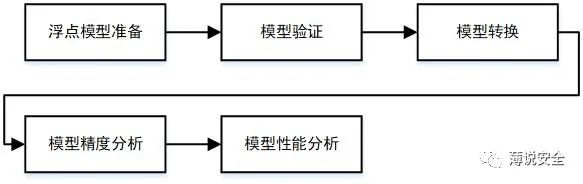
Deploying an AI algorithm model onto an embedded system allows it to run on the board and implement algorithms such as object detection, classification, etc. The entire development process requires support from the AI development toolchain. This article discusses the series of toolchains used in AI development before deployment, taking the Horizon Open Explorer toolchain as an example.
-
Preparing Floating Point Models:
The floating point models come from various publicly available deep learning training frameworks, the most commonly used DL training frameworks include:
| DL Framework | Link | |
| TensorFlow | Google’s open-source AI framework for machine learning and high-performance numerical computation. It is a Python library that calls C++ to build and execute data flows. It supports various classification and regression algorithms, deep learning, and neural networks. One of TensorFlow’s biggest advantages is its simplification and abstraction, which keeps the code concise and improves development efficiency. | www.tensorflow.org |
| Scikit-learn |
Scikit-learn is an open-source AI library that is commercially usable and also a Python library. It supports supervised and unsupervised machine learning, including classification, regression, clustering, dimensionality reduction, model selection, and preprocessing. Scikit-learn is built on top of NumPy, Matplotlib, and SciPy libraries. Scikit-learn is positioned as a “simple and efficient tool for data mining and data analysis, accessible and reusable in various environments.” |
www.scikit-learn.org/stable |
| Caffe | Caffe is a deep learning framework that considers expression, speed, and modularity. It was developed by the Berkeley AI Research (BAIR) and community contributors. Its flexible architecture encourages applications and innovations, while the extensible code promotes proactive development, making Caffe suitable for research experiments and industry deployment. | caffe.berkeleyvision.org |
| Keras |
Keras is a high-level neural network API that can run on TensorFlow, Microsoft Cognitive Toolkit, or Theano. This Python DL library helps in rapid experimentation and claims to “convert ideas into results with minimal delay, which is key to good research.” Keras is not an end-to-end machine learning framework but operates as a user-friendly, easily extensible interface that supports modularity and full expressiveness. Independent modules (such as neural layers, loss functions, etc.) can be combined with almost no restrictions, and new modules can be added easily. With a consistent and simple API, it minimizes user operations in common use cases. It can run on CPUs or GPUs. |
www.keras.io |
| Microsoft Cognitive Toolkit |
Previously known as Microsoft CNTK, the Microsoft Cognitive Toolkit is an open-source deep learning library designed to support powerful commercial-grade datasets and algorithms. With well-known clients such as Skype, Cortana, and Bing, Microsoft Cognitive Toolkit offers efficient scalability from a single CPU to GPUs and multiple machines without sacrificing quality, speed, and accuracy. Microsoft Cognitive Toolkit supports C++, Python, C#, and BrainScript. |
docs.microsoft.com/en-us/cognitive-toolkit/ |
| PyTorch |
PyTorch is an open-source machine learning Python library mainly developed by Facebook’s AI research team. PyTorch supports CPU and GPU computation, providing scalable distributed training and performance optimization in both research and production. Its two high-level features include tensor computation with GPU acceleration (similar to NumPy) and a taped-based autodiff system for building deep neural networks. |
www.pytorch.org |
| Torch |
Similar to PyTorch, Torch is a tensor library similar to NumPy and also supports GPU. Unlike PyTorch, Torch is wrapped in LuaJIT, with a lower-level C/CUDA implementation. As a scientific computing framework, Torch prioritizes speed, flexibility, and simplicity when building algorithms. Through popular neural network and optimization libraries, Torch provides users with easy-to-use libraries while allowing flexible implementation of complex neural network topologies. |
www.torch.ch |
| MXNet | An open-source DL framework for training and deploying deep neural networks, featuring scalability, allowing rapid model training, and supporting flexible programming models and multiple languages. | mxnet.apache.org |
The floating point models trained based on publicly available DL frameworks serve as input for model conversion tools. Among the above frameworks, the Caffe-exported caffemodel is directly supported; PyTorch, TensorFlow, and MXNet are indirectly supported through conversion to ONNX.
ONNX is a development-oriented file format designed for machine learning to store trained models. It allows different DL frameworks to use the same format to store model data, facilitating model migration between mainstream DL frameworks.
2. Model Validation
To run efficiently on embedded platforms, the operators used in the model must comply with the platform’s operator constraints. Taking the Horizon platform as an example, specific parameter constraints for each operator are provided in the supported_op_list_and_restrictions_release.

Caffe operator constraints (example)
To avoid the hassle of manually checking each item, Horizon provides the hb_mapper_checker tool to verify the support status of the operators used in the model. The hb_mapper_checker tool checks results where each row represents the check status of a model node, containing four columns: Node, ON, Subgraph, and Type, which represent the node name, hardware executing the node’s computation, the subgraph to which the node belongs, and the internal implementation name mapped to Horizon.
3. Model Conversion
Model quantization conversion is a performance optimization technique for deep neural networks. The models obtained from the previously prepared floating point training frameworks are generally float32. Deploying such models on embedded platforms may not match the platform’s storage space and bus bandwidth. Therefore, by reducing the precision of weights and activations, the storage and computation can be minimized, converting them to fixed-point models, such as int8.
The model quantization conversion in Horizon includes model parsing, model structure optimization, parameter fixed-point conversion, model instruction compilation, and optimization, ultimately generating a model that can be deployed on embedded platforms.
The quantized_model.onnx generated by model quantization converts the computational precision from float32 to int8, and finally, through the platform’s model compiler, the quantized model is converted into computation instructions and data supported by the platform, resulting in a bin model, which is the final output of the model conversion.
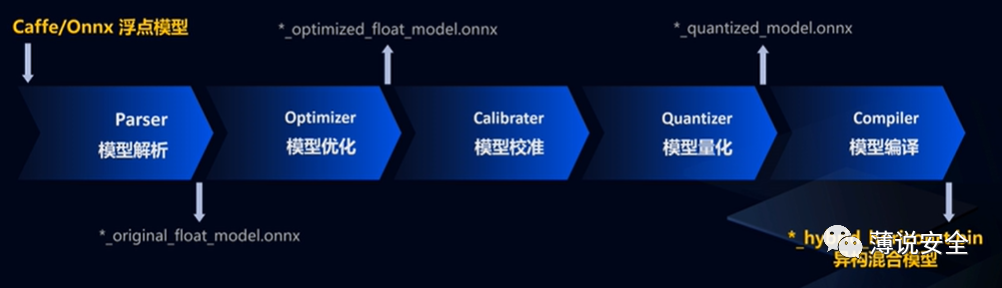
Model quantization conversion process
The Onnx model generated during the conversion process can be analyzed using the Netron visualization tool to view the optimization results of each conversion process.
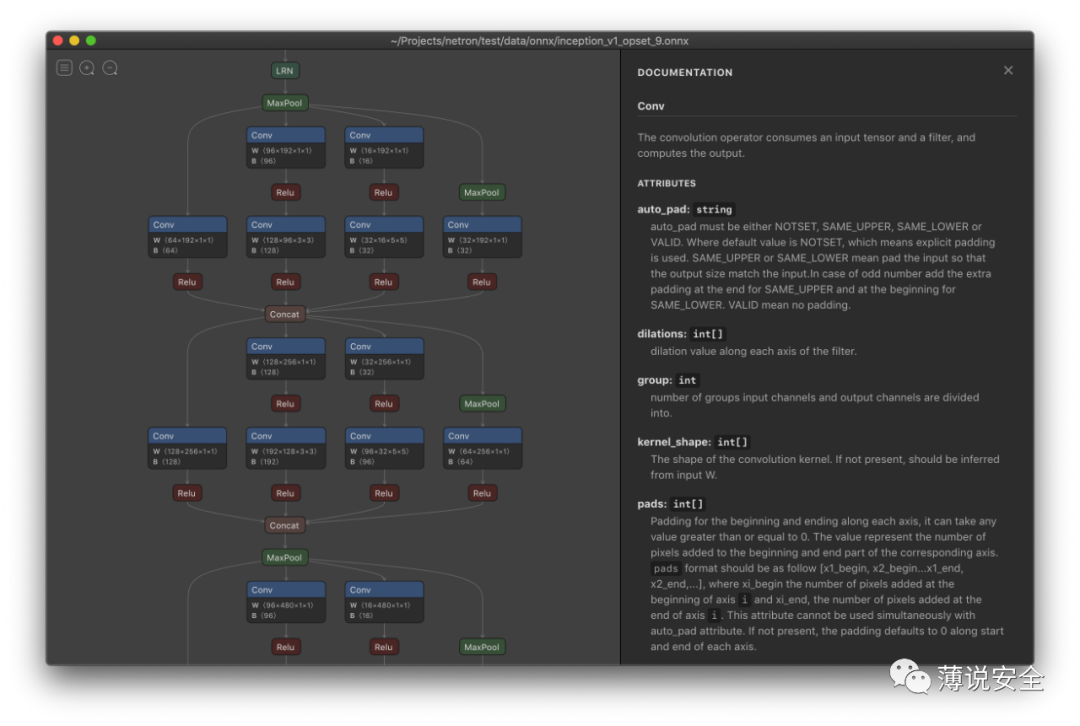
Netron visualization tool
4. Model Accuracy Analysis
The post-quantization method for converting floating point models to fixed point models based on calibration data may result in some accuracy loss, requiring analysis to ensure that the accuracy loss after conversion is within an acceptable range. According to the recommendations in the Horizon accuracy tuning user manual:
If there is a significant accuracy loss (greater than 4%): This issue is often caused by improper yaml configuration, unbalanced validation datasets, etc. It can be addressed by checking the pipeline, model conversion settings, and consistency.
If the accuracy loss is small (1.5%~3%): After eliminating the above issues causing significant accuracy deviations, if small accuracy losses still occur, it is often due to the model’s sensitivity. The vendor’s accuracy tuning tools can be used for adjustment.
If no configuration issues are found through the above analysis, but the accuracy still does not meet requirements, it may be a limitation of PTQ (Post-training Quantization). In this case, QAT (Quantization Aware Training) can be used for model quantization.
5. Model Performance Analysis
Model performance analysis consists of two steps: evaluation using development machine tools and actual performance evaluation on the board. On the development machine, Horizon uses the hb_perf tool with the bin file of the model conversion as input to directly obtain the expected functionality on the board. The overall metrics evaluated include:
-
Model Name — Model Name.
-
Model Latency (ms) — Total computation time per frame of the model (in ms).
-
Model DDR Occupation (Mb per frame) — Overall memory usage of the model (in Mb/frame).
-
Loaded Bytes per Frame — Data read per frame during model operation.
-
Stored Bytes per Frame — Data stored per frame during model operation.
In addition to overall metrics, there are also detailed metrics for model subgraphs:
-
Model Subgraph Name — Subgraph Name.
-
Model Subgraph Calculation Load (OPpf) — Calculation load per frame of the subgraph.
-
Model Subgraph DDR Occupation (Mbpf) — Read/write data volume per frame of the subgraph (in MB).
-
Model Subgraph Latency (ms) — Calculation time per frame of the subgraph (in ms).
On the development board, Horizon uses hrt_model_exec_perf as the evaluation tool to assess the model’s inference performance, gaining insights into the actual performance of the model.
The above describes the basic processes of model preparation, validation, quantization conversion, and model evaluation in embedded AI development. Successfully running the entire toolchain is fundamental to AI development. Compared to traditional software development tools, the debugging, target code generation, and testing processes in AI development are notably different. Moreover, the AI development toolchain is not as user-friendly as traditional software integrated compilation environments and requires a certain learning curve.
References: horizon_ai_toolchain_user_guide, Horizon Community