Introduction
I have been researching IO for a long time and have been unable to connect bio and block device drivers. I only knew that bio is passed to the block device driver through the IO scheduling algorithm, but I never fully understood how this happens or where the IO scheduling algorithm plays its role. After reviewing many materials, I finally gained an understanding of block device drivers and connected bio to the block device.
1. Traditional Block Devices
Let’s first implement a traditional block device driver based on memory.
1.1 Initializing Some Things
// Temporarily use COMPAQ_SMART2_MAJOR as the major device number to prevent device number conflicts
#define SIMP_BLKDEV_DEVICEMAJOR COMPAQ_SMART2_MAJOR
// Block device name
#define SIMP_BLKDEV_DISKNAME "simp_blkdev"
// Use an array to simulate a physical storage
#define SIMP_BLKDEV_BYTES (16*1024*1024)
unsigned char simp_blkdev_data[SIMP_BLKDEV_BYTES];
static struct request_queue *simp_blkdev_queue;// Request queue
static struct gendisk *simp_blkdev_disk;// Block device
struct block_device_operations simp_blkdev_fops = {// Block device operation functions
.owner = THIS_MODULE,
};
1.2 Loading the Driver
The whole process: 1. Create request_queue (one queue for each block device), bind function simp_blkdev_do_request 2. Create a gendisk (each block device is a gendisk) 3. Bind request_queue and gendisk 4. Register gendisk
static int __init simp_blkdev_init(void)
{
int ret;
// Initialize request queue
simp_blkdev_queue = blk_init_queue(simp_blkdev_do_request, NULL);// This method will be analyzed in detail in 1.5
simp_blkdev_disk = alloc_disk(1);// Allocate simp_blkdev_disk
// Initialize simp_blkdev_disk
strcpy(simp_blkdev_disk->disk_name, SIMP_BLKDEV_DISKNAME);// Device name
simp_blkdev_disk->major = SIMP_BLKDEV_DEVICEMAJOR;// Major device number
simp_blkdev_disk->first_minor = 0;// Minor device number
simp_blkdev_disk->fops = &simp_blkdev_fops;// Block device operation function pointer
simp_blkdev_disk->queue = simp_blkdev_queue;
// Set the size of the block device, size is the number of sectors, one sector is 512B
set_capacity(simp_blkdev_disk, SIMP_BLKDEV_BYTES>>9);
add_disk(simp_blkdev_disk);// Register simp_blkdev_disk
return 0;
}
1.3 simp_blkdev_do_request
1. Call the scheduling algorithm’s elv_next_request method to get the next request to process 2. If it is a read, copy simp_blkdev_data to request.buffer 3. If it is a write, copy request.buffer to simp_blkdev_data 4. Call end_request to notify completion
static void simp_blkdev_do_request(struct request_queue *q)
{
struct request *req;
while ((req = elv_next_request(q)) != NULL) {// Get the next request based on the scheduling algorithm
switch (rq_data_dir(req)) {// Determine read or write
case READ:
memcpy(req->buffer, simp_blkdev_data + (req->sector << 9),
req->current_nr_sectors << 9);
end_request(req, 1);// Completion notification
break;
case WRITE:
memcpy(simp_blkdev_data + (req->sector << 9), req->buffer,
req->current_nr_sectors << 9);
end_request(req, 1);// Completion notification
break;
default:
/* No default because rq_data_dir(req) is 1 bit */
break;
}
}
1.4 Unloading the Driver
static void __exit simp_blkdev_exit(void)
{
del_gendisk(simp_blkdev_disk);// Unregister simp_blkdev_disk
put_disk(simp_blkdev_disk);// Release simp_blkdev_disk
blk_cleanup_queue(simp_blkdev_queue);// Release request queue
}
Don’t forget the following code
module_init(simp_blkdev_init);
module_exit(simp_blkdev_exit);
1.5 blk_init_queue
Looking at the code above, you may still not clearly understand how request_queue connects bio and block device drivers. Let’s take a deeper look.
simp_blkdev_queue = blk_init_queue(simp_blkdev_do_request, NULL);// Call blk_init_queue
struct request_queue *blk_init_queue(request_fn_proc *rfn, spinlock_t *lock)
{
return blk_init_queue_node(rfn, lock, NUMA_NO_NODE);// Jump to 1.5.1
}
EXPORT_SYMBOL(blk_init_queue);
// 1.5.1
struct request_queue *
blk_init_queue_node(request_fn_proc *rfn, spinlock_t *lock, int node_id)
{
struct request_queue *q;
q = blk_alloc_queue_node(GFP_KERNEL, node_id, lock);
if (!q)
return NULL;
q->request_fn = rfn;// This is simp_blkdev_do_request
if (blk_init_allocated_queue(q) < 0) {// Jump to 1.5.2
blk_cleanup_queue(q);
return NULL;
}
return q;
}
EXPORT_SYMBOL(blk_init_queue_node);
// 1.5.2
int blk_init_allocated_queue(struct request_queue *q)
{
...
blk_queue_make_request(q, blk_queue_bio);// Jump to 1.5.3
if (elevator_init(q))// Initialize IO scheduling algorithm
goto out_exit_flush_rq;
return 0;
...
}
EXPORT_SYMBOL(blk_init_allocated_queue);
// 1.5.3
void blk_queue_make_request(struct request_queue *q, make_request_fn *mfn)
{
...
q->make_request_fn = mfn;// mfn is also blk_queue_bio
...
}
EXPORT_SYMBOL(blk_queue_make_request);
static blk_qc_t blk_queue_bio(struct request_queue *q, struct bio *bio)// Complete how bio is inserted into request_queue
{
// IO scheduling algorithm plays its role here
}
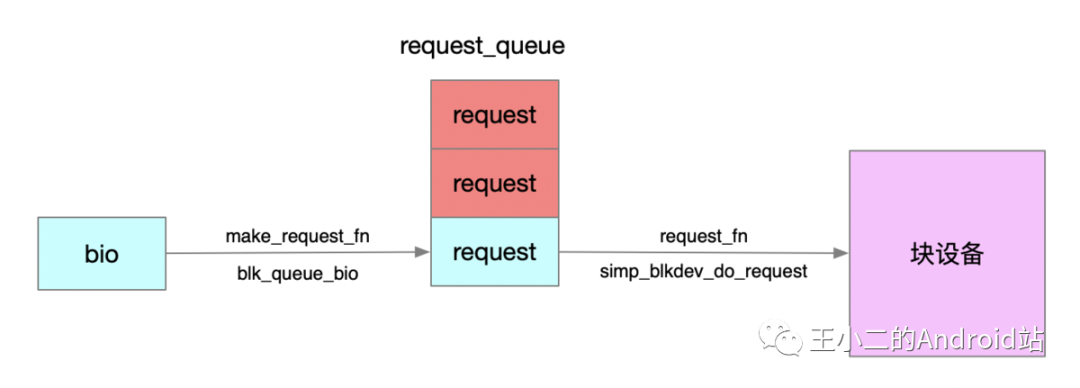
After the entire call is completed, two important methods of the current block device’s request_queue are bound
q->make_request_fn = blk_queue_bio;// Linux default implementation
q->request_fn = simp_blkdev_do_request;// Driver's own implementation
1.5.1 make_request_fn(struct request_queue *q, struct bio *bio)
submit_bio will call make_request_fn to encapsulate bio into request and insert it into request_queue, by default, it will use the Linux system’s implementation blk_queue_bio. If we replace make_request_fn, it will cause the IO scheduling algorithm to become ineffective, which is generally not modified.
1.5.2 request_fn(struct request_queue *q)
This method is generally implemented by the driver, which is simp_blkdev_do_request, to take the appropriate request from request_queue for processing, and will generally call the scheduling algorithm’s elv_next_request method to obtain a recommended request.
1.5.3 bio-block device
Through make_request_fn and request_fn, we have connected bio and block device drivers. Moreover, the IO scheduling algorithm will play its role in these two functions.
I have dug two pits for myself: 1. Throughout the process, I was influenced by the IO scheduling algorithm. How does the IO scheduling algorithm play its role? 2. How does make_request_fn trigger request_fn?
2. Ultra-High-Speed Block Devices
Traditional block device access is through the magnetic head, and the IO scheduling algorithm can optimize the order of moving the magnetic head when multiple IO requests occur.
IO Scheduling Algorithm
If you are a librarian, and ten people come to borrow ten books from you, located in different corners of the library, you will definitely choose the shortest route to get those ten books. This is actually the IO scheduling algorithm.
Ultra-High-Speed Block Devices
If this library only has one window, and borrowers just have to say the book title, the book will fly out from the window, then there is no need for any librarian, and no need for any IO scheduling algorithm. This library is an ultra-high-speed block device.
The memory-based block device we wrote above is not an ultra-high-speed block device. Can we write a driver without intermediaries?
2.1 simp_blkdev_init
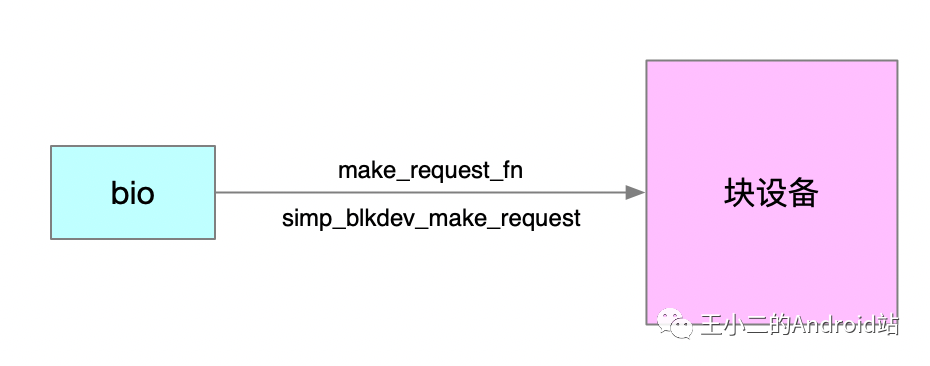
We need to rewrite the init code and not call blk_init_queue. Use the methods in 2.1.1 and 2.1.2 directly. After initialization, we will set make_request_fn to simp_blkdev_make_request.
static int __init simp_blkdev_init(void)
{
int ret;
// Initialize request queue
simp_blkdev_queue = blk_alloc_queue(GFP_KERNEL);// 2.1.1
// Bind simp_blkdev_make_request to request_queue's make_request_fn.
blk_queue_make_request(simp_blkdev_queue, simp_blkdev_make_request);// 2.1.2
simp_blkdev_disk = alloc_disk(1);// Allocate simp_blkdev_disk
// Initialize simp_blkdev_disk
strcpy(simp_blkdev_disk->disk_name, SIMP_BLKDEV_DISKNAME);// Device name
simp_blkdev_disk->major = SIMP_BLKDEV_DEVICEMAJOR;// Device number
simp_blkdev_disk->first_minor = 0;
simp_blkdev_disk->fops = &simp_blkdev_fops;// Block device operation function pointer
simp_blkdev_disk->queue = simp_blkdev_queue;
set_capacity(simp_blkdev_disk, SIMP_BLKDEV_BYTES>>9);// Set the size of the block device, size is the number of sectors, one sector is 512B
add_disk(simp_blkdev_disk);// Register simp_blkdev_disk
return 0;
err_alloc_disk:
blk_cleanup_queue(simp_blkdev_queue);
err_alloc_queue:
return ret;
}
2.2 simp_blkdev_make_request
Bypassing intermediaries, directly copy simp_blkdev_data to bio’s page, and call bio_endio to notify read/write completion. From start to finish, request_queue and request are not used at all.
static int simp_blkdev_make_request(struct request_queue *q, struct bio *bio) {
struct bio_vec *bvec;
int i;
void *dsk_mem;
// Get the starting address of the block device memory, bi_sector represents the starting sector
dsk_mem = simp_blkdev_data + (bio->bi_sector << 9);
bio_for_each_segment(bvec, bio, i) {// Traverse each block
void *iovec_mem;
switch (bio_rw(bio)) {
case READ:
case READA:
// Page represents high-end memory that cannot be accessed directly and needs to be mapped to a linear address
iovec_mem = kmap(bvec->bv_page) + bvec->bv_offset;// Obtain the corresponding memory address by adding page number and offset
memcpy(iovec_mem, dsk_mem, bvec->bv_len);// Copy data to memory
kunmap(bvec->bv_page);// Return linear address
break;
case WRITE:
iovec_mem = kmap(bvec->bv_page) + bvec->bv_offset;
memcpy(dsk_mem, iovec_mem, bvec->bv_len);
kunmap(bvec->bv_page);
break;
default:
printk(KERN_ERR SIMP_BLKDEV_DISKNAME": unknown value of bio_rw: %lu\n", bio_rw(bio));
#if LINUX_VERSION_CODE < KERNEL_VERSION(2, 6, 24)
bio_endio(bio, 0, -EIO);// Report error
#else
bio_endio(bio, -EIO);// Report error
#endif
return 0;
}
dsk_mem += bvec->bv_len;// Move address
}
#if LINUX_VERSION_CODE < KERNEL_VERSION(2, 6, 24)
bio_endio(bio, bio->bi_size, 0);
#else
bio_endio(bio, 0);
#endif
return 0;
}
2.2 No Intermediaries
Because we directly implement data access in make_request_fn, which is simp_blkdev_make_request, we have thus eliminated the request_queue and IO scheduling algorithm. No intermediaries, access speed is excellent.
The zram device in the kernel is also a memory-based block device without intermediaries profiting from the price difference. The code is very similar; if interested, you can take a look.
3. Conclusion
After such a long time of study, breaking through layers of obstacles, I finally connected IO. However, the file system, IO scheduling algorithm, and each module are worth my in-depth study; the real challenge has just begun.
Code Reference
Write a Block Device Driver.pdf
Material Reference
“Linux Kernel Design and Implementation” “Complete Commentary on Linux Kernel” Linux.Generic.Block.Layer.pdf https://zhuanlan.zhihu.com/c_132560778
Read the original text to obtain the complete code
