handling do_anonymous_page() PF.
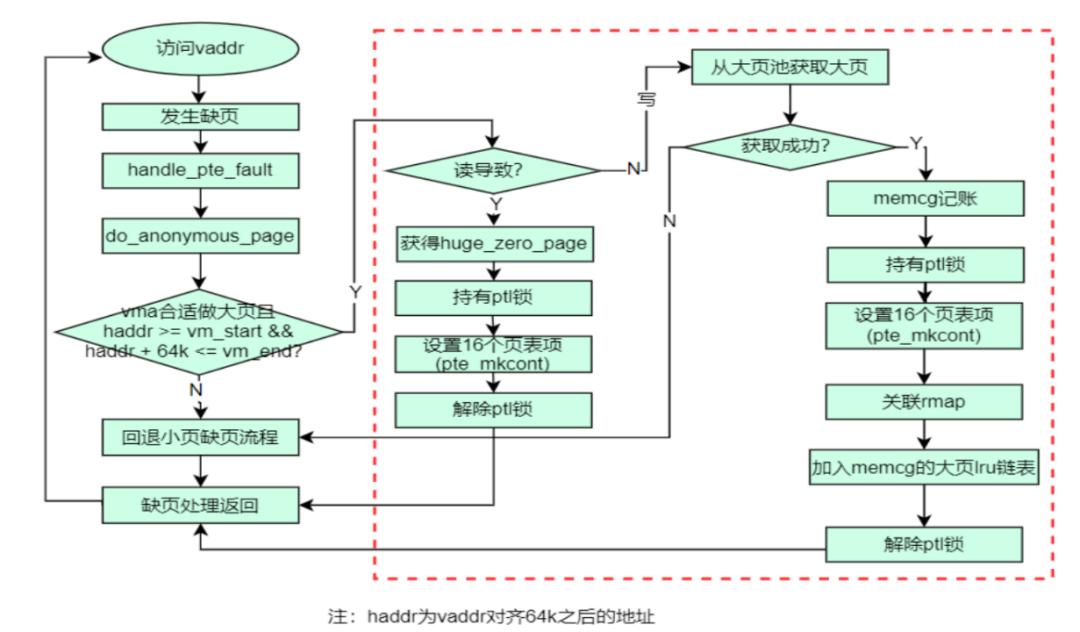
Chuanhua presented the software architecture diagram for OPPO’s dynamic large pages at CLK2023:
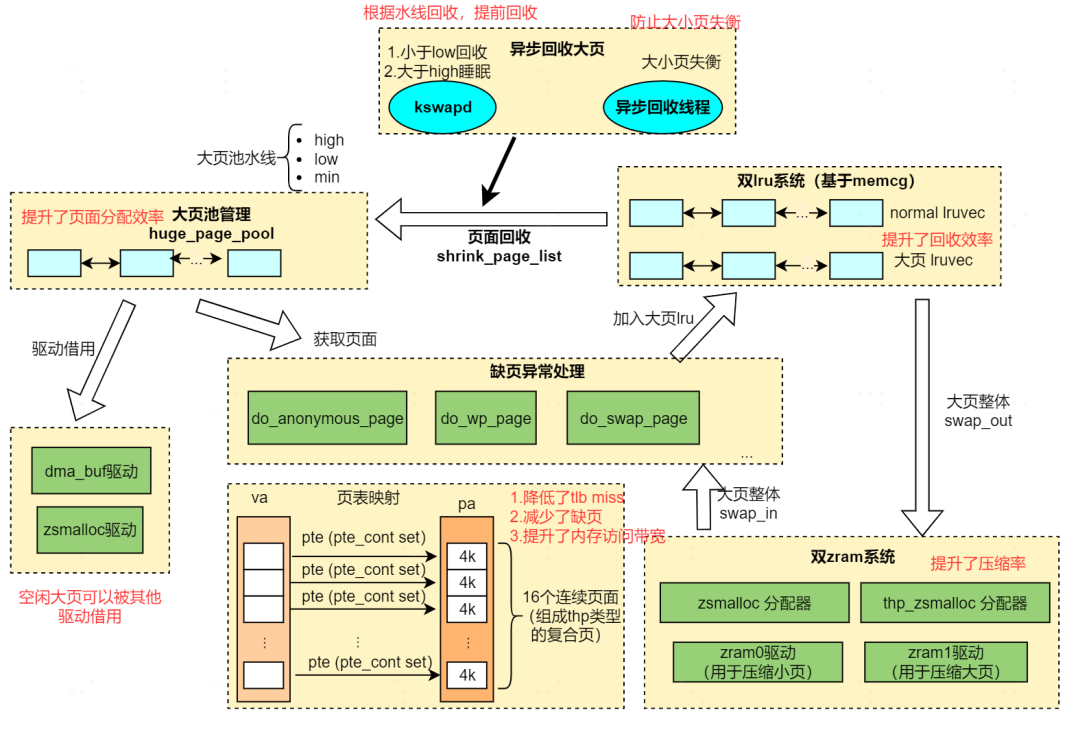
This architecture diagram highlights several outstanding features:
1. Comprehensive modifications to do_anonymous_page, do_wp_page, do_swap_page, and swapout, meaning this solution supports large folio allocation during PF, CoW at the large folio level, and swapout/swapin at the large folio level;
2. Large Page Pool: Pooling technology is used to address the overhead of large folio allocation and provide a high success rate for large folio allocation;
3. Dual LRU: Large folios and small folios are located in different LRUs, rather than being mixed together. This way, the reclamation efficiency of both large and small folios is relatively high, and they do not hinder each other (for example, if you urgently need large folios, but the tail of the LRU has 100 small folios, reclaiming those 100 still does not yield large folios);
4. zsmalloc and zRAM support both large folios and small folios simultaneously, enjoying the high compression ratio and low CPU utilization of large folios.
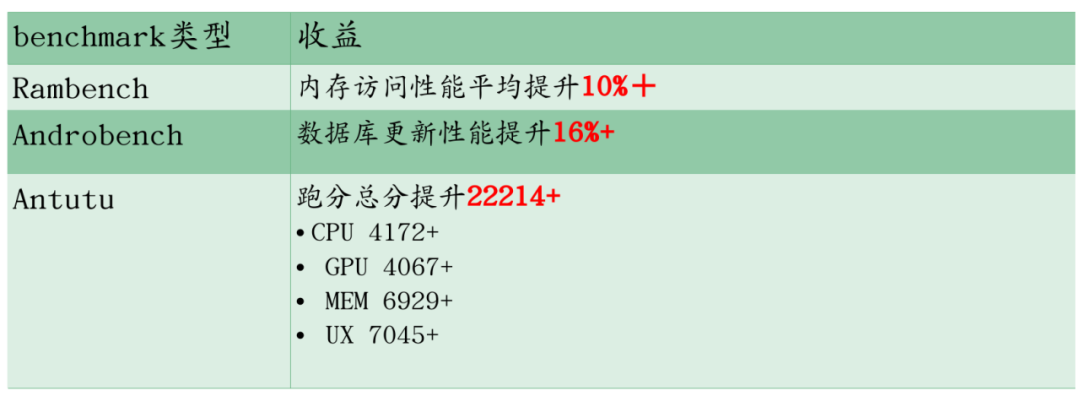
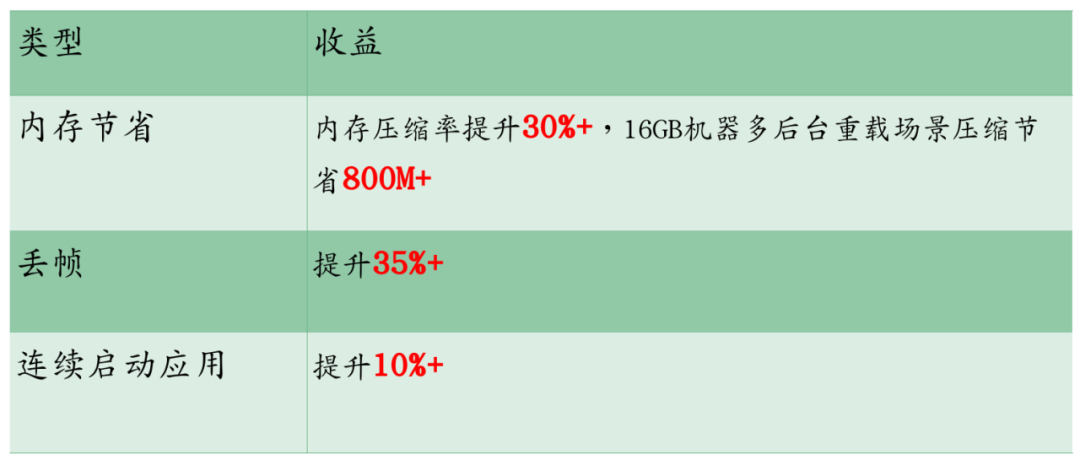
The presentation also presented the benefit data of OPPO mobile phones adopting dynamic large pages:

The Future of Large Folios
Several predictions about the future:
1. More file systems will support large folios mapping.
2. A practical mechanism similar to TAO is needed to ensure the high efficiency of large folios allocation.
3. Large folios swap-in needs to be supported by the mainline.
4. Large folios will bring more parallel processing capabilities, such as combining hardware compression and decompression offload functions, where one large folio can be offloaded for fast multi-threaded compression and decompression.
5. In the future, zswap may also need to provide large folios support; currently, zswap does not support mTHP.
6. Swap defragmentation or storing swapped-out mTHP in non-contiguous swap slots needs to be addressed. Currently, the overall swapout of mTHP requires nr_pages of contiguous and naturally aligned swap slots.
7. Balancing the performance improvements brought by mTHP and the potential increase in memory fragmentation waste. Since mTHP’s granularity is larger than that of small folios, it may potentially allocate memory that does not need to be accessed. However, Tangquan’s zRAM/zsmalloc work also shows us another possibility: large folios are not always a source of waste; they may also become a source of memory savings, aligning with the principle of mutual generation and restraint.
8. Properly handling the potential waste and performance loss caused by partially unmapping a large folio in user space. Since user space typically only understands the base page size, it may not know that the underlying structure is a large folio, potentially leading to unmapping, mprotect, madvise, etc., in a non-aligned manner. For example, if a user space unmaps 0~60KiB of a 64KiB large folio, the remaining 4KiB may still occupy the entire 64KiB large folio for a long time.
Barry Song: A long-time frontline Linux kernel developer, OPPO consultant, and author of projects like per-numa CMA, SCHED_CLUSTER, and ARM64 BATCHED_UNMAP_TLB_FLUSH;
Yu Zhao: A renowned developer in the Linux kernel community, Google Staff Software Engineer, and author of projects like Multi-Gen LRU and POSIX_FADV_NOREUSE.
[1] https://lwn.net/Articles/956575/
[5] https://lore.kernel.org/linux-mm/CAF8kJuMQ7qBZqdHHS52jRyA-ETTfHnPv+V9ChaBsJ_q_G801Lw@mail.gmail.com/
[16] https://github.com/ChinaLinuxKernel/CLK2023/blob/main/%E5%88%86%E8%AE%BA%E5%9D%9B1%EF%BC%88%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86%EF%BC%89/8%20%20%E5%8A%A8%E6%80%81%E5%A4%A7%E9%A1%B5%EF%BC%9A%E5%9F%BA%E4%BA%8EARM64%20contiguous%20PTE%E7%9A%8464KB%20HugePageLarge%20Folios%E2%80%94%E2%80%94%E9%9F%A9%E4%BC%A0%E5%8D%8E.pptx
▶“Sora cannot bring AGI, GPT is the key,” an interview with Pan Xin, co-founder of Zero One Wanwu | AGI Technology 50 People
▶“After two weeks off the internet, the former OpenAI genius returns to create again, 1000 lines of C code to complete GPT-2 training, netizens: C language revival!”
▶Apple exposes “insider” bombshell: seeks 180,000 yuan in compensation for leaking at least six secrets over five years, sending over 10,000 messages!
From April 25 to 26, the “Global Machine Learning Technology Conference” co-hosted by CSDN and the high-end IT consulting and education platform Boolan will be held at the Hyatt Hotel in Shanghai. Nearly 50 technical leaders and industry application experts are invited, along with over 1000 elite attendees from various industries such as e-commerce, finance, automotive, smart manufacturing, telecommunications, industrial internet, medical, and education, to discuss cutting-edge developments and industry best practices in the field of artificial intelligence.All developer friends are welcome to visit the official website http://ml-summit.org, click “Read the original text” or scan the QR code for more details.
