Disclaimer

Crack detection, especially in the domain of pavement images, faces significant challenges in the field of computer vision due to inherent complexities such as uneven intensity, complex topology, low contrast, and noisy backgrounds. Automatic crack detection is crucial for maintaining the structural integrity of critical infrastructure, including buildings, pavements, and bridges.
Existing lightweight methods often face issues such as low computational efficiency, complex crack patterns, and difficult backgrounds, leading to inaccurate detection and unsuitability for practical applications.
To overcome these limitations, the authors propose EfficientCrackNet, a lightweight hybrid model that combines Convolutional Neural Networks (CNNs) with Transformers for precise crack segmentation. EfficientCrackNet integrates Depthwise Separable Convolution (DSC) layers and Mobile Vision Blocks to capture global and local features. The model employs an Edge Extraction Method (EEM) for efficient crack edge detection without the need for pre-training and enhances feature extraction with an Ultra-Lightweight Subspace Attention Module (ULSAM).
Extensive experiments conducted on three benchmark datasets—Crack500, DeepCrack, and GAPs384—demonstrate that EfficientCrackNet outperforms existing lightweight models, requiring only 0.26M parameters and 0.483 GFLOPs (G).
The proposed model finds an optimal balance between accuracy and computational efficiency, surpassing state-of-the-art lightweight models and providing a robust and adaptable solution for practical crack segmentation.
1 Introduction
Figure 1: Evaluation of parameters, mIoU, and FLOPs (G) on the Crack500 test dataset. The bubble radius represents the model’s FLOPs (G).
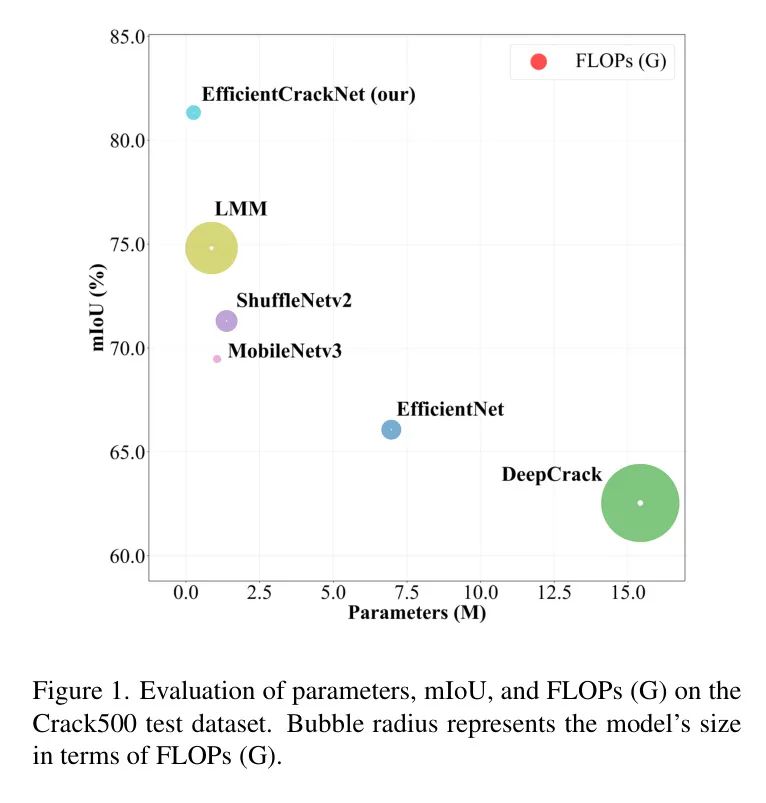
Cracks are common structural failures in residential buildings, pavements, and bridges, often caused by insufficient load-bearing capacity, which can jeopardize safety. The gradual propagation of cracks can affect the integrity and durability of structures. Therefore, identifying and inspecting cracks is crucial for assessing and maintaining structural safety. A study in 2006 estimated that traffic casualties due to road conditions resulted in losses of $217.5 billion, representing 43.6% of the total losses from all accidents in the United States. The American Society of Civil Engineers (ASCE) rated the condition of U.S. highway infrastructure as “D” in its 2021 infrastructure report, indicating poor conditions and risk. An analysis of the U.S. Interstate Highway System found that 11% of interstate pavements are in poor or fair condition, with 3% classified as poor and 8% as fair.
Given these serious issues, improving the safety, functionality, and durability of highway infrastructure is critical. Effectively monitoring structural health and assessing road conditions can facilitate rapid decision-making and handling. Manual crack detection and segmentation is a time-consuming task that requires significant expertise. Therefore, automating crack segmentation is essential for expediting concrete pavement surveys. The main challenges in crack segmentation include uneven intensity, inconsistent contrast, and cluttered backgrounds.
Visual-based crack segmentation methods have gained widespread attention in academia and industry in recent years due to their objectivity, cost-effectiveness, efficiency, and safety. Over the past decade, deep learning has experienced a resurgence, achieving significant success in various computer vision applications. Currently, many semantic segmentation algorithms used for crack segmentation research rely on Convolutional Neural Networks (CNNs). The advantage of CNNs lies in their convolutional kernels, which possess translation invariance and local sensitivity, enabling them to capture local spatial features accurately. However, convolution operations, due to their fixed receptive fields, are effective in recognizing local patterns but limited in capturing global contextual features or long-range dependencies.
In semantic segmentation, relying solely on local features for pixel-level classification can lead to ambiguity, while combining global contextual features can improve the semantic content accuracy of each pixel. However, the ability of convolutional kernels to understand and establish the overall structure of an image and the relationships between different features is limited, making it challenging to improve the accuracy of crack segmentation. In contrast, Transformer-based networks can capture global contextual features, providing a potential solution to these challenges. However, these performance gains come at the cost of model size. Many practical applications require timely execution of visual recognition tasks on resource-constrained handheld devices.
Numerous studies have proposed various deep learning models for crack segmentation, which often rely on high-performance computing devices such as Graphics Processing Units (GPUs). These models typically have many parameters and require stable, well-controlled environments, such as data centers, to ensure reliable operation. However, due to these dependencies, their practical applications in real-world external environments, such as typical crack segmentation tasks, are limited. In contrast, physical-based systems, such as drones and mobile robots, have achieved significant success in real-world applications.
Devices like NVIDIA Jetson TX2, Jetson Nano, and Jetson Xavier NX are widely used in edge computing due to their portability, energy efficiency, and compact form factor, making them ideal for real-world applications. These devices can be mounted on Unmanned Aerial Vehicles (UAVs) or robotic platforms for inspecting infrastructure such as high-rise buildings, bridges, tunnels, and roads. Therefore, despite the success of deep learning models in precise segmentation performance, their use in practical, field applications remains limited. Edge computing devices provide a more practically valuable solution to tackle these challenging environments.
2 Related Works
In previous studies, most CNN models for crack segmentation were based on U-Net, which is the most well-known CNN-based model and has been widely applied in crack segmentation [14, 15, 20]. Other CNN-based models, such as FCNs [2, 45], SegNet [37, 7], DeepLab [42], and Mask R-CNN [55], have also been used in various studies for crack segmentation. Furthermore, CNN-based models have been combined with other attention modules [13]. For instance, integrating attention gate modules into U-Net enhances crack feature extraction by prioritizing important areas and reconstructing semantic features, improving crack segmentation performance [27]. Another study enhanced DeepLabv3+ by using multi-scale attention modules combined with multi-scale crack features [42]. Similarly, an attention module was integrated into the DCANet backend network, combining detailed and abstract features to improve the overall performance of the model, thereby recovering edge information from cracks [38]. However, CNN-based models struggle to capture explicit long-range dependencies due to their inherent local nature.
Since most cracks occupy only a small portion of the image, capturing both local and non-local features is necessary for accurate crack segmentation [8]. Transformer-based models have shown significant performance in crack segmentation [29, 61]. One study developed SegCrack using MMSegmentation and OHEM strategies to improve the accuracy of crack segmentation [41, 46].
Subsequently, another study proposed the Crack Transformer [17], which combines elements from Swin Transformer [32] and SegFormer [50]. However, training Transformer-based models can be challenging in the early stages and prone to overfitting on limited datasets [31]. Recently, there has been increasing interest in hybrid models that combine CNNs and Transformers.
Unlike CNNs, Transformers possess strong capabilities for modeling long-range dependencies. However, cracks typically occupy only a small portion of the image. Therefore, relying solely on Transformers may lead to background interference, resulting in reduced overall segmentation performance. Using hybrid models can compensate for this drawback [49, 51, 65]. Mobile devices (such as drones and smartphones) often have limited computing power, memory capacity, and battery life. Therefore, the authors aim to explore a compact hybrid model to create a network whose lightweight structure can improve crack segmentation accuracy.
3 Methodology
This section primarily introduces the architectural components of the proposed model. The proposed EfficientCrackNet model consists of three main parts: encoder, bottleneck, and decoder. The key components in the EfficientCrackNet model are the Edge Extraction Method (EEM), Ultra-Lightweight Subspace Attention Mechanism (ULSAM), and MobileViT block.
Edge Extraction Method (EEM)
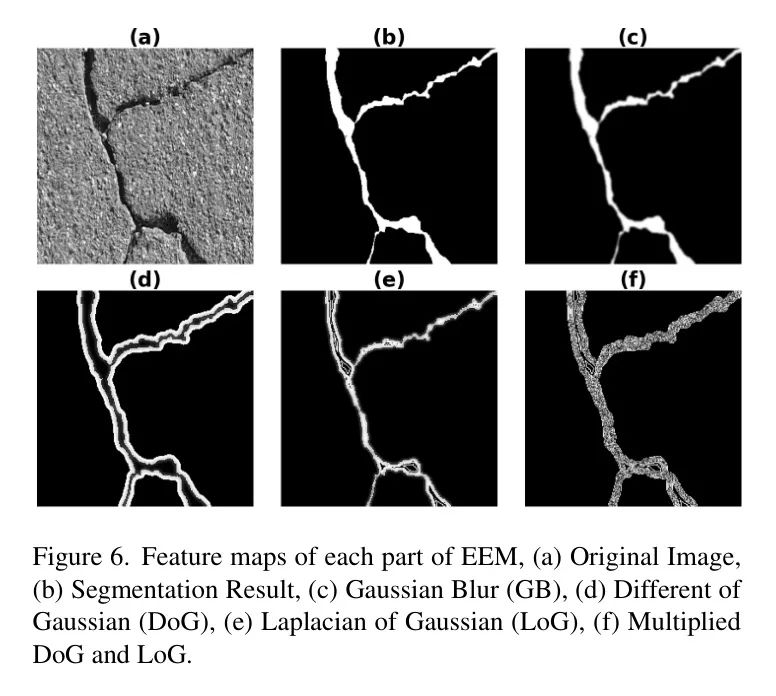
The authors adopted the Edge Extraction Method (EEM) by combining two traditional edge detection methods, Difference of Gaussian (DoG) and Laplacian of Gaussian (LoG), along with convolutional layers. Ultimately, the authors obtained a trainable EEM that can learn edge features without requiring separate edge label training while minimizing the number of parameters.
For edge extraction, EEM first convolves the input image with a Gaussian kernel of size (3, 3) to apply Gaussian blur, smoothing high-frequency components while preserving the overall structure of objects in the image by retaining low-frequency features.
Secondly, the mathematical formula for DoG is given by Equation (1), where the convolved input image is subtracted from the original input image to extract the object boundaries and edges between the complete image and the low-frequency features in the input. This process is similar to a band-pass filter effect. Furthermore, combining Gaussian and Laplacian kernels yields a LoG kernel, expressed in Equation (2). Convolving this LoG kernel with the input image performs second-order derivatives, thus only extracting those edges with significant changes.
(Figure 2) Edge Extraction Method (EEM).
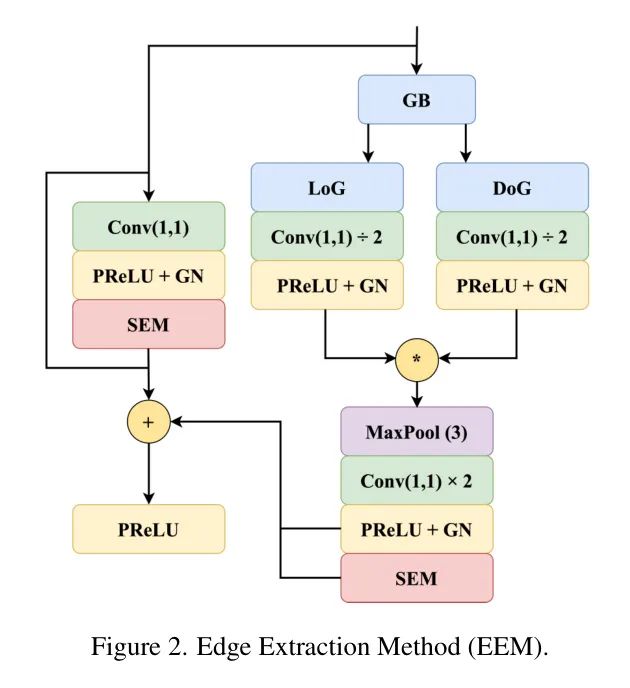
Integrating SEM into residual connections emphasizes key features, ensuring the preservation and effective utilization of edge features, which is crucial for crack segmentation. Therefore, integrating SEM into residual connections allows EEM to enhance and maintain edge features, which is essential for accurate crack detection and segmentation. The structure of EEM is shown in Figure 2.
Ultra-Lightweight Subspace Attention Module (ULSAM)
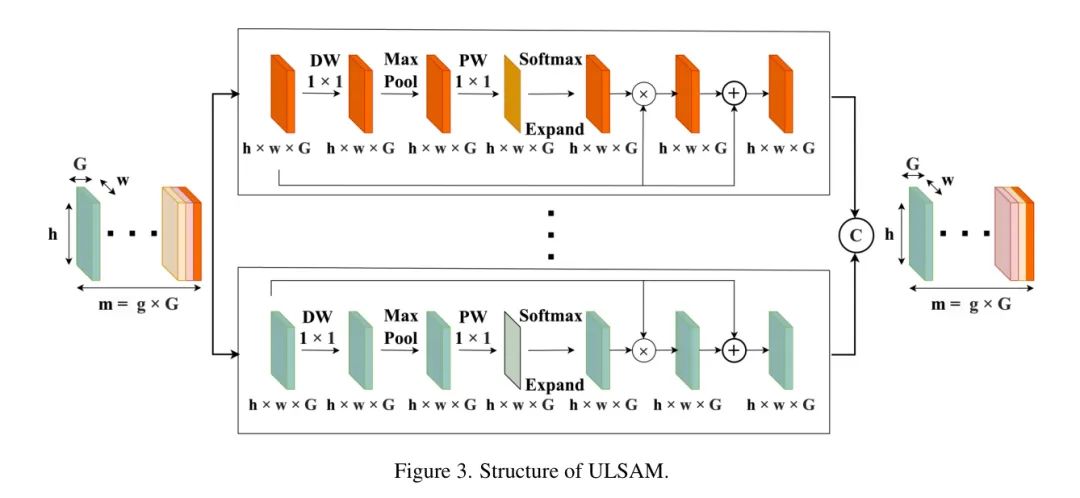
The attention mechanism can effectively perform global dependency modeling and provide an infinite receptive field. Multi-scale convolution structures have the potential to yield more detailed features; however, interference from irrelevant features may occur [48, 60]. To address this issue, it is essential to implement an attention mechanism. The currently state-of-the-art attention mechanisms are not suitable for the authors’ lightweight model due to their computational and/or parameter overhead. Therefore, this study employs a simple, effective, and lightweight attention mechanism, ULSAM. ULSAM uses a single attention map for each feature subspace. Initially, ULSAM employs depthwise convolution (DW) and subsequently applies a single filter in the pointwise convolution (PW) stage to generate the attention map. This approach significantly reduces computational complexity.
Using symbols, let F represent the feature map obtained from the convolutional layer with dimensions (m, h, w), where m represents the number of input channels, and h and w represent the spatial dimensions. In ULSAM, the feature map (F) is divided into g different groups ([F1, F2, … , F_bar{n}, … , F_g]), each containing G feature maps. Group F_bar{n} represents a specific set of these intermediate feature maps, and the subsequent steps outline the processing.
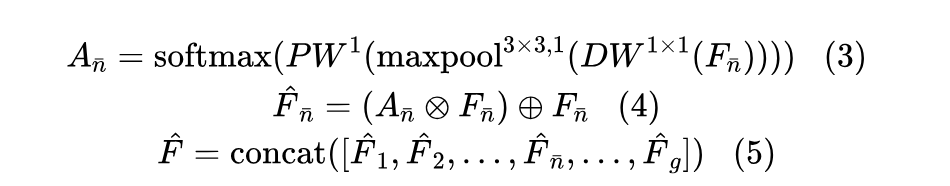
In Equation 3, the attention map is generated from a series of intermediate feature maps. Equation 4 describes how the feature maps within each group are refined to obtain enhanced feature maps, utilizing feature distributions; represents element-wise multiplication, and represents element-wise addition. By concatenating the feature maps of each group, ULSAM generates the output. This method allows ULSAM to capture features of various scales and frequencies while also facilitating effective cross-channel feature utilization within the network [39]. As shown in Figure 3, the structure of ULSAM is illustrated.
MobileViT block
The Mobile Vision Transformer (MobileViT) module consists of three different sub-modules: local feature encoding, global feature encoding, and feature fusion. Each sub-module is responsible for extracting local features, capturing global features, or merging the extracted features, respectively. The Mobile Vision Transformer maintains a low number of parameters while efficiently extracting image features, making it an ideal choice for applications constrained by computing resources.
The input tensor first undergoes a convolution layer, followed by a pointwise (or) convolution layer output. The convolutional layer captures local spatial features, while the pointwise convolution maps the tensor to a higher-dimensional space ((dd>C).
The Mobile Vision Transformer enhances the network’s ability to perceive global and local features, thus improving feature extraction capabilities compared to traditional convolutional modules. This convolution operation allows the transformer to learn positional features, requiring fewer transformer modules to learn more features, making it lightweight [36].
Encoder
The design goal of the network is lightweight, efficient, and robust. To keep the model lightweight, depthwise separable convolution (DSC) [18] is used in this study. Many efficient network architectures use DSC as their fundamental component [58, 21, 40]. DSC significantly reduces the computational load and the total number of parameters in the network, thereby improving efficiency.
DW and PW play different roles in feature generation: DW primarily focuses on identifying spatial relationships, while PW emphasizes capturing cross-channel correlations [18]. Batch normalization (BN) and ReLU activation functions are applied after the DSC layers.
The encoding part of the network utilizes EEM, ULSAM, and MobileViT blocks. EEM enhances the model’s capability to delineate external crack boundaries. EEM employs a combination of Gaussian and Laplacian filters to effectively extract edges. This module can highlight edges and details, making it particularly suitable for crack segmentation.
ULSAM primarily adopts a subspace attention mechanism. This allows the proposed model to simultaneously capture features of different scales and frequencies while facilitating effective utilization of cross-channel features. Designed with fixed receptive field convolution operations, it can detect local patterns but is inherently difficult to capture global context or long-term dependencies. The MobileViT block addresses this limitation by allowing the model to encode local and global features efficiently.
Decoder
As shown in Figure 4: the framework of EfficientCrackNet.
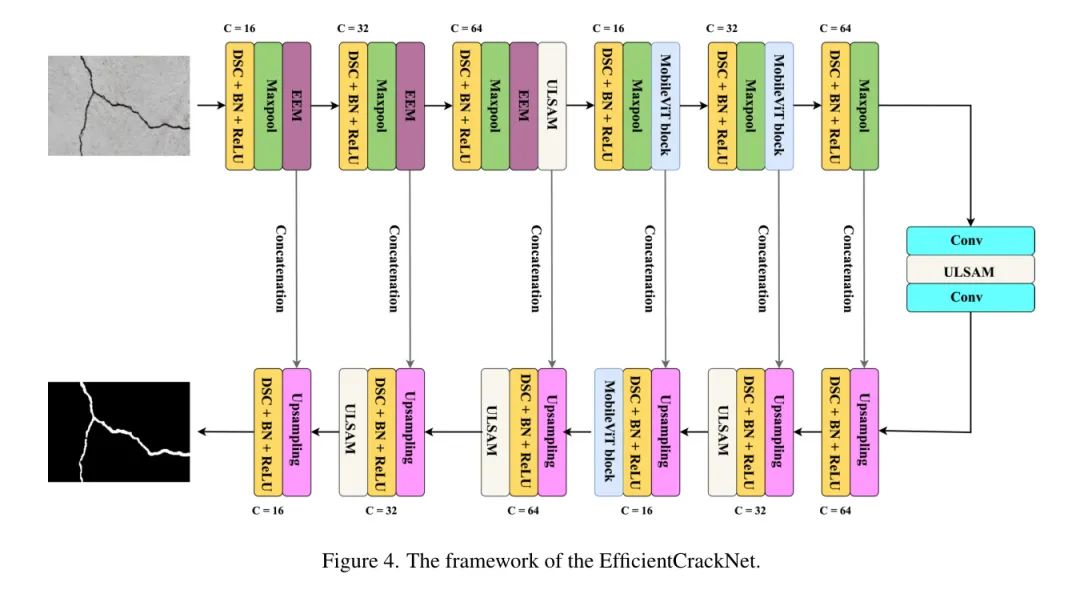
Similar to the encoder, the decoding part of the network integrates several advanced components, such as DSC (Directional Short-Circuit Connections), upsampling, concatenation blocks, ULSAM (Multi-Scale Fusion), and MobileViT blocks to achieve a robust and efficient design.
The decoder path first increases the resolution of the feature maps and then combines them with the corresponding feature maps from the encoder to retain spatial information. DSC is also used in the decoder to maintain the efficiency and lightweight characteristics of the network. Each upsampling step is concatenated with the corresponding feature map from the encoder, allowing the decoder to leverage high-level abstract features and low-level detailed features.
This skip connection strategy ensures that the decoder retains important spatial features from the encoder. ULSAM is integrated into the decoder to enhance cross-channel interdependencies and multi-scale feature learning. The MobileViT block is integrated into the decoder to improve the model’s ability to capture both local and global features.
4 Experiments and Analysis
Datasets
This study utilized the Crack500, DeepCrack, and GAPs384 datasets.
Crack500: The Crack500 dataset includes 447 images with a resolution of 2560 x 2592 pixels, featuring various crack shapes and widths, along with complex background textures, making segmentation challenging [57].
DeepCrack: DeepCrack is a well-known dataset for evaluating crack detection algorithms. It contains 537 images, each with a resolution of 384 x 544 pixels. The dataset has clear intensity differences between cracks and backgrounds, aiding in effective crack identification in pavement images [30].
GAPs384: The GAPs384 dataset consists of 384 high-resolution images (1080 x 1920 pixels) with various types of noise and complex road textures, making crack segmentation challenging and critical for developing advanced algorithms [53].
Data Augmentation
To enhance the generalization ability of the authors’ model, various data augmentation techniques were employed. The authors applied flipping (probability 0.7), rotation (probability 0.7), random brightness and contrast adjustments (probability 0.2), Gaussian blur (probability 0.2), and displacement Scale-Rotate transformations (probability 0.2) as augmentations. Additionally, Gaussian noise (probability 0.2) and color inversion (probability 0.2) were also applied. These augmentations simulated various real-world conditions, enhancing the model’s robustness and generalization ability across different scenarios.
Loss Function
In this study, the authors used the Dice coefficient loss, defined as follows:
where is the set of predicted pixels and (B$ is the set of true pixels. The authors define Dice loss as:
In practical applications, it can be represented as continuous variables:
where and represent the predicted and true values of the pixels, respectively, and is the total number of pixels [59, 25].
Evaluation Metrics
Four widely recognized evaluation metrics were utilized: Recall (Re), Precision (Pr), F1 score, and Mean Intersection over Union (mIoU). The definitions of these metrics are as follows:
Figure 5: Segmentation results on the DeepCrack dataset (a) Original image, (b) Ground truth, (c) EfficientCrackNet (the authors’), (d) LLM, (e) ShuffleNetV2, (f) MobileNetV3, (g) EfficientNet, (h) DeepCrack.

where the quantities TP, FP, FN, and TN represent True Positives, False Positives, False Negatives, and True Negatives, respectively.
Comparison with the Lightweight Models
The authors evaluated several state-of-the-art lightweight segmentation models across three datasets, comparing their model with them. The models compared include EfficientNet [33], DeepCrack [30], ShuffleNetV2 [35], MobileNetV3 [21], and LMM [1]. Here, Table 1 presents the results. Figure 5 compares the segmentation outputs of the authors’ model and other lightweight models on the DeepCrack dataset, demonstrating the robustness of the proposed model.
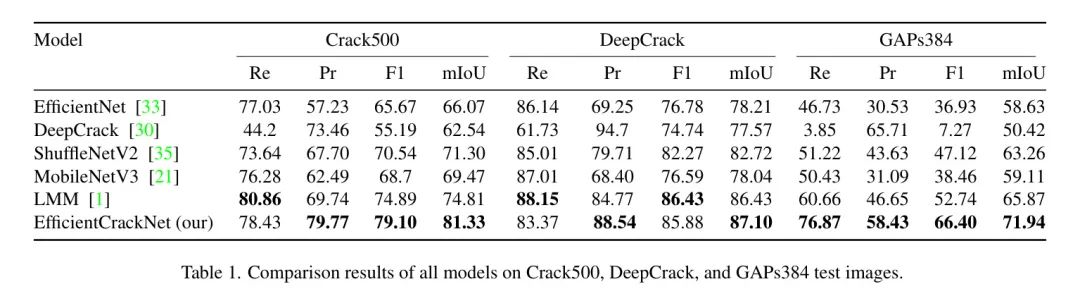
Results on the Crack500 Dataset: On the Crack500 test dataset, the proposed EfficientCrackNet model achieved an mIoU of 81.33%, Re of 78.43%, and Pr of 79.77%. In terms of the F1 score, EfficientCrackNet reached the highest score of 79.10%. Compared to other models, EfficientCrackNet shows a significant improvement in performance, achieving 8.02% higher mIoU than LMM, 17.07% higher than MobileNetV3, 14.07% higher than ShuffleNetV2, 18.79% higher than DeepCrack, and 30.04% higher than EfficientNet.
Results on the DeepCrack Dataset: When tested on the DeepCrack dataset, the proposed EfficientCrackNet model achieved an mIoU of 87.10%, Re of 83.37%, and Pr of 88.54%. In terms of the F1 score, EfficientCrackNet reached 85.88%. Comparative analysis reveals that EfficientCrackNet significantly outperforms other models, with a 0.77% increase in mIoU compared to LMM, 11.61% compared to MobileNetV3, 5.29% compared to ShuffleNetV2, 12.29% compared to DeepCrack, and 11.37% compared to EfficientNet.
Results on the GAPs384 Dataset: On the GAPs384 test dataset, EfficientCrackNet achieved Re of 76.87%, Pr of 58.43%, and F1 of 66.40%. Additionally, it obtained an mIoU of 71.94%, which is the highest value among all evaluated models. Compared to other models, EfficientCrackNet demonstrates superior performance, with an mIoU that is 8.44% higher than LMM, 21.71% higher than MobileNetV3, 13.72% higher than ShuffleNetV2, 29.91% higher than DeepCrack, and 22.70% higher than EfficientNet.
Consistent superior performance indicates the robustness and adaptability of the proposed model while maintaining computational efficiency.
Model Complexity
Lightweight networks attempt to reduce model complexity by addressing three key factors: Floating Point Operations per Second (FLOPs) and the number of parameters. FLOPs and the number of parameters can be quantified using the formulas defined in Equations 14 and 15.
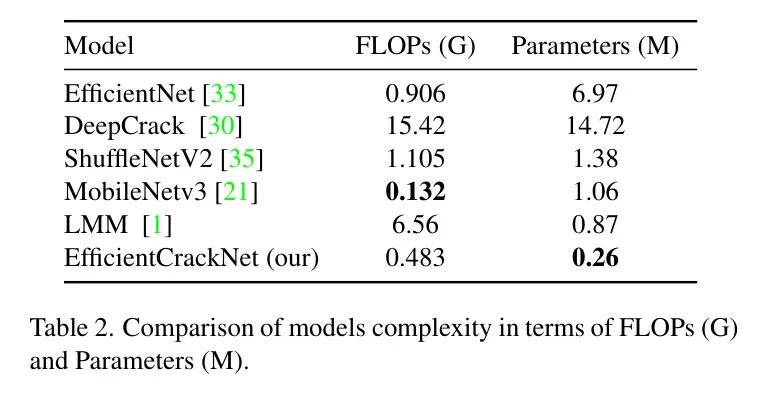
Lightweight networks attempt to reduce model complexity by addressing three key factors: Floating Point Operations per Second (FLOPs) and the number of parameters. FLOPs and the number of parameters can be quantified using Equations 14 and 15.
In this context, (HWC_{in} represents the number of output channels. The variable corresponds to the kernel size.
Despite the lightweight nature of the authors’ model, it performs excellently across the three datasets, indicating its suitability for real-time crack segmentation on mobile devices.
5 Ablation Study
This section discusses the impact of ULSAM, MobileViT blocks, and EEM on the authors’ model. The authors used the Crack500 dataset as an example because it contains a wide range of shapes and widths, with most images featuring complex background textures.
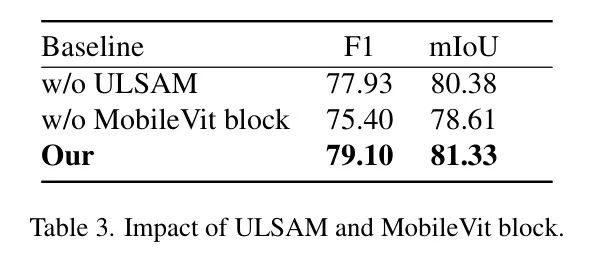
Effect of ULSAM and MobileViT Block
The authors conducted experiments to evaluate the impact of ULSAM and the MobileViT block in the model. The results presented in Table 3 are based on the Crack500 dataset. If ULSAM is removed, the F1 score will decrease by 1.49%, and the mIoU will decrease by 1.18%. Similarly, removing the MobileViT block will lead to a 4.79% decrease in the F1 score and a 3.40% decrease in the mIoU. ULSAM is integrated into the encoder, bottleneck, and decoder of the model. ULSAM enhances the network’s ability to understand complex visual patterns without significantly increasing model parameters. On the other hand, the MobileViT block helps capture global features without significantly increasing model complexity.
Effect of EEM
Edges and object boundaries are crucial for various advanced computer vision tasks, such as image segmentation. In the early feature maps of the model, spatial details of the object’s shape are retained more, making it particularly important to extract these edges for tasks like crack segmentation. In the authors’ proposed model, EEM is used in the first few layers of the encoder. The results presented in Table 4 demonstrate that removing EEM leads to a significant drop in performance, with the F1 score decreasing by 10.71% and the mIoU decreasing by 7.48%. This highlights the importance of EEM in enhancing segmentation accuracy. Figure 6 illustrates the impact of each component in EEM on the segmentation mask.
6 Conclusion
EfficientCrackNet is a lightweight hybrid model designed for the automatic detection and segmentation of cracks in infrastructure maintenance. It combines DSC and MobileViT blocks to capture global and local features, enhancing segmentation accuracy. The model utilizes an innovative EEM that combines DoG and LoG for feature extraction without additional training and integrates ULSAM to improve feature representation. EfficientCrackNet achieves state-of-the-art results on three benchmark datasets, requiring only 0.26M parameters and 0.483 GFLOPs, making it an ideal choice for practical applications.
Despite the many advantages of EfficientCrackNet, there are also limitations that require further exploration. It faces challenges in detecting extremely thin cracks, which may require more advanced feature extraction techniques. Additionally, variations in lighting and background conditions may affect its performance. Future research should further optimize the model and expand its applications in structural health monitoring to enhance the automation and safety of infrastructure maintenance.
References
[1]. EfficientCrackNet: A Lightweight Model for Crack Segmentation.

