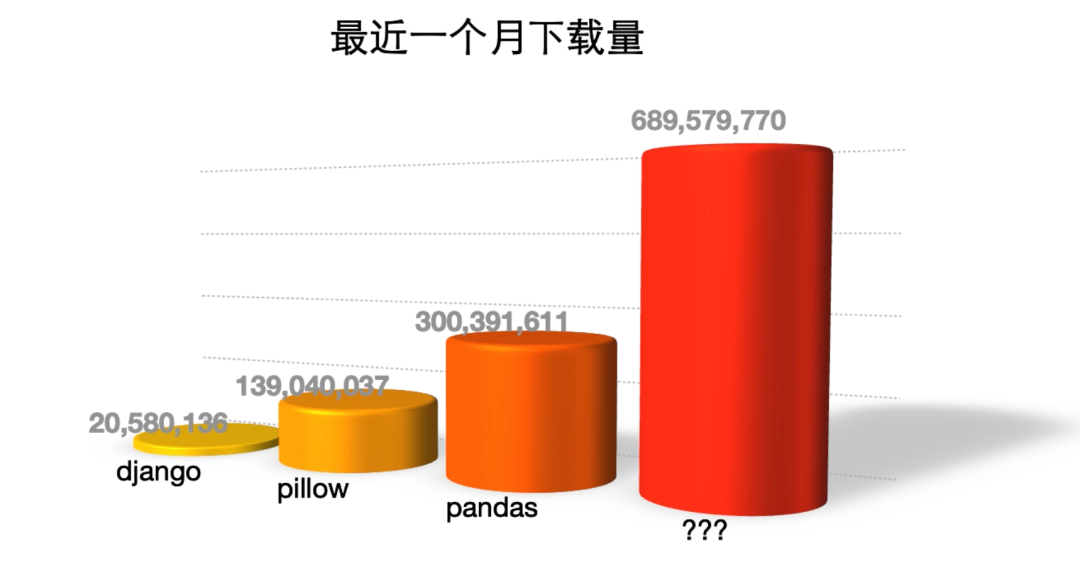
With over 600 million downloads in a month and more than 50,000 stars on GitHub, what project has such explosive data?


When it comes to Python third-party libraries, which one comes to your mind first? The data analysis library pandas? The image processing library pillow? Or using Django for web development? Sure, they are all impressive, but this library has an even larger download volume.
Follow the Programming Classroom to learn programming knowledge. Today, we will talk about this so-called “most user-friendly” HTTP library – requests.

What makes it user-friendly?
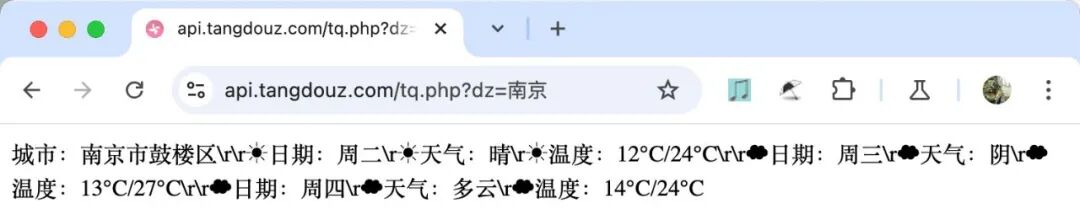
If you want to get the temperature changes of a city through a weather API, you can do it with requests in just two lines of code:
import requests
r = requests.get('http://api.tangdouz.com/tq.php?dz=南京')
print(r.text)Other common network request operations include:
Submitting a POST request with parameters

Modifying the webpage encoding (encoding)

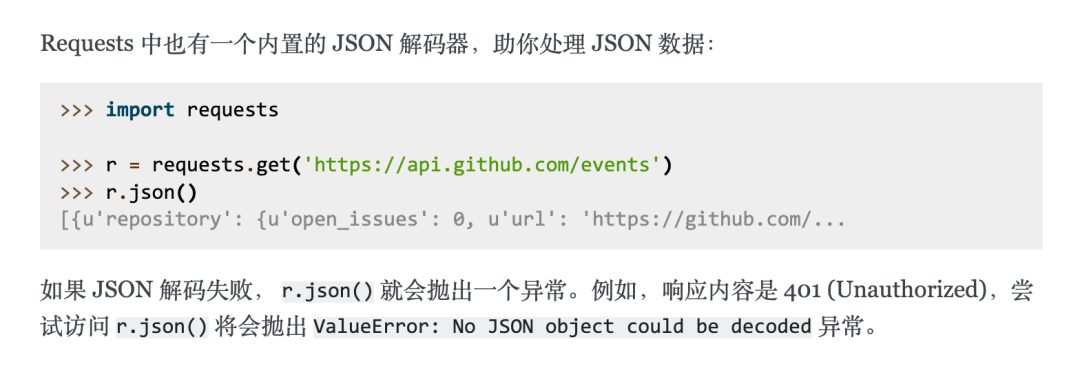
Decoding JSON data
Customizing request headers (headers)

Adding cookies

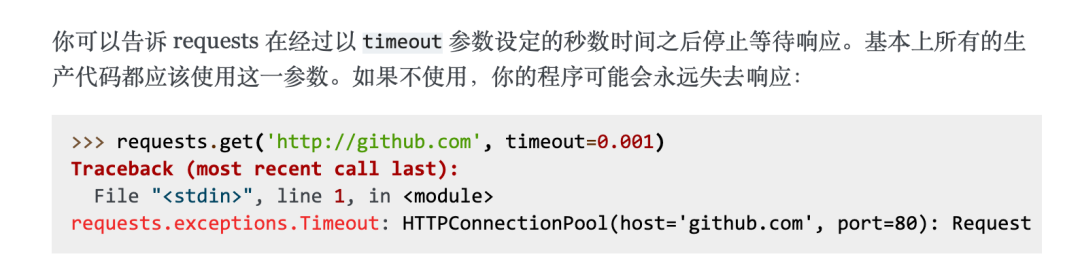
Setting request timeout (timeout)
All these operations can be easily accomplished in one or two lines of code using the attributes or methods provided by requests.
To get started, all you need to do is install it via pip and refer to the official documentation to understand how to use the module.
pip install requestsYou might wonder, can’t the built-in Python modules achieve this? Well, they can, but… it’s not as convenient.
For example, if I want to request a:
POST interface that restricts browser types and requires a set of parameters, with the return result encoded in UTF8 JSON format and also gzip compressed.
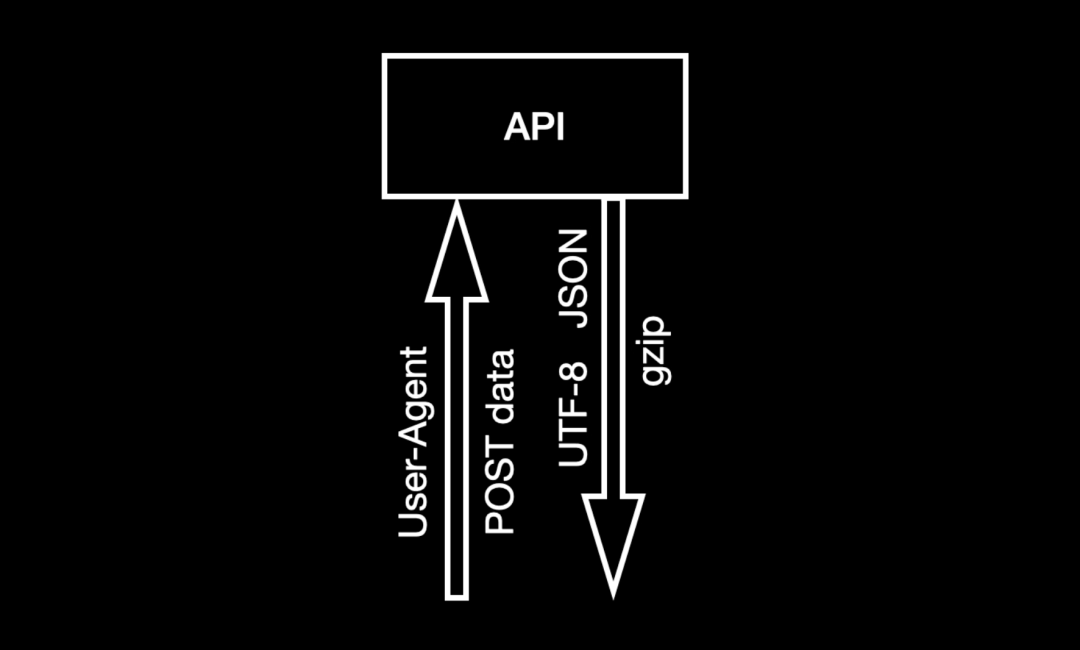
If I use Python’s default library, I need to handle each step manually, making the code quite cumbersome.
from urllib.request import Request, urlopen
from urllib.parse import urlencode
import gzip
import json
headers = {'User-Agent': 'Chrome'}
data = {'username': 'test_user', 'password': '123456'}
url = 'https://api.example.com/login'
# Encode request data
data_encoded = urlencode(data).encode('utf-8')
# Create request object, set request data, headers, and method
req = Request(url, data=data_encoded, headers=headers, method='POST')
# Send request
response = urlopen(req)
# Read return result
recv_data = response.read()
# Decompress return result if it's gzip encoded
if response.getheader("Content-Encoding") == "gzip":
recv_data = gzip.decompress(recv_data)
# Decode return result in UTF-8
json_string = recv_data.decode('utf-8')
# Parse return result as JSON
result = json.loads(json_string)
print(result)
# Close request
response.close()Switching to requests, you only need to provide dictionary-type headers and data parameters in the post function to set the request headers and data.As for the gzip decompression and UTF8 decoding of the return result, it will be handled automatically for you.If the encoding is not recognized, you can simply assign a value to make it run successfully.
Finally, use the json function to parse the result into a directly usable dictionary type. Developers save a lot of tedious work, and the amount of code is greatly reduced.
import requests
headers = {'User-Agent': 'Chrome'}
data = {'username': 'test_user', 'password': '123456'}
url = 'https://api.example.com/login'
# Set request data, headers, and send POST request
response = requests.post(url, headers=headers, data=data)
# Set encoding of return result
response.encoding = 'utf-8'
# Parse return result as JSON
result = response.json()
print(result)Not to mention, if you want to maintain the login state after logging in, the built-in library requires using http.cookiejar and urllib.request together, resulting in code like this:
from urllib.request import build_opener, HTTPCookieProcessor, Request
from urllib.parse import urlencode
import http.cookiejar
login_url = 'https://example.com/login'
login_data = {'username': 'test_user', 'password': '123456'}
headers = {'User-Agent': 'Chrome'}
data_encoded = urlencode(login_data).encode('utf-8')
# Create CookieJar and opener to manage session
cookie_jar = http.cookiejar.CookieJar()
opener = build_opener(HTTPCookieProcessor(cookie_jar))
# Use opener to send login request
login_request = Request(login_url, data=data_encoded, headers=headers, method='POST')
login_response = opener.open(login_request)
# Use the same opener to access the page after logging in
protected_url = 'https://example.com/profile'
profile_request = Request(protected_url, headers=headers, method='GET')
profile_response = opener.open(profile_request)
print(profile_response.read().decode('utf-8'))
login_response.close()
profile_response.close()With requests, it’s much simpler. Just add a Session object, and you can maintain the login state with almost no changes to the previous code.
import requests
login_url = 'https://example.com/login'
login_data = {'username': 'test_user', 'password': '123456'}
headers = {'User-Agent': 'Chrome'}
# Create Session object
session = requests.Session()
# Use Session to send login request
login_response = session.post(login_url, data=login_data, headers=headers)
# Use the same Session to access the page after logging in
protected_url = 'https://example.com/profile'
profile_response = session.get(protected_url, headers=headers)
print(profile_response.text)The difference between the two approaches is very clear.Once you have experience with requests, you open up a new world of network requests and never want to use the built-in urllib again.
Even major companies often use requests for network requests in their Python projects.After all, who wouldn’t want to use such a convenient module?
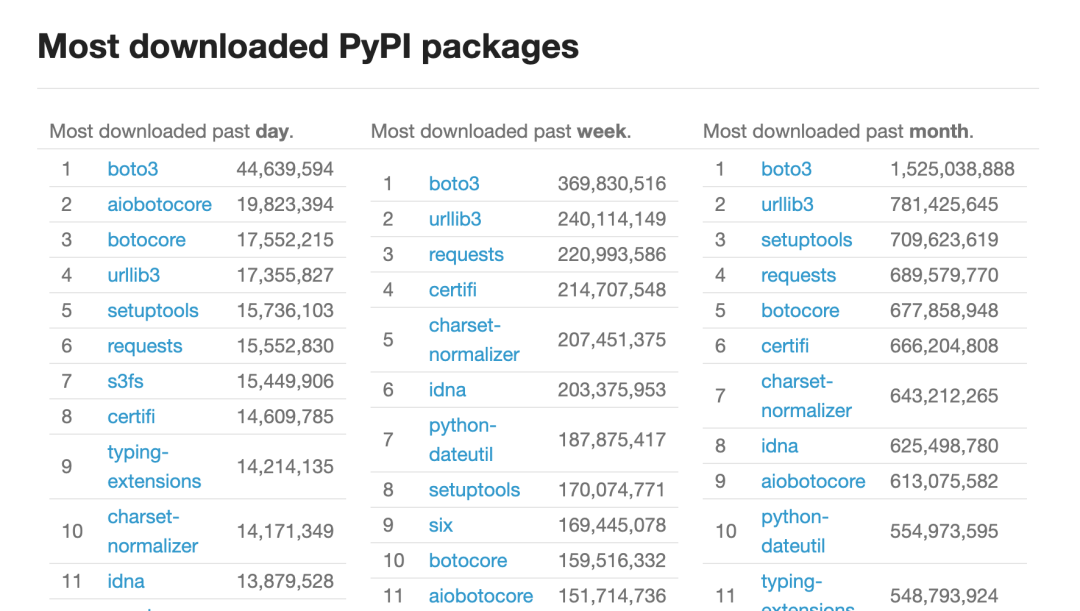
The widespread usage has kept requests at the top of the PyPI rankings.
This powerful library was initially just a personal project of a programmer. One afternoon in 2011, a guy named Kenneth, unable to tolerate Python’s built-in urllib library, decided to showcase his development skills by writing a truly user-friendly HTTP request library, not expecting it to become a crucial pillar of the Python ecosystem.
Speaking of Kenneth, he is also a highly talked-about figure in the tech community. Beyond software development, he is passionate about music and photography. His photos from different periods reveal that he must have a rich personal story. (See: This man has increased your web scraping development efficiency by 8 times)

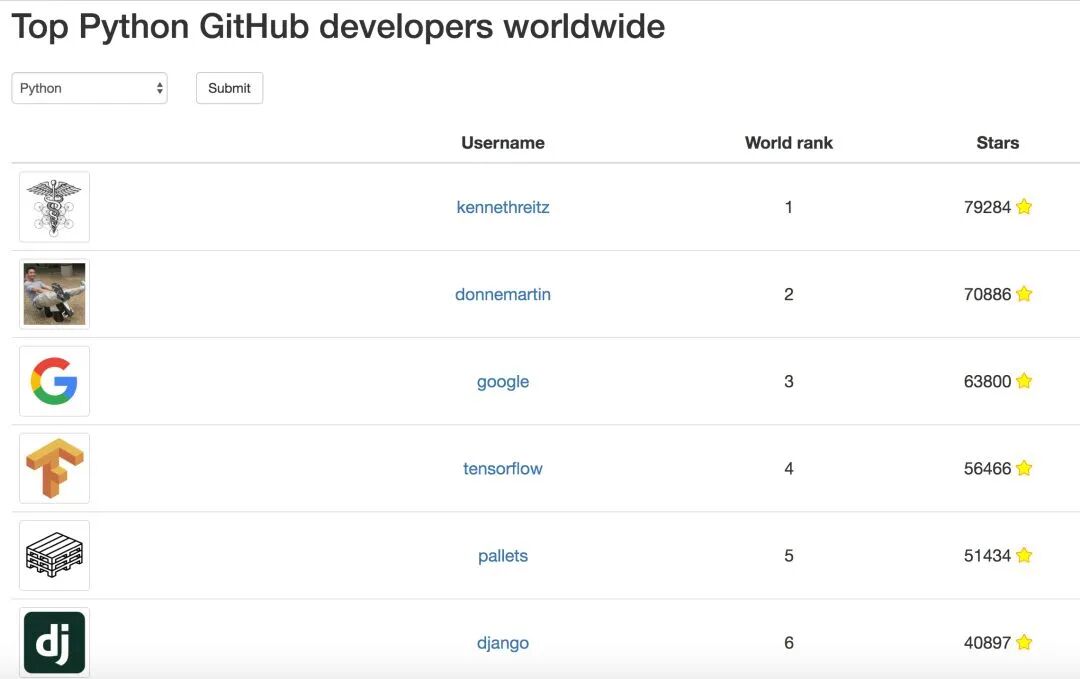
In addition to requests, another popular Python virtual environment management tool, Pipenv, was also released by him.With these projects, he was once the most starred Python user on GitHub.
However, he has now handed over most of his projects to the Python open-source community for management and maintenance.Every Python developer has the opportunity to contribute their skills to the project.
If you are a beginner in Python and have not yet learned about third-party modules, you might as well start with requests. It is easy to get started and has clear documentation, making it an essential tool for developing web scrapers and API requests.
If you have already started with Python and want to further enhance your programming skills, you can also use the requests project as an advanced learning case, reading the source code, learning code style and program structure design, and even submitting code to improve issues in the project, contributing to the open-source community.
Crossin’s new book “Code in Action: Learn Python Programming with ChatGPT” is now available.This book systematically and comprehensively explains how to master Python programming with the assistance of ChatGPT, suitable for readers with zero foundation in Python.[Click here for detailed introduction]After purchase, you can join the reader group, and Crossin will open a study mode for you, answering all your questions while reading this book.Crossin’s other books:Add WeChat crossin123 to join the Programming Classroom for collaborative learning.~

Thanks to everyone for sharing and liking!