Due to the modern operating system’s architecture of multiprocessor computing, it is inevitable to encounter situations where multiple processes and threads access shared data, as shown in the figure below:
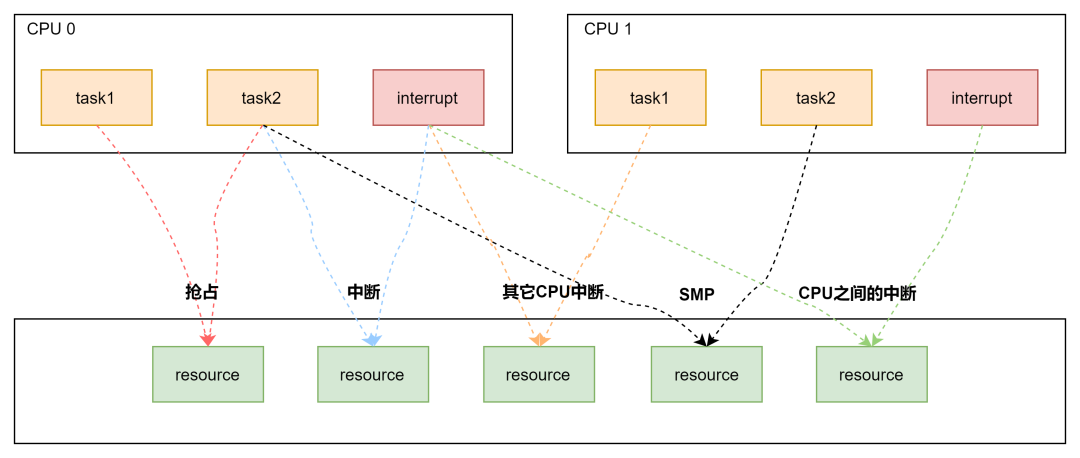
Each color in the figure represents a type of race condition, which can be categorized into three main types:
-
Between processes: preemption on a single core, SMP on multiple cores; -
Between processes and interrupts: interrupts include both upper and lower halves, and interrupts can always interrupt the execution flow of processes; -
Between interrupts: peripheral interrupts can be routed to different CPUs, which may also cause race conditions;
At this point, a synchronization mechanism is needed to protect the memory data accessed concurrently. This series of articles is divided into two parts, with this chapter primarily discussing atomic operations, spin locks, semaphores, and mutexes.
Atomic Operations
Atomic operations are operations that cannot be interrupted before completion and are the smallest unit of execution. For example, on the ARM platform, the APIs for atomic operations include the following:
| API | Description |
|---|---|
| int atomic_read(atomic_t *v) | Read operation |
| void atomic_set(atomic_t *v, int i) | Set variable |
| void atomic_add(int i, atomic_t *v) | Add i |
| void atomic_sub(int i, atomic_t *v) | Subtract i |
| void atomic_inc(atomic_t *v) | Add 1 |
| void atomic_dec(atomic_t *v) | Subtract 1 |
| void atomic_inc_and_test(atomic_t *v) | Add 1 and check if it is 0 |
| void atomic_dec_and_test(atomic_t *v) | Subtract 1 and check if it is 0 |
| void atomic_add_negative(int i, atomic_t *v) | Add i and check if it is negative |
| void atomic_add_return(int i, atomic_t *v) | Add i and return result |
| void atomic_sub_return(int i, atomic_t *v) | Subtract i and return result |
| void atomic_inc_return(int i, atomic_t *v) | Add 1 and return |
| void atomic_dec_return(int i, atomic_t *v) | Subtract 1 and return |
Atomic operations are usually inline functions and are often implemented using inline assembly instructions. If a function itself is atomic, it is often defined as a macro, as shown in the example below.
#define ATOMIC_OP(op, c_op, asm_op)
static inline void atomic_##op(int i, atomic_t *v)
{
unsigned long tmp;
int result;
prefetchw(&v->counter);
__asm__ __volatile__("@ atomic_" #op "\n"
"1: ldrex %0, [%3]\n"
" " #asm_op " %0, %0, %4\n"
" strex %1, %0, [%3]\n"
" teq %1, #0\n"
" bne 1b"
: "=&r" (result), "=&r" (tmp), "+Qo" (v->counter)
: "r" (&v->counter), "Ir" (i)
: "cc");
}
It can be seen that the atomicity of atomic operations relies on ldrex and strex implementations, where ldrex reads data while marking it as exclusive, preventing other kernel paths from accessing it until the call to strex completes the write and clears the mark.
The ldrex and strex instructions break down the simple memory update atomic operation into two independent steps:
-
ldrex is used to read the value in memory and mark exclusive access to that segment of memory:
ldrex Rx, [Ry]
This reads the 4-byte memory value pointed to by register Ry, saves it to register Rx, and marks exclusive access to the memory area pointed to by Ry. If the ldrex instruction finds that it has already been marked for exclusive access when executed, it does not affect the execution of the instruction.
-
strex checks if the memory value is already marked for exclusive access when updating the memory value and decides whether to update the value in memory:
strex Rx, Ry, [Rz]
If this instruction finds that it has already been marked for exclusive access when executed, it updates the value in register Ry to the memory pointed to by register Rz and sets register Rx to 0. After successful execution, it clears the exclusive access mark. If this instruction finds that the exclusive mark is not set, it does not update the memory and sets the value in register Rx to 1.
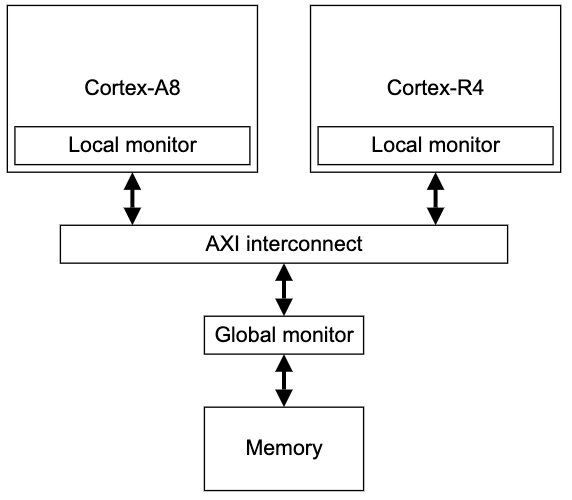
The internal implementation of ARM is shown below, which will not be elaborated on here.
Spin Lock
The most common lock in the Linux kernel is the spin lock, which can only be held by one executable thread at a time. If a thread tries to acquire a spin lock that is already held, it will enter a busy loop—spinning and waiting (which wastes processor time) until the lock becomes available again. A spin lock cannot be preempted while held.
Another way to handle lock contention is to let the waiting thread sleep until the lock becomes available again, so the processor does not have to spin and can execute other code, but this incurs the overhead of two noticeable context switches; semaphores provide this locking mechanism.
The interface for using spin locks is as follows:
| API | Description |
|---|---|
| spin_lock() | Acquire the specified spin lock |
| spin_lock_irq() | Disable local interrupts and acquire the specified lock |
| spin_lock_irqsave() | Save the current state of local interrupts, disable local interrupts, and acquire the specified lock |
| spin_unlock() | Release the specified lock |
| spin_unlock_irq() | Release the specified lock and enable local interrupts |
| spin_unlock_irqrestore() | Release the specified lock and restore the previous state of local interrupts |
| spin_lock_init() | Dynamically initialize the specified lock |
| spin_trylock() | Attempt to acquire the specified lock, returning 0 on success, otherwise returning non-zero |
| spin_is_locked() | Test if the specified lock is occupied; returns non-zero if occupied, otherwise returns 0 |
Taking spin_lock as an example, here is how it is used:
DEFINE_SPINLOCK(mr_lock);
spin_lock(&mr_lock);
/* Critical section */
spin_unlock(&mr_lock);
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned int tmp;
arch_spinlock_t lockval, newval;
asm volatile(
/* Atomically increment the next ticket. */
ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
" prfm pstl1strm, %3\n"
"1: ldaxr %w0, %3\n"
" add %w1, %w0, %w5\n"
" stxr %w2, %w1, %3\n"
" cbnz %w2, 1b\n",
/* LSE atomics */
" mov %w2, %w5\n"
" ldadda %w2, %w0, %3\n"
__nops(3)
)
/* Did we get the lock? */
" eor %w1, %w0, %w0, ror #16\n"
" cbz %w1, 3f\n"
/*
* No: spin on the owner. Send a local event to avoid missing an
* unlock before the exclusive load.
*/
" sevl\n"
"2: wfe\n"
" ldaxrh %w2, %4\n"
" eor %w1, %w2, %w0, lsr #16\n"
" cbnz %w1, 2b\n"
/* We got the lock. Critical section starts here. */
"3:"
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp), "+Q" (*lock)
: "Q" (lock->owner), "I" (1 << TICKET_SHIFT)
: "memory");
}
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{
unsigned long tmp;
asm volatile(ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
" ldrh %w1, %0\n"
" add %w1, %w1, #1\n"
" stlrh %w1, %0",
/* LSE atomics */
" mov %w1, #1\n"
" staddlh %w1, %0\n"
__nops(1))
: "=Q" (lock->owner), "=&r" (tmp)
:
: "memory");
}
The core logic in the above code lies within the asm volatile() inline assembly, which contains many exclusive operation instructions. Only based on exclusive operation instructions can software-level mutual exclusion be guaranteed. Translating the core logic into C language:
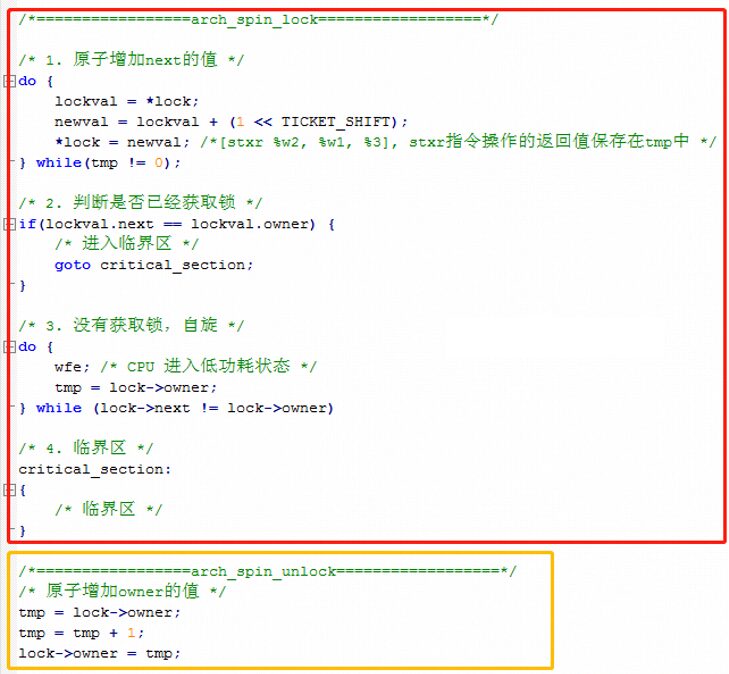
It can be seen that for each spin_lock in Linux, there are two counts: next and owner (initially 0). When process A requests the lock, it checks whether the values of next and owner are equal. If they are equal, it means the lock can be successfully requested; otherwise, it spins in place. It will exit the spin only when the values of owner and next are equal.
Semaphore
A semaphore is a measure used in a multithreaded environment that coordinates various processes to ensure that they can use shared resources correctly and reasonably. Its biggest difference from a spin lock is that a process that cannot acquire a semaphore can sleep, which leads to system scheduling.
The definition of a semaphore is as follows:
struct semaphore {
raw_spinlock_t lock; // Synchronization using spin lock
unsigned int count; // Resource counting
struct list_head wait_list; // Waiting queue
};
A semaphore is initialized with an initial value count when created, which indicates the current number of available resources. A task must obtain the semaphore before accessing the shared resource, and the operation to acquire the semaphore is count – 1. If the current count is negative, it indicates that the semaphore cannot be obtained, and the task must suspend in the waiting queue for that semaphore; if the current count is non-negative, it indicates that the semaphore can be obtained, and thus the task can immediately access the shared resource protected by that semaphore.
After the task has accessed the shared resource protected by the semaphore, it must release the semaphore, which is done by performing count + 1. If the count after adding one is non-positive, it indicates that there are tasks waiting, so all tasks waiting for that semaphore will be awakened.
Having understood the structure and definition of semaphores, let’s look at the commonly used semaphore interfaces:
| API | Description |
|---|---|
| DEFINE_SEMAPHORE(name) | Declare a semaphore and initialize it to 1 |
| void sema_init(struct semaphore *sem, int val) | Declare a semaphore and initialize it to val |
| down | Acquire the semaphore; the task cannot be interrupted unless it is a fatal signal |
| down_interruptible | Acquire the semaphore; the task can be interrupted |
| down_trylock | Attempt to acquire the semaphore; if successful, count –, otherwise return immediately without joining the waitlist |
| down_killable | Acquire the semaphore; the task can be killed |
| up | Release the semaphore |
Here we will look at the two core implementations down and up.
-
down
down is used for the caller to acquire the semaphore; if count is greater than 0, it indicates that resources are available, and it can be decremented.
void down(struct semaphore *sem)
{
unsigned long flags;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;
else
__down(sem);
raw_spin_unlock_irqrestore(&sem->lock, flags);
}
EXPORT_SYMBOL(down);
If count < 0, the function __down() is called, which adds the task to the waiting queue and enters the scheduling loop waiting until it is awakened by __up or removed from the waiting queue due to timeout.
static inline int __sched __down_common(struct semaphore *sem, long state,
long timeout)
{
struct semaphore_waiter waiter;
list_add_tail(&sem->wait_list);
waiter.task = current;
waiter.up = false;
for (;;) {
if (signal_pending_state(state, current))
goto interrupted;
if (unlikely(timeout <= 0))
goto timed_out;
__set_current_state(state);
raw_spin_unlock_irq(&sem->lock);
timeout = schedule_timeout(timeout);
raw_spin_lock_irq(&sem->lock);
if (waiter.up)
return 0;
}
timed_out:
list_del(&waiter.list);
return -ETIME;
interrupted:
list_del(&waiter.list);
return -EINTR;
}
-
up
up is used for the caller to release the semaphore; if the waitlist is empty, it indicates that there are no waiting tasks, and count + 1, making the semaphore available.
void up(struct semaphore *sem)
{
unsigned long flags;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(list_empty(&sem->wait_list)))
sem->count++;
else
__up(sem);
raw_spin_unlock_irqrestore(&sem->lock, flags);
}
EXPORT_SYMBOL(up);
If the waitlist is not empty, the task is removed from the waiting queue and woken up, corresponding to the conditions of __down.
static noinline void __sched __up(struct semaphore *sem)
{
struct semaphore_waiter *waiter = list_first_entry(&sem->wait_list,
struct semaphore_waiter, list);
list_del(&waiter->list);
waiter->up = true;
wake_up_process(waiter->task);
}
Mutex
In the Linux kernel, there is also a synchronization mechanism similar to semaphores called mutex. A mutex is similar to a semaphore with a count of 1. Therefore, semaphores are mechanisms for protecting access to a shared resource among multiple processes/threads, while mutexes are for protecting access to a shared resource by a single process/thread.
Mutexes have a special feature: only the holder can unlock it. As shown in the figure below:
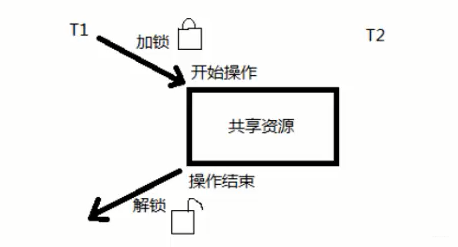
In summary, the difference between semaphores and mutexes is that semaphores are used for thread synchronization, while mutexes are used for thread mutual exclusion.
The structure definition of a mutex is as follows:
struct mutex {
atomic_long_t owner; // Owner of the mutex
spinlock_t wait_lock; // Synchronization using spin lock
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
struct optimistic_spin_queue osq; /* Spinner MCS lock */
#endif
struct list_head wait_list; // Waiting queue
......
};
Its commonly used interfaces are as follows:
| API | Description |
|---|---|
| DEFINE_MUTEX(name) | Statically declare a mutex and initialize it to unlocked state |
| mutex_init(mutex) | Dynamically declare a mutex and initialize it to unlocked state |
| void mutex_destroy(struct mutex *lock) | Destroy the mutex |
| bool mutex_is_locked(struct mutex *lock) | Check if the mutex is locked |
| mutex_lock | Acquire the lock; the task cannot be interrupted |
| mutex_unlock | Unlock |
| mutex_trylock | Attempt to acquire the lock; if it cannot be locked, return immediately |
| mutex_lock_interruptible | Acquire the lock; the task can be interrupted |
| mutex_lock_killable | Acquire the lock; the task can be interrupted |
| mutex_lock_io | Acquire the lock; when the task waits for the lock, it will be marked as in IO wait state by the scheduler |
The implementations of spin locks, semaphores, and mutexes mentioned above all use atomic operation instructions. Since atomic operations will lock, when threads contend to enter the critical section across multiple CPUs, they will all operate on the lock data shared between multiple CPUs. When CPU 0 operates on the lock, to maintain data consistency, the operation of CPU 0 will invalidate the lock in the L1 cache of other CPUs, causing subsequent accesses to the lock from other CPUs to result in L1 cache misses (more accurately, communication cache misses), requiring retrieval from the next level of cache.
This can severely degrade cache consistency and lead to performance degradation. Therefore, the kernel provides a new synchronization method: RCU (Read-Copy-Update).
What RCU Solves
RCU is a high-performance version of read-write locks. Its core idea is that while readers access, writers can update copies of the accessed objects, but writers must wait for all readers to complete access before deleting the old objects. Readers have no synchronization overhead, while the synchronization overhead for writers depends on the inter-writer synchronization mechanism used.
RCU is suitable for scenarios where frequent reads occur, but modifications to the data are relatively few, such as in file systems, where directory lookups are frequent while modifications to the directory are relatively infrequent. This is the optimal scenario for RCU to function.
RCU Examples
The commonly used interfaces for RCU are shown in the figure below:
| API | Description |
|---|---|
| rcu_read_lock | Mark the reader as entering the read-side critical section |
| rcu_read_unlock | Mark the reader as exiting the critical section |
| synchronize_rcu | Synchronize RCU, meaning that all readers have completed the read-side critical section, and the writer can proceed with the next operation. This function blocks the writer and can only be used in process context |
| call_rcu | Register the callback function func to the RCU callback function chain and then return immediately |
| rcu_assign_pointer | Used for RCU pointer assignment |
| rcu_dereference | Used for RCU pointer dereferencing |
| list_add_rcu | Register a linked list structure to RCU |
| list_del_rcu | Remove a linked list structure from RCU |
To better understand, let’s look at an example before analyzing RCU:
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
#include <linux/slab.h>
#include <linux/spinlock.h>
#include <linux/rcupdate.h>
#include <linux/kthread.h>
#include <linux/delay.h>
struct foo {
int a;
struct rcu_head rcu;
};
static struct foo *g_ptr;
static int myrcu_reader_thread1(void *data) // Reader thread 1
{
struct foo *p1 = NULL;
while (1) {
if(kthread_should_stop())
break;
msleep(20);
rcu_read_lock();
mdelay(200);
p1 = rcu_dereference(g_ptr);
if (p1)
printk("%s: read a=%d\n", __func__, p1->a);
rcu_read_unlock();
}
return 0;
}
static int myrcu_reader_thread2(void *data) // Reader thread 2
{
struct foo *p2 = NULL;
while (1) {
if(kthread_should_stop())
break;
msleep(30);
rcu_read_lock();
mdelay(100);
p2 = rcu_dereference(g_ptr);
if (p2)
printk("%s: read a=%d\n", __func__, p2->a);
rcu_read_unlock();
}
return 0;
}
static void myrcu_del(struct rcu_head *rh) // Reclaim handling operation
{
struct foo *p = container_of(rh, struct foo, rcu);
printk("%s: a=%d\n", __func__, p->a);
kfree(p);
}
static int myrcu_writer_thread(void *p) // Writer thread
{
struct foo *old;
struct foo *new_ptr;
int value = (unsigned long)p;
while (1) {
if(kthread_should_stop())
break;
msleep(250);
new_ptr = kmalloc(sizeof (struct foo), GFP_KERNEL);
old = g_ptr;
*new_ptr = *old;
new_ptr->a = value;
rcu_assign_pointer(g_ptr, new_ptr);
call_rcu(&old->rcu, myrcu_del);
printk("%s: write to new %d\n", __func__, value);
value++;
}
return 0;
}
static struct task_struct *reader_thread1;
static struct task_struct *reader_thread2;
static struct task_struct *writer_thread;
static int __init my_test_init(void)
{
int value = 5;
printk("figo: my module init\n");
g_ptr = kzalloc(sizeof (struct foo), GFP_KERNEL);
reader_thread1 = kthread_run(myrcu_reader_thread1, NULL, "rcu_reader1");
reader_thread2 = kthread_run(myrcu_reader_thread2, NULL, "rcu_reader2");
writer_thread = kthread_run(myrcu_writer_thread, (void *)(unsigned long)value, "rcu_writer");
return 0;
}
static void __exit my_test_exit(void)
{
printk("goodbye\n");
kthread_stop(reader_thread1);
kthread_stop(reader_thread2);
kthread_stop(writer_thread);
if (g_ptr)
kfree(g_ptr);
}
MODULE_LICENSE("GPL");
module_init(my_test_init);
module_exit(my_test_exit);
The execution results are:
myrcu_reader_thread2: read a=0myrcu_reader_thread1: read a=0myrcu_reader_thread2: read a=0myrcu_writer_thread: write to new 5myrcu_reader_thread2: read a=5myrcu_reader_thread1: read a=5myrcu_del: a=0
RCU Principle
The following diagram summarizes the situation: when the writer thread myrcu_writer_thread finishes writing, it will update the two reader threads myrcu_reader_thread1 and myrcu_reader_thread2. The reader threads act as subscribers; once the writer thread has an update to the critical section, the writer thread acts like a publisher notifying the subscribers, as shown in the diagram below.
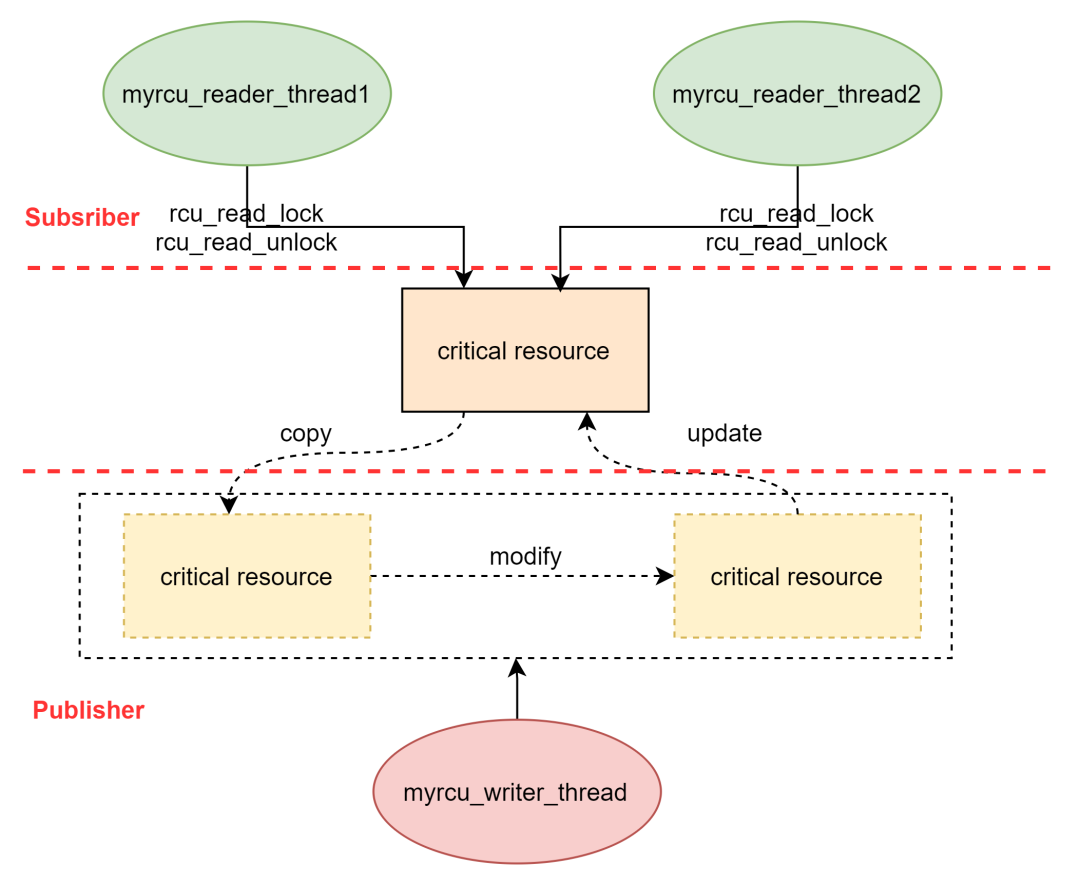
When the writer modifies the copy after updating, it first removes the old critical resource data (Removal); then it recycles the old data (Reclamation). The corresponding API implementation is that first, use rcu_assign_pointer to remove the old pointer reference and point it to the updated critical resource; then use synchronize_rcu or call_rcu to start the Reclaimer to recycle the old critical resource (where synchronize_rcu indicates synchronous waiting for recycling, and call_rcu indicates asynchronous recycling).
To ensure that no readers are accessing the critical resource to be recycled, the Reclaimer must wait for all readers to exit the critical section; this waiting time is called the grace period.
Grace Period
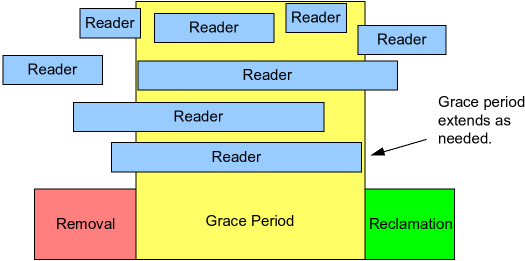
The yellow part in the middle represents the Grace Period, which refers to the time from Removal to Reclamation. The grace period indicates that only after the grace period ends can the recycling work be triggered. The end of the grace period represents that all readers have exited the critical section, thus making the recycling work a safe operation.
The end of the grace period is related to the detection of the CPU’s execution state, which is the detection of the Quiescent Status.
Quiescent Status
Quiescent Status is used to describe the CPU’s execution state. When a CPU is accessing the RCU-protected critical section, it is considered active; when it leaves the critical section, it is considered quiescent. Once all CPUs have at least experienced one Quiescent Status, the grace period will end, triggering the recycling work.
This is because rcu_read_lock and rcu_read_unlock respectively disable and enable preemption, as shown below:
static inline void __rcu_read_lock(void)
{
preempt_disable();
}
static inline void __rcu_read_unlock(void)
{
preempt_enable();
}
Thus, preemption indicates that it is not between rcu_read_lock and rcu_read_unlock, meaning that access has been completed or has not yet started.
Summary of Linux Synchronization Methods
| Mechanism | Waiting Mechanism | Advantages and Disadvantages | Scenario |
|---|---|---|---|
| Atomic Operations | None; ldrex and strex implement exclusive access to memory | Performance is quite high; limited scenarios | Resource counting |
| Spin Lock | Busy waiting; uniquely held | Excellent performance under multiprocessor conditions; long critical section times waste resources | Interrupt context |
| Semaphore | Sleeps waiting (blocking); multiple held | Relatively flexible, suitable for complex situations; longer time-consuming | Complex situations that are time-consuming; for example, interaction between kernel and user space |
| Mutex | Sleeps waiting (blocking); prefers spin waiting; uniquely held | More efficient than semaphores under suitable conditions; has several limitations | Under satisfying conditions, mutexes are preferred over semaphores |
| RCU | Extremely efficient in scenarios where reads are far more frequent than writes; however, delayed memory release can cause memory overhead, and writer blocking can be severe | In cases of more reads than writes and insensitivity to memory consumption, RCU is preferred over read-write locks; it also performs well for dynamically allocated data structures with reference counting. |

5T technology resources are being offered! Including but not limited to: C/C++, Arm, Linux, Android, artificial intelligence, microcontrollers, Raspberry Pi, etc. Reply “peter” in the above 【Everyone is a Geek】 public account to get it for free!!
 Don’t forget to clickshare,likeandlook, give me some energy!
Don’t forget to clickshare,likeandlook, give me some energy!