We believe that through the previous articles, everyone has gained some understanding of the architecture of Weibo’s DCP system. Today, we will discuss some practical experiences in image distribution in Weibo’s mixed cloud.
Due to the characteristics of Weibo’s business, we often face traffic that is several times the usual peak, such as major news events and hot topics in the entertainment industry. To cope with these peaks relatively smoothly, we must have the ability to scale up quickly and in large quantities, even doubling our capacity. To achieve this capability, we need to not only redesign the overall system architecture but also face significant challenges with our distribution system (whether Docker or non-Docker, the essence of scaling is distribution).
As mentioned in previous articles, private cloud (intranet) and public cloud (Aliyun) are designed to meet different scenarios, so their demands for image repository services will also differ:
-
The pressure on the intranet image repository mainly comes from daily releases and elastic scheduling, with bandwidth pressure relatively stable.
-
The intranet environment is much more complex than Aliyun, with significant differences in operating system versions, software versions, configurations, etc., across various businesses.
-
The pressure on the Aliyun image repository is determined by the number of machines that need to be scaled up at that time, which cannot be estimated in advance.
-
The Aliyun environment is customizable, clean, and unified.
Based on the above points, we have adopted different deployment architectures in the intranet and Aliyun, as shown in the figure below:
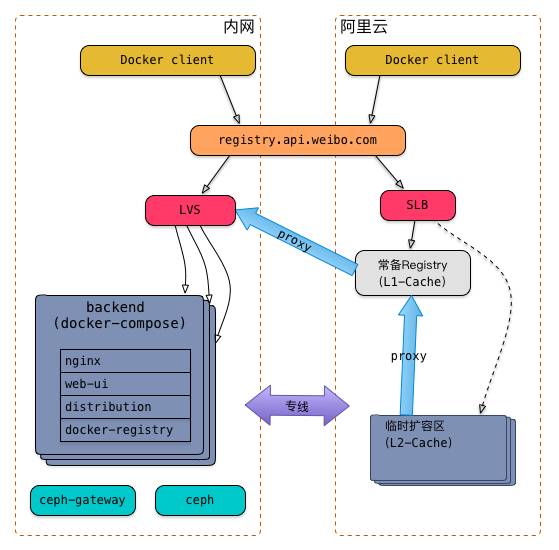
To eliminate differences, we used the same domain name for both the intranet and Aliyun, pointing to the intranet’s LVS and Aliyun’s SLB respectively; we will discuss the other details later.
Currently, this architecture addresses two main problems we face:
1: Aliyun’s Distribution Capability Issue
Regarding image distribution in Aliyun, there are two main pain points:
-
Large image size: The Weibo platform’s business is primarily based on Java, which is known for having a heavy runtime environment. Our typical business images are generally over 700M in size.
-
Full Pull: Each scaling involves new machines, so each machine must pull the complete image rather than an incremental pull.
In fact, these two pain points can be summarized into one point: the bandwidth pressure brought by scaling is very large. For example, estimating the total bandwidth consumption when scaling 50 machines: 50 * 700M = 35GB = 280Gb; theoretically, a machine with a gigabit network card can distribute it in 280/60 ≈ 5 minutes, but in reality, there will be a lot of Pull failures.
To address this, we utilized the proxy mechanism built into the image repository to construct a multi-level cache architecture that can scale elastically (the right part in the above image).
-
We also managed the image repository service as a special service pool, with its operating system image being customized;
-
Deploying an image repository as a standby service, also serving as a first-level cache to improve the scaling speed of the image repository service itself;
-
When large-scale business scaling is needed on Aliyun, we will first scale up the image repository service by a certain ratio (this ratio is related to image size, machine hardware configuration, network environment, etc., in our scenario it is 1:20), serving as a second-level cache.
We also made some optimizations to the operating system image of the image repository, as follows:
-
Support specifying an image list for preheating: You can pass the list of business images needed for the current scaling into the image repository container through environment variables (docker run’s -e parameter); this way, the image repository can support multiple businesses scaling simultaneously;
-
Built-in common base images like JDK, Tomcat, etc., to reduce the time spent on preheating images;
-
After preheating, automatically call the Aliyun SLB interface to add back-end nodes, and then it can provide services externally.
The lifecycle of the Aliyun image repository temporary scaling area is shown in the figure below:
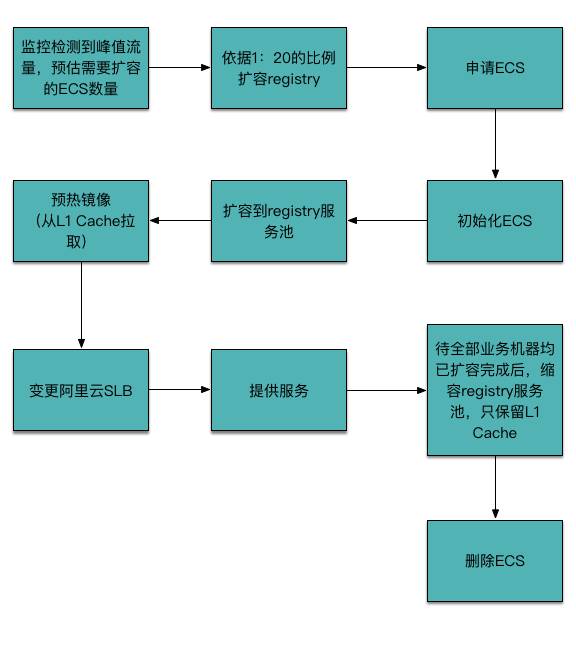
Note that preheating is a critical step; if not preheated, all requests will go through levels (rather than waiting), and the results are predictable.
Note: The 1:20 ratio was derived from repeated testing – that is, under the condition of having only one image repository, it can support 20 machines pulling 700M images simultaneously within 2 minutes; exceeding this number will result in pull failures.
Currently, this architecture ensures the ability to scale up 1000 nodes in Aliyun within 10 minutes while also reducing costs and bandwidth pressure on dedicated lines.
2: Intranet Environment Uniformity Issue
Due to the rapid updates of Docker versions and insufficient backward compatibility, as the time using Docker increases, the Docker versions running in our production environment have also diversified, ranging from 1.2 to 1.8. When Docker 1.6 was released, the original image repository project (docker-registry) was marked as deprecated and migrated to the new distribution project, which is implemented in Go and has a significantly different API. Versions below Docker 1.6 only support the old API, while versions 1.6 and above default to using the new API for interaction with the image repository and support fallback to the old API.
Therefore, we retained both docker-registry and distribution services and used docker-compose to orchestrate a set of services that can interact normally with all versions of Docker we have, with a rough structure as follows:
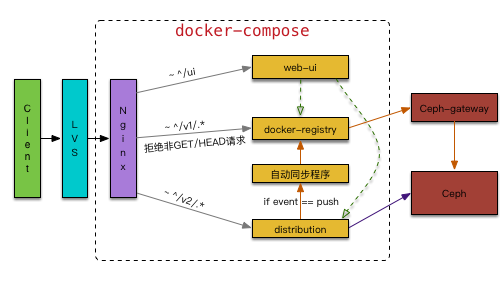
As shown in the figure, the Nginx layer is configured to forward requests from different versions of Docker to the corresponding backend; to avoid image synchronization issues, all push requests from Docker versions below 1.6 are rejected, and the built-in notification mechanism is used to achieve automatic synchronization of images (one-way).
For the storage layer, after comparing Glusterfs, Swift, and Ceph, we finally chose Ceph. The reasons are several: simple configuration, more active community, and support for block storage. While ensuring high throughput, it also solves the single point problem; as long as the distribution server is down, as long as Ceph is still there, it can be quickly rebuilt.
It is worth mentioning that distribution itself is a Ceph client and can interact directly with Ceph, with simple configuration; while docker-registry needs to access Ceph through ceph-gateway, which requires more complex configuration.
Note: In the latest version of distribution, the Ceph-related configuration and rados driver code have been removed, and can only be accessed indirectly through a Swift gateway.
Issues with Docker and Its Tools
Of course, in addition to the two issues related to Weibo’s environment mentioned above, there are also some issues with Docker itself and its surrounding tools.
As mentioned above, Docker’s version updates are very rapid, and there are often disruptive updates (such as 1.6 and 1.10), reflecting that the entire Docker community is quite aggressive. Therefore, many details of usage need us to accumulate experience in practice while keeping an eye on Docker community dynamics to use this technology more adeptly.
Here are a few relatively significant issues we encountered (related to the image repository):
Cache Invalidity Issue of Proxy Mechanism
First, let’s look at the principle of the image repository proxy mechanism (which is generally called pull through cache by the official):
A distribution can be configured as a proxy (read-only, i.e., only pull, cannot push) to another distribution (either official or private), by adding the following configuration in config.yml:
-
proxy:
-
remoteurl: http://10.10.10.10
After configuration, when a Docker pull request comes in, it will check if the requested image already exists locally; if not, it will penetrate to the configured backend and simultaneously cache it locally, so that subsequent requests will not penetrate again.
The default cache validity period is one week (can be adjusted by modifying the code, requiring recompilation); after exceeding the validity period, a scheduler coroutine will delete all layer files and metadata of the cached image. When a cached image expires, all pulls of that image will fail and prompt image not found.
The cause of the problem lies in the logic for checking cache validity in distribution, which is not detailed here; interested parties can refer to this issue or read the source code.
The official has made a fix for this issue, but it is not thorough. Before the official fix is complete, our solution is to set the cache validity period a bit longer (one month) and regularly (once a month) clear the cache directory and restart the distribution container.
Setting Issues with X-Forwarded-Proto Header When Using HTTPS Protocol
Sometimes, for security or usage specification reasons, we set up a set of image repository services that support HTTPS protocol access; the industry’s common practice is to configure the certificate at the Nginx layer and convert it to HTTP protocol before passing it to the backend; we also do this.
Here is one point to note: in principle, both Docker pull and push are a series of HTTP requests. For Docker push, distribution will determine the protocol of the next location returned to the client based on the value of the “X-Forwarded-Proto” header. Therefore, it is essential to ensure that when the request reaches the distribution side, the value of the X-Forwarded-Proto header is correct, reflecting the protocol used by the client to initiate the request. Otherwise, when the permission control of the image repository is enabled, there will be push failures.
When there are multiple layers of Nginx or similar reverse proxy programs in the entire HTTP call stack, this issue needs special attention. For example, in our two-layer Nginx, the configurations are as follows:
LVS Layer:
location / {
...
proxy_set_header X-Forwarded-Proto $scheme;
...
}
docker-compose Layer:
location / {
...
# proxy_set_header X-Forwarded-Proto $scheme;
...
}
Using Aliyun SLB, Docker pull waits for a while before starting to pull the image
After pointing Aliyun’s registry domain name to SLB, we noticed a strange phenomenon: every time we pull the image from the domain name, there is a delay before starting to pull the image, while pulling directly by IP works fine, as follows:
docker pull registry.api.weibo.com/busybox:latest // Waits about 20 seconds before starting to download the image
docker pull 10.75.0.52/busybox:latest // Normal
After some investigation, we found that the Docker daemon, upon receiving the pull command, first checks whether the specified address is a legitimate service provider; during the check, it requests in the order of https+v2, https+v1, http+v2, http+v1. However, Aliyun’s SLB does not respond to unlistened ports by default, so the client can only wait for a timeout.
Our solution was to add the TCP port 443 to the SLB, so that the client quickly knows that this distribution does not provide HTTPS services, thereby immediately falling back to HTTP protocol.
Note: This issue exists in Docker version 1.6.2; whether it has been fixed in later versions is left for interested parties to experiment.
The image repository service, as part of Weibo’s mixed cloud infrastructure, is crucial for its distribution capability and stability. The architecture plan we adopted is designed considering Weibo’s business characteristics, costs, historical legacy issues, and various other factors, and may not necessarily be suitable for everyone. Meanwhile, to address the need to scale up the image repository first and shorten total scaling time, we are also developing a set of image distribution solutions based on the BitTorrent protocol, hoping to communicate and learn from industry peers.
▽
Further Reading (Click the title):
Challenges in Mixed Cloud Architecture Practice: Insights into Elastic Scheduling
Mixed Cloud Architecture Practice: Immutable Infrastructure
Daily Active Users Over 100 Million: Insights into Weibo’s Mixed Cloud DCP Architecture Practice
This article is originally published by InfoQ and is prohibited from reprinting without authorization.
