Internet/Programmer/Technology/Resource Sharing
It takes about 11 minutes to read this article.
Source:Programmer Without Learning Countless,
Link: jianshu.com/p/6d349acf48aa
What is ZooKeeper
ZooKeeper is an Apache top-level project that provides efficient and highly available distributed coordination services for distributed applications. It offers basic distributed services such as data publishing/subscription, load balancing, naming services, distributed coordination/notification, and distributed locks. Due to its convenient usage, excellent performance, and good stability, ZooKeeper is widely used in large distributed systems such as Hadoop, HBase, Kafka, and Dubbo.
ZooKeeper has three operating modes: standalone mode, pseudo-cluster mode, and cluster mode.
-
Standalone Mode: This mode is generally suitable for development and testing environments. On one hand, we do not have so many machine resources, and on the other hand, the usual development and debugging do not require excellent stability.
-
Cluster Mode: A ZooKeeper cluster usually consists of a group of machines, generally more than 3 machines can form a usable ZooKeeper cluster. Each machine that makes up the ZooKeeper cluster will maintain the current server status in memory, and each machine will communicate with each other.
-
Pseudo-Cluster Mode: This is a special cluster mode where all servers of the cluster are deployed on a single machine. When you have a relatively good machine, deploying it in standalone mode would waste resources. In this case, ZooKeeper allows you to start multiple ZooKeeper service instances on a single machine by starting different ports, thereby providing external services with cluster characteristics.
Knowledge Related to ZooKeeper
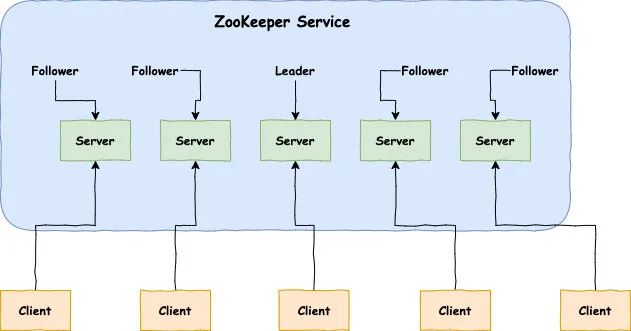
Roles in ZooKeeper:
-
Leader: Responsible for initiating and deciding votes, updating system status.
-
Follower: Used to receive client requests and return results to clients, participating in voting during the leader election process.
-
Observer: Can accept client connections, forward write requests to the leader, but the observer does not participate in the voting process and is only used to expand the system and improve read speed.
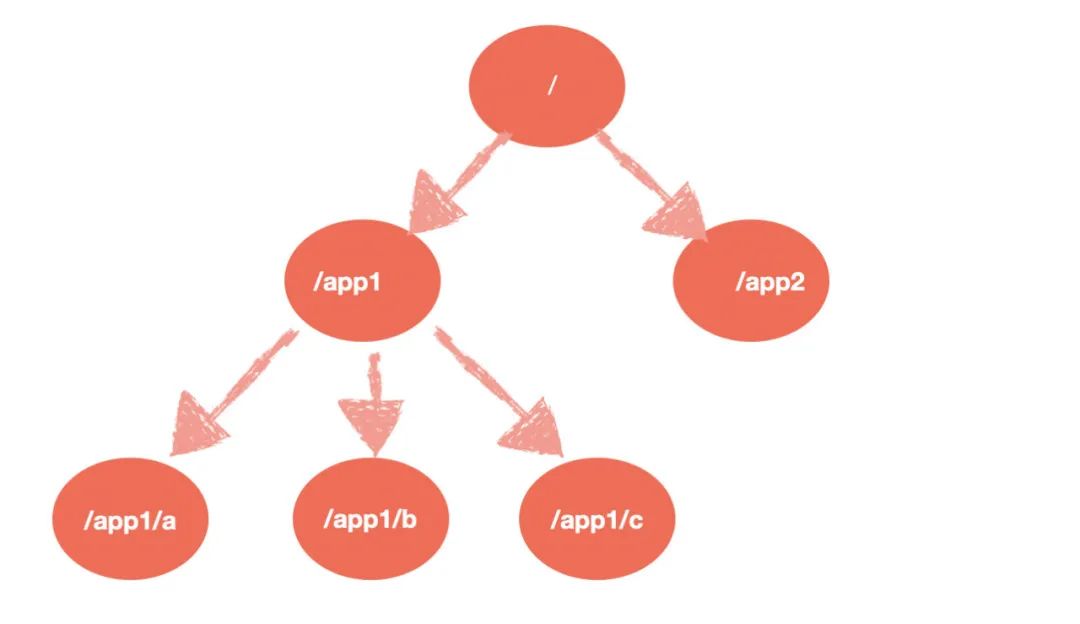
The Data Model of ZooKeeper
-
Hierarchical directory structure, naming conforms to conventional file system specifications, similar to Linux.
-
Each node in ZooKeeper is called a Znode, and it has a unique path identifier.
-
Nodes Znode can contain data and child nodes, but EPHEMERAL type nodes cannot have child nodes.
-
The data in a Znode can have multiple versions. For example, if a certain path stores multiple data versions, querying the data under this path requires including the version.
-
Client applications can set watchers on nodes.
-
Nodes do not support partial read/write but require complete read/write at once.
Node Characteristics of ZooKeeper
ZooKeeper nodes are lifecycle-dependent, which depends on the type of node. In ZooKeeper, nodes can be categorized based on duration into persistent nodes (PERSISTENT) and ephemeral nodes (EPHEMERAL), and based on whether they are ordered into sequential nodes (SEQUENTIAL) and unordered nodes (the default is unordered).
Persistent nodes remain in ZooKeeper once created unless actively removed; they do not disappear due to the expiration of the session of the client that created the node.
Application Scenarios of ZooKeeper
ZooKeeper is a highly available distributed data management and system coordination framework. Based on the implementation of the Paxos algorithm, this framework guarantees strong consistency of data in a distributed environment, which is precisely why ZooKeeper solves many distributed issues.
It is worth noting that ZooKeeper was not inherently designed for these application scenarios; rather, many developers later explored typical usage methods based on the characteristics of its framework, utilizing the series of API interfaces it provides (or called the primitive set).
Data Publishing and Subscription (Configuration Center)
The publishing and subscription model, or configuration center, is where the publisher publishes data to ZooKeeper nodes for subscribers to dynamically retrieve data, achieving centralized management and dynamic updating of configuration information. For example, global configuration information, service addresses for service frameworks, etc., are very suitable for use.
Some configuration information used in applications is placed on ZooKeeper for centralized management. This scenario usually works as follows: the application actively retrieves the configuration once when it starts and registers a watcher on the node. This way, whenever there is an update to the configuration, the subscribed client will be notified in real time, achieving the purpose of obtaining the latest configuration information.
In distributed search services, the index metadata and the status of server cluster machines are stored in some designated nodes of ZooKeeper for various clients to subscribe to.
Distributed Log Collection System
This system’s core task is to collect logs distributed across different machines. Collectors are usually assigned collection tasks based on applications, so it is necessary to create a node P on ZooKeeper with the application name as the path and register the IPs of all machines of this application as child nodes under node P. This way, when there are machine changes, the collector can be notified in real-time to adjust task allocation.
Some information in the system needs to be dynamically obtained and may require manual modification. Typically, an interface, such as a JMX interface, is exposed to retrieve some runtime information. After introducing ZooKeeper , there is no need to implement a set of solutions; just store this information in designated ZooKeeper nodes.
Note: In the application scenarios mentioned above, there is a default premise — a small amount of data, but the data updates may be relatively fast.
Load Balancing
The load balancing referred to here is soft load balancing. In a distributed environment, to ensure high availability, the same application or service provider usually deploys multiple instances to achieve peer service. Consumers must choose one of these peer servers to execute related business logic, among which a typical example is the producer and consumer load balancing in message middleware.
Naming Service
Naming services are also a common scenario in distributed systems. In distributed systems, by using naming services, client applications can obtain resource or service addresses based on specified names, such as the machines in the cluster, service addresses provided, remote objects, etc. — these can all be collectively referred to as names.
One common example is the service address list in some distributed service frameworks. By calling the API provided by ZooKeeper to create nodes, it is easy to create a globally unique path that can serve as a name.
The distributed service framework Dubbo, open-sourced by Alibaba Group, uses ZooKeeper as its naming service to maintain a global service address list.
In Dubbo’s implementation:
-
When the service provider starts, it writes its URL address to the specified node /dubbo/${serviceName}/providers in ZooKeeper, completing the service publishing.
-
When the service consumer starts, it subscribes to the provider URL address under /dubbo/${serviceName}/providers and writes its URL address to /dubbo/${serviceName}/consumers.
Note: All addresses registered to ZooKeeper are temporary nodes, which ensures that service providers and consumers can automatically sense resource changes.
Additionally, Dubbo has monitoring at the service granularity. The method is to subscribe to all provider and consumer information under the /dubbo/${serviceName} directory.
Distributed Notification/Coordination
The unique Watcher registration and asynchronous notification mechanism in ZooKeeper can effectively achieve notification and coordination between different systems in a distributed environment, enabling real-time processing of data changes. The usual method is for different systems to register on the same Znode in ZooKeeper and listen for changes to the Znode (including changes to the Znode itself and its child nodes). If one system updates the Znode, another system can receive a notification and respond accordingly.
Another heartbeat detection mechanism: the detection system and the detected system are not directly associated but are linked through a certain node in ZooKeeper, greatly reducing system coupling.
Another system scheduling mode: one system consists of a console and a push system, where the console’s responsibility is to control the push system to perform corresponding push tasks. Some operations performed by the manager on the console actually modify the state of certain nodes in ZooKeeper, and ZooKeeper notifies the clients that registered watchers of these changes, which in turn triggers the corresponding push tasks.
Another work reporting mode: similar to a task distribution system. Once a sub-task is started, it registers a temporary node in ZooKeeper and periodically reports its progress (writing the progress back to this temporary node). This way, the task manager can know the task progress in real-time.
Distributed Locks
Distributed locks mainly benefit from ZooKeeper’s guarantee of strong data consistency. Lock services can be divided into two categories: one is to maintain exclusivity, and the other is to control sequencing.
Maintaining exclusivity means that among all clients attempting to acquire this lock, only one will ultimately succeed. The usual approach is to treat a Znode on ZooKeeper as a lock and achieve this by creating a Znode. All clients attempt to create the /distribute_lock node, and the client that successfully creates it owns the lock.
Controlling sequencing means that all clients attempting to acquire this lock will eventually be scheduled for execution, but with a global sequence. The approach is similar to the previous one, except that the /distribute_lock already exists, and clients create temporary sequential nodes under it (which can be controlled by the node’s attributes: CreateMode.EPHEMERAL_SEQUENTIAL ). The parent node of ZooKeeper (/distribute_lock) maintains a sequence to ensure the sequentiality of the created child nodes, thus forming a global sequence for each client.
-
Since child node names cannot be the same under the same node, as long as a Znode is created under a certain node, successful creation indicates successful locking. Register a listener for this Znode, and as soon as this Znode is deleted, it notifies other clients to attempt locking.
-
Create temporary sequential nodes: create nodes under a certain node. For each request, a node is created. Since it is sequential, the one with the smallest number gets the lock. When releasing the lock, notify the next one in line to acquire the lock.
Distributed Queues
In terms of queues, there are two types: one is a conventional first-in-first-out queue, and the other is an equal queue that executes only when all members have gathered. The basic principle for the first type of queue is similar to the control sequencing scenario in the distributed lock service, so it will not be elaborated here.
The second type of queue is actually an enhancement based on the FIFO queue. Usually, a /queue Znode is pre-established with a /queue/num node and assigned a value of n (or directly assigning n to /queue) to represent the queue size. Then, every time a member joins the queue, it checks whether the queue size has been reached to decide whether to start execution.
This usage is typically seen when a large task Task A in a distributed environment needs to proceed only when many sub-tasks are completed (or conditions are met). In this case, whenever one of the sub-tasks is completed (or ready), it creates its temporary sequential node under /taskList (CreateMode.EPHEMERAL_SEQUENTIAL). When /taskList detects that the number of its child nodes meets the specified count, it can proceed to the next step in order.
Using Docker-Compose to Set Up a Cluster
Having introduced the various application scenarios of ZooKeeper, let’s first learn how to set up a ZooKeeper cluster and then proceed to practical applications of the above scenarios.
The directory structure of the files is as follows:
Writing the docker-compose.yml File
The content of the docker-compose.yml file is as follows:
version: '3.4'
services:
zoo1:
image: zookeeper
restart: always
hostname: zoo1
ports:
- 2181:2181
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=0.0.0.0:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
zoo2:
image: zookeeper
restart: always
hostname: zoo2
ports:
- 2182:2181
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=0.0.0.0:2888:3888;2181 server.3=zoo3:2888:3888;2181
zoo3:
image: zookeeper
restart: always
hostname: zoo3
ports:
- 2183:2181
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=0.0.0.0:2888:3888;2181
In this configuration file, Docker runs 3 Zookeeper images and binds the local ports 2181, 2182, 2183 to the corresponding container’s 2181 port.
ZOO_MY_ID and ZOO_SERVERS are two environment variables required to set up a Zookeeper cluster. ZOO_MY_ID identifies the service ID, which must be a unique integer between 1-255 in the cluster. ZOO_SERVERS is the list of hosts in the cluster.
Execute docker-compose up in the directory where the docker-compose.yml is located to see the startup logs.
Connecting to ZooKeeper
Once the cluster is up, we can connect to ZooKeeper to perform operations related to nodes.
-
First, download ZooKeeper.
-
Unzip it.
-
Enter its conf/ directory and rename zoo_sample.cfg to zoo.cfg.
Configuration file explanation
# The number of milliseconds of each tick
# tickTime: Heartbeat count for CS communication
# The time interval for maintaining heartbeat between ZooKeeper servers or between clients and servers. Every tickTime milliseconds, a heartbeat will be sent. tickTime in milliseconds. tickTime=2000
# The number of ticks that the initial synchronization phase can take
# initLimit: Initial communication limit
# The maximum number of heartbeats (in tickTime counts) that can be tolerated during the initial connection between follower servers (F) and leader servers (L) in the cluster. initLimit=5
# The number of ticks that can pass between sending a request and getting an acknowledgment
# syncLimit: Synchronization communication limit
# The maximum number of heartbeats (in tickTime counts) that can be tolerated between requests and responses between follower servers and leader servers in the cluster. syncLimit=2
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# dataDir: Data file directory
# The directory where ZooKeeper saves data. By default, ZooKeeper also saves the log files of written data in this directory. dataDir=/data/soft/zookeeper-3.4.12/data
# dataLogDir: Log file directory
# The directory where ZooKeeper saves log files. dataLogDir=/data/soft/zookeeper-3.4.12/logs
# the port at which the clients will connect
# clientPort: Client connection port
# The port where clients connect to the ZooKeeper server. ZooKeeper listens on this port to accept client access requests. clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
## Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
## http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
## The number of snapshots to retain in dataDir
autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
autopurge.purgeInterval=1
# Server name and address: cluster information (server number, server address, LF communication port, election port)
# This configuration item's writing format is quite special, as follows:
# server.N=YYY:A:B
# where N is the server number, YYY is the server's IP address, A is the LF communication port, which indicates the port the server exchanges information with the leader in the cluster. B is the election port, which indicates the port for inter-server communication when electing a new leader (when the leader goes down, the other servers will communicate with each other to choose a new leader). Generally, each server's A port is the same in the cluster, and each server's B port is also the same. However, when using pseudo-cluster mode, the IP addresses are the same, only the A and B ports are different.
You can use the default configuration without modifying zoo.cfg. Next, execute the command ./zkCli.sh -server 127.0.0.1:2181 in the bin/ directory of the extracted files to connect.
Welcome to ZooKeeper!2020-06-01 15:03:52,512 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1025] - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)JLine support is enabled2020-06-01 15:03:52,576 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@879] - Socket connection established to localhost/127.0.0.1:2181, initiating session2020-06-01 15:03:52,599 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1299] - Session establishment complete on server localhost/127.0.0.1:2181, sessionid = 0x100001140080000, negotiated timeout = 30000WATCHER::
WatchedEvent state:SyncConnected type:None path:null[zk: 127.0.0.1:2181(CONNECTED) 0]
Next, you can use commands to view nodes:
[zk: 127.0.0.1:2181(CONNECTED) 10] ls /[zookeeper]
[zk: 127.0.0.1:2181(CONNECTED) 11] create /zk myDataCreated /zk[zk: 127.0.0.1:2181(CONNECTED) 12] ls /[zk, zookeeper][zk: 127.0.0.1:2181(CONNECTED) 13]
[zk: 127.0.0.1:2181(CONNECTED) 13] get /zkmyDatacZxid = 0x400000008ctime = Mon Jun 01 15:07:50 CST 2020mZxid = 0x400000008mtime = Mon Jun 01 15:07:50 CST 2020pZxid = 0x400000008cversion = 0dataVersion = 0aclVersion = 0ephemeralOwner = 0x0dataLength = 6numChildren = 0
[zk: 127.0.0.1:2181(CONNECTED) 14] delete /zk[zk: 127.0.0.1:2181(CONNECTED) 15] ls /[zookeeper]
Due to space limitations, in the following articles, I will implement the application scenarios of ZooKeeper mentioned above one by one with code.
You can directly pull the project from GitHub; starting it only requires two steps:
-
Pull the project from GitHub.
-
Execute docker-compose up command in the ZooKeeper folder.
GitHub:github.com/modouxiansheng/about-docker/tree/master/ZooKeeper
Recommended Reading:
Recommending a Java object mapping tool
The world’s second-largest browser upgrade! Dramatic drop in memory/CPU usage
5T Technology Resources Giveaway! Including but not limited to: C/C++, Linux, Python, Java, PHP, Artificial Intelligence, Microcontrollers, Raspberry Pi, etc. Reply “2048” in the public account to get it for free!!

Scan the QR code to follow my public account
I’ve read it