1. Introduction to HTTP
1. The HTTP protocol, or Hypertext Transfer Protocol, is a detailed specification that defines the rules for communication between browsers and World Wide Web (WWW) servers, facilitating the transfer of web documents over the Internet.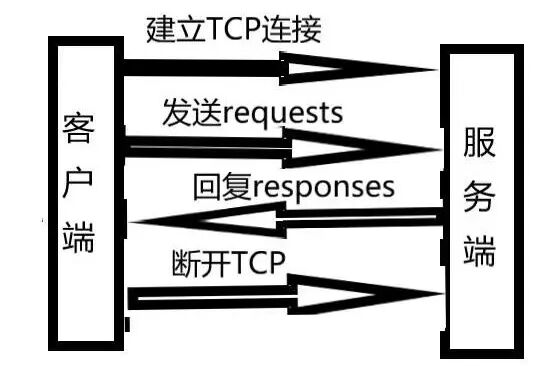 2. As a protocol in the application layer of the TCP/IP model, HTTP typically operates over the TCP protocol, and sometimes over TLS or SSL, which is commonly referred to as HTTPS. See the diagram below:
2. As a protocol in the application layer of the TCP/IP model, HTTP typically operates over the TCP protocol, and sometimes over TLS or SSL, which is commonly referred to as HTTPS. See the diagram below: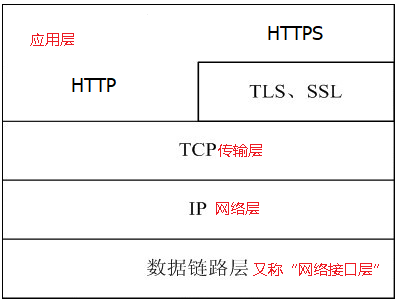
3. HTTP is an application layer protocol composed of requests and responses, following a standard client-server model. It is a stateless protocol.
4. The default port for HTTP is 80, while HTTPS uses port 443.
5. Browsing web pages is the primary application of HTTP, but it is not limited to this. HTTP is a protocol that can be utilized as long as both parties in communication adhere to it. For example, commonly used applications like QQ and Thunder also utilize the HTTP protocol (along with other protocols).
2. Characteristics of HTTP
1. Simple and Fast: When a client requests a service from a server, it only needs to send the request method and path. The simplicity of the HTTP protocol results in smaller server program sizes, leading to faster communication speeds.2. Flexible: HTTP allows the transmission of any type of data object, with the type being indicated by the Content-Type header.3. HTTP 0.9 and 1.0 use non-persistent connections: each connection handles only one request, and the connection is closed after the server processes the client’s request and receives the response. HTTP 1.1 uses persistent connections: a single connection can transmit multiple objects, saving transmission time. 4. Stateless: The HTTP protocol is stateless, meaning it does not retain memory of transactions. The lack of state implies that if subsequent processing requires previous information, it must be retransmitted, potentially increasing the amount of data transmitted with each connection. Conversely, responses are faster when the server does not require prior information.5. Supports both B/S and C/S models.
4. Stateless: The HTTP protocol is stateless, meaning it does not retain memory of transactions. The lack of state implies that if subsequent processing requires previous information, it must be retransmitted, potentially increasing the amount of data transmitted with each connection. Conversely, responses are faster when the server does not require prior information.5. Supports both B/S and C/S models.
3. HTTP Workflow
An HTTP operation is referred to as a transaction, and its workflow can be divided into four steps:
1. First, the client and server need to establish a connection. The HTTP process begins when a hyperlink is clicked.
2. After establishing a connection, the client sends a request to the server, formatted as: Uniform Resource Identifier (URL), protocol version, followed by MIME information including request modifiers, client information, and possible content.
3. Upon receiving the request, the server responds with corresponding information, formatted as a status line that includes the protocol version, a success or error code, followed by MIME information including server information, entity information, and possible content.
4. The client receives the information returned by the server, which is displayed on the user’s screen via the browser, after which the client disconnects from the server. If an error occurs at any step in this process, an error message will be returned to the client, which will be displayed on the screen. For the user, these processes are handled by HTTP itself; they simply need to click the mouse and wait for the information to display.
4. HTTP Request Message
The HTTP request sent by the client to the server includes the following format:
Request Line, Request Header, Empty Line and Request Data consist of four parts.
(1) Example of a GET request

First Part:Request Line, which specifies the request type, the resource to be accessed, and the HTTP version used.
GET indicates that the request type is GET, [/562f25980001b1b106000338.jpg] is the resource to be accessed, and the last part of this line indicates that HTTP version 1.1 is being used.
Second Part:Request Header, which follows the request line (i.e., the first line), provides additional information that the server needs to use.
From the second line onward is the request header, where HOST indicates the destination of the request. User-Agent can be accessed by both server-side and client-side scripts; it is an important basis for browser type detection logic. This information is defined by your browser and is automatically sent with each request, among other things.
Third Part:Empty Line, which is mandatory after the request header.
Even if the fourth part, the request data, is empty, the empty line must still be present.
Fourth Part:Request Data, also known as the body, can include any additional data.
In this example, the request data is empty.Example of a POST request
First Part: Request Line, which clearly indicates it is a POST request and the HTTP version is 1.1.Second Part: Request Header, from the second to the sixth line.Third Part: Empty Line, the empty line on the seventh line.Fourth Part: Request Data, on the eighth line.
5. HTTP Response Message
Generally, after the server receives and processes the request sent by the client, it returns an HTTP response message.
HTTP responses also consist of four parts:Status Line, Message Header, Empty Line and Response Body.
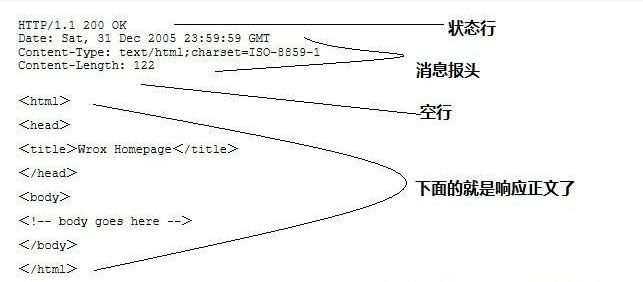
First Part:Status Line, composed of the HTTP protocol version, status code, and status message.
The first line is the status line, (HTTP/1.1) indicates that the HTTP version is 1.1, the status code is 200, and the status message is (OK).
Second Part:Message Header, which provides additional information that the client needs to use.
The second, third, and fourth lines are the message headers,Date: the date and time the response was generated; Content-Type: specifies the MIME type of HTML (text/html), and the encoding type is ISO-8859-1.
Third Part:Empty Line, which is mandatory after the message header.
Fourth Part:Response Body, the text information returned by the server to the client.
The HTML part following the empty line is the response body.
6. HTTP Status Codes
Status codes consist ofthree digits, with the first digit defining the category of the response, which is divided into five categories:
1xx:Informational — indicates that the request has been received and is continuing to be processed.
2xx:Success — indicates that the request has been successfully received, understood, and accepted.
3xx:Redirection — further action is required to complete the request.
4xx:Client Error — indicates that there is a syntax error in the request or the request cannot be fulfilled.
5xx:Server Error — indicates that the server failed to fulfill a valid request.
Common status codes:

7. HTTP Request Methods
According to HTTP standards, various request methods can be used.HTTP 1.0 defined three request methods: GET, POST and HEAD methods.HTTP 1.1 added five new request methods:OPTIONS, PUT, DELETE, TRACE and CONNECT methods.

8. How HTTP Works
The HTTP protocol defines how web clients request web pages from web servers and how servers deliver web pages to clients. The HTTP protocol employs a request/response model. The client sends a request message to the server, which includes the request method, URL, protocol version, request headers, and request data. The server responds with a status line, which includes the protocol version, success or error code, server information, response headers, and response data.
The following are the steps of the HTTP request/response process:
1. The client connects to the web server
An HTTP client, typically a browser, establishes a TCP socket connection with the web server’s HTTP port (default is 80). For example, http://www.oakcms.cn.
2. Send HTTP request
Through the TCP socket, the client sends a text request message to the web server, which consists of four parts: request line, request headers, empty line, and request data.
3. Server receives the request and returns HTTP response
The web server parses the request and locates the requested resource. The server writes a copy of the resource to the TCP socket for the client to read. A response consists of four parts: status line, response headers, empty line, and response data.
4. Release connectionTCP connection
If the connection mode is close, the server actively closes the TCP connection, and the client passively closes the connection, releasing the TCP connection; if the connection mode is keepalive, the connection will remain open for a period, allowing further requests during that time;
5. Client browser parses HTML content
The client browser first parses the status line to check the status code indicating whether the request was successful. It then parses each response header, which informs how many bytes of HTML document and the document’s character set are present. The client browser reads the response data HTML, formats it according to HTML syntax, and displays it in the browser window.
9. Differences Between GET and POST
1. Data submitted via GET is appended to the URL after a ?, with parameters separated by &, such as EditPosts.aspx?name=test1&id=123456. The POST method places the submitted data in the body of the HTTP packet. 2. GET has size limitations on submitted data (due to browser URL length restrictions), while POST has no such limitations. 3. GET requires using Request.QueryString to retrieve variable values, while POST uses Request.Form to obtain variable values. 4. Using GET to submit data can lead to security issues; for example, when submitting data from a login page via GET, the username and password will appear in the URL. If the page can be cached or if others can access the machine, they can retrieve the user’s account and password from the history.
Source: The Name of the Raindrop
Address: https://www.cnblogs.com/qdhxhz/p/8468913.html