Skip to content
Recently, Arm officially released the TCS23 (Total Compute Solutions 23) platform along with corresponding IP products, including the Cortex-X4, A720, A520 CPUs based on the Armv9 architecture, and the latest Immortalis-G720, which is a new IP based on Arm’s fifth-generation GPU microarchitecture, along with an updated DSU. Undoubtedly, these IPs will be the focus of mobile application processors (AP) and SoCs in the next 1-2 years.
Recently, Arm dedicated significant time at the Media Technology Day in China to discuss the details of these IPs and the TCS23 platform. Arm shared extensive information from four aspects: solutions, CPU/GPU and related IPs, software, and security.
The core IPs of greatest concern to the general public include the CPU IP fully migrated to AArch64, the next-generation Immortalis GPU, and the new DSU-120 (DynamIQ Shared Unit). We will elaborate on these components in a separate article.
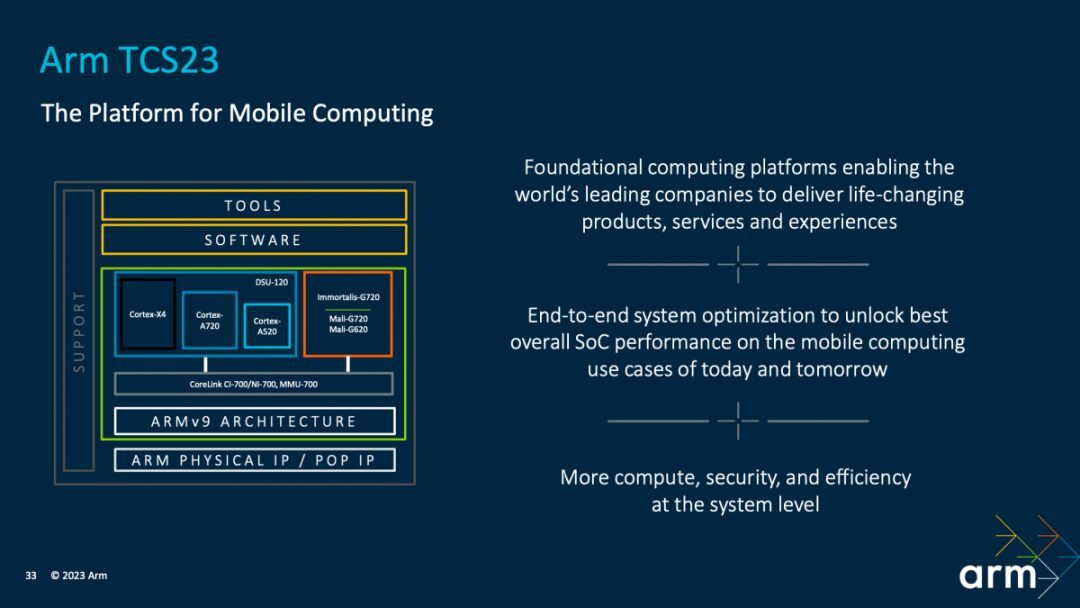
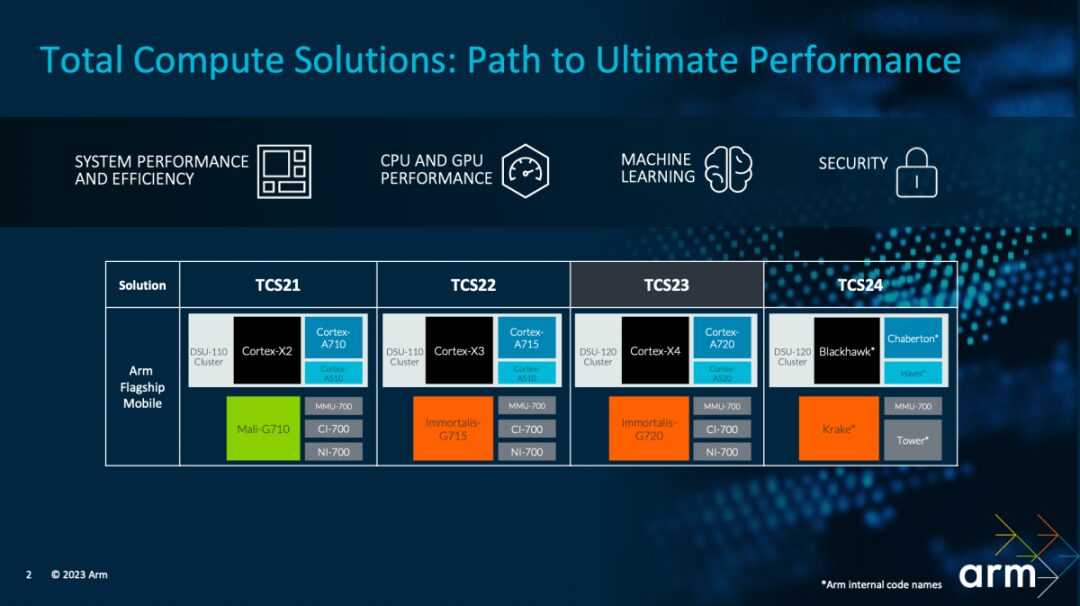
In fact, the TCS23 solution promoted by Arm is already in its third generation. Most people understand the term “solution” in the context of Arm IP as a packaged sale of IP. However, TCS aims to enhance performance and efficiency from a more comprehensive design perspective.
As shown in the image above, most people are concerned about the central aspects, namely the Armv9 architecture and its storage and interconnect consistency, along with various core IPs. In reality, TCS also includes software, development tools, and physical IPs implementing Arm IP using advanced processes.
Kinjal Dave, Senior Director of Product Management at Arm’s Client Division, stated: “When discussing solutions, why does Arm adopt such a holistic methodology to develop solutions, continuously pushing performance and efficiency? It has become increasingly difficult and costly. For Arm, this means that every year we must achieve progress in performance and efficiency with TCS. Therefore, we need to strike a balance.”
Kinjal mentioned that Arm has always strived to balance between benchmarks and real-world usage scenarios: “On one hand, individual IPs must continuously strengthen, while on the other hand, when these individual IPs are combined, the overall system level must also achieve dual improvements in performance and efficiency.” “Providing our partners with complete performance improvements through system-level solutions that integrate these individual IPs.”
With the slowdown of Moore’s Law and the comprehensive rollout of various classic technologies at the design level, the performance and efficiency improvements brought about by individual IP microarchitectures in recent years have not been as significant as before. Considering things from a more systematic perspective is a consensus among all players in the semiconductor chain.
Thus, this article will look at the improvements of this generation of platforms from the overall perspective of TCS23, which will involve the aforementioned IPs but will not delve too deeply. Additionally, it is noteworthy that Arm has dedicated a section of a keynote speech to discuss software improvements, including compilers, SVE2 instructions, and the Android Dynamic Performance Framework, which will also be briefly covered in this article.
This article will not elaborate on the performance and efficiency changes of individual IPs, including a 15% performance improvement of Cortex-X4 compared to X3, a 20% energy efficiency improvement of Cortex-A720 compared to A715, a 22% energy efficiency improvement of Cortex-A520 compared to A510, improvements in dynamic power consumption performance of DSU, new power modes for idle and low-load scenarios, and a 15% performance improvement and 40% reduction in bandwidth usage for Immortalis-G720, etc.
However, Arm has provided reference designs at the FPGA level for TCS23, “representing real chip devices.” The reason for Arm’s reference design is that the IPs are becoming increasingly complex, and many features in the system require cross-system integration, such as the MTE (Memory Tagging Extension) security feature that Arm has been discussing.
Additionally, as more diverse terminal usage scenarios emerge, the difficulty of trade-offs in design choices and balances for chip design work has also increased.
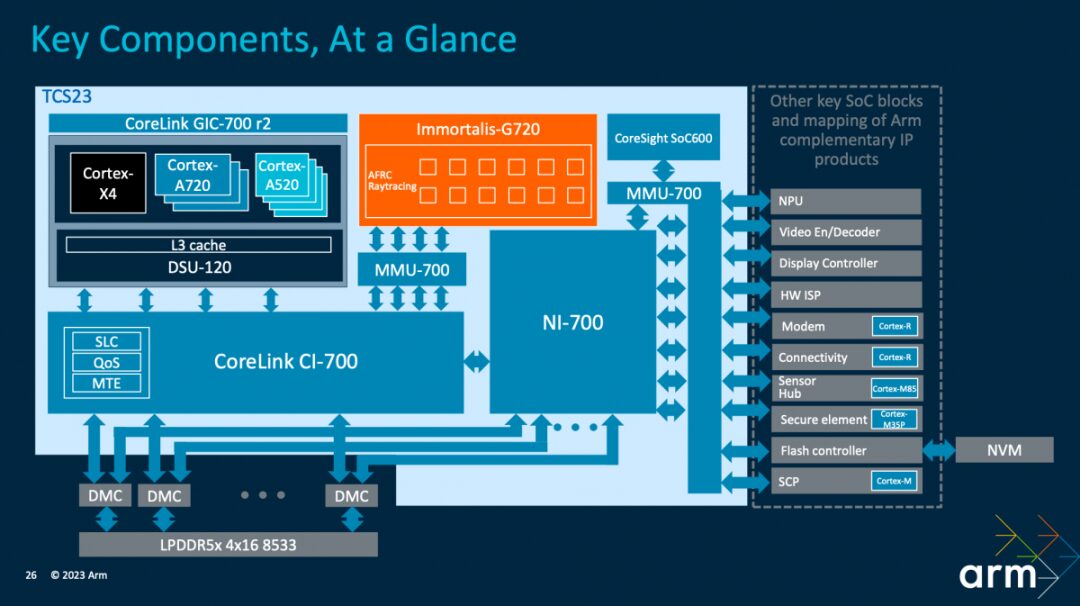
The above image shows Arm’s TCS23 reference design. On a broad framework, both the CPU and GPU utilize the latest IPs of this generation. The CPU cluster composed of different cores is “connected to the shared system backplane along with the DSU-120”; leveraging the CoreLink CI-700 where the system cache (SLC) is located, it connects to the Immortalis-G720 GPU.
Here, the CoreLink CI-700 acts as the core of the storage system, providing a convergence point for all IO traffic (also used to implement MTE). At the same time, NI-700 provides a separate path to DRAM for all other traffic; “it can perform QoS execution, allowing different types of traffic to flow together without cross-flow or blocking each other.”
The Essence of System-Level Solutions
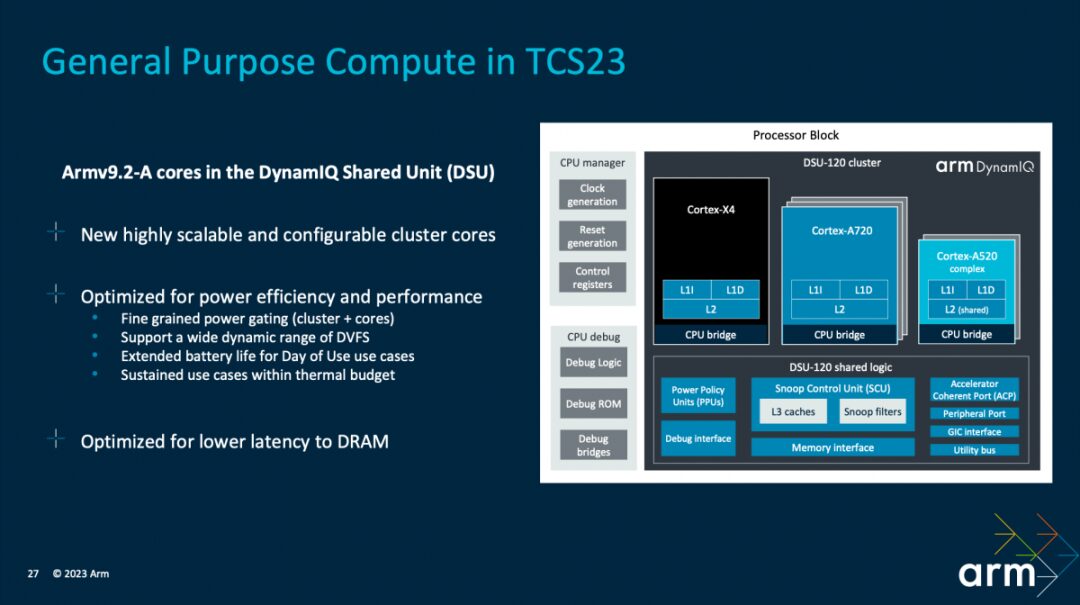
The CPU part of the reference design is configured with 1x Cortex-X4, 3x Cortex-A720, and 4x Cortex-A520; the DSU-120 is equipped with 8MB L3 cache. Arm believes that the 1+3+4 configuration is a balanced solution for achieving performance and efficiency. However, in multi-threaded performance comparisons, Arm also presented a 1+5+2 combination.
Kinjal did not elaborate on this part of the configuration. However, the focus remains on system-level work. He emphasized that the key to the CPU cluster is how to utilize the CPU and behavioral architecture to achieve a dynamic range of performance across three levels; additionally, DRAM latency is a significant factor affecting CPU performance.
For the latter, on one hand, “we have conducted structural static latency optimizations for DRAM,” “firstly, selecting clock configurations in the paths within the DynamIQ shared unit and leading to memory, which involves resource competition in this field”—in this process, DynamIQ clock configuration optimizations must be performed while minimizing the number of selections;
On the other hand, it is necessary to consider the “dynamic priority levels under the loading of system memory,” including “GPU, camera, and other multimedia pipelines,” “which may need to access memory simultaneously.” All of this requires corresponding considerations when configuring the CPU cluster.
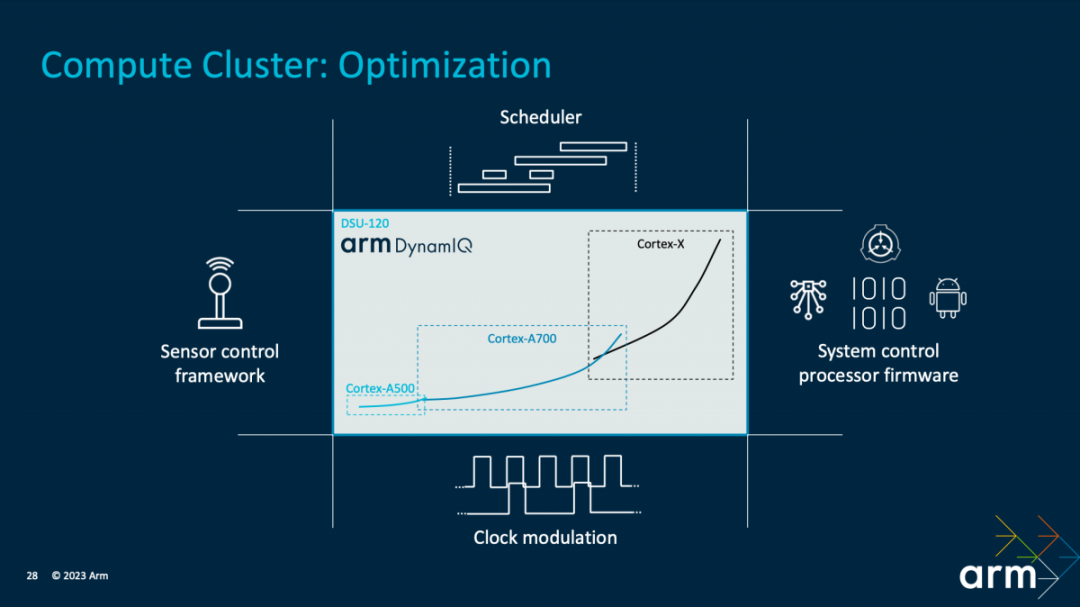
In optimizing the CPU cluster, the first step is to provide the “widest dynamic range” based on the “CPU core microarchitecture,” spanning across three layers (Cortex X4, Cortex A720, and Cortex A520). This includes DVFS dynamic adjustments, thread core migration, etc.; adapting to various load scenarios and meeting different performance goals. This encompasses optimizing efficiency for various operational scenarios, including how much CPU resource to allocate, such as frequency, response, and which cores to participate, etc.
“System-level solutions at the IP level include modes for different power selections and configurations for different clock options,” “in TCS23, we have added a logic-enhanced power-saving mode.”
“At the solution level, our power control firmware stack works together with the scheduler to achieve selections based on different usage scenarios, which is crucial.” Kinjal stated, “There is also a system control processor in the TCS23 solution that can coordinate the sensor control framework, fully considering thermal and power delivery constraints when moving between various CPU cores and the DSU-120 operating points.” “Across the entire CPU cluster, we also implement active clock gating and spatiotemporal adjustment mechanisms to save dynamic power consumption.”
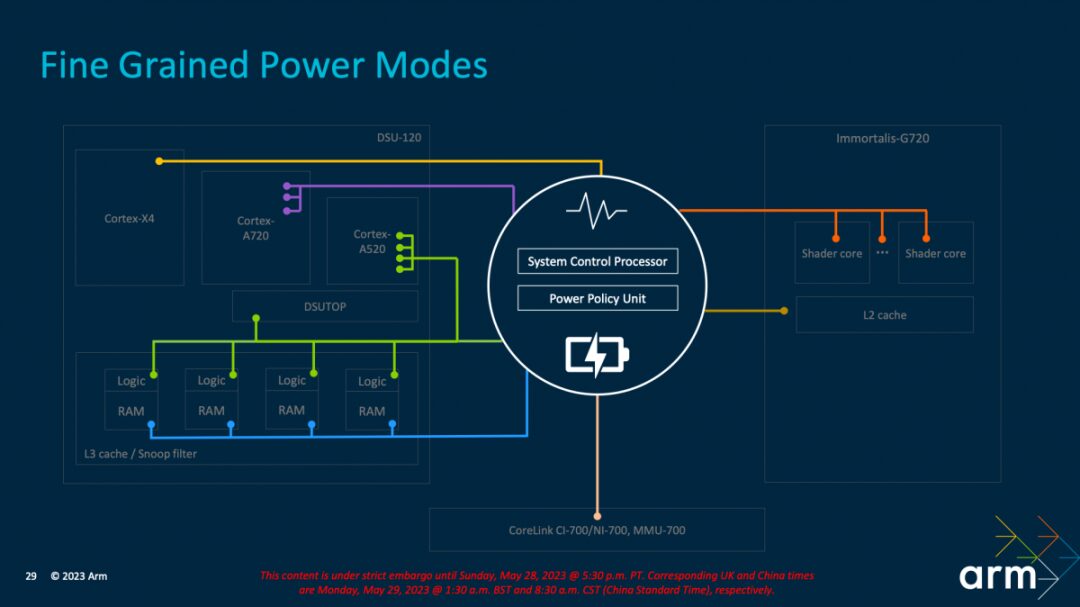
Another key aspect is the fine-grained power modes—this is also the essence of contemporary low-power design. The above image shows that each color represents “individual power connections.” One of Arm’s tasks here is to manage the complexity of power supply, “we have dedicated components for voltage supply management, power transmission, and network control power management.”
“Here, the power control components coordinate with the scheduler and the operating system’s power management software.”
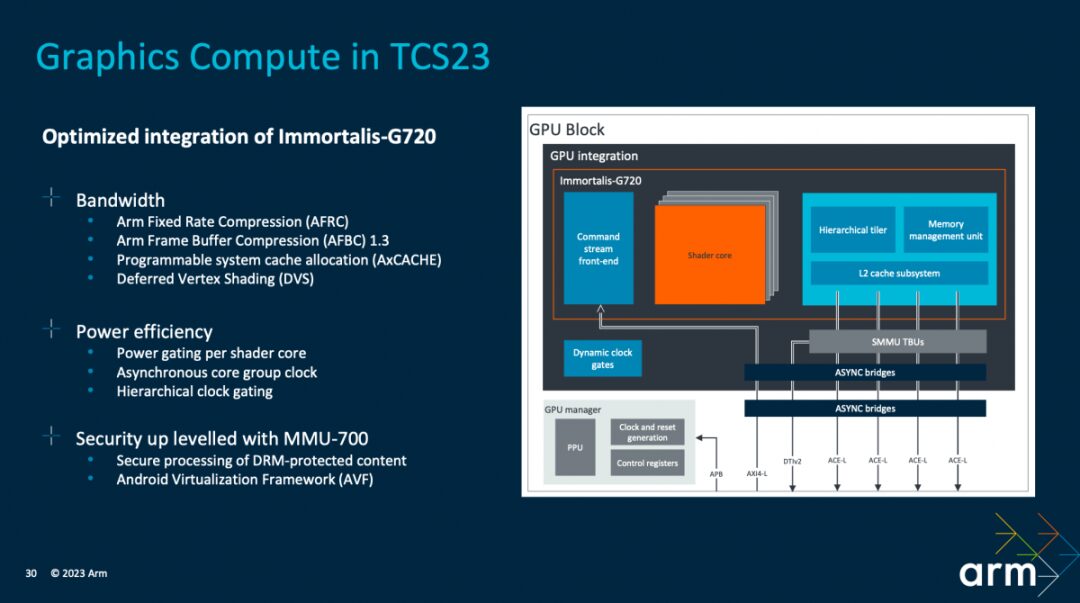
Regarding graphics computing, Arm emphasized three points of focus at the solution level: bandwidth, power consumption, and security. “We integrated Arm Immortal-G720 into the TCS23 solution, configured with MMU-700, to achieve joint optimization with the GPU.” Some parts of this will be detailed in our subsequent IP articles related to GPUs—such as the bandwidth-saving Deferred Vertex Shading.
From a broader perspective, the work on bandwidth savings includes AFRC and AFBC lossless compression—data compression at different stages of the pipeline has always been a constant topic for GPUs, which is valuable for reducing DRAM access demands and providing greater thermal headroom; IO consistency minimizes cache maintenance overhead, achieved through collaboration between CoreLink CI-700 and Immortalis-G720 to enhance performance; and leveraging large system caches (system cache), along with memory allocation hints to prioritize which portions should reside in the cache.
For energy efficiency optimization, on one hand, it involves utilizing power gating for each shader core, and on the other hand, power-saving modes for core groupings, etc. “The TCS23 solution provides a complete reference: how Immortalis-G720 collaborates with our reference firmware stack to achieve power control, dynamic voltage, and frequency adjustments.” Additionally, “we have also implemented an active clock gating scheme in the GPU to manage dynamic power consumption.”
In terms of security, the integration of MMU-700 is crucial for supporting secure processing of DRAM-protected content and supporting the Android virtualization framework.
By combining changes in cache, memory latency, floorplan, and memory support, the reference design achieves comprehensive bandwidth throughput, improving by 33% compared to the previous generation.
In summary, Kinjal reiterated that based on the TCS comprehensive computing solution, “Arm has gone beyond individual IP products to achieve end-to-end system-level optimization for customers, thereby unleashing the full performance of the entire SoC system.” This is the core value of TCS.
Performance Improvements from Software
In addition to the IPs that attract considerable attention, as mentioned at the beginning, TCS, as a solution, also encompasses tools, software, physical/POP IPs, etc. Here, we will also discuss tools and software, as TCS23 not only upgrades IPs but also upgrades software and tools. Geraint North, Senior Director of Ecosystem and Engineering at Arm’s Client Division, stated that over 45% of Arm’s engineers are software engineers, covering the lower layers with drivers, Linux kernels, and upwards with software frameworks, performance analysis tools, developer education, and best practices.
Software is naturally positioned above hardware, and Geraint mainly discussed the complete migration to 64-bit, enhancements in compiler performance, and the software-level performance improvements brought by ADPF (Android Dynamic Performance Framework).
In fact, regarding the software-related keynote, Arm also dedicated significant time to discussing security, including MTE, PAC/BTI technologies and corresponding ecosystems—mentioning collaborations with Google, Unity on security features, and even inviting partners like Kuaishou, MediaTek, and Vivo to stand on stage regarding MTE (Memory Tagging Extension) technology. However, we will not focus on security issues this time, even though this issue has become particularly important in contemporary mobile technology.
Regarding the topic of 64-bit ecosystem migration, the bottleneck is not on the chip and operating system vendors, but on the top-level app developers. Since 2011, CPU-level support for 64-bit (Cortex-A57/A53) was provided, followed by the Android operating system two years later, and only this year did the Pixel 7 emerge as a purely 64-bit Android-configured phone. This has been a relatively long process, and TCS23 represents a generation that is thoroughly built on pure 64-bit support clusters.
From the perspectives of security and performance, 64-bit is clearly a better choice. In terms of security, 64-bit provides a larger memory address space, making it more effective in implementing features like Address Space Layout Randomization (ASLR); it also provides a foundation for MTE and PAC (Pointer Authentication) frequently mentioned by Arm.
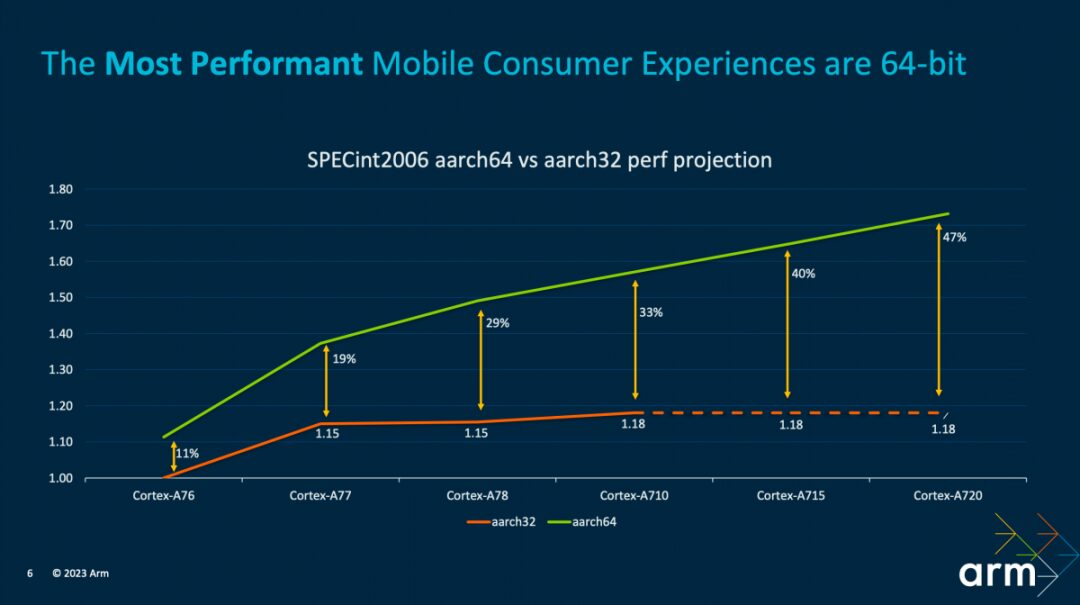
In terms of performance, Arm provided the above image. The performance changes of the Cortex-A7x series cores from A76 to A720 in SPECint2006 show that the performance gap between 32-bit and 64-bit applications is gradually widening. By the time of the Cortex-A710 generation, the performance gap had expanded to 33%, and subsequent IPs will no longer provide performance dividends for 32-bit applications. Geraint stated: “This widening gap is partly due to the decisions made in IP implementation, as we will focus more valuable time and silicon area on optimizing the 64-bit path.”
“The same goes for software; our compiler and library optimization teams have focused their efforts on 64-bit. If you are still developing in 32-bit, then the work we are doing may not empower you.” Although historical legacy issues still exist, TCS23 should also signify that the 64-bit offensive on mobile platforms is nearing its conclusion.
Regarding the compiler, Geraint mentioned that over the past three years, LLVM has achieved a 12% performance improvement. Therefore, “this work is very valuable because it not only improves the performance of the latest generation of CPUs, regardless of whether the device is based on Armv8 or Armv9, but when it is recompiled with the latest toolchain, it will generally achieve performance improvements.”
Geraint emphasized that a significant portion of Arm’s investment in LLVM has been focused on enhancing the performance of SVE2 instructions—vector extensions introduced in the Armv9 architecture.
The true value of SVE2 for Arm lies in ensuring that “first, we need to ensure that SVE2’s code generation is done as well as possible, which means we need to ensure that LLVM can perform vectorization work while also ensuring that LLVM can vectorize things it currently cannot.” This means doing better than NEON on the basis of LLVM’s achievable vectorization work, such as scatter/gather instructions and predicted instructions.
On the other hand, LLVM version 16 introduced Function Multi-Versioning, “so developers can more easily ensure that their functions can generate both versions for SVE2 and automatically select the correct version at runtime.” “As a developer, you don’t need to create two binary files simultaneously or check the CPU every time.” This is a consideration for compatibility.
However, we know that a practical issue facing SVE2 at this stage is its utilization and whether the mobile platform truly needs SVE2. Therefore, Geraint specifically mentioned that SVE2 is particularly suitable for image processing.
He cited the example of iToF (indirect Time-of-Flight), which uses a phase difference-based ToF method to construct depth maps. The underlying Halide image processing algorithm runs on Cortex-A720 at FP32 and FP16 precision, where SVE2 outperforms NEON by 10% and 23% respectively. This is largely due to the efficiency of SVE2’s scatter/gather instructions, which retrieve data from non-contiguous memory sections.
Another interesting aspect of software-related improvements is the Android Adaptability Framework (ADPF). ADPF provides developers with various APIs, including ADPF Hint API, Thermal API, Game State API, etc. For instance, the Hint API allows the operating system to adjust CPU frequency and resources more quickly to meet performance demands or save energy; the Thermal API is clearly related to temperature control.
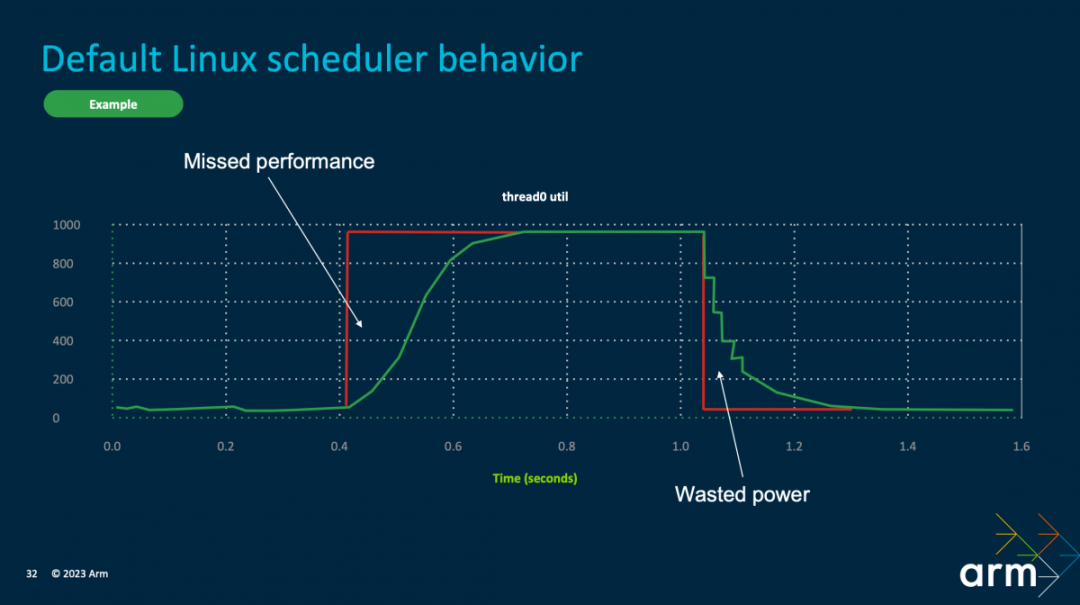
For example, regarding the PerformanceHint API, its existence is valuable as it can provide the operating system with more information about the application’s or game’s target load, allowing the CPU to adjust resources more accurately—this is more efficient than the previous behavior of the Linux kernel’s scheduler. For instance, the governor needs 200ms to ramp up from an idle state to the highest frequency, and after completing this task, the frequency also has a slow decline process. These behaviors are not efficient.
By directly sending the expected duration and target load from the application or game to the operating system, the scheduling strategy becomes much more efficient, reducing frame drops and improving energy efficiency. Geraint stated that the application of the PerformanceHint API can ensure that the correct workloads are placed on the correct cores, “instead of guessing with previous tools like setAffinity.”
Pixel phones have applied ADPF to SurfaceFlinger (the Android service responsible for rendering application UIs), reducing frame drops by 50% and saving 6% in power consumption. The PerformanceHint API became mandatory in Android 14; in the Unity game engine, it also exists as an Adaptability Plugin.
Another aspect of ADPF that Geraint shared includes the Thermal API, with test results from the game Candy Clash. Its essence is to achieve better gaming experiences, dynamically adapting the rendering quality (including frame rate, resolution, LOD, textures) based on the device’s thermal state, ensuring that even older phones do not overheat and can maintain stable frames while reducing power consumption. The test results showed an average frame rate improvement of 25% and a CPU power saving of up to 18%.
ADPF and Unity’s adaptive performance features clearly need to work in conjunction with Arm’s IP. Of course, on the other hand, this also requires developers to use the corresponding APIs. Such APIs should not only become part of software-level performance improvements but also be key to Arm strengthening ecosystem stickiness.
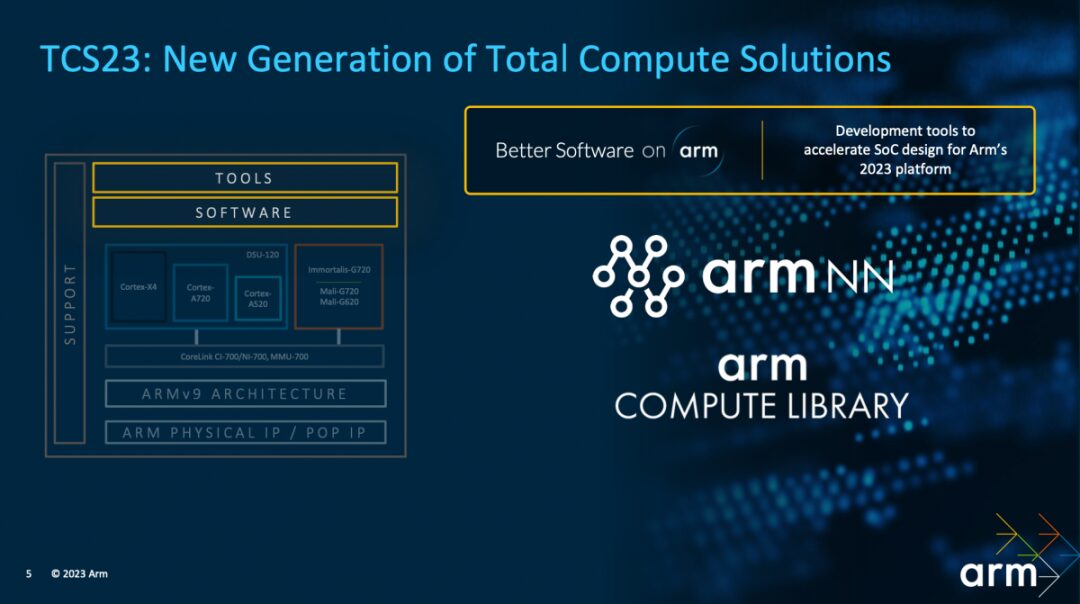
Regarding software and tools, Kinjal talked about one of the current market demand hotspots: AI and machine learning. Arm’s middleware and libraries in this area mainly include Arm NN and Arm Compute Library.
Kinjal stated: “Developers can achieve higher machine learning application development every quarter from the latest software library optimizations released by Arm.” In January of this year, Android NN and ACL were already available for download in the Google Play Store; by 2024, both can be accessed directly on GMS (Google Mobile Services)—becoming the NN standard for Android on a broader scale.
Regarding development tools, there is an improvement that facilitates software optimization: Profile Guided Optimization (PGO) performance enhancements. Developers can use PGO to “collect various data and information needed for application execution, optimize based on it, and the information collected can help everyone understand the bottlenecks in executing this application, allowing for guided adjustments to achieve maximum benefits.”
The Armv9 architecture captures this data through extensions called ETE (Embedded Trace Extension) and TRBE (Trace Buffer Extension), achieving minimal impact on the program’s binary size and trace capture data on performance.
Some Numerical References for Performance Improvements in Next Year’s Mobile Phones
Finally, let’s discuss some performance improvement numbers that may concern more people, most of which should reflect the performance improvements of the aforementioned reference design, also considering software-level enhancements. Since this is a system-level perspective, it involves high-level system testing, which should be more valuable in reflecting future mobile performance changes compared to the performance and efficiency improvement numbers at the IP level.
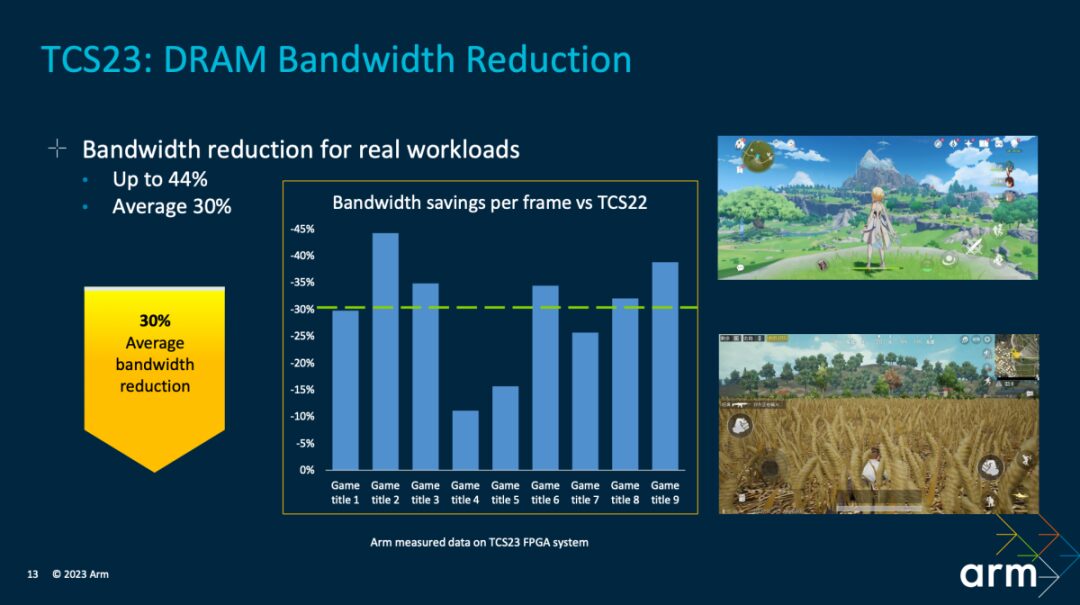
First, the comparisons above show the reduced DRAM bandwidth demand per frame in different games. Arm tested numerous games. Compared to TCS22, a maximum bandwidth reduction of 44% was achieved, with an average reduction of 30%. In other words, the reliance on external main memory has decreased, which is valuable for improving gaming efficiency.
This has also correspondingly brought about a 20% power saving (testing these games at sustained performance under 60fps). “This means that the energy saved can either be used for SoC power calculations to achieve further performance improvements or can be stored to achieve longer battery life, allowing users to play games for longer periods.” Kinjal stated.
As mentioned earlier, one of the graphics computing goals is bandwidth reduction, mainly due to the introduction of DVS (Deferred Vertex Shading) technology and optimization of system cache allocation strategies.
In GFXBench system performance tests, two well-known test items, Manhattan 3.0 and Aztec Ruins High, showed performance improvements of 21% and 20% respectively for TCS23. This is due to higher frequencies, more shader cores, along with system-level optimizations. Future gaming phones can look forward to this.
On the CPU side, Arm primarily provided Geekbench 6 multi-threading tests and Speedometer 2.1 web browsing tests. It is important to note that for GB6, the CPU configuration method for TCS23 is 1+5+2, resulting in a 27% improvement in multi-threaded performance.
Kinjal explained that the reason for this configuration is that “more and more people are starting to compare multi-threaded metrics, and it has also become a target for our partners to optimize. We see that many AAA-level games generate high-performance threads, and the number is continuously increasing, thus requiring sustained multi-thread performance from the CPU cluster. We use this benchmark to demonstrate the efficiency improvements of the new IP and the advances in process technology, which can meet the demands for sustained multi-thread performance.”
For Speedometer, the configuration is 1+3+4, which also includes software optimizations—namely Arm’s collaboration with Google on Chromium, enabling PAC/BTI security features. The performance improvements achieved through software optimization are higher.
Another CPU comparison focuses on machine learning performance, specifically object recognition, classification, and human pose tracking; the main comparison is Int8 inference. The performance improvements of different cores compared to TCS22 are shown in the above image.
The image on the right shows that the GPU’s AI super-resolution performance has achieved a fourfold improvement. This is due to the enhanced CPU and GPU computing power, as well as the evolution of Arm NN and Arm Compute Library.
This is the TCS23 that Arm explained from a solution perspective. However, Kinjal mentioned that TCS23 is a scalable platform aimed at a wide range of client devices, not just high-end mobile devices. For example, the Immortalis-G720 has scalable options such as Mali-G720/G620; in terms of CPU clusters, Cortex-A720 cores also have corresponding scalable options.
“Our latest products will also drive the next generation of flagship smartphones,” said Ian Smythe, Arm’s Vice President of Product Marketing. In fact, he also looked forward to future TCS designs, as shown in the above image, including key IPs such as Blackhawk CPU and Krake GPU. “We are also looking to the future. Our commitment to the product roadmap for CPU and GPU is stronger than ever, and in the coming years, we will increase investment in key IPs such as Krake GPU and Blackhawk CPU to meet our partners’ demands for computing and graphics performance.”