Click the button below to follow the 3D Vision Workshop official account and select Star to receive valuable insights promptly.
Source: 3D Vision Workshop
Add the assistant: cv3d001, note: direction + school/company + nickname, and we will add you to the group. A detailed 3D vision industry subgroup is attached at the end of this article.
Scan the QR code below to join the “3D Vision from Beginner to Mastery” knowledge group, which contains numerous practical issues in 3D vision and learning materials for various modules: nearly 20 secret video courses, latest top conference papers, computer vision books, high-quality 3D vision algorithm source codes, etc. If you want to enter the field of 3D vision, work on projects, or conduct research, feel free to scan and join!

0. Paper Information
Title: BEV-ODOM: Reducing Scale Drift in Monocular Visual Odometry with BEV Representation
Authors: Yufei Wei, Sha Lu, Fuzhang Han, Rong Xiong, Yue Wang
Institution: Zhejiang University
Original link: https://arxiv.org/abs/2411.10195
1. Introduction
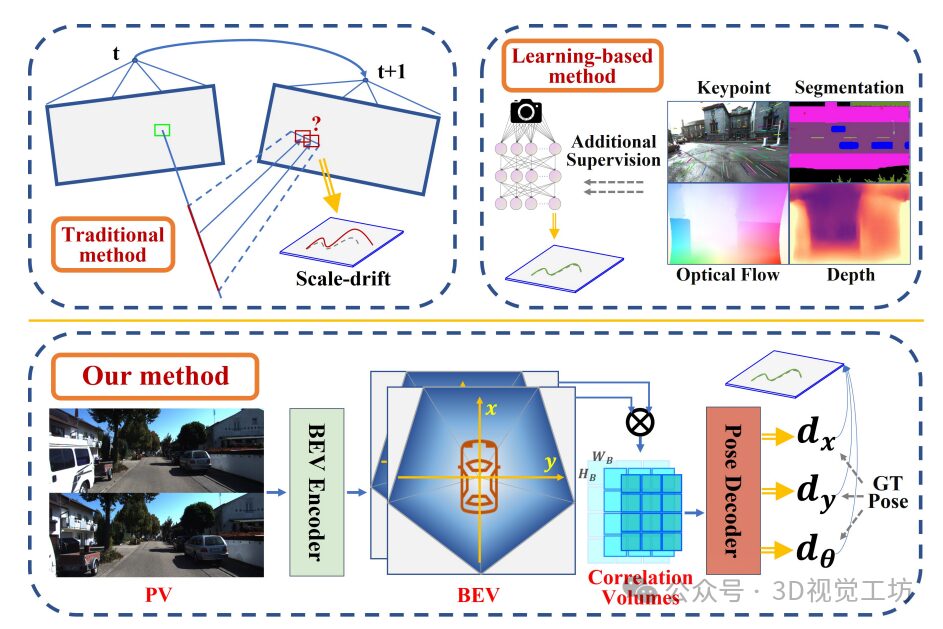
Monocular Visual Odometry (MVO) is crucial in autonomous navigation and robotics, providing an economical and flexible motion tracking solution. However, the inherent scale ambiguity in monocular setups often leads to cumulative errors over time. In this paper, we propose BEV-ODOM, a new MVO framework that utilizes Bird’s Eye View (BEV) representation to solve scale drift. Unlike existing methods, BEV-ODOM integrates depth-based Perspective View (PV) into the BEV encoder, correlation feature extraction neck, and CNN-MLP-based decoder, allowing it to estimate motion in three degrees of freedom without depth supervision or complex optimization techniques. Our framework reduces scale drift in long sequences and achieves precise motion estimation across various datasets, including NCLT, Oxford, and KITTI. Results show that BEV-ODOM outperforms current MVO methods, demonstrating reduced scale drift and higher accuracy.
2. Introduction
Monocular Visual Odometry (MVO) has become an important solution in robotics and autonomous driving due to its cost-effectiveness, garnering attention over the years. It serves as an economical and practical supplement to navigation aids such as GPS and inertial navigation systems. Despite its many advantages, the widespread application of MVO is limited by a key challenge: scale uncertainty. Due to the lack of universal depth information, monocular systems can typically only estimate motion in relative scale.
Traditional MVO methods, such as feature-based methods, semi-direct methods, and direct methods, determine scale during initialization and use it as a global reference. This approach tightly couples scale estimation with initial motion, making tracking performance highly sensitive to starting motion speed. Furthermore, these methods heavily depend on initial scale settings, leading to severe scale drift issues over time.
Learning-based MVO methods leverage the powerful fitting capabilities of machine learning to model the prior distribution in training data. They use Convolutional Neural Networks (CNN) to automatically extract features from images and regress poses based on temporal modeling methods. Additionally, some methods combine the interpretability of traditional methods with the powerful data fitting capabilities of deep learning. These methods integrate deep learning into steps such as absolute scale recovery and feature point selection to achieve absolute scale and enhance matching robustness. To obtain high-precision depth estimates, these methods often introduce depth supervision or optical flow supervision as additional supervisory means, which incurs extra costs.
In recent years, with advancements in Bird’s Eye View (BEV) transformation technology and the outstanding performance of BEV representation in 3D detection and scene segmentation, some methods have started utilizing BEV representation for visual odometry. The motivation for using BEV representation lies in leveraging the common ground plane assumption in autonomous driving to simplify the six degrees of freedom (6-DoF) odometry estimation problem. However, these methods do not extend beyond the framework of other 3D tasks under BEV representation; they require prior scene segmentation and then use the segmentation results to estimate poses. The use of auxiliary task supervision raises questions about whether the inherent scale properties come from the BEV representation itself or from supervision. Moreover, these methods lead to high labeling costs and do not fully utilize the direct information provided by BEV representation. Recommended courses: (Second session) Thoroughly understand 3D Laser SLAM based on LOAM framework: from source code analysis to algorithm optimization.
To address this issue, we propose BEV-ODOM, a novel MVO method that utilizes BEV representation. Our framework is built around a depth-based perspective view to BEV encoder, a correlation feature extraction neck to assess similarity between two BEVs with different displacements, and a decoder that integrates CNN and MLP to estimate motion in three degrees of freedom (3-DoF). Unlike existing learning-based MVO methods, our approach avoids complex procedures such as bundle adjustment, pose graph optimization, and auxiliary task supervision. Unlike other visual odometry methods that rely on BEV representation, our method does not depend on segmentation results from BEV maps or occupancy maps for pose estimation, nor does it require additional supervision. This simplification not only enhances the efficiency of our method but also avoids the impact of inaccurate segmentation results on MVO and reduces data collection costs. By fully leveraging the consistent scale properties and precise, detailed feature extraction capabilities of BEV representation, our method demonstrates outstanding scale consistency and achieves optimal (SOTA) performance under 3-DoF evaluation on challenging datasets. Due to minimal changes in the z-axis translation, pitch, and roll in the NCLT and Oxford datasets, our method also performs excellently under 6-DoF evaluation.
3. Performance Demonstration
Comparison of MVO methods: Traditional methods lack consistent scale; learning-based methods require additional supervision. In contrast, our method achieves low scale drift using only pose supervision from BEV representation.
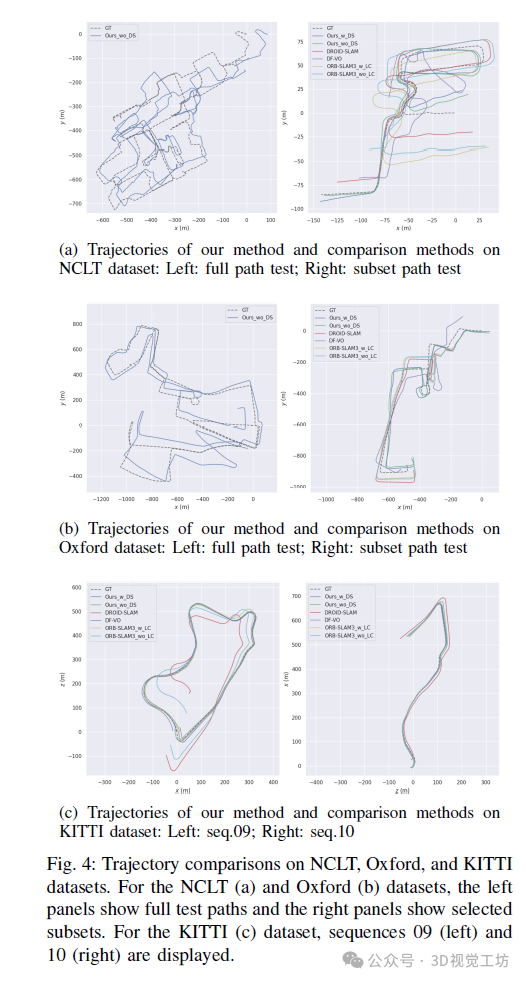
In trajectory analysis, as shown in Figure 4, for the NCLT and Oxford datasets, the left image depicts the complete trajectory, while the right image shows selected parts of these trajectories. This distinction is crucial for comprehensive evaluation:
• Complete trajectory analysis (left image): These trajectory images visualize the results obtained by training on three complete sequences and testing on another complete sequence. Only our method is shown, as other methods usually produce unreliable trajectories over the entire sequence. This highlights the challenges faced by existing MVO methods in maintaining scale consistency and accurate trajectory estimation in long-term or complex environments.
• Selected segment analysis (right image): These trajectory images visualize the results obtained by training on parts of the same sequence and testing in completely unseen scenarios. This testing method evaluates our method’s generalization ability and accuracy in new environments, where our method still performs the best.
This dual analysis demonstrates the robustness and adaptability of BEV-ODOM. It reliably handles long and complex trajectories and performs well in unfamiliar environments, highlighting the advantages of using BEV representation for MVO tasks in complex and long-distance scenarios that meet the plane assumption.
4. Main Contributions
Our contributions are as follows:
• We proposed a novel MVO framework utilizing BEV representation, effectively addressing the scale drift issue and improving accuracy.
• Our method simplifies the learning-based MVO process based on BEV representation, eliminating the need for supervision from auxiliary tasks such as depth estimation, segmentation, and occupancy map generation, enhancing efficiency and robustness.
• Our method achieves optimal performance among current MVO methods on challenging datasets.
5. Method
BEV-ODOM introduces an MVO method that leverages the inherent scale consistency of BEV representation for motion estimation. It requires no additional modules apart from visual input and pose supervision. The process begins by extracting features from the perspective view (PV), then maps these features onto the BEV plane through frustum projection. We then compute the correlation of multi-channel BEV feature maps between two frames with different displacements, identifying matches that reveal self-motion translation and rotation. Finally, we refine these features using CNN and MLP to generate the final output.
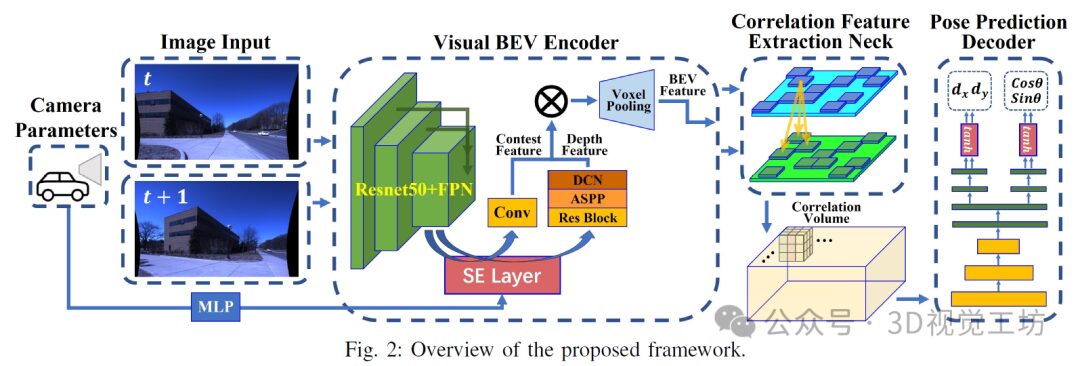
The intermediate processes and results of BEV-ODOM: predicted and actual trajectories (top left), camera images at four positions (A-D, top right), and visualizations of BEV feature maps and BEV optical flow information (bottom).

6. Experimental Results
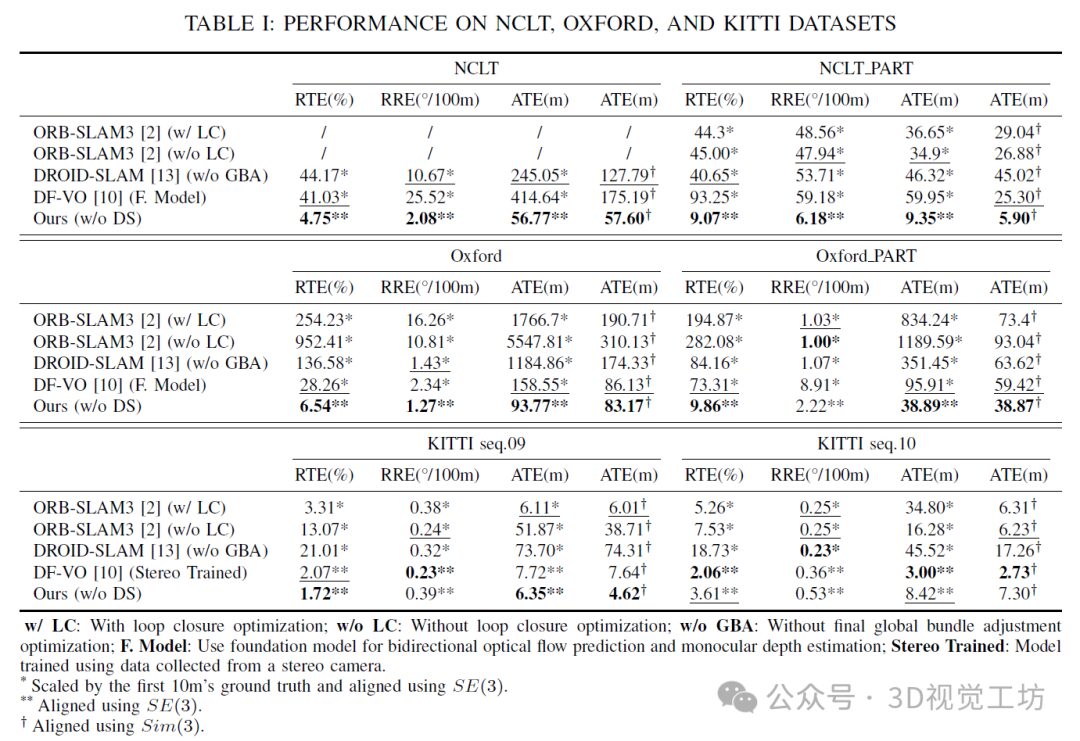
Table I shows the performance comparison of our method with other methods on the KITTI, NCLT, and Oxford datasets.
On the KITTI dataset, our method achieved the best or second-best results on most metrics in seq.09, particularly excelling in the absolute trajectory error (ATE) that measures overall trajectory drift. In seq.10, our method was not optimal in translation accuracy, partly due to significant elevation changes throughout the sequence. This indicates room for improvement in our method in scenarios that do not meet the plane assumption. Another reason is that DF-VO uses stereo camera data for training.
For the more challenging NCLT and Oxford datasets, our method significantly outperformed other methods on nearly all metrics.
DF-VO performed better on the KITTI dataset as it uses stereo depth information for training. However, even when tested on the NCLT and Oxford datasets, which provide bi-directional optical flow and monocular depth estimation, its performance remains poor. This highlights the difficulties faced by such methods when the dataset lacks depth and optical flow supervisory data or when vehicles are not equipped with the necessary data collection devices. In contrast, our method achieves good scale consistency and precise relative pose estimation even without depth supervision. It performs excellently in real-time scenarios without Sim(3) alignment and surpasses other methods that require Sim(3) alignment in ATE metrics on the NCLT and Oxford datasets.
Finally, compared to techniques like DROID-SLAM, which require continuous multi-frame optimization, and DF-VO, which involves predicting intermediate depth and bi-directional optical flow, our method demonstrates improvements in speed and memory consumption. Our method achieves speeds of over 60 frames per second (fps) on an RTX4090 graphics card. This efficiency and reduced resource usage simplify the deployment of learning-based methods, making our method more practical for real-world applications.
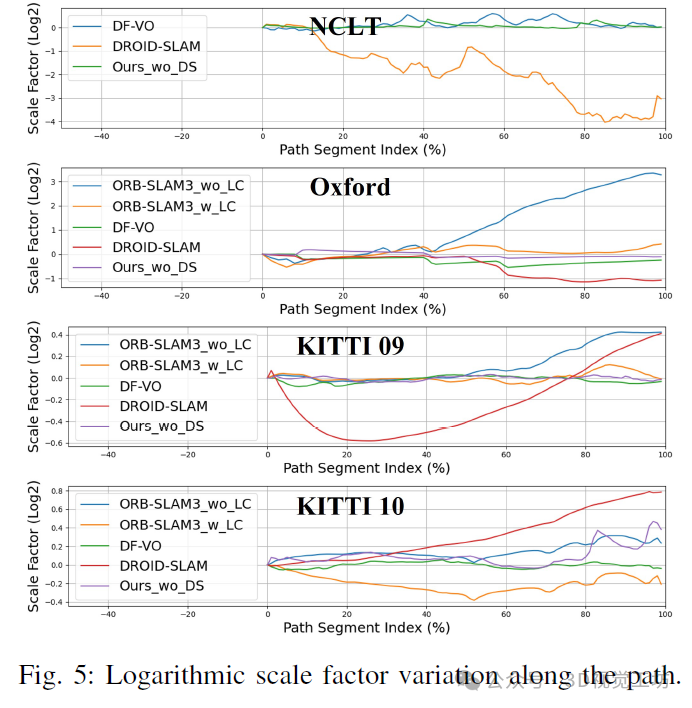
We also present Figure 5, which shows the variation of logarithmic scale factors along the path for various methods. Our method maintains a consistent scale factor throughout the path compared to others.
The results indicate that our method maintains a high level of performance across various datasets, only underperforming compared to the DF-VO method trained with stereo data on one test sequence of the KITTI dataset. By observing Figure 5 and analyzing the true values of this sequence, we found that the primary reason for scale drift is the uphill segment in the last 50% of the path. Since our method only predicts 3 degrees of freedom (3-DoF) motion, it leads to such errors.
Additionally, it is noteworthy that even in the severely jittery NCLT dataset, our method consistently maintains scale accuracy from start to finish. This is because, under severe jitter, the motion amplitude of BEV features is smaller than that of perspective view (PV) features. The BEV encoder focuses on mapping features to BEV space based on depth, making it more capable of handling these situations, while finding accurate matches for PV features during high-frequency, large-amplitude back-and-forth movements is challenging.
7. Summary
In this paper, we propose BEV-ODOM, a visual odometry framework aimed at addressing the scale drift problem in visual odometry systems. We extract features from perspective view images and estimate their depth distribution, project them into 3D space, and compress them into BEV representation. Next, we use a correlation feature extraction module to capture motion information between BEV feature maps. Finally, the pose decoder based on Convolutional Neural Network-Multi-Layer Perceptron (CNN-MLP) estimates 3-DoF motion. We conducted extensive experiments on widely used NCLT, Oxford, and KITTI datasets to validate the effectiveness of our method. The results show that the proposed method exhibits superior performance across all datasets.
Readers interested in more experimental results and details of the article can read the original paper~
This article is for academic sharing purposes only. If there is any infringement, please contact us to delete the article.


The 3D Vision Exchange Group has been established!
We have currently established multiple communities in the field of 3D vision, including 2D computer vision, cutting-edge, industrial 3D vision, SLAM, autonomous driving, 3D reconstruction, drones, etc. The subgroups include:
Industrial 3D Vision: camera calibration, stereo matching, 3D point cloud, structured light, robotic arm grasping, defect detection, 6D pose estimation, phase deflection, Halcon, photogrammetry, array cameras, photometric stereo vision, etc.
SLAM: visual SLAM, laser SLAM, semantic SLAM, filtering algorithms, multi-sensor fusion, multi-sensor calibration, dynamic SLAM, MOT SLAM, NeRF SLAM, robot navigation, etc.
Autonomous driving: depth estimation, Transformer, millimeter-wave | laser radar | visual camera sensors, multi-sensor calibration, multi-sensor fusion, autonomous driving comprehensive group, 3D object detection, path planning, trajectory prediction, 3D point cloud segmentation, model deployment, lane detection, Occupancy, target tracking, etc.
3D Reconstruction: 3DGS, NeRF, multi-view geometry, OpenMVS, MVSNet, colmap, texture mapping, etc.
Drones: quadrotor modeling, drone flight control, etc.
2D Computer Vision: image classification/segmentation, object detection, medical imaging, GAN, OCR, 2D defect detection, remote sensing surveying, super-resolution, face detection, behavior recognition, model quantization pruning, transfer learning, human pose estimation, etc.
Cutting-edge: embodied intelligence, large models, Mamba, diffusion models, image/video generation, etc.
In addition to these, there are also job seeking, hardware selection, visual product landing, product, industry news and other exchange groups.
Add the assistant: cv3d001, note: research direction + school/company + nickname (e.g., 3D point cloud + Tsinghua + little strawberry), and we will add you to the group.

3D Vision Workshop Knowledge Group
“3D Vision from Beginner to Mastery” knowledge group has been established for 6 years, and the materials in the group include: nearly 20 secret video courses (including structured light 3D reconstruction, camera calibration, SLAM, depth estimation, 3D object detection, 3DGS top conference reading courses, 3D point clouds, etc.), project docking, summary of 3D vision learning routes, latest top conference papers & codes, latest modules in the 3D vision industry, high-quality source codes for 3D vision, book recommendations, programming basics & learning tools, practical projects & assignments, job recruitment & interview experiences & interview questions, etc. Welcome to join the “3D Vision from Beginner to Mastery” knowledge group, and learn and progress together.

3D Vision Workshop official website: www.3dcver.com
Embodied intelligence, 3DGS, NeRF, structured light, phase deflection, robotic arm grasping, point cloud practical work, Open3D, defect detection, BEV perception, Occupancy, Transformer, model deployment, 3D object detection, depth estimation, multi-sensor calibration, planning and control, drone simulation, C++, 3D vision python, dToF, camera calibration, ROS2, robot control planning, LeGo-LAOM, multi-modal fusion SLAM, LOAM-SLAM, indoor and outdoor SLAM, VINS-Fusion, ORB-SLAM3, MVSNet 3D reconstruction, colmap, line and surface structured light, hardware structured light scanner, etc.

3D Vision Module Selection: www.3dcver.com

Click here👇 to follow me, and remember to star it~
One-click triple connection “share”, “like” and “view”
3D vision technology frontier progress seen every day ~