DeepSeek V3.1 AI model introduces a technological innovation called “UE8M0 FP8,” which has garnered widespread attention in the AI community and the market. Domestic chip companies have seen a significant rise.
1. DeepSeek V3.1 Release Causes a Sensation
-
DeepSeek V3.1 is a newly released AI large model developed by Huansquare Quantization (the company behind DeepSeek). The official announcement mentions that it utilizes the “UE8M0 FP8” parameter precision format, a brief 20-character message that contains significant technological breakthroughs.
-
This news has caused a “sensation” in the AI community, as it implies progress in domestic chips: domestic chip companies (such as Cambricon) saw their stock prices soar, with Cambricon’s intraday increase nearing 14%, making it the top market capitalization on the Sci-Tech Innovation Board; the semiconductor ETF also surged by 5.89%. The market response has been enthusiastic, as this is seen as a signal to reduce dependence on foreign chips (such as NVIDIA).
-
The official text only modestly mentions UE8M0 FP8 (hidden in the feature updates), but the comments section emphasizes “new architecture, next-generation domestic chips,” sparking speculation and heated discussions.
2. Understanding: What is UE8M0 FP8?
-
Core Concept: UE8M0 FP8 is an 8-bit floating-point (FP8) format specifically optimized for AI computation. FP8 is a compressed version of conventional floating-point numbers (compressed from 32 bits or 16 bits to 8 bits), which can reduce data storage and transmission requirements, thereby enhancing computational efficiency and lowering power consumption.
-
Technical Breakdown:
-
UE8M0 FP8 can be divided into two parts:
-
UE8M0: A format representing the “scaling factor.” Here, “U” stands for unsigned (no distinction between positive and negative), “E8” indicates that 8 bits are entirely used for the exponent part, and “M0” indicates that 0 bits are used for the mantissa part. This simplifies calculations, as scaling only requires moving the exponent bit (multiplying by a power of 2), eliminating complex floating-point operations.
-
FP8: The actual 8-bit floating-point number, typically using E4M3 or E5M2 formats (4 bits for exponent + 3 bits for mantissa or 5 bits for exponent + 2 bits for mantissa), used to store actual data.
-
-
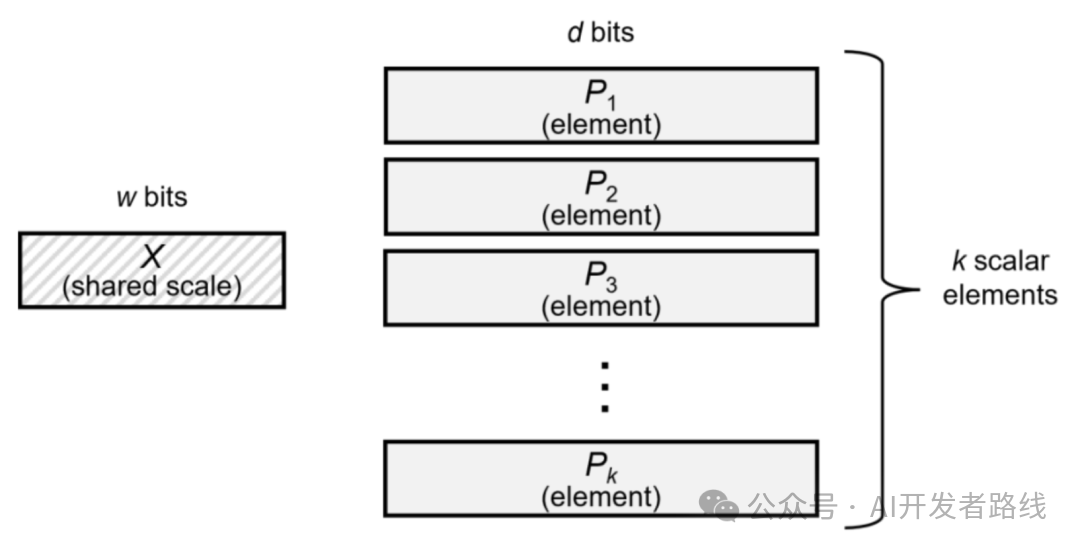
UE8M0 FP8 is based on the MXFP8 standard (released by the Open Compute Project in 2023). The core idea of MXFP8 is to split data tensors into small blocks, each block specifying its own scaling factor (i.e., UE8M0), and then uniformly scaling the data within the block to store it as FP8. This can expand the dynamic range (avoiding overflow or compression of large/small values to zero) and reduce information loss.
-
For example, traditional FP8 may cause errors due to insufficient dynamic range, but MXFP8 solves this problem through block scaling. The image below, sourced from NVIDIA’s technical blog, illustrates how MXFP8 works: it divides data into blocks, each with its own scaling factor, thus maintaining high precision under an 8-bit width.
-
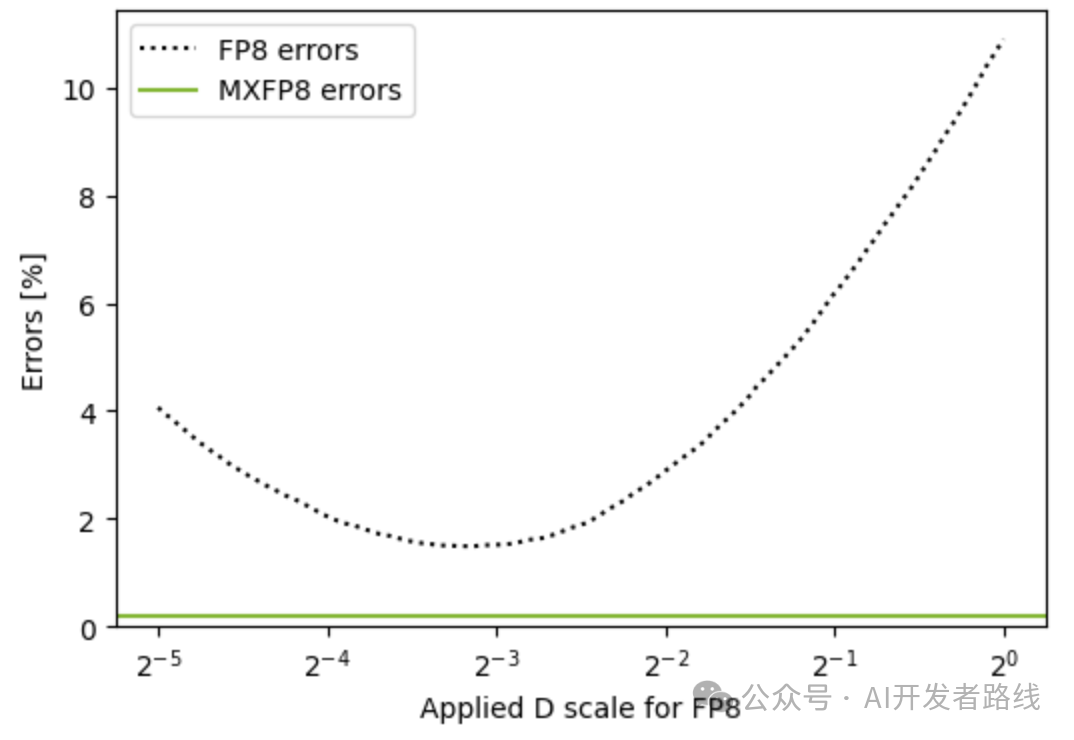
Another image shows a comparison of dynamic ranges of different formats: the error rate of UE8M0 FP8 (red line) is significantly lower than that of single-scale FP8, as it can handle both large and small values simultaneously, reducing precision loss during AI training.
-
Why is it important? UE8M0 FP8 can significantly enhance the efficiency of AI computation:
-
Reduced bandwidth requirements: A set of 32 FP8 data only requires an additional 8-bit scaling factor (saving 75% traffic compared to traditional FP32 scaling), which is particularly critical for domestic chips with limited high-bandwidth memory (HBM).
-
Increased throughput and reduced power consumption: Simpler calculations (only exponent displacement) shorten the processor’s critical path, making it suitable for large model inference.
-
DeepSeek’s previously open-sourced DeepGEMM project has supported UE8M0, but primarily adapted for NVIDIA chips; now, the optimizations in V3.1 indicate a shift towards the domestic ecosystem.
3. Impact on Domestic Chips: Adaptation of Next-Generation Chips
-
Why adapt to domestic chips? Currently, most domestic AI chips (such as Cambricon and Huawei Ascend) still use FP16 or INT8 computation and do not natively support full FP8. However, the “next-generation domestic chips” (such as Moore Threads MUSA 3.1 GPU and Chipone VIP9000 NPU) set to be released in the second half of 2025 have already advertised support for “native FP8” or “Block FP8” and are collaborating with manufacturers like DeepSeek to validate the UE8M0 format.
-
The optimization of UE8M0 FP8 can compensate for the bandwidth disadvantages of domestic chips (HBM/LPPDDR bandwidth is lower than that of foreign top chips) by reducing data traffic, allowing the same hardware to run larger models and improving cost-effectiveness.
-
-
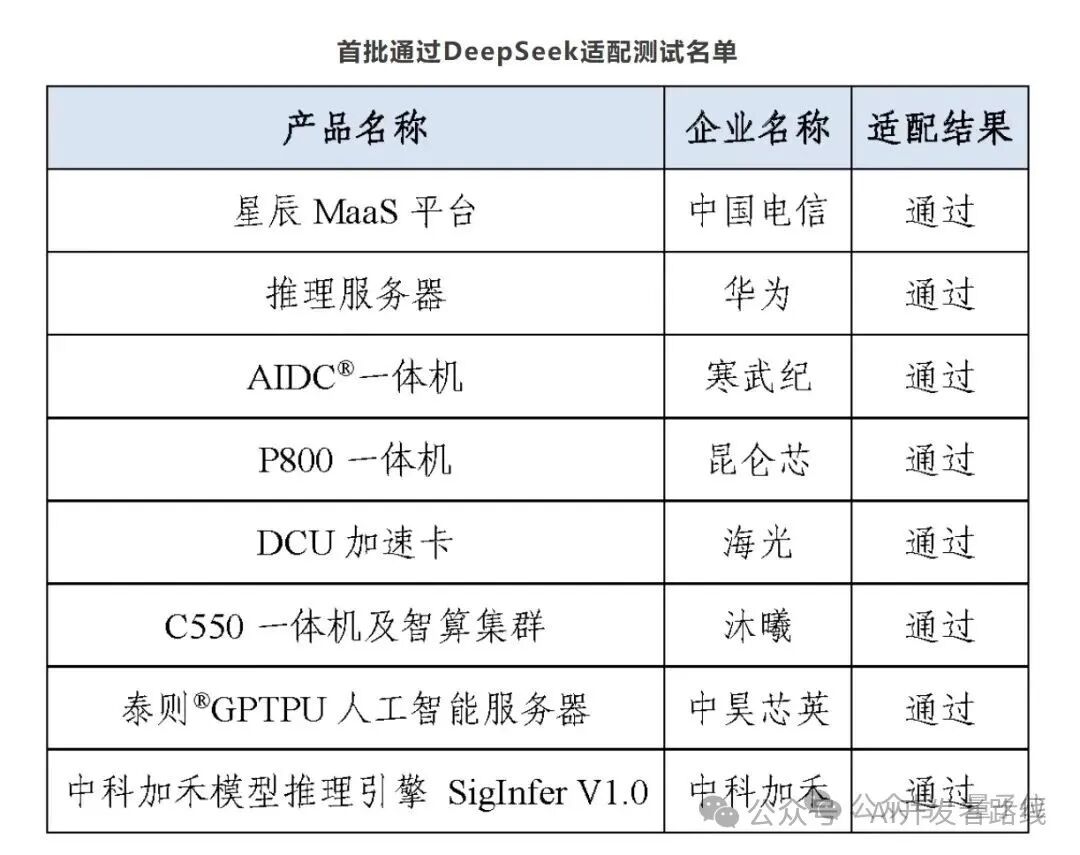
Speculated chip manufacturers: The first batch of eight manufacturers adapted by DeepSeek (such as Cambricon, Hygon, and Muxi) saw Cambricon’s stock price soar, becoming the “top seed” as it already has chips (such as MLU370-S4 and Siyuan 590) that support FP8. Other potential manufacturers include:
-
Huawei Ascend: The roadmap indicates native FP8 by Q4 2025, and the next-generation chip (such as Ascend 910D) may become a dark horse.
-
Moore Threads: MTT S5000 GPU natively supports FP8.
-
Others like Zhonghao Xinying and Muxi also support FP8.
-
-
Reasons for market excitement: This represents a shift in domestic AI towards a “soft and hard collaboration” stage—DeepSeek optimizes software (UE8M0 FP8) to fit domestic chip hardware, similar to the “Wintel alliance,” reducing dependence on foreign computing power like NVIDIA. The image shows the collective rise of domestic chip concept stocks (the Sci-Tech Innovation 50 index surged by 3%):
4. Overall Significance and Response
-
Industry Impact: The adoption of UE8M0 FP8 marks a transition of domestic AI from “going it alone” to ecological collaboration, which can substantially promote domestic alternatives. Platforms like Zhihu have seen experts providing analysis, sparking heated discussions.
-
Subtlety: The official mention of UE8M0 FP8 (only one sentence in the text) has ignited the market, humorously referred to as “possibly taking the opportunity to inflate stock prices.” However, the essence of the technology is progress: through precision format innovation, it enhances the competitiveness of domestic chips.
-
Conclusion: The release of DeepSeek V3.1 is not just an upgrade of the AI model but a milestone for the domestic chip ecosystem, signaling a new breakthrough for China in the field of AI computing power.
-

-