
From: May’s Cangjie
Cause
During the 6.1 major promotion, a problem was discovered during duty hours: an RPC interface showed high response time (RT) during the peak order placement time from 0 to 2 AM (over 1s, even though this interface was optimized, an RT over this value is problematic; typically, even complex logic in an RPC interface should be resolved within 300ms). This is understandable, but at 4 to 5 AM, when the TPS of the interface was not high, the response time remained between 600ms and 700ms, which is puzzling.
Upon investigation, it was found that there was a segment of logic calling the Alipay HTTP interface, but a new HttpClient was created for each call, which took about 300ms+, resulting in high response times even during non-peak hours.
The problem is not difficult; I will write an article to systematically summarize this area.
The Difference Between Using and Not Using a Thread Pool
This article mainly discusses the impact of “pools” on system performance. Therefore, before discussing connection pools, we can start with an example of thread pools to illustrate the difference in effects when using a pool. The code is as follows:
/** * Thread Pool Test * * @author May's Cangjie https://www.cnblogs.com/xrq730/p/10963689.html */public class ThreadPoolTest { private static final AtomicInteger FINISH_COUNT = new AtomicInteger(0); private static final AtomicLong COST = new AtomicLong(0); private static final Integer INCREASE_COUNT = 1000000; private static final Integer TASK_COUNT = 1000; @Test public void testRunWithoutThreadPool() { List<Thread> tList = new ArrayList<Thread>(TASK_COUNT); for (int i = 0; i < TASK_COUNT; i++) { tList.add(new Thread(new IncreaseThread())); } for (Thread t : tList) { t.start(); } for (;;); } @Test public void testRunWithThreadPool() { ThreadPoolExecutor executor = new ThreadPoolExecutor(100, 100, 0, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>()); for (int i = 0; i < TASK_COUNT; i++) { executor.submit(new IncreaseThread()); } for (;;); } private class IncreaseThread implements Runnable { @Override public void run() { long startTime = System.currentTimeMillis(); AtomicInteger counter = new AtomicInteger(0); for (int i = 0; i < INCREASE_COUNT; i++) { counter.incrementAndGet(); } // Accumulate execution time COST.addAndGet(System.currentTimeMillis() - startTime); if (FINISH_COUNT.incrementAndGet() == TASK_COUNT) { System.out.println("cost: " + COST.get() + "ms"); } } }}The logic is quite simple: 1000 tasks, each task increments an AtomicInteger from 0 to 1 million.
Each Test method runs 12 times, excluding one lowest and one highest, averaging the middle 10 results. When not using a thread pool, the total task time was 16693s; when using a thread pool, the average task execution time was 1073s, over 15 times faster, with a very obvious difference.
The reasons are quite simple, as everyone knows, mainly two points:
-
Reduce the overhead of thread creation and destruction
-
Control the number of threads to avoid creating a thread for each task, which could lead to a surge in memory usage or even exhaustion
Of course, as mentioned earlier, this is just an introduction leading into this article. When we use an HTTP connection pool, the reasons for improved task processing efficiency are not limited to this.
Which HttpClient to Use
A common point of confusion, please pay special attention. There are two similar packages for HttpClient: one is commons-httpclient:
<dependency> <groupId>commons-httpclient</groupId> <artifactId>commons-httpclient</artifactId> <version>3.1</version></dependency>The other is httpclient:
<dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.8</version></dependency>Choose the second one, do not get it wrong. Their differences are explained on StackOverflow:

That is, commons-httpclient is an older version of HttpClient, up to version 3.1, after which the project was abandoned and no longer updated (version 3.1 was released on August 21, 2007). It has been incorporated into a larger Apache HttpComponents project, with the version number HttpClient 4.x (4.5.8 being the latest version, released on May 30, 2019).
With continuous updates, the HttpClient has ongoing optimizations regarding code details and performance, so remember to choose org.apache.httpcomponents as the groupId.
Performance Without Connection Pool
With the utility class, we can write code to validate. First, define a base test class that can be reused when demonstrating the code with a connection pool:
/** * Connection Pool Base Class * * @author May's Cangjie https://www.cnblogs.com/xrq730/p/10963689.html */public class BaseHttpClientTest { protected static final int REQUEST_COUNT = 5; protected static final String SEPARATOR = " "; protected static final AtomicInteger NOW_COUNT = new AtomicInteger(0); protected static final StringBuilder EVERY_REQ_COST = new StringBuilder(200); /** * Get threads to run */ protected List<Thread> getRunThreads(Runnable runnable) { List<Thread> tList = new ArrayList<Thread>(REQUEST_COUNT); for (int i = 0; i < REQUEST_COUNT; i++) { tList.add(new Thread(runnable)); } return tList; } /** * Start all threads */ protected void startUpAllThreads(List<Thread> tList) { for (Thread t : tList) { t.start(); // Add a slight delay here to ensure requests are sent in order try { Thread.sleep(300); } catch (InterruptedException e) { e.printStackTrace(); } } } protected synchronized void addCost(long cost) { EVERY_REQ_COST.append(cost); EVERY_REQ_COST.append("ms"); EVERY_REQ_COST.append(SEPARATOR); }}Next, let’s look at the test code:
/** * Test Without Connection Pool * * @author May's Cangjie https://www.cnblogs.com/xrq730/p/10963689.html */public class HttpClientWithoutPoolTest extends BaseHttpClientTest { @Test public void test() throws Exception { startUpAllThreads(getRunThreads(new HttpThread())); // Wait for threads to run for (;;); } private class HttpThread implements Runnable { @Override public void run() { /** * HttpClient is thread-safe, so it should be a global variable. However, if it is shared globally, a connection pool will be created internally during HttpClient initialization. * Thus, it cannot reflect the effect of using a connection pool, so here we create a new HttpClient each time to ensure requests are not made through the connection pool. */ CloseableHttpClient httpClient = HttpClients.custom().build(); HttpGet httpGet = new HttpGet("https://www.baidu.com/"); long startTime = System.currentTimeMillis(); try { CloseableHttpResponse response = httpClient.execute(httpGet); if (response != null) { response.close(); } } catch (Exception e) { e.printStackTrace(); } finally { addCost(System.currentTimeMillis() - startTime); if (NOW_COUNT.incrementAndGet() == REQUEST_COUNT) { System.out.println(EVERY_REQ_COST.toString()); } } } }}Note that, as mentioned in the comments, HttpClient is thread-safe, but once it is made global, it loses the testing effect because HttpClient will create a connection pool during initialization.
Let’s look at the execution results of the code:
324ms 324ms 220ms 324ms 324msEach request is almost independent, so the execution time is all above 200ms. Next, let’s see the effect of using a connection pool.
Results of Using a Connection Pool
The BaseHttpClientTest class remains unchanged; let’s write a test class that uses a connection pool:
/** * Test Using Connection Pool * * @author May's Cangjie https://www.cnblogs.com/xrq730/p/10963689.html */public class HttpclientWithPoolTest extends BaseHttpClientTest { private CloseableHttpClient httpClient = null; @Before public void before() { initHttpClient(); } @Test public void test() throws Exception { startUpAllThreads(getRunThreads(new HttpThread())); // Wait for threads to run for (;;); } private class HttpThread implements Runnable { @Override public void run() { HttpGet httpGet = new HttpGet("https://www.baidu.com/"); // Long connection identifier; it doesn't matter if not added, HTTP1.1 defaults to Connection: keep-alive httpGet.addHeader("Connection", "keep-alive"); long startTime = System.currentTimeMillis(); try { CloseableHttpResponse response = httpClient.execute(httpGet); if (response != null) { response.close(); } } catch (Exception e) { e.printStackTrace(); } finally { addCost(System.currentTimeMillis() - startTime); if (NOW_COUNT.incrementAndGet() == REQUEST_COUNT) { System.out.println(EVERY_REQ_COST.toString()); } } } } private void initHttpClient() { PoolingHttpClientConnectionManager connectionManager = new PoolingHttpClientConnectionManager(); // Total connection pool count connectionManager.setMaxTotal(1); // Set a separate connection pool count for each domain name connectionManager.setMaxPerRoute(new HttpRoute(new HttpHost("www.baidu.com")), 1); // setConnectTimeout sets the connection establishment timeout // setConnectionRequestTimeout sets the timeout for waiting to get a connection from the pool // setSocketTimeout sets the timeout for waiting for a response after sending a request RequestConfig requestConfig = RequestConfig.custom().setConnectTimeout(1000).setConnectionRequestTimeout(2000).setSocketTimeout(3000).build(); // Retry handler; StandardHttpRequestRetryHandler is provided by the official; it seems a bit inadequate as it cannot retry many errors; you can implement the HttpRequestRetryHandler interface yourself HttpRequestRetryHandler retryHandler = new StandardHttpRequestRetryHandler(); httpClient = HttpClients.custom().setConnectionManager(connectionManager).setDefaultRequestConfig(requestConfig).setRetryHandler(retryHandler).build(); // If the server has assumed the connection is closed, it is opaque to the client; to alleviate this issue, HttpClient will check whether a connection is expired before using it; if it is expired, the connection is invalidated. However, this approach adds some additional overhead for each request. Therefore, there is a scheduled task specifically for reclaiming long-inactive connections that are deemed expired, which can somewhat alleviate this issue. Timer timer = new Timer(); timer.schedule(new TimerTask() { @Override public void run() { try { // Close expired connections and remove them from the connection pool connectionManager.closeExpiredConnections(); // Close idle connections that have not been active for 30 seconds and remove them from the connection pool; the idle time starts from when it is returned to the connection manager connectionManager.closeIdleConnections(20, TimeUnit.SECONDS); } catch (Throwable t) { t.printStackTrace(); } } }, 0 , 1000 * 5); }}This class illustrates the usage of HttpClient in detail, with relevant notes written in the comments, so I won’t elaborate further.
As before, let’s look at the execution results of the code:
309ms 83ms 57ms 53ms 46msExcept for the first call of 309ms, the overall execution time of the subsequent four calls greatly improved, which demonstrates the benefits of using a connection pool. Next, let’s explore the reasons for the overall performance improvement when using a connection pool.
Unavoidable Long and Short Connections
When talking about HTTP, one cannot avoid the topic of long and short connections, which has been discussed many times in previous articles, and I will write it again here.
We know that there are several steps from the client initiating an HTTP request to the server responding:
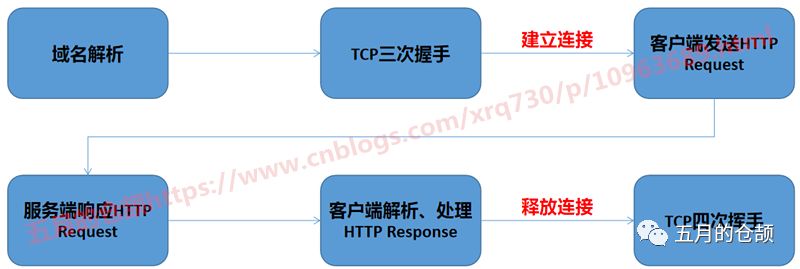
HTTP 1.0 was first used in web pages in 1996, at that time only simple web and network requests were made, each request required establishing a separate connection, with the previous and next requests being completely separate. This approach, even with a small amount of requests each time, incurs a relatively time-consuming process of establishing and closing TCP connections each time, severely impacting performance for both the client and server.
To address this issue, HTTP 1.1 was widely adopted in 1999 in major browser network requests, and HTTP 1.1 is currently the most widely used HTTP protocol (HTTP 2 was born in 2015 but has not yet been widely adopted). Here, I won’t detail the comparisons between HTTP 1.1 and HTTP 1.0; I will only note that regarding connections, HTTP 1.1 supports sending multiple HTTP requests and responses over a single TCP connection, reducing the overhead of establishing and closing connections, which somewhat compensates for the shortcomings of HTTP 1.0 requiring a connection for each request. This is known as long connections, and HTTP 1.1 uses long connections by default.
So, how does a long connection work? First, we need to clarify that long and short connections are concepts at the communication layer (TCP), while HTTP is an application layer protocol. It can only indicate to the communication layer that it intends to reuse the TCP channel for a period of time without having the ability to establish or release the TCP channel itself. So how does HTTP inform the communication layer to reuse the TCP channel? Let’s take a look at the following diagram:

The steps are as follows:
-
The client sends a Connection: keep-alive header, indicating the need to maintain the connection
-
The client can also optionally send a Keep-Alive: timeout=5,max=100 header to the server, indicating that the TCP connection should be kept alive for a maximum of 5 seconds and can accept 100 requests before disconnecting. However, it seems that browsers do not often send this parameter with requests.
-
The server must recognize the Connection: keep-alive header and respond with the same Connection: keep-alive header to inform the client that it can maintain the connection
-
The client and server exchange data through the maintained channel
-
For the last request, the client sends a Connection: close header to indicate the connection should be closed
Thus, the process of exchanging data over a channel concludes. By default:
-
The maximum number of requests for a long connection is limited to 100 consecutive requests; exceeding this limit will close the connection
-
The timeout between two consecutive requests on a long connection is 15 seconds (with a 1-2 second error margin); after timing out, the TCP connection will be closed, so long connections should ideally maintain a request within 13 seconds.
These limits are a compromise between reusing long connections and excessive long connections, as although long connections are beneficial, prolonged TCP connections can lead to inefficient resource usage, wasting system resources.
Lastly, a quick note on the difference between HTTP keep-alive and TCP keep-alive, a common question worth recording:
-
HTTP keep-alive is for reusing existing connections
-
TCP keep-alive is for keeping alive, ensuring the other end is still alive. If the other end is no longer available, the connection is wasted on the server side. The method involves sending a heartbeat packet to the server at intervals, and if no response is received for a long time, the connection is proactively closed.
Reasons for Performance Improvement
From the previous analysis, it is evident that the most important reason for using an HTTP connection pool to improve performance is the significant reduction in time spent establishing and releasing connections. In addition, I would like to mention one more point.
When TCP establishes a connection, the following process occurs:
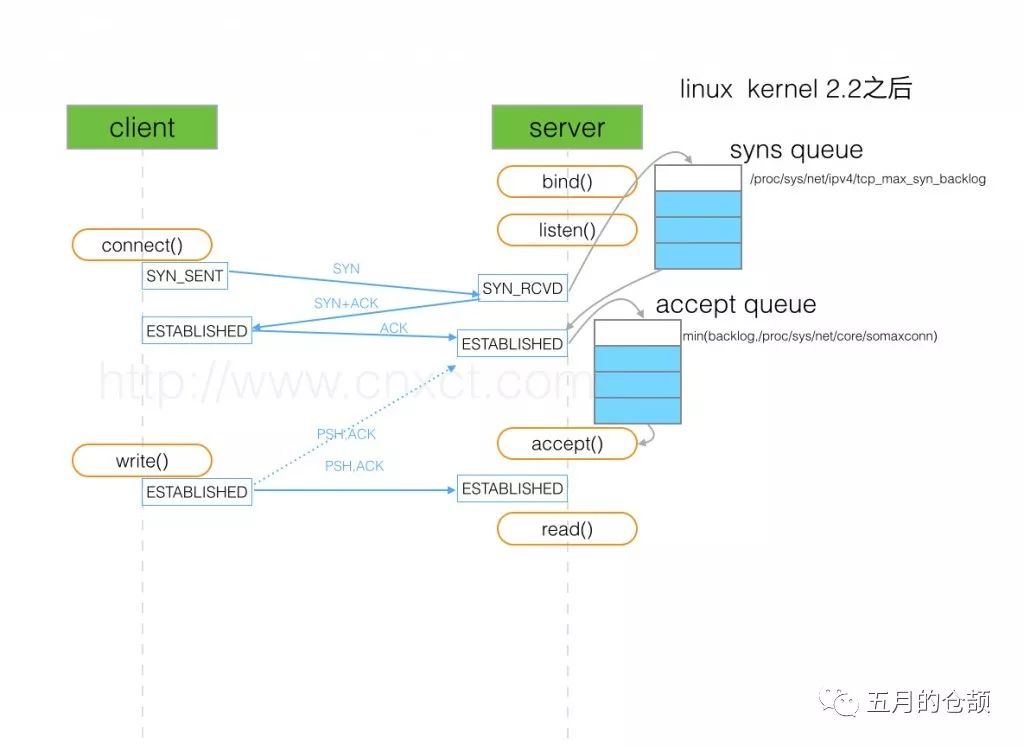
As shown, there are two queues involved, the syns queue (half-connection queue) and the accept queue (full connection queue). I won’t go into detail about this process; I previously wrote an article on this topic here: https://www.cnblogs.com/xrq730/p/6910719.html.
If long connections are not used and each connection is re-established, once the queue is full, the server will send an ECONNREFUSED error message to the client, effectively invalidating that request. Even if it does not invalidate, subsequent requests will have to wait for previous requests to be processed, increasing response time due to queuing.
By the way, based on the analysis above, not only HTTP but all application layer protocols, such as databases with database connection pools, and HSF providing HSF interface connection pools, all benefit significantly from the use of connection pools, following the same principle.
TLS Layer Optimization
The above discussion pertains to the reasons for performance improvement through connection pools at the application layer protocol level. However, for HTTP requests, we know that most websites currently operate over HTTPS, which adds a layer of TLS between the communication and application layers:
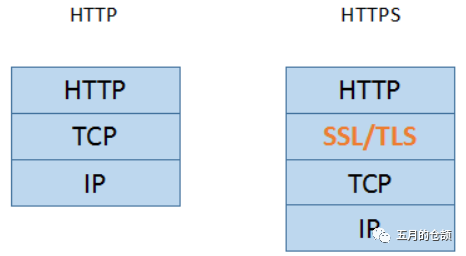
By encrypting messages at the TLS layer, data security is ensured. In fact, at the HTTPS level, using connection pools also enhances performance, and TLS layer optimization is a crucial reason for this.
The principles of HTTPS won’t be detailed here; essentially, it involves a certificate exchange –> server encryption –> client decryption process. Throughout this process, repeatedly exchanging data between client and server is time-consuming, and the encryption and decryption of data is computationally intensive, consuming CPU resources. Therefore, if identical requests can skip the encryption and decryption process, it can significantly enhance performance under the HTTPS protocol. In practice, this optimization exists and utilizes a technique called session reuse.
The TLS handshake begins with the client sending a Client Hello message, and the server returns a Server Hello to conclude. This process provides two different session reuse mechanisms, which we will briefly look at:
-
Session ID reuse —- For established TLS sessions, the session ID serves as the key (from the session ID in the first request’s Server Hello), with the main key as the value, forming a key-value pair stored locally on both the server and client. When the second handshake occurs, if the client wishes to reuse the session, it sends the session ID in the Client Hello. The server checks locally for this session ID; if found, it allows session reuse and proceeds with subsequent operations.
-
Session Ticket reuse —- A session ticket is an encrypted data blob that contains the TLS connection information to be reused, such as session keys, etc. It is generally encrypted using a ticket key known to the server. During the initial handshake, the server sends a session ticket to the client, which is stored locally. When reusing the session, the client sends the session ticket to the server, and if the server successfully decrypts it, the session can be reused.
The session ID method has obvious drawbacks, primarily because of synchronization issues between multiple machines in load balancing; if two requests do not land on the same machine, the matching information cannot be found. Additionally, storing a large number of session IDs on the server consumes resources. The session ticket method resolves this issue more effectively, but which method is ultimately used is still determined by the browser. Regarding session tickets, I found a diagram online that illustrates the process of a client sending a request with a session ticket:
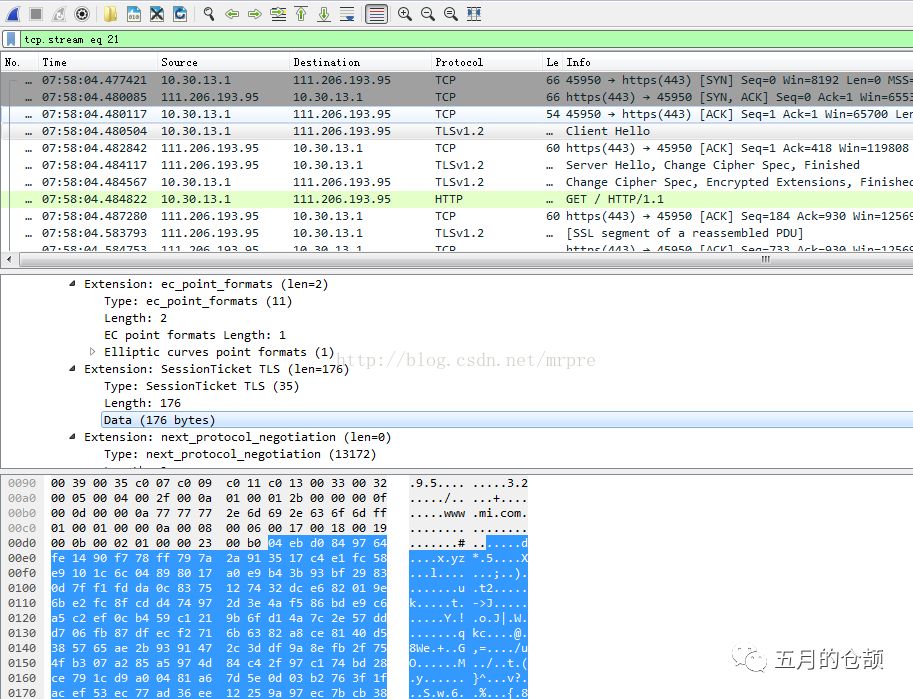
A session ticket has a default timeout of 300 seconds. The TLS layer’s certificate exchange and asymmetric encryption are significant performance drains, and session reuse technology can greatly enhance performance.
Points to Note When Using Connection Pools
When using connection pools, be sure to keep the execution time of each task short.
Because whether it’s an HTTP request, a database request, or an HSF request, there are timeout settings. For example, if there are 10 threads in the connection pool and 100 requests come in concurrently, if the task execution time is very long, the connections will be occupied by the first 10 tasks, and the remaining 90 requests will wait too long to get a connection, leading to slow responses or even timeouts for these requests.
Of course, the execution time of each task varies, but based on my experience, try to keep the task execution time within 50 to 100 ms at most. If it exceeds this, consider one of the following three solutions:
-
Optimize task execution logic, such as introducing caching
-
Appropriately increase the number of connections in the connection pool
-
Split tasks into several smaller tasks
How to Set the Number of Connections in the Connection Pool
Some friends might ask, I know I need to use a connection pool, so how many connections should I generally set in the pool? Is there an empirical value? First, we need to clarify that having too many connections in the pool is not good, nor is having too few:
-
For example, if qps=100, because the upstream request rate cannot remain constant at 100 requests/second, it might be 900 requests in the first second and 100 requests in the next 9 seconds, averaging qps=100, when there are too many connections, the scenario may occur where high traffic establishes connections —> low traffic releases some connections —> high traffic re-establishes connections, which means that although a connection pool is used, the connections are repeatedly established and released due to uneven traffic.
-
Having too few threads is also not good; if there are many tasks and few connections, it will lead to many tasks waiting in line until the previous ones finish before they can get a connection to handle, slowing down processing speed.
So regarding how to set the number of connections in the connection pool, the answer is that there is no fixed number, but an estimated value can be derived.
First, developers should have a rough idea of the daily call volume for a task. Suppose there are 10 million calls per day; then with 10 servers online, the average daily call volume per server is 1 million. Averaging this over a day of 86400 seconds, the average call volume is approximately 1000000 / 86400 ≈ 11.574 times, and with a little extra margin based on the average response time for the interface, setting it around 15 to 30 is generally appropriate, adjusting based on actual online performance.
Long press to subscribe for more exciting content ▼

If you found this helpful, please give a thumbs up; I sincerely appreciate it.