-
Surface Web, Deep Web, and Dark Web
 Most of the resources on the internet exist beyond the normal world of e-commerce, email, and social media that most people use daily. When a person delves into the lesser-known areas of the internet, it requires special knowledge to find these websites, and sometimes specific software is needed to access them.
Most of the resources on the internet exist beyond the normal world of e-commerce, email, and social media that most people use daily. When a person delves into the lesser-known areas of the internet, it requires special knowledge to find these websites, and sometimes specific software is needed to access them.
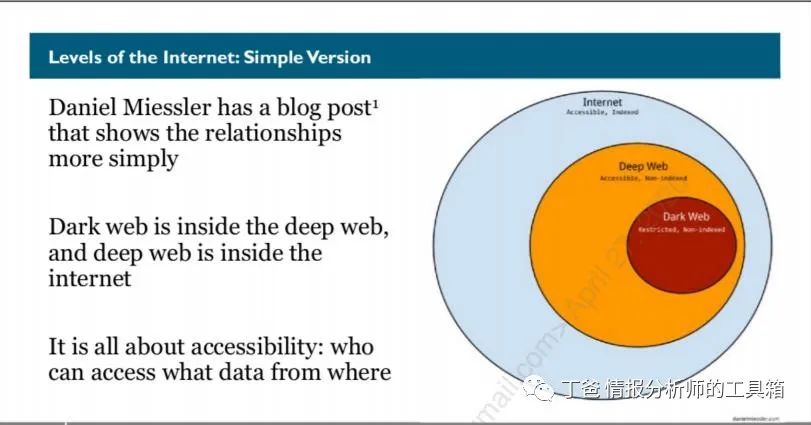
The layers of the internet: Daniel Miessler created the image above. As Daniel points out in his blog, the size of these “circles” does not depend on usage, the number of sites, or user base. They are representative and indicate that the internet serves as a communication pillar for all other networks. We should also mention that some sites may fit multiple layers, but these are exceptions to the rule.
The “Surface Web” (or “Internet” in the image above) can be accessed by most users unless access is restricted by individuals, companies, or countries. Here, DuckDuckGo, Yahoo, Bing, and Google all have web crawlers that scan all the systems they can find and index their data for us to search. The surface web primarily shares data with individuals seeking network or system resources.
While these search engines scan a vast amount of internet resources, they miss even more. This group of “missed services” constitutes the deep web. Why are these sites “missed” by search engines? Wikipedia? There are many reasons why crawlers cannot access this data, but some simple explanations are that these sites may require authentication, or they may have non-web content that search engines do not collect.
Within the deep and unindexed web lies the dark web. Accessing resources in this part of the internet requires additional knowledge and software. While the dark web is often considered a place for evil and criminal activities, there are many other legitimate (and lawful) reasons to use it.

What is the surface web?
Most of the services consumers use on the internet are found on the surface web. It includes all the websites and services you can find through search engines, social media, and other sites.
Examples of surface web sites include:
Search Engines – Google, Baidu, Yandex
E-commerce Sites – Alibaba, Amazon
News – BBC, CNN
Streaming Audio/Video – YouTube, Twitch.tv
Government Pages – nist.gov, gov.uk
Weather, Map Sites – weather.com, Bing Maps
Social Media – Facebook, Twitter, Instagram
File Sharing Sites – Dropbox, Box
When people mention the “internet,” they are usually referring to this layer of the surface web. Access and use are straightforward.

What is the deep web?
Any person who knows where to look can access deep web sites. Due to access restrictions, these sites and systems usually do not appear in search engine results. The websites in this area can be free or paid. They may require authentication or may not. In most cases, they are services that are harder to find on the internet. There is a gray area between the surface web and the deep web because as search engines index more sites, some content in the deep web seems to shift to the surface web. Other sites do the opposite, if they add authentication to protect their data from search engines.
Some of the sites displayed above are in the deep web.

What is the dark web?
The dark web requires people to use special software and understand how specific dark web sites operate. Most people think criminals exploit the dark web, and while that is true, they are not the only ones who do so.
Overall, the dark web is a place where people communicate with others more anonymously. If a person lives or works in a country that does not allow freedom of speech, they can use the anonymity of the dark web to pass their information to others. In the dark web, you can buy and sell a variety of legal and illegal items, from firearms and drugs to services and counterfeit currency.
Finding sites within some dark web networks can be a challenge because many dark web services may be private or hidden. You may need to know certain people to get an invitation for some resources. But other dark web networks allow users to enter the dark web from the internet, jump from one system to another, and then return to the internet to post content more anonymously.

Open Source Intelligence in the Dark Web
As an OSINT analyst, you may need to access the dark web for several reasons:
Curiosity – What is it? Think about whether it can help your clients.
Secure Communication – Sometimes, OSINT analysts may need to access resources from countries with oppressive computer network policies. By using the dark web, they may be able to penetrate these networks or obtain useful information from them.
Traffic Anonymization – This is one of the main reasons many OSINT analysts use the dark web: it helps hide their traffic sources. If you work in an “intelligence agency” and are trying to access websites on the internet, they may block, monitor, and highlight your network activity. By using anonymous services in the dark web, analysts can hide their traffic sources and access network resources without additional scrutiny.
Searching for Targets – Depending on your work, you may need to check for people and content that exist in one or more dark networks. Whether your target is a terrorist, human trafficker, or counterfeiter, they may operate in the dark web.
Financial Fraud – With its marketplace, the dark web is an ideal place for those who steal credit card or bank account information to sell their products.
Law Enforcement and Intelligence Agencies – Based on the statements above, your targets may operate in the dark web. Law enforcement and intelligence agencies use the dark web to research crime (past, present, and future).

Tracking Websites: In the early days when the World Wide Web was just invented, we did not have search engines. We did not need them because there were not many websites publishing content. As the World Wide Web grew, people began creating lists of their favorite websites and publishing them on the page you see above. This was the first web page on the internet, which was simply an organized list of resources that people could access.
If you did not know about these list pages, you could buy a book from O’Reilly, “The Whole Internet User’s Guide and Catalog,” which cataloged the “new websites” on the internet every year.
Why take a history lesson? Because the deep web is also in a similar state.
Similar Questions, Different Layers
When the internet first started, there were only a handful of websites. As its popularity and usefulness grew, people needed a way to categorize useful web resources. As mentioned earlier, they created lists and hyperlinked to content. The deep web has the same issue. There are many resources on the internet that are not indexed by search engines, and we need to track them. How do we do it? We do what we did in the beginning: we create web pages with hyperlinks to deep web content.
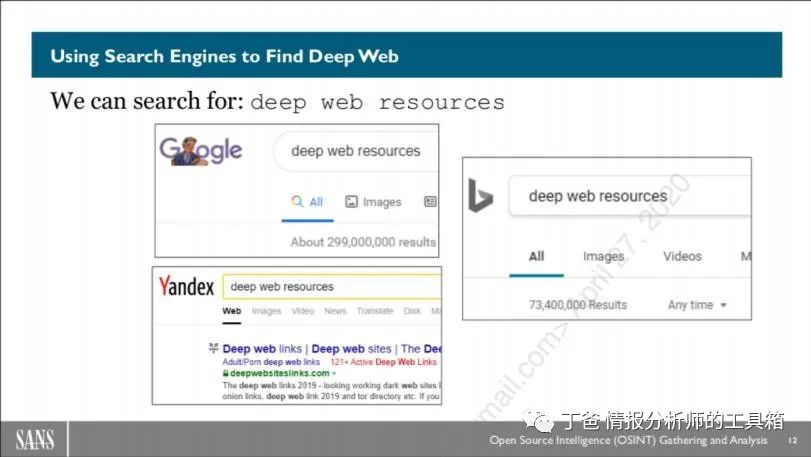
Using Search Engines to Find the Depth of Us
Using Google, Yandex, and Bing search engines, we search the string “deep web resources” and find tens of millions of possible pages that may list web pages for you to access. Where do you start? It depends on what your purpose is for entering the deep web. Just browsing? Choose any of the most popular sites and start browsing. If you want something specific, you may need to dig deeper.
Generating Sites and Good Links So, what we need to do now is visit the top sites from those results, each with hundreds of overlapping resources. Sounds like a waste of precious time, doesn’t it?
Researching the deep web from an OSINT perspective is often one of the focuses of research. We know what data we want, and we know there must be a source that can give us that data. Verifying a healthcare worker’s credentials is a great example. During an assessment, we got a name of a person and were told she was a retired healthcare worker. We needed to verify that statement (and others) for our client. So, we accessed the deep web to search for US medical license registries, entered the target’s data, and ultimately found her information. The OSINT community is very good at helping each other. This slide points out four different sites that contain excellent, curated, organized pages linking to deep web resources that you can use in your OSINT work.
-
Dark Web

Warning!! The dark web contains illegal, unethical, and disturbing content! Before using it, ensure that you and your organization are aware of the risks involved.

Risks of the Dark Web to Know
At almost any time you use the dark web, you may see and hear some unpleasant or unsuitable for work videos that should raise concerns. Plan ahead and ensure you are in a safe place where you can control who can see and hear what’s on your computer screen. We know of an investigator who worked from home through the dark web. The content of that work was very disturbing, but it was crucial for her case. She took precautions to only view the content in her home office and wore headphones. One day, while she was working, her young son accidentally walked into the room and saw a video she was watching. Because she had headphones on, she was unaware of him behind her for several minutes, by which time he had already seen a lot of what was on her screen.
Be Aware of Your Surroundings.
We know there are malicious people on the dark web. Before venturing into the dark web, ensure your computer systems and applications (like web browsers) are hardened, patched, and running the latest security software. Attackers on the dark web may embed malware in the files they offer for download, attacking your computer browser and operating system or trying to identify you or your organization. Be vigilant and protect yourself, your computer, and your organization.
If your assessment leads you into those parts of the dark web, you may see child pornography; ensure your team has a plan for how to handle it. In many countries, you may be legally required to report child sexual exploitation material.

Can Your Organization Use the Dark Web?
While many managers support their employees conducting OSINT investigations where needed to achieve results, these managers may not have the authority to give you that flexibility.
Before working in the dark web for your company, organization, and clients, ensure you have written approval from someone in authority about where and what systems you can work with.
Being aware of this information in advance helps prevent legal and ethical issues later.

Welcome to the Dark Web!
We have finally succeeded.
There are a few things to note about the dark web. First, as mentioned earlier, the dark web is an overlay network that sends and receives data over the regular internet. So, when we use the dark web, we are also using the internet. Second, while there are various different dark networks, “we will focus on the three most well-known networks: Freenet, I2P (Invisible Internet Project), and Tor.”
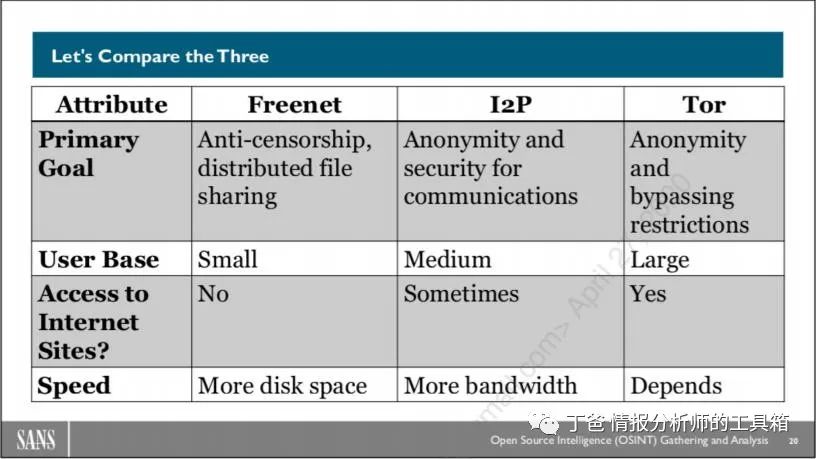
Let’s Compare The Three
Comparing the three dark web networks is a challenge because they are distinctly different. We will examine the networks from three angles: the primary goal of the network, how large its user base is, and whether it allows access to internet network resources.
Each overlay network has different primary goals. For Freenet, it is a distributed file-sharing network that breaks files into fragments and disperses those fragments across the network in retrievable parts. This makes it impossible to delete content uploaded to Freenet.
I2P uses a series of temporary, one-way encrypted tunnels to transmit data from one system to another. Its goal is to protect the data traversing its network and make it challenging to trace data back to a single source through network traffic analysis techniques.
Tor proxies network traffic across multiple systems to access internet sites (as well as its own onion services) anonymously. User data hops from one computer to another until it reaches its destination. The target site does not know where the original request came from, thus the user’s computer is anonymous.
When looking at the estimated user numbers for each network, note that Freenet has the smallest user base, Tor has the largest user base, and I2P is in the middle. These are rough estimates (as we will see), as accurately reading the number of users traversing anonymous networks becomes quite a challenge.
Freenet and I2P are largely closed networks where you can only access resources on those networks and not the internet. Tor allows access to resources found only on its network and allows anonymous browsing of internet resources.
We will learn that these networks are much more complex in the following chapters.
-
Freenet

The First Network: Freenet
You can think of the Freenet project (https://freenetproject.org/) as a large storage device where the content is distributed across all computers (nodes) in the network. Each person’s computer has a local data store containing encrypted fragments of popular files that can be shared with other nodes on the network. When you upload a file to Freenet, it is broken down into fragments, encrypted, and then distributed to peer nodes (the computers closest to your computer on the network). The upload program is provided with a key to retrieve that file. They can provide this key to others on Freenet, who can also retrieve that file.

About Freenet Storage
All nodes in Freenet share Freenet data fragments. As each file is split into chunks and distributed to other nodes, each node can have content from any file. You can choose to set, increase, or decrease the amount of encrypted storage on your hard drive that you are willing to donate to Freenet within its settings.
Note that if someone uploads confidential or sensitive data to Freenet, that data will be encrypted and distributed to peer nodes. Your computer may store that content, but you may never know it. That’s the power of Freenet. No user knows what data their system contains; thus, they cannot delete content in Freenet, and authorities cannot shut down Freenet by deleting some nodes.
If content is popular on Freenet, it can spread indefinitely among nodes, moving from one node to another as people request resources.

Two Modes of Freenet
When you start using Freenet, you will likely want to use it in the low-security opennet mode, where Freenet will automatically connect to seed nodes (computers it knows about at installation) and then begin connecting to other random nodes over time. This is less secure than dark web mode because you do not know who the other nodes your system is connecting to are. Opennet has two sub-modes: low security (default) and normal.
If you are using the open network mode, consider switching to normal mode to increase your anonymity. As you use Freenet more or your friends begin using Freenet, you can change the opennet mode to darknet mode by specifying to connect only to friends’ nodes in your Freenet settings. Since you may know those people, your level of trust will increase, and using Freenet will be safer. The dark web also has two settings: high and maximum mode.
Accessing Freenet
Accessing Freenet is done by downloading the software from freenetproject.org. The site has versions for macOS, Windows, and Linux systems. The installation program is very nice and is wizard-driven, asking users questions and providing suggestions for setting up the initial configuration.

Freenet Keys
When content is configured/uploaded to Freenet, it is assigned a key. When Freenet is installed on a computer, it installs FProxy, which is used to configure and access Freenet through a web interface.
In a web browser, you can access http://127.0.0.1:8888/[key], as shown in the slide above.
There are four types of keys in Freenet:
CHK – Content Hash Key applies to static content files, like .mp3 or pdf documents. These keys are hashes of the file content.
SSK – Signed Subspace Key is typically used for sites that change over time. For example, a site that may need to update news or correct, add, or remove information.
USK – Updatable Subspace Key is useful for linking to the latest version of a signed subspace key (SSK) site. Note that USKs are essentially just a friendly wrapper for SSKs that hides the process of searching for the latest version of a site.
KSK – Keyword Signed Key (KSK) allows you to save specific pages in Freenet.

“Browsing” Freenet
When you access websites using Freenet, it provides them to your browser in a way that is slightly different from how you do it on the internet. You request a resource through FProxy, which finds the fragments of that content on Freenet, requests and downloads them, and then reassembles them so they can be displayed in your browser. This takes time and makes Freenet a high-latency network.
Of course, if the content you want has already been downloaded to your computer, viewing that content is fast because FProxy retrieves it from local cache. The longer your computer spends on Freenet and the more data you allow Freenet to host on your system, the faster your browsing speed will be.

Browsing Default Bookmarks
Where do you start browsing content on Freenet? Start Freenet, then access FProxy in your browser at http://127.0.0.1:8888. From there, access the