Author: Wahda Xi Wah
https://www.zhihu.com/question/278798145/answer/3416549119

In recent years, I have often seen some large companies that heavily used Python migrate to other language stacks. But what about small companies or teams?
I have always wanted to understand how companies that still insist on using Python, and support a certain scale of business, are using the Python tech stack for development, what difficulties or lessons they encounter, and what excellent experiences they have?
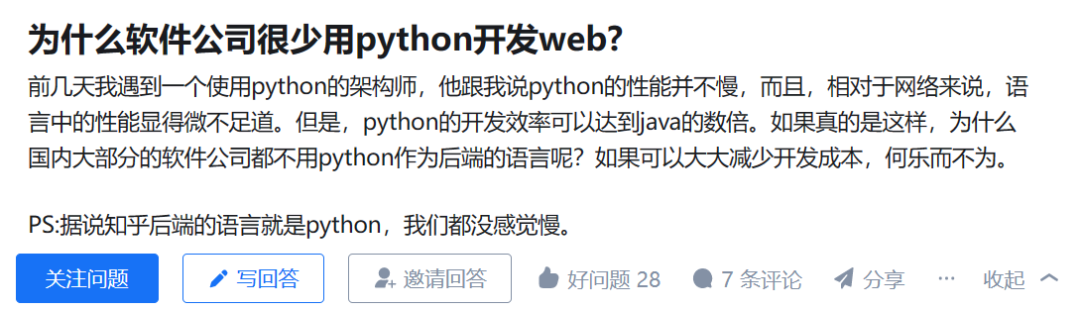
By chance, I saw an answer under the question “Why do software companies rarely use Python for web development?” on a certain platform, and I would like to share it with everyone.
Author: Wahda Xi Wah
(https://www.zhihu.com/question/278798145/answer/3416549119)
Response:
I have been using Python for over 10 years. The longest-maintained project of mine has an annual transaction volume of several hundred million, which is an e-commerce platform. The concurrency is not large, usually around dozens, and during holidays, it goes over 100. At the peak, I don’t think it ever exceeded 200. The total number of orders in the database is around 50 million, increasing by several thousand daily. The project has been running for seven or eight years, still using Python 2.7 + Django 1.8, and there are no plans to upgrade.
Currently, we have 1 server with 4 cores and 8GB, and 3 servers with 8 cores and 16GB on Alibaba Cloud. The database and Redis are also on Alibaba Cloud, costing about 50,000 a year. We use Qiniu for CDN, which also costs several thousand a year. There are three programmers, including myself, maintaining it, and new features are added almost every week. After several years of adjustments, the effective code is estimated to be less than 70%, as some code is no longer used for business reasons.
In 2021, we developed another system using Python 3.8 + Django 3. It usually has little volume but spikes during holidays. So far, the highest record is 350 orders per minute, with 150,000 orders in a day, resulting in a transaction volume of about 15 million that day. We usually have two servers with 8 cores and 16GB, and during holidays, we expand to 6 servers, and the database is also temporarily upgraded.
We also have a few small projects that haven’t really taken off, with about two people responsible for one project, and one person managing two projects in a cross manner.
Currently, the entire company’s backend tech stack is Python + Django + Gunicorn (with a small project using Tornado). The company has accumulated some basic framework based on Django, and the entire company is not large, with about fourteen or fifteen programmers familiar with this framework. Newcomers usually go through a process of strengthening their Python basics -> learning Django -> learning the company framework -> entering project development.
The company has stricter requirements for naming, style, etc., and pays more attention during code reviews. After becoming familiar, everyone works in harmony, so the drawbacks of Python as a dynamic language have not been significantly manifested.
In the early days, we lacked experience and encountered crashes when concurrency slightly increased. Later, we upgraded the database (initially self-built) and added some Redis caching, which significantly reduced the occurrence of such issues.
Some of the query languages constructed by Django are overly complex or not optimized, leading to slow queries. The current solution is to regularly monitor slow logs and find the problematic code for optimization. The database itself also needs to be upgraded according to business needs. This is actually the same for any language.
I have had exposure to most programming languages, but I feel that Python allows me to express my intentions to the computer as easily as my native language.
In my opinion, once programmers become familiar with Python, they only need to understand the business and convert requirements into code without spending too much time on technical aspects. Python also has a rich library, and most problems encountered have ready-made solutions. Django’s ORM is also excellent, allowing programmers to easily interact with the database without worrying about table structure changes or complex queries.
There are downsides, such as Python being somewhat cumbersome, especially as projects grow larger and more complex, leading to longer startup times and increased memory usage.
Django’s ORM brings convenience but also leads to some inefficient code, such as complex queries that result in too many joins, causing long query times, or querying unnecessary fields all at once, as well as a large number of data queries within for loops.
However, I believe these drawbacks are not fatal, as the cost of increasing cloud server resources is minimal compared to labor costs and development efficiency. Moreover, for performance, most projects do not reach the optimization stage before they fail. Some norms or usage methods can be improved through training, and the code quality of most people will gradually improve.
In addition to web development, we also use Python on some hardware devices (mostly single-board computers running Linux, such as Raspberry Pi, 7688, etc.). The advantage is that we can develop on a computer and directly run it on the device without needing to hire specialized embedded engineers. After encapsulating the hardware call parts, any backend developer in the company can develop.
We also use Python for image processing, web scraping, automated testing, and CI/CD.
For small teams, Python’s low entry barrier and high efficiency are more valuable than the elusive performance loss, provided that norms are established, quality is emphasized, and continuous attention and optimization are maintained.
I didn’t expect this answer to attract so much attention, so I will add a few more points.
The system mentioned earlier, which processes 350 orders per minute, mainly aggregates orders from several food delivery platforms into the system, allowing merchants to also aggregate and call delivery platforms to send riders. The entire process involves synchronizing food delivery orders and delivery orders, as well as some management functions.
Order notifications from food delivery platforms (new orders, order status changes, etc.) are sent to our system via HTTP requests. In the early days, we implemented a synchronous approach, where we would call the food delivery platform’s order query interface (and several other supporting interfaces) to obtain order details after receiving the request, then create the order in the database, and finally respond. Since a large number of network requests take considerable time, we couldn’t handle even a slight increase in concurrency. We tried running multiple machines and processes, but the effect was minimal.
I remember that in the early days, being able to process 30 orders per minute was basically the limit. Beyond that, we experienced significant slow responses, and the food delivery platform required us to respond within a specified time. Therefore, this synchronous processing approach couldn’t last long before hitting a bottleneck. We tried using multi-threaded task queues, but the results were unsatisfactory, and there was a risk of task loss.
Later, we used Celery; after receiving notifications, we placed the messages in the Celery queue and returned immediately, allowing Celery worker processes to handle them gradually, thus avoiding being overwhelmed during peak periods. Since placing messages in the Celery queue is a very fast operation, the system can respond to food delivery platform notifications immediately.
Based on message backlog conditions, we adjust the number of Celery worker processes appropriately and can allocate different queues based on message priority, ensuring that new order notifications are processed promptly, allowing merchants to know about new orders that need handling as soon as possible.
Initially, we used Redis for Celery’s message distribution, but later we switched to RabbitMQ for easier monitoring. After several years of iteration, we are now relatively confident in handling peak periods during holidays. We can temporarily increase cloud resources as needed, and the Celery worker processes are also set to scale automatically. In principle, we believe we can handle most situations without encountering extreme cases.
In addition to the above, about seven or eight years ago, we used Python 2 + Django 1.8 to develop a data reporting system for the government. Each year, we would open it for a week for around four or five thousand enterprises to fill in. I didn’t pay attention to concurrency at that time, but conservatively estimating, there would be dozens.
Initially, we ran it using Django’s built-in runserver mode (due to lack of experience), which easily led to stalling. Later, we ran several processes using Gunicorn, and the language-level stalling issue was resolved. When it was slow, it was mostly due to high database load or MongoDB doing data aggregation.
The server configuration was not high, just 2C8G, running Python Web, MySQL, MongoDB, and several other application processes. This system ran for three years, and in the fourth year, due to changes in government relations, it was redeveloped by another company. Their functionality was less than ours and was difficult to use, and I don’t know what language they used.
In this project, the combination of Python + MongoDB gave us great flexibility because the data filled out each year was different, and the statistical indicators varied. The entire system supported custom forms, data validation, data import/export, and custom statistics. I feel it would be challenging to achieve such results with another language, or the cost would be much higher.
Of course, this system had very few maintenance issues; it was basically developed once and needed to be accessible afterward. At that time, I led a junior programmer in the development, where I was responsible for the core architecture and most of the code implementation, while he handled simpler logic, UI, and table definitions. He might not have found it easy to understand the code I wrote. The maintainability of such complex systems’ code largely depends on norms, documentation, and training, rather than the language’s type constraints.
We also developed an internal office system for travel agencies, primarily targeting Southeast Asian travel agencies, supporting multiple languages and currencies, covering almost all daily operations of travel agencies, including planning, group formation, shopping, hotels, transportation, guiding, guests, accounting, revenue, finance, reports, charts, etc.
This was also done using Python 2 + Django 1.8. We deployed an independent web process and a database for each travel agency (the database name was independent, but one MySQL instance ran on one machine). Each web process used about 170MB of memory. We used 2C8G machines, and each machine could serve around 40 clients. Generally, the daily user data for clients was about 10, while larger travel agencies might have 20 to 30 employees operating simultaneously. Most of the time, the concurrency for each agency would not exceed 10.
At the beginning of each month, when all agencies were doing accounting and exporting data, they occasionally reported slowdowns. From my observation, most of the time, it was a database performance issue. Our solution was to tell clients to wait a while before exporting (or if they needed to export a lot of data, we advised them to do so at night). As long as a few agencies staggered their exports, there would be no issues.
To save costs, we also self-built the database on cloud servers, nearly pushing the cloud servers to their limits. During the day, the servers typically ran at over 80% CPU usage and over 90% memory usage, with CPU usage hitting 100% during data exports.
Before 2020, we had over 100 clients, but during the three years of the pandemic, we basically stopped tourism work. In recent years, we have regained a few clients, but the situation is completely different, as income has sharply reduced, and clients’ willingness to pay has significantly decreased.
I started using Python around 2012, prior to which I worked more with Java and C#. Java was used for Android and web development, while C# was used for Windows desktop applications and Windows Phone development.
Before, I found Java’s SSH framework XML configuration quite cumbersome, and I didn’t know if Spring would be more convenient now. Besides the framework hassle, I felt that Java itself was relatively tedious.
C# felt better than Java, but it fell short in cross-platform aspects. So now, I choose C# only for desktop applications; otherwise, I wouldn’t select it, especially since most desktop applications are now web-based.
Python, on the other hand, feels simple enough to allow people to focus on business. Therefore, when the company chose its primary language, Python was selected (even though at that time, I wasn’t as familiar with Python as I was with Java and C#). The entire team was built around Python, and I believe that with the development of AI, Python will become increasingly popular.
In the past few years, it was relatively difficult to recruit Python developers, as most came from other languages and gradually adapted and became familiar. However, in recent years, there have been more people with a Python background (thanks to advertising on public accounts?), but most are still at a low level and require a familiarization and strengthening process.
Generally, those who work on better projects for more than half a year become quite proficient, while those who take longer may need more than a year. The key factor is interest; some people inherently enjoy programming and will make quick progress in their personal projects after work.
Different team experiences cannot be completely replicated. I am one of the founders of the company, and I determine the technical direction, so there are no issues with resignations.
I am still very interested in using Python to solve most of the technical problems we encounter, including how to establish norms and train people to ensure code control and personnel improvement.
In conclusion, over these years, I have accumulated some technical and management experience, and I will share a recommendation for a productivity tool that everyone uses.
Recommended productivity tool that everyone uses
I am selling this tool that completely clones ChatGPT and Claude every day. It can be used directly in the domestic environment and costs less than half of the official price. If you want to improve your work efficiency through ChatGPT and Claude, you can scan the code to learn more and purchase.
 Improve work efficiency, scan the code to learn about the dual systems of GPT and Claude.
Improve work efficiency, scan the code to learn about the dual systems of GPT and Claude.