
AliMei’s Guide
The author recently attempted to write some Rust code, and this article mainly discusses their views on Rust and some differences between Rust and C++.
Background
Risks in C++ Code
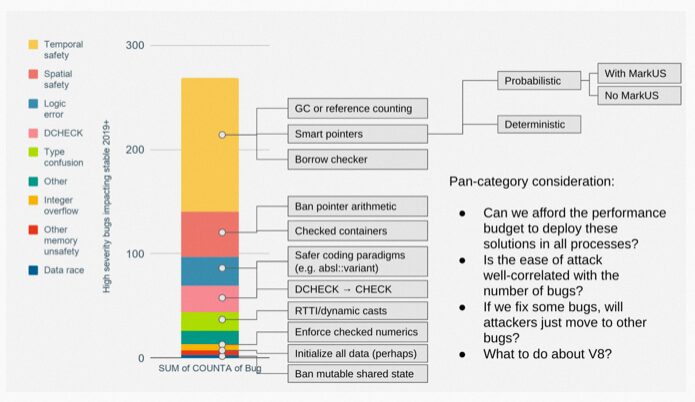
-
Temporal safety: Simply put, it’s use after free. -
Spatial safety: Simply put, it’s out of bounds access. -
Logic error -
DCHECK: Simply put, it’s when a debug assert condition is triggered in the release version.
Not much more to elaborate.
First Experience with Rust
Default Immutability
let x = 0;x = 10; // error
let mut y = 0;y = 10; //okfn foo(x: u32) {}
let x: i32 = 0;foo(x); // errorSimplified Construction, Copying, and Destruction
class ABC{public: virtual ~ABC();
ABC(const ABC&) = delete; ABC(ABC&&) = delete;
ABC& operator=(const ABC&) = delete; ABC& operator=(ABC&&) = delete;};
Clearly, this is a very routine thing, yet writing it is so complex.
fn main(){ // String is similar to std::string, only supports explicit clone, does not support implicit copy
let s: String = "str".to_string(); foo(s); // s will move // cannot use s anymore
let y = "str".to_string(); foo(y.clone());
// use y is okay here}
fn foo(s: String) {}
// can only be passed by movestruct Abc1{ elems: Vec<int>}
// can use abc.clone() to explicit clone a new Abc#[derive(Clone)]struct Abc2{ elems: Vec<int>}
// implement custom destructor for Abcimpl Drop for Abc2 { // ...}
// foo(xyz) will copy, 不能再定义Drop/析构函数,因为copy和drop是互斥的#[dervie(Clone, Copy)]struct Xyz{ elems: i32}
Explicit Parameter Passing
let mut x = 10;
foo(x); // pass by move, x cannot be used after the callfoo(&x); // pass by immutable referencefoo(&mut x); // pass by mutable reference-
errno -
std::exception -
std::error_code/std::error_condition -
std::expected
Look, even the standard library itself is like this. In std::filesystem, every interface has at least two overloads, one that throws exceptions and one that passes std::error_code.
enum MyError{ NotFound, DataCorrupt, Forbidden, Io(std::io::Error)}
impl From<io::Error> for MyError { fn from(e: io::Error) -> MyError { MyError::Io(e) }}
pub type Result<T> = result::Result<T, Error>;
fn main() -> Result<()>{ let x: i32 = foo()?; let y: i32 = bar(x)?;
foo(); // result is not handled, compile error
// use x and y}
fn foo() -> Result<i32>{ if (rand() > 0) { Ok(1) } else { Err(MyError::Forbidden) }}
Error handling is uniformly completed through Result<T, ErrorType>, and through ?, errors are propagated upwards with one click (supporting automatic conversion from ErrorType1 to ErrorType2, provided you implement the related trait), and when there are no errors, it automatically unpacks. When you forget to handle Result, the compiler will report an error.
Built-in Formatting and Linting
Standardized Development Process and Package Management
cargo test
cargo bench
cargo specifies directory styles
benches // benchmark code goes here
src // source code goes here
tests // unit tests go here
Improvements in Rust’s Safety
Lifetime Safety
let s = vec![1,2,3]; // s owns the Vecfoo(s); // the ownership is passed to foo, s cannot be used anymore
let x = vec![1,2,3];let a1 = &x[0];let a2 = &x[0]; // a1/a2 are both immutable refs to x
x.resize(10, 0); // error: x is already borrowed by a1 and a2
println!("{a1} {a2}");This unique ownership + borrow check mechanism effectively avoids pointer/iterator invalidation bugs and performance issues caused by aliasing.
let s: &String;
{ let x = String::new("abc"); s = &x;}
println!("s is {}", s); // error, lifetime(s) > lifetime(x)This example is quite simple, now let’s look at some more complex ones.
// not valid rust, for exposition only
struct ABC{ x: &String,}
fn foo(x: String){ let z = ABC { x: &x };
consume_string(x); // not compile, x is borrowed by z drop(z); // call destructor explicitly
consume_string(x); // ok
// won't compile, bind a temp to z.x let z = ABC { x: &String::new("abc") }; // use z
// Box::new == make_unique // won't compile, the box object is destroyed soon let z = ABC{ x: &*Box::new(String::new("abc") }; // use z}
Now let’s look at a more concrete example involving multithreading.
void foo(ThreadPool* thread_pool){ Latch latch{2};
thread_pool->spawn([&latch] { // ... latch.wait(); // dangling pointer access });
// forget latch.wait();}
This is a very typical lifetime error; C++ may only discover the issue at runtime, but for Rust, similar code will fail to compile. Because latch is a stack variable, its lifetime is very short, while passing references across threads means this reference could be called at any time, and its lifetime is the entire process lifecycle. Rust has a dedicated name for this lifetime, called ‘static. As the C++ core guidelines state:CP.24: Think of a thread as a global container, never save a pointer in a global container.
fn foo(thread_pool: &mut ThreadPool){ let latch = Arc::new(Latch::new(2)); let latch_copy = Arc::clone(&latch);
thread_pool.spawn(move || { // the ownership of latch_copy is moved in latch_copy.wait(); });
latch.wait();}
Let’s look at a more specific example. Suppose you are writing a file reader that returns a line each time. To reduce overhead, we want the returned line to directly reference the buffer maintained internally by the parser to avoid copying.
FileLineReader reader(path);
std::string_view<char> line = reader.NextLine();std::string_view<char> line2 = reader.NextLine();
// opsstd::cout << line;
let reader = FileReader::next(path);let line = reader.next_line();
// won't compile, reader is borrowed to line, cannot mutate it nowlet line2 = reader.next_line();
println!("{line}");// &[u8] is std::span<byte>fn foo() -> &[u8] { let reader = FileReader::next(path); let line = reader.next_line();
// won't compile, lifetime(line) > lifetime(reader) return line;}
In summary, Rust defines a set of rules, and adhering to these rules guarantees that there will be no lifetime issues. When the Rust compiler cannot infer the correctness of a particular syntax, it will force you to use reference counting to resolve the problem.
Boundary Safety
Type Safety
let i: i32;
if rand() < 10 { i = 10;}
println!("i is {}", i); // do not compile: i is not always initializedRust’s Multithreading Safety
-
Send: A type is Send, indicating that the ownership of an object of this type can be passed across threads. When all members of a new type are Send, that type is also Send. Almost all built-in types and standard library types are Send, except for Rc (which is similar to a local shared_ptr) because it uses a normal int for counting. -
Sync: A type is Sync, indicating that this type can be shared across multiple threads (in Rust, sharing means immutable references, i.e., concurrent access through its immutable references).
Send/Sync are two traits in the standard library, and the standard library provides corresponding implementations or forbids corresponding implementations for existing types.
-
The lifetime mechanism requires that when an object is passed across threads, it must be wrapped in Arc (Arc for atomic reference counted) (Rc cannot be used because it is explicitly marked as !Send, meaning it cannot be passed across threads). -
The ownership + borrow mechanism requires that objects wrapped in Rc/Arc can only be dereferenced as immutable references, and concurrent access to an immutable object is inherently safe. -
Interior mutability is used to solve the shared write problem: Rust defaults to sharing meaning immutability, and only exclusivity allows mutation. If both sharing and mutability are needed, Rust’s official term for this is interior mutability, which is actually more easily understood as shared mutability. It is a mechanism that provides safe changes to shared objects. If multiple threads need to change the same shared object, additional synchronization primitives (RefCell/Mutex/RwLock) must be used to achieve interior/shared mutability, and these primitives ensure that only one writer exists. RefCell is used with Rc for shared access in single-threaded environments. RefCell is specifically marked as !Sync, meaning that if it is used with Arc, Arc is not Send, and thus Arc<RefCell<T>> cannot be passed across threads.
Let’s look at an example: suppose I implement a Counter object that multiple threads want to use simultaneously. To solve the ownership problem, I need to use Arc<Counter> to pass this shared object. However, the following code will not compile.
struct Counter{ counter: i32}
fn main(){ let counter = Arc::new(Counter{counter: 0}); let c = Arc::clone(&counter); thread::spawn(move || { c.counter += 1; });
c.counter += 1;}
This is because Arc shares an object, and to ensure the borrow mechanism, accessing the internal object of Arc can only yield immutable references (the borrow mechanism stipulates that there can be either one mutable reference or several immutable references). This rule of Arc prevents the occurrence of data races.
fn main(){ let counter = Arc::new(RefCell::new(Counter{counter: 0})); let c = Arc::clone(&counter); thread::spawn(move || { let mut x = c.get_mut(); x.counter += 1; });
c.get_mut().counter += 1;}
Why? Because RefCell is not Sync, so it does not allow multi-threaded access. Arc is only Send when its internal type is Sync. Thus, Arc<Cell<T>> is not Send and cannot be passed across threads.
struct Counter{ counter: i32}
fn main(){ let counter = Arc::new(Mutex::new(Counter{counter: 0})); let c = Arc::clone(&counter); thread::spawn(move || { let mut x = c.lock().unwrap();
x.counter += 1; });}
Rust’s Performance
// for demo purpose
fn foo(tasks: Vec<Task>){ let latch = Arc::new(Latch::new(tasks.len() + 1));
for task in tasks { let latch = Arc::clone(&latch); thread_pool.submit(move || { task.run(); latch.wait(); }); }
latch.wait();}
Here, latch must use Arc (i.e., shared_ptr).
-
Function calls -
Pointer aliasing
Both C++ and Rust can eliminate the overhead caused by function calls through inline. However, C++ is basically powerless against pointer aliasing. C++’s optimization for pointer aliasing relies on the strict aliasing rule, which is notoriously problematic; Linus has criticized it several times. In Linux code, the -fno-strict-aliasing is used to disable this rule.
int foo(const int* x, int* y){ *y = *x + 1;
return *x;}
The Rust version:
fn foo(x: &i32, y: &mut i32) -> i32{ *y = *x + 1;
*x}
The corresponding assembly is as follows:
# c++__Z3fooPKiPi: ldr w8, [x0] add w8, w8, #1 str w8, [x1] ldr w0, [x0] ret
# rust__ZN2rs3foo17h5a23c46033085ca0E: ldr w0, [x0] add w8, w0, #1 str w8, [x1] retCan you see the difference?
Reflections
-
The evolution of C++’s safety is a trend, but the future is very unclear: C++ has billions of lines of existing code worldwide. Expecting C++ to improve memory safety while maintaining compatibility is an almost impossible task. Both clang-format and clang-tidy provide line-filter to check specific lines, avoiding situations where modifying an old file requires reformatting the entire file or modifying all lint failures. Perhaps based on this, Bjarne has been trying to enhance C++’s memory safety through static analysis and localized checks. -
Rust is beneficial for large team collaboration: As long as Rust code compiles and does not use unsafe features, it is guaranteed to have no memory safety or thread safety issues. This greatly reduces the mental burden of writing complex code. However, Rust’s safety comes at the cost of language expressiveness, which may be a good thing for team collaboration and code readability. As for the rest, without sufficient Rust practical experience, I cannot make further judgments.
Relax and enjoy coding!
References:
1. Cpp core guidelines: https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines
2. Chrome’s exploration in security:https://docs.google.com/document/d/e/2PACX-1vRZr-HJcYmf2Y76DhewaiJOhRNpjGHCxliAQTBhFxzv1QTae9o8mhBmDl32CRIuaWZLt5kVeH9e9jXv/pub
3. NSA’s criticism of C++:https://www.theregister.com/2022/11/11/nsa_urges_orgs_to_use/
4. C++ Lifetime Profile: https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#SS-lifetime
5. C++ Safety Profile: https://open-std.org/JTC1/SC22/WG21/docs/papers/2023/p2816r0.pdf?file=p2816r0.pdf
6. Herb CppCon2022 Slide: https://github.com/CppCon/CppCon2022/blob/main/Presentations/CppCon-2022-Sutter.pdf
7. Understanding Rust’s ownership model:https://limpet.net/mbrubeck/2019/02/07/rust-a-unique-perspective.html