Automated testing tools
Automated testing tools are software tools used to perform software automation testing. They can simulate user operations and automatically execute a series of testing steps to verify whether the software functions as expected. Automated testing tools are commonly used in several areas:
1. Unit Testing: Used to test the smallest testable units of code, such as functions or methods.
2. Integration Testing: Used to test whether the integration between different components or modules is correct.
3. System Testing: Used to test whether the entire software system meets its requirements specifications.
4. Performance Testing: Used to evaluate the performance of software under various load conditions.
5. Regression Testing: Used to test whether the software still works as expected after updates or modifications.
Automated testing tools can manually write test scripts or use a graphical user interface (GUI) to design the testing process. Some common automated testing tools include:
– Selenium: For automated testing of web applications, supporting multiple programming languages and browsers.
– JUnit: A unit testing framework for Java.
– Pytest: A testing framework for Python.
– JMeter: A tool for performance and load testing.
– Appium: For automated testing of mobile applications.
– TestNG: A testing framework for Java that can extend JUnit.
– Robot Framework: A generic test automation framework that supports multiple programming languages.
– Cucumber: A behavior-driven development (BDD) tool for writing readable test cases.
Automated testing tools can significantly improve the efficiency of software development and testing, reduce the time and cost of manual testing, and ensure the consistency and reliability of software quality.
Introduction
Diffy is an open-source automated testing tool that can automatically detect services based on Apache Thrift or HTTP. With Diffy, you only need to perform simple configuration, and there is no need to write test code afterwards.
Diffy primarily compares the outputs of the stable version and its replica against the candidate version’s output to check if the candidate version is correct. Therefore, Diffy first assumes that the candidate version should have “similar” outputs to the stable version. That is, regardless of whether the candidate version and the stable version’s system modules are the same, their final outputs should be “similar.” The term “similar” is used rather than “identical” because identical requests may have some interference that Diffy does not need to care about, such as:
-
The response contains server-generated timestamps;
-
Random numbers are used in the code;
-
There are race conditions between system services.
The principle of Diffy
According to Diffy’s GitHub documentation, Diffy can act as a proxy to intercept requests and send them to all running service instances, discovering potential issues in each iteration of the code by comparing response results. Among them, Diffy runs three types of code instances:
1. Online Stable Version: A node running the online stable version of the code.
2. Backup of Online Stable Version: Also runs the online stable version to eliminate noise.
3. Test Version: The test version to be deployed, used for comparison with the online environment code.
The overall architecture is as follows:
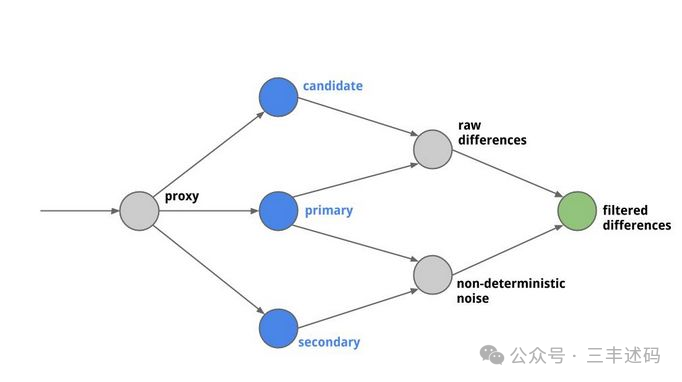
As shown in the figure, Diffy can compare the differences between the primary (online stable version) and secondary (backup of online stable version) by performing subtraction on these differences to eliminate noise; by comparing the candidate (test version) and primary (online stable version), it obtains the basic diff result; finally, by comparing the basic diff result with the noise-eliminated result, it obtains the final diff result.
Practical Introduction
Regression testing is a headache for experienced developers, and Twitter Diffy provides a new perspective on this issue. It strictly compares the outputs of the candidate version against the outputs of the stable version and its replica to check if the candidate version is correct, significantly reducing the regression workload. Let’s learn more about it!
Foreword
Testing is a very important part of the software lifecycle, but as projects gradually iterate through versions, the functions increase, and the systems become more complex, the proportion of new functions added in the current iteration relative to existing functions in the previous version becomes smaller. Every time we need to ensure that the newly added or modified functions do not affect the functions already present in the previous version. If we want to conduct a comprehensive regression, the workload of this testing will be enormous. Moreover, it may take hundreds or even thousands of test cases to find one or even zero issues, making the testing input-output ratio disproportionate. Twitter Diffy provides a good solution to the above problem. It compares the outputs of the candidate version against the outputs of the stable version and its replica to check if the candidate version is correct.
Working Principle
Diffy acts as a proxy, distributing incoming requests to different versions of the system and making final conclusions by comparing the outputs of each version of the system.
Diffy requires three versions of the system to achieve its noise filtering and comparison functions, which are:
-
Candidate Version: This version is the version to be tested, containing updated code relative to the production environment version;
-
Stable Version: This version is usually the one that has been deployed, or a version known to function correctly;
-
Backup of Stable Version: This version is a replica of the stable version, running the same code as the stable version, mainly used to eliminate noise.
The operating process is as follows:
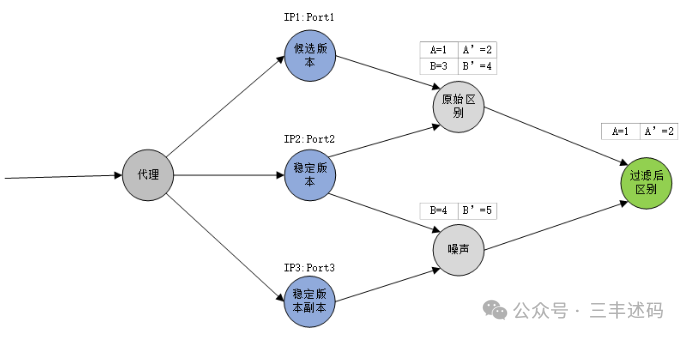
Where:
-
The original difference is the difference in output between the candidate version and the stable version, which may contain the aforementioned noise;
-
The noise is obtained from the stable version and its replica; if two systems running the same code produce different outputs with the same input, Diffy considers this to be noise that does not need to be concerned with.
Based on the above two sets of differences, Diffy can identify the real differences between the candidate version and the stable version, which are likely to be defects. For example, as shown in the figure, the original differences contain noise, and by comparing the stable version and the backup of the stable version, noise can be further filtered out. Project PracticeSimple Example
The general steps for installing and using Diffy are as follows:
-
Install Diffy;
-
Start the candidate service, stable service, and backup of the stable service;
-
Run Diffy;
-
Send requests & view results;
Let’s look at a simple example to understand the working process and usage of Diffy:
After successfully installing and running Diffy, start three simple local services for comparison: the candidate version (returns “hello world”), the stable version (returns “hello!!!”), and the backup of the stable version (returns “hello!!!”).
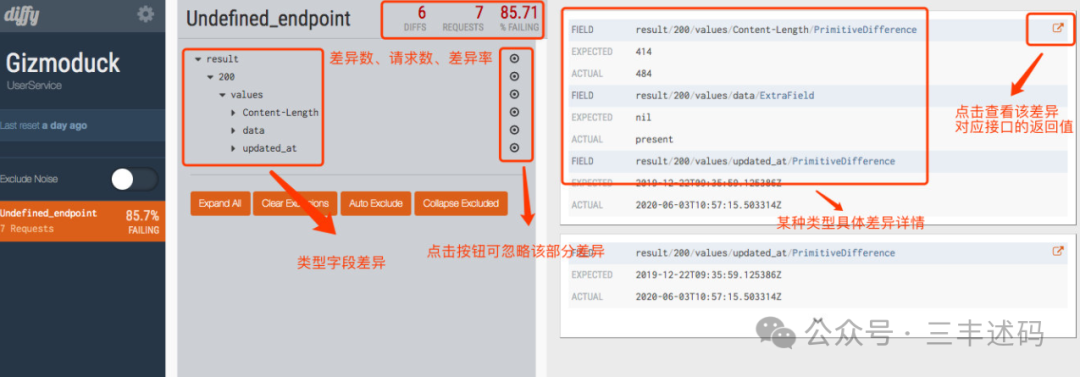
By sending test requests through the Diffy proxy service to the three different versions, we can see the difference results from Diffy as follows:
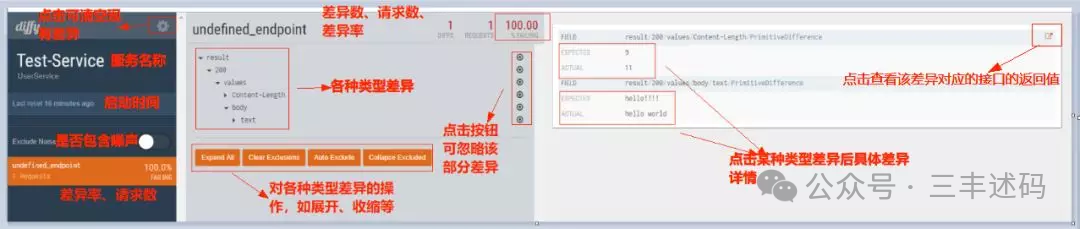
From the difference results of this example, we can see that a request was tested, and the results were inconsistent, so the failure rate is 100%. Upon checking the details, we find that the inconsistency lies in the specific values and lengths of the returned results. Therefore, Diffy’s results are consistent with the comparison services.
Open Source Address
Follow the public account and reply 20240824 to obtainYou might like:
[Open Source] Auxiliary College Education System, Supports Millions of Users for Online Education Platform System
What are the Advantages of Our Customized Development Projects
[Open Source] Visual Drag-and-Drop Programming, Automatically Generate Projects, Automatically Generate Code, Self-Import Third-Party Components
[Open Source] Next-Generation Crawler Platform, Define Crawling Processes in a Graphical Way, Complete Crawling Without Writing Code
[Free] Quickly Generate Videos from Stories, Free and Unlimited! Generate Original Videos in Minutes with AI! Includes Tutorial
Add WeChat to Join Relevant Group Chats,
Note “Microservices” to join the discussion group
Note “Low Start” to join the low start group discussion
Note “AI” to join the AI big data and data governance group discussion
Note “Digital” to join the Internet of Things and digital twin group discussion
Note “Security” to join the security-related group discussion
Note “Automation” to join the automation operation and maintenance group discussion
Note “Trial” to apply for product trials
Note “Channel” for cooperation channel information
Note “Customization” for project customization, full source code delivery