Linux Traffic Control

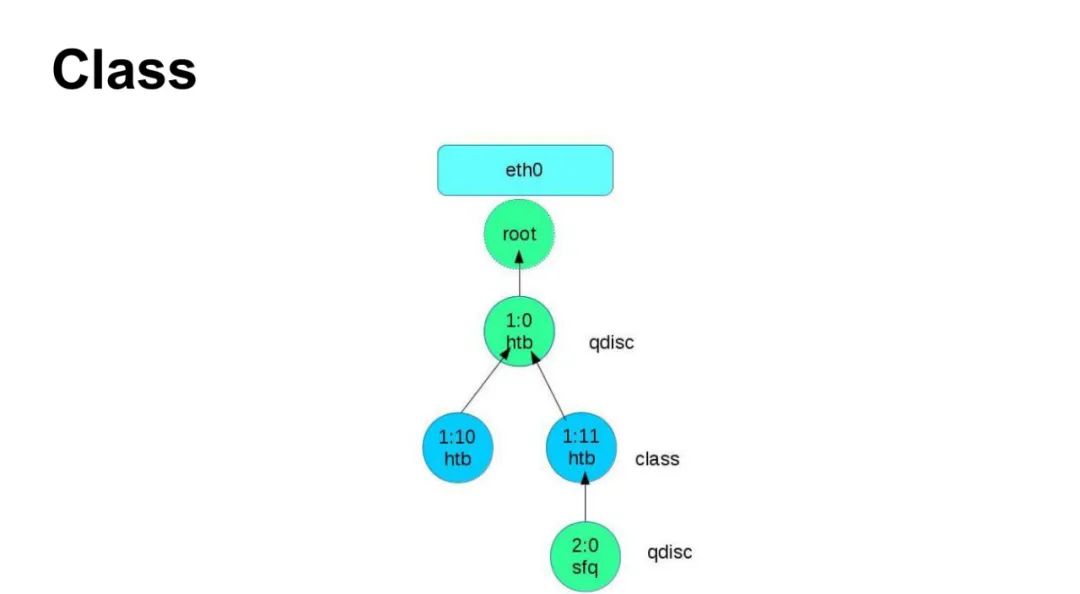
Overview● Queueing Discipline (Qdisc): Defines the queuing strategy for packets, such as First In First Out (<span>pfifo_fast</span>) or Hierarchical Token Bucket (<span>HTB</span>).● Class: Forms a hierarchical structure combined with queueing disciplines to allocate bandwidth priorities (e.g., assigning high priority to real-time traffic).● Filter: Classifies traffic based on rules (such as IP address, protocol type) and binds it to specific queues or classes.● Action: Performs operations on packets that match filter conditions (such as rate limiting, dropping, or redirecting).

for_each_packet(pkt, Qdisc): # Iterate through each packet in the Qdisc queue
for_each_filter(filter, Qdisc): # Iterate through all filters defined in the Qdisc
if filter(pkt): # If the packet matches the filter conditions (such as IP address, protocol type)
classify(pkt) # Classify the packet into the corresponding class
for_each_action(act, filter): # Execute all actions associated with the filter
act(pkt) # Actions include rate limiting, dropping, or redirecting, etc.


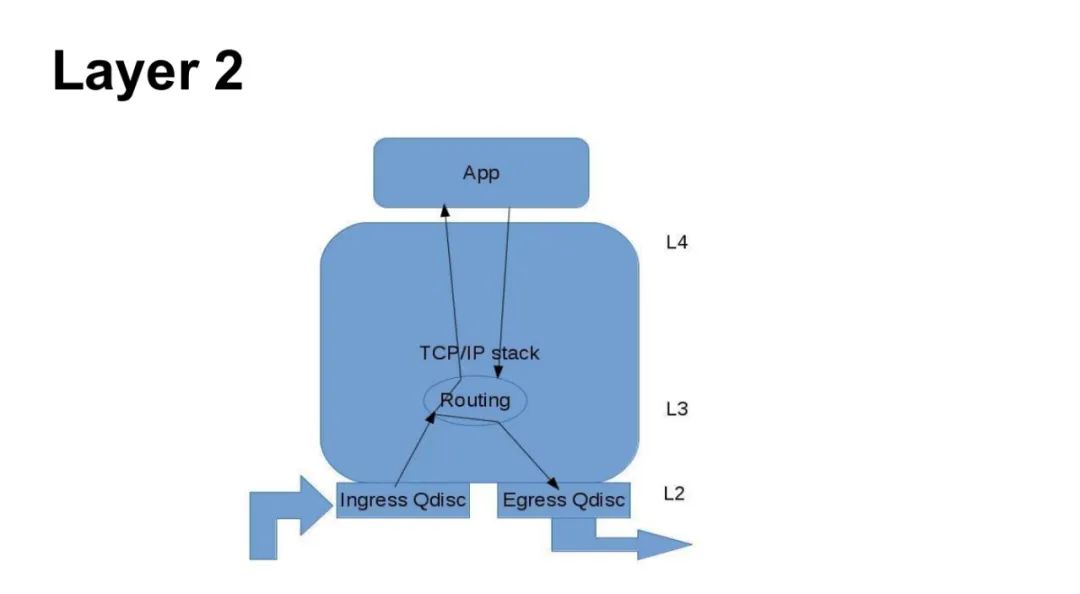
TC Queueing Discipline (Qdisc)
- Attached to Network Interface: Each Qdisc is bound to a specific network interface (e.g., eth0), configured via the
<span>tc qdisc add dev eth0 ...</span>command. - Can Form Hierarchical Structure via Classes: Supports parent-child class nesting (e.g., HTB hierarchy) for bandwidth allocation and priority management.
- Each Interface Has a Unique Handle: Handle format is like
<span>10:</span>, used to identify Qdisc and its subclasses. - Almost All Queueing Disciplines Are Used for Egress Traffic: By default, controls packet sending (e.g., rate limiting, scheduling), as the kernel has limited direct control over ingress traffic.
- Ingress Traffic Is a Special Case: Requires simulating ingress control through
<span>ingress</span>Qdisc (e.g.,<span>tc qdisc add dev eth0 ingress</span>), but still relies on egress queueing disciplines.

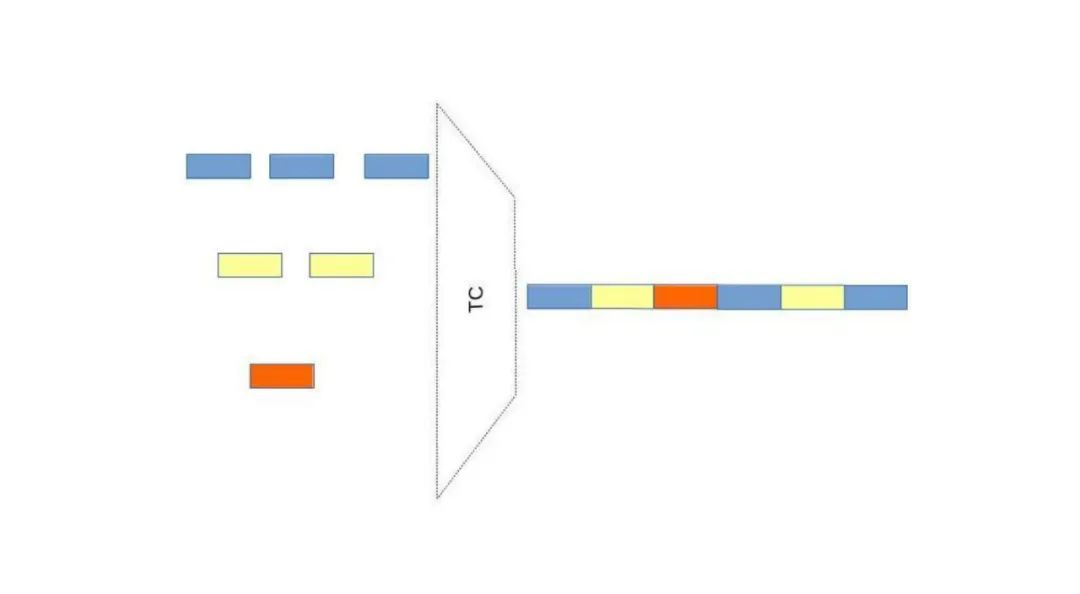
FIFO (First In First Out)
-
bfifo, pfifo, pfifo_head_drop
<span>bfifo</span>(Byte-level FIFO): Limits the queue by byte length<span>pfifo</span>(Packet-level FIFO): Limits the queue by the number of packets<span>pfifo_head_drop</span>: A variant of packet-level FIFO that prioritizes dropping packets from the head rather than the tail when the queue is full-
Single Queue, Simple and Efficient All packets are stored and processed in the order they arrive, with no complex scheduling logic, resulting in high throughput performance
-
No Flow Classification, No Fairness Does not distinguish between traffic types (e.g., TCP/UDP), nor guarantees fair bandwidth distribution among different flows
-
Drop Policy When the queue is full, can choose to drop packets from the tail (tail drop) or head (head drop).

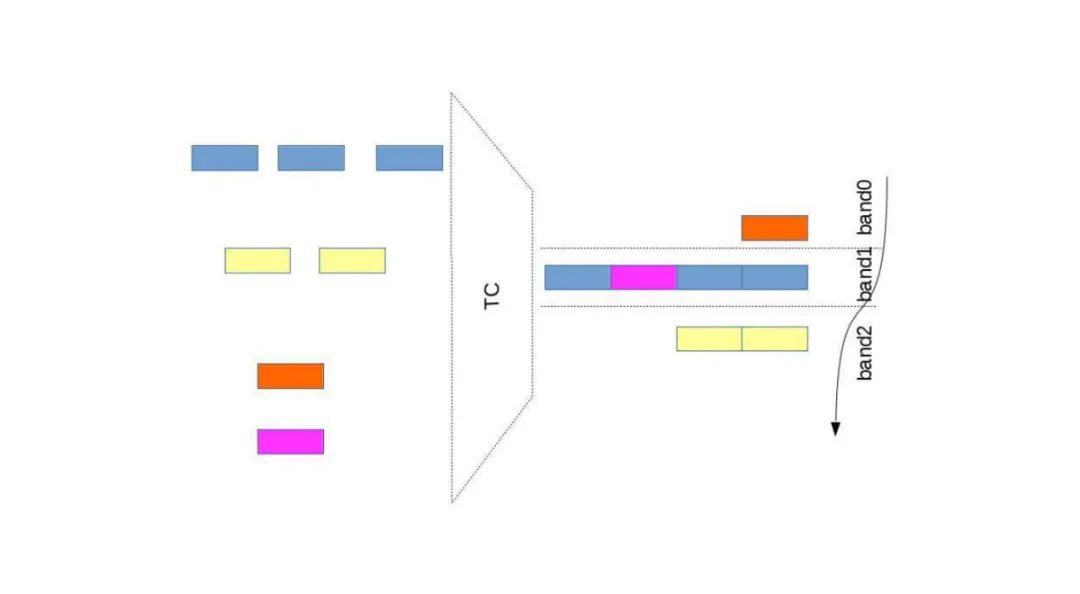
Priority Queueing
-
pfifo_fast, prio
<span>pfifo_fast</span>: The default egress queueing discipline in Linux, which includes 3 priority queues (bands 0-2), with decreasing priority.<span>prio</span>: Another multi-queue implementation that supports custom priority classification logic.-
Multiple Queues Each queue corresponds to a different priority, for example, the 3 bands of
<span>pfifo_fast</span>, where packets are allocated to different queues based on rules. -
Priority Service for High-Priority Queues Packets in high-priority queues (e.g., band 0) are always sent first, ensuring low latency for critical traffic (e.g., VoIP).
-
Using TOS Field for Priority Determines priority through the TOS (Type of Service) field in the IP packet header. For example,
<span>pfifo_fast</span>by default maps TOS values to 3 bands for automatic classification.
TOS Field and Priority Mapping
- The lowest 3 bits of the TOS field (i.e., priority bits) determine which band the packet enters. For example:
- TOS=0x10 (Priority 0) → Band 0 (Highest Priority)
- TOS=0x08 (Priority 1) → Band 1
- TOS=0x00 (Priority 2) → Band 2 (Lowest Priority)

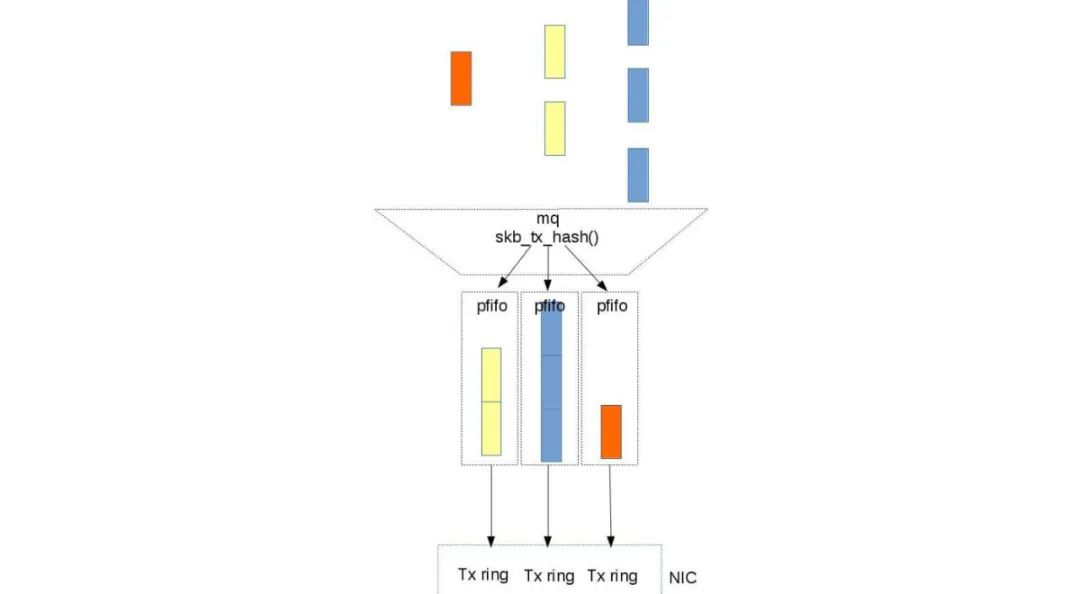
Multiqueue
-
mq, multiq General multiqueue mechanism that supports hardware-level parallel processing for network cards (e.g., virtio-net) or block devices (e.g., SSD).
-
Applicable to Multiple Hardware Transmit Queues (TX queues) Distributes traffic across multiple independent hardware queues, leveraging multi-core CPUs for parallel processing, significantly improving throughput (e.g., public cloud NIC multiqueue).
-
Queue Mapping Methods
- Hash: Calculates hash values based on fields like IP/port to allocate queues (e.g., NIC multiqueue).
- Priority: Maps to different queues based on traffic priority (e.g., TOS field).
- Classifier: Dynamically allocates based on custom rules (e.g., iptables marking).
-
Combined with Priority: mq_prio A multiqueue implementation with priority scheduling (e.g.,
<span>mq_prio</span>Qdisc), allowing high-priority traffic to monopolize hardware queues, ensuring low latency.
Multiqueue and Hardware Acceleration
- NIC multiqueue distributes traffic through RSS (Receive Side Scaling) or VMDq technology to avoid single-core CPU bottlenecks
- Block device multiqueue (e.g., blk-mq) separates each CPU software queue and hardware queue, reducing lock contention and improving IOPS
Typical Application of mq_prio
In real-time systems, mq_prio can map VoIP traffic to high-priority queues while ordinary traffic uses low-priority queues, ensuring quality of service for critical business services
Support for Virtualization Environments
The multiqueue feature of virtio-net allows each vCPU of a virtual machine to monopolize a queue, avoiding Hypervisor scheduling delays.

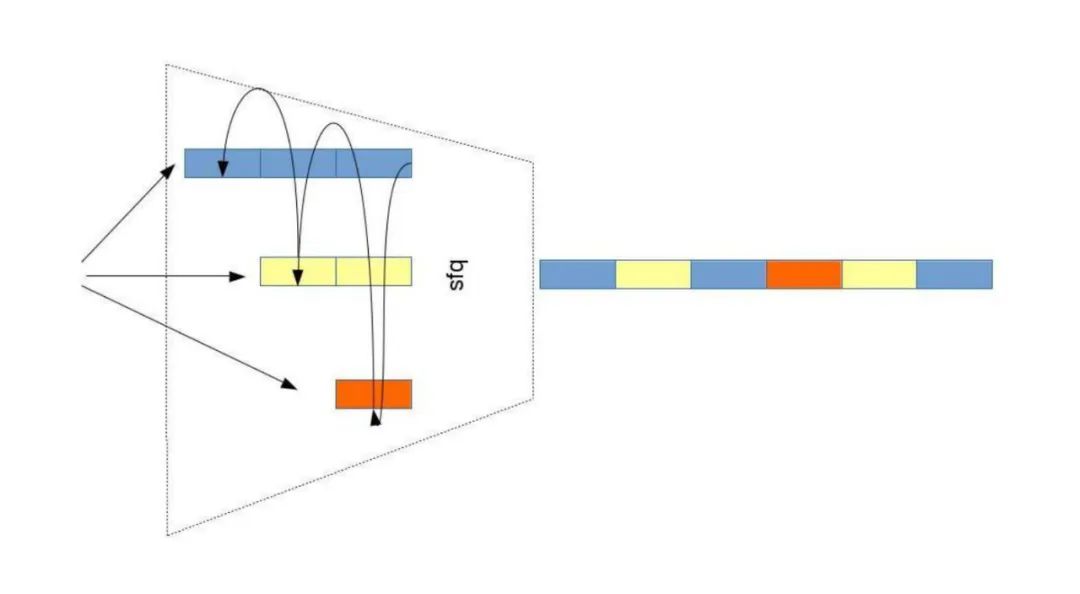
Fair Queueing
-
Each Flow Fairly Shares the Link The core goal of fair queueing is to ensure that different traffic (e.g., TCP connections) fairly share bandwidth as needed, avoiding a single flow monopolizing resources. For example, multiple recharge windows at a subway station in Shanghai achieve equal service through fair queueing.
-
Polling Scheduling, No Weights: sfq
<span>sfq</span>(Stochastic Fair Queueing) serves each sub-queue in a round-robin manner, assuming equal packet lengths, ensuring fairness among flows.- Sub-queues are classified by flow (e.g., IP+port) and allocated through hashing to avoid reordering of packets from the same flow.
-
Deficit Round Robin: drr
<span>drr</span>(Deficit Round Robin) supports variable packet lengths, dynamically adjusting service order through a “deficit counter”. For example, if a queue has larger packets, its deficit value accumulates, ensuring long packets do not permanently occupy bandwidth.-
Max-Min Fairness Resource allocation principle: prioritize meeting minimum demands. For example, if A needs 1Mbps, B needs 2Mbps, and total bandwidth is 3Mbps, then A gets 1Mbps, B gets 2Mbps; if total bandwidth is only 2Mbps, then A gets 1Mbps, B gets 1Mbps.
-
Socket Flow Parsing + Rate Limiting: fq
<span>fq</span>(Fair Queueing) combines flow parsing (e.g., based on socket classification) and rate limiting (pacing), preventing burst traffic from causing congestion. For example, Hadoop’s fair scheduler allocates computing resources through a similar mechanism.
Comparison of SFQ and DRR
- sfq is suitable for small-scale flows, relying on fixed polling; while drr adapts to variable packet lengths through the deficit mechanism, making it more suitable for complex scenarios (e.g., mixed video streaming and file transfer)
Implementation of Max-Min Fairness
- Achieved by dynamically calculating each flow’s “fair share”, such as weighted fair queueing (WFQ) allows allocating weights for different priority flows, achieving proportional bandwidth distribution
Application of FQ in Linux
- Linux’s fq queueing discipline is often used for congestion control (e.g., BBR algorithm), reducing network jitter through rate limiting, enhancing the experience of real-time applications (e.g., gaming)

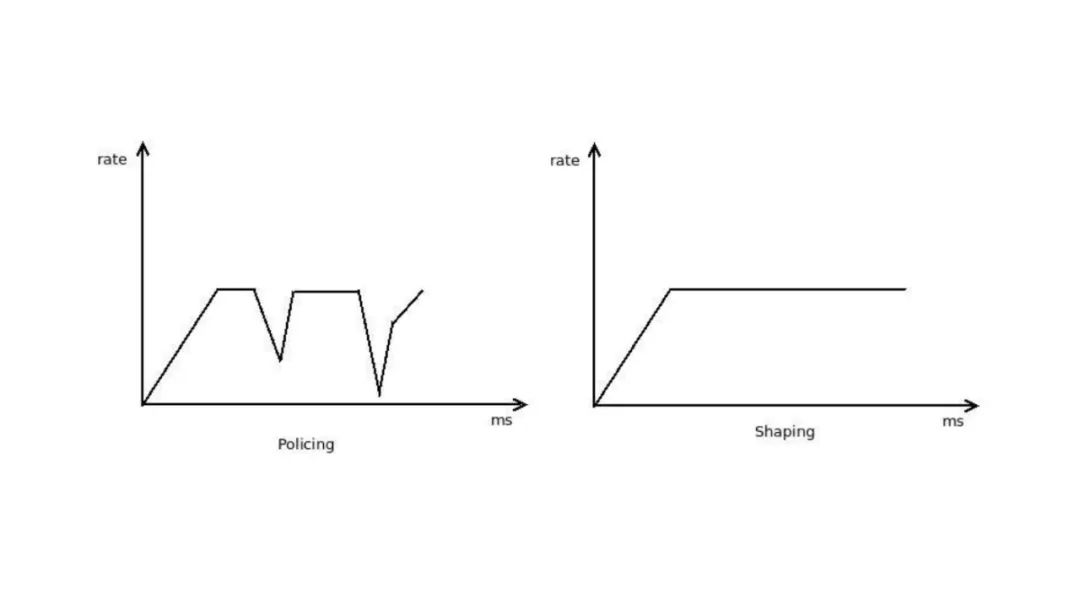
Traffic Shaping
- Shaping Buffers and Delaying Packets Smooths the output rate of traffic through buffering mechanisms, avoiding burst traffic from impacting downstream devices (e.g., when transmitting from high-speed links to low-speed links).
- Policing Mainly Discards Packets Unlike shaping, policing directly discards traffic that exceeds rate limits (e.g., using
<span>htb</span>or<span>tbf</span>discard strategies). - Buffering Means Delay Accumulating packets in buffers increases end-to-end delay, which may affect real-time applications (e.g., VoIP).
- CBQ is Complex and Difficult to Understand Class-Based Queueing (CBQ) implements hierarchical bandwidth control through complex algorithms, but is difficult to configure and prone to errors.

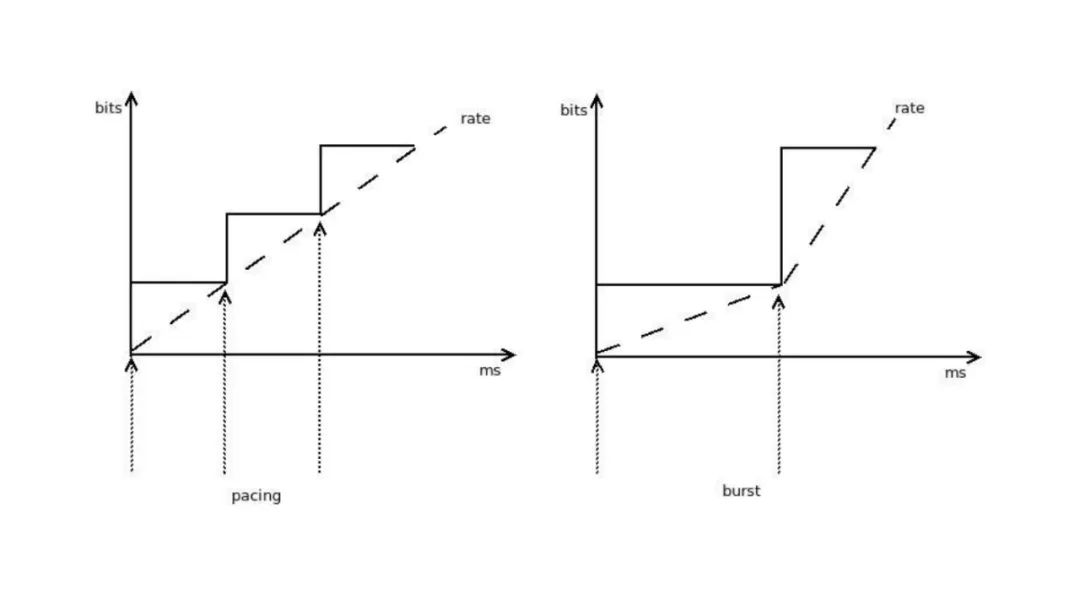
Token Bucket Filter (TBF)
- Each Token Represents One Bit The token bucket generates tokens at a fixed rate (e.g., 100 tokens per second), with each token allowing the transmission of 1 bit of data.
- Token Bucket Fills at a Constant Rate For example, if the configured rate is 1Mbps, then 1 million tokens are generated per second (1 token = 1 bit).
- Only Send When Tokens Are Sufficient Packets must consume tokens equivalent to their size to be sent; otherwise, they must wait for tokens to accumulate.
- Unused Tokens Can Accumulate, Supporting Burst Traffic Allows temporarily exceeding the configured rate (e.g., burst transmission of large files), but is limited by the bucket’s capacity.
- Tail Drop May Still Occur If the bucket is full and no tokens are available, subsequent packets will be dropped (e.g., TBF’s default drop strategy).
- Large Packets May Block Small Packets Large packets consume more tokens, potentially causing delays for small packets (which must wait for tokens to regenerate).

Hierarchical Token Bucket (HTB)
- Essentially a Token Bucket (TBF) with Classification Support HTB is based on the token bucket algorithm but implements fine-grained bandwidth management through a hierarchical structure, allowing parent and child classes to nest.
- Supports Link Sharing Multiple subclasses can share bandwidth allocated by the parent class (e.g., if the parent class allocates 100Mbps, subclasses 1 and 2 each get 50Mbps).
- Predefined Bandwidth Allocation Each class’s bandwidth must be pre-configured (e.g.,
<span>rate</span>and<span>ceil</span>parameters), with excess being dropped based on priority. - Difficult to Precisely Control Queue Length and Delay The queue depth of HTB depends on buffer configuration; excessive buffering may lead to high latency (needs to be optimized with tools like
<span>netem</span>).

Hierarchical Fair Service Curve (HFSC)
- Proportional Bandwidth Allocation Defines bandwidth allocation ratios through service curves (Service Curve), for example, allocating 70% bandwidth for real-time traffic and 30% for ordinary traffic.
- Leaf Nodes: Real-Time and Shared Link Combination Leaf classes can set both a real-time service curve (guaranteeing minimum latency) and a link sharing curve (dynamically allocating idle bandwidth).
- Internal Nodes: Only Link Sharing Parent classes (inner classes) are only responsible for proportional bandwidth allocation, not directly handling real-time requirements.
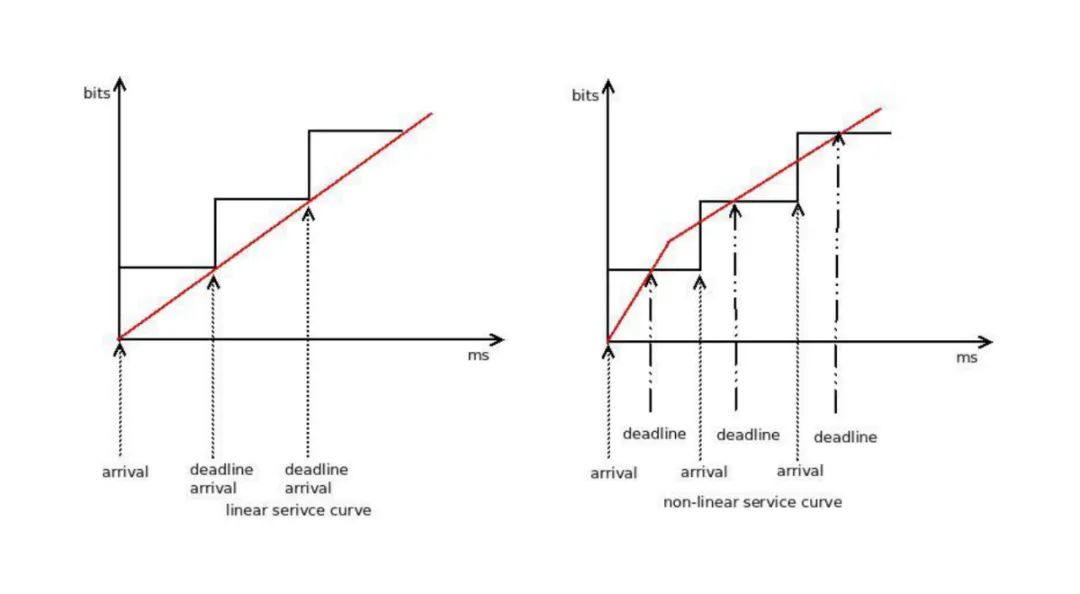
- Allows Higher Rates for Real-Time Traffic For example, the service curve for VoIP traffic can be configured as
<span>sc m1 100mbit d 10ms</span>, ensuring at least 100Mbps within 10ms. - Non-Linear Service Curves Decouple Delay and Bandwidth By independently defining service curves for delay and bandwidth, it avoids the mutual constraints of both in traditional algorithms (e.g., the complexity of CBQ).
Comparison of HTB and HFSC
-
HTB: Suitable for simple hierarchical bandwidth allocation, intuitive configuration (e.g., tc class add … htb), but weak delay control
-
HFSC: Achieves precise decoupling of delay and bandwidth through service curves, suitable for scenarios with high real-time requirements (e.g., video conferencing), but complex to configure
 Active Queue Management (AQM)
Active Queue Management (AQM)
- Bufferbloat is a Delay Issue Excessive buffering in network devices can lead to a surge in packet queuing delays (e.g., the bufferbloat phenomenon in Linux systems), severely impacting real-time applications (e.g., video calls).
- Manage Delay Rather Than Just Focus on Bandwidth AQM dynamically adjusts queue lengths, prioritizing delay control over maximizing throughput.
- Tail Drop Damages TCP Performance Traditional tail drop can frequently trigger TCP tail loss probe, reducing transmission efficiency.
- Modern AQM Queueing Disciplines Do Not Require Manual Parameter Tuning For example,
<span>codel</span>and<span>pie</span>algorithms automatically optimize parameters through adaptive mechanisms, reducing the complexity of manual configuration. - Mainstream AQM Algorithms:
<span>RED</span>(Random Early Detection)<span>CoDel</span>(Controlled Delay)<span>PIE</span>(Proportional Integral Enhanced)<span>HHF</span>(Hybrid Head Drop)
 Controlled Delay (CoDel)
Controlled Delay (CoDel)
- Directly Measures Delay Through Timestamps CoDel records the time packets enter and exit the queue, calculating actual queuing delay (e.g.,
<span>sojourn time</span>). - Distinguishes Between “Good Queues” and “Bad Queues”
- Good Queue: Absorbs short burst traffic (e.g., instantaneous peaks during webpage loading).
- Bad Queue: Sustained high-delay queues trigger drop strategies.
- Accelerated Dropping to Suppress Bad Queues If delays persist beyond a threshold (e.g., 5ms), CoDel gradually increases the drop rate, forcing the sender to reduce speed.
- Head Drop Prioritizes dropping the head packet in the queue, avoiding TCP retransmission storms (e.g., an improved version of
<span>pfifo_head_drop</span><code><span>).</span>

Ingress Traffic Control
- Only Supports Ingress Queueing Rules In Linux, ingress direction can only use
<span>ingress</span>Qdisc, and cannot directly apply complex scheduling strategies (e.g., HTB). - No Classes, Only Filtering Ingress control relies on filters to classify traffic, and cannot manage through hierarchical classes.
- Only Policing, Shaping Difficult Ingress traffic shaping requires intermediate virtual interfaces (e.g.,
<span>ifb</span>module), as hardware queues typically only support egress shaping. - Requires Transport Layer Support Requires feedback mechanisms from protocols like TCP or RSVP (e.g., ECN marking) to achieve ingress rate control.
Hack: IFB Device
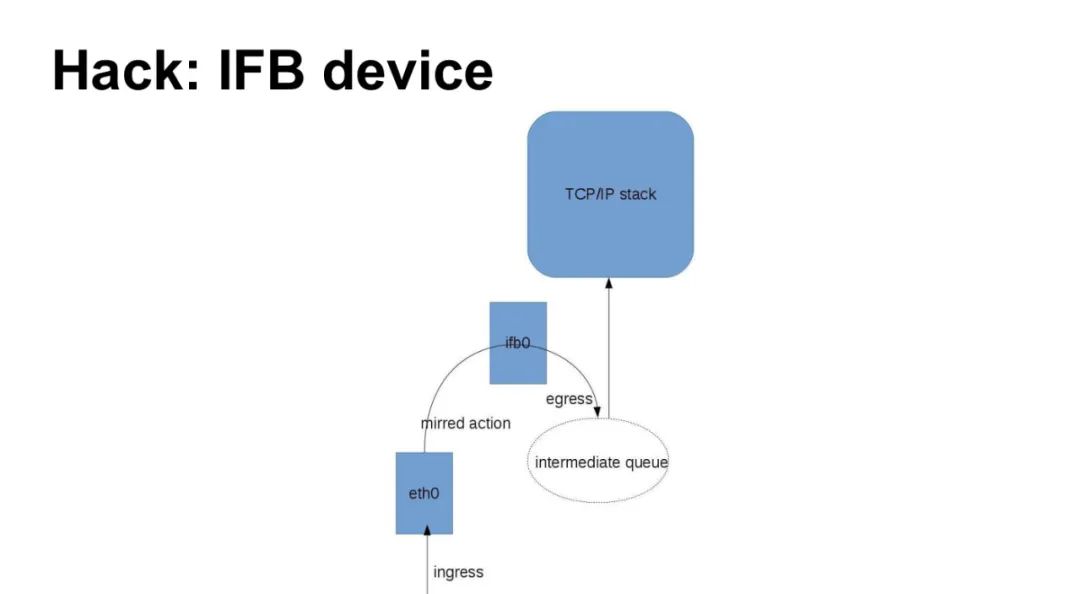
IFB (Intermediate Functional Block Device) is a virtual network device in Linux used for ingress traffic control, as an improved version of IMQ (Intermediate Queue Device). Its core function is to redirect ingress traffic to a virtual interface (e.g., ifb0), thereby bypassing hardware queue limitations and achieving ingress traffic shaping.
Typical Use Case:
# Mirror ingress traffic from eth0 to ifb0 and apply HTB queueing discipline
tc qdisc add dev eth0 ingress
tc filter add dev eth0 parent ffff: protocol ip u32 match u32 0 0 action mirred egress redirect dev ifb0
tc qdisc add dev ifb0 root htb
This configuration redirects ingress traffic to ifb0 through the mirred action, achieving ingress rate limiting.

TC Filters (TC Filter)
- Also Known as Classifier Matches packets through rules and classifies them into specific queues or classes (e.g., subclasses of HTB).
- Attached to Queueing Discipline (Qdisc) Filters must be bound to a Qdisc (e.g.,
<span>ingress</span>or<span>htb</span>), for example:
tc filter add dev eth0 parent 1:0 prio 1 u32 match ip src 192.168.1.0/24 flowid 1:10
This command classifies traffic from source IP 192.168.1.0/24 into HTB class 1:10.
- Matching Rules
Support conditions such as protocol, priority, handle, etc.
- Requires Qdisc Support
For example, clsact Qdisc is designed for efficient classification, supporting both ingress and egress directions.

Available Filters
| Filter | Function and Example |
|---|---|
| cls_u32 | Matches based on 32-bit fields (e.g., IP address, port), the most commonly used filter. |
| cls_basic | Combines complex conditions using <span>ematch</span> expressions (e.g., <span>ether protocol ip</span>). |
| cls_cgroup | Classifies traffic based on cgroup (e.g., allocating bandwidth for specific containers). |
| cls_bpf | Defines flexible matching logic through BPF syntax (e.g., custom protocol parsing). |
| cls_fw | Classifies based on <span>skb->mark</span> (marked by <span>iptables</span> or <span>nftables</span>). |

TC Actions (TC Action)
- Originally Called Policing Actions define operations after matching (e.g., rate limiting, redirecting), now expanded to a more general
<span>action</span>framework. - Attached to Filters Each filter can associate multiple actions, executed in order (e.g., first mark then redirect).
- Operations Executed After Packet Matching For example,
<span>act_mirred</span>redirects traffic,<span>act_police</span>rate limits or drops packets. - Bind or Share Actions can be shared through
<span>index</span>(e.g., multiple filters reuse the same rate limiting strategy). - Index Identifies action instances through
<span>index</span>, supporting reuse across filters (e.g.,<span>action index 1</span>).

Available Actions
- act_mirred: Mirrors and redirects packets (e.g., redirecting ingress traffic to
<span>ifb0</span>virtual interface). - act_nat: Implements stateless NAT (modifies source/destination IP or port of packets).
- act_police: Traffic policing (rate limiting or dropping excess traffic), implemented based on the token bucket algorithm.
- act_pedit/act_skbedit: Edits packet content (e.g., modifies protocol header fields) or socket buffer (
<span>skbuff</span><span>) metadata.</span> - act_csum: Automatically calculates or corrects the checksum of packets (e.g., TCP/UDP checksum).
 Sourcehttps://events.static.linuxfound.org/sites/events/files/slides/Linux_traffic_control.pdf
Sourcehttps://events.static.linuxfound.org/sites/events/files/slides/Linux_traffic_control.pdf