Click the “Machine Vision” above, then click the top right corner… select “Pin/Star“Public Account to receive the latest articles!
Source: Translated by Machine Heart
Original article link: https://towardsdatascience.com/i-built-a-diy-license-plate-reader-with-a-raspberry-pi-and-machine-learning-7e428d3c7401
Author:Robert Lucian Chiriac Translated by Machine Heart
Out of boredom, we equipped our beloved car with a Raspberry Pi, paired it with a camera, designed a client, and completed a real-time license plate detection and recognition system.
How to create a smart car system without changing the car? For some time, the author Robert Lucian Chiriac has been thinking about giving the car the ability to detect and recognize objects. This idea is very interesting, as we have seen the capabilities of Tesla, and although we cannot buy a Tesla right away (it must be mentioned that the Model 3 looks increasingly attractive now), he had an idea to work towards realizing this dream.


-
Detect the license plate.
-
Recognize the text within each license plate boundary box.
-
A machine learning model that detects license plates using unlabelled images as input;
-
Some hardware. Simply put, I needed a computer system connected to one or more cameras to call my model.
-
YOLOv3 – This is one of the fastest models available, and its mAP is comparable to other SOTA models. We use this model to detect objects;
-
CRAFT Text Detector – We use it to detect text in images;
-
CRNN – Simply put, it’s a recurrent convolutional neural network model. To arrange the detected characters into words in the correct order, it must be sequential data;
-
First, the YOLOv3 model receives frames from the camera and finds the boundary boxes for the license plates in each frame. It’s not advisable to use very precise predicted boundary boxes—the boxes should be slightly larger than the actual detected object. If they are too tight, it may affect the performance of subsequent processes;
-
The text detector receives the cropped license plates from YOLOv3. At this point, if the boundary box is too small, it’s likely that part of the license plate text will be cropped out, leading to poor prediction results. However, when the boundary box is enlarged, we can let the CRAFT model detect the positions of the letters, allowing for very precise positioning of each letter;
-
Finally, we can pass the boundary boxes of each word from CRAFT to the CRNN model to predict the actual words.

-
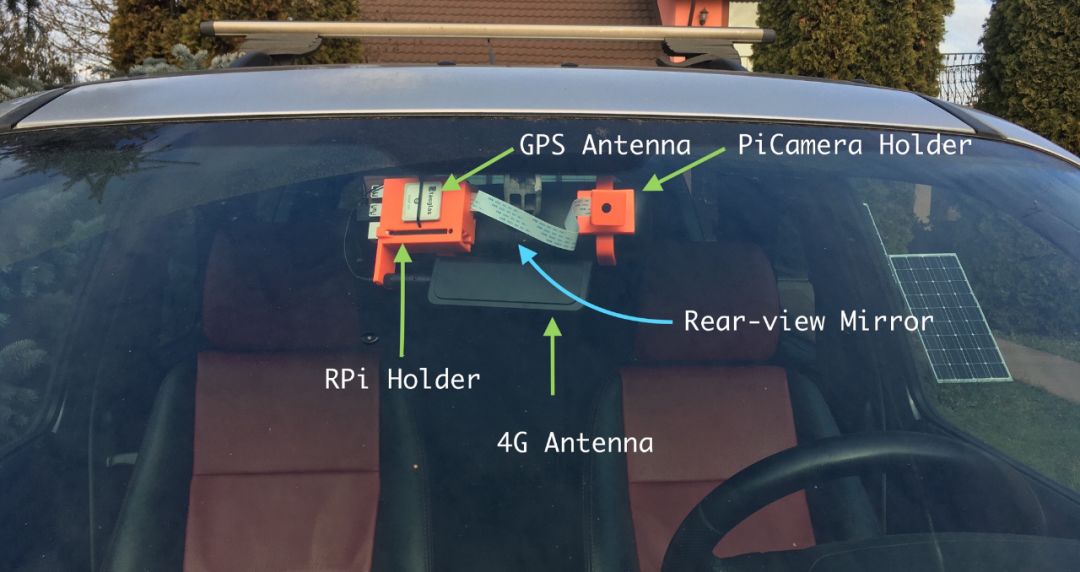
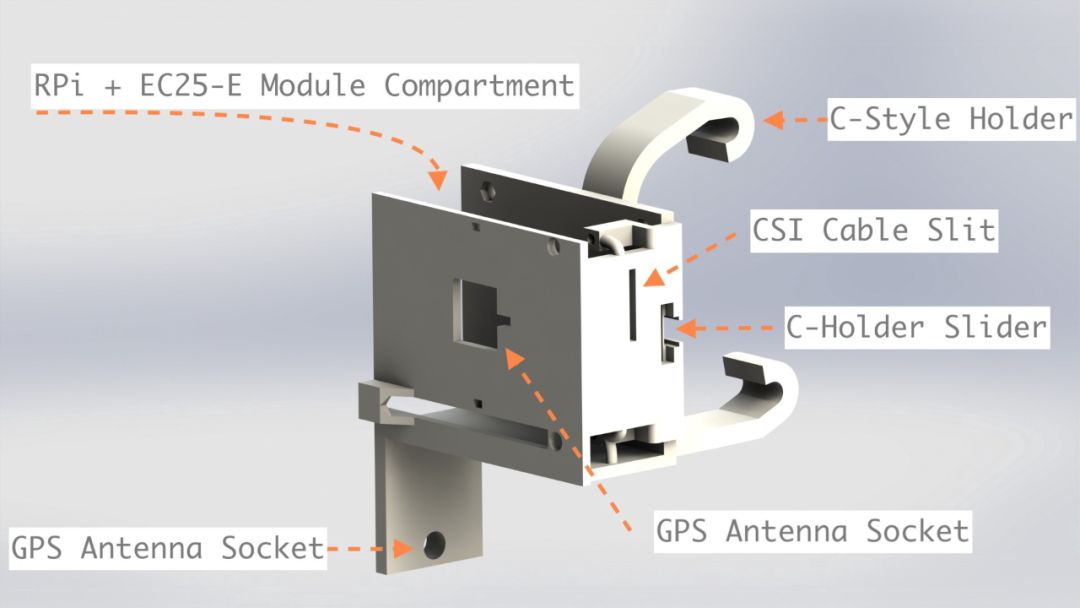
On the rearview mirror side, the Raspberry Pi + GPS module + 4G module will be retained. You can check my article about the EC25-E module for the GPS and 4G antennas I used;
-
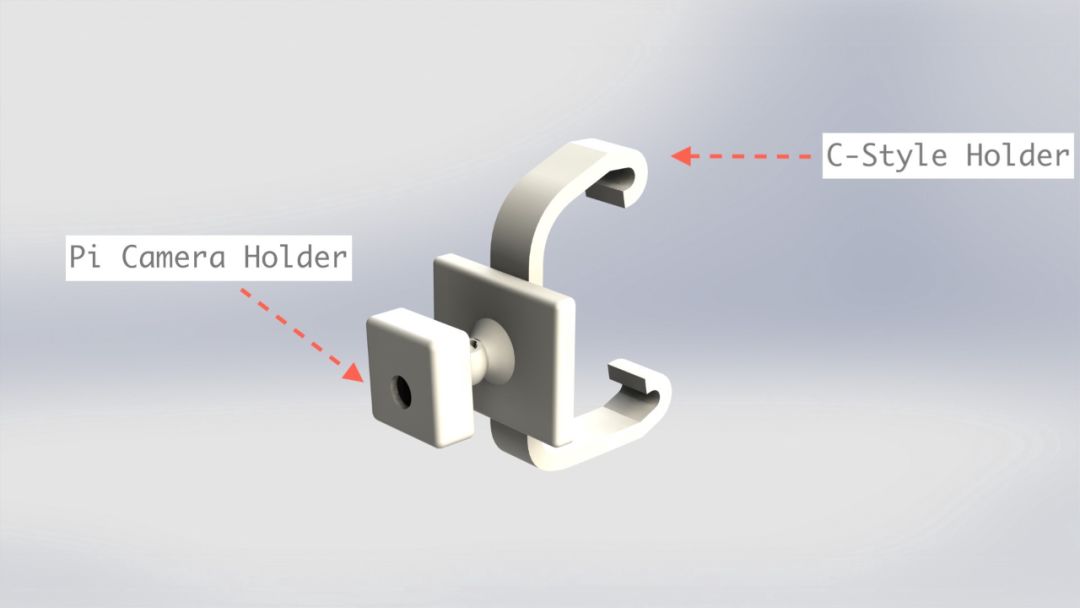
On the other side, I used an arm that utilizes a ball joint to support the Pi Camera.

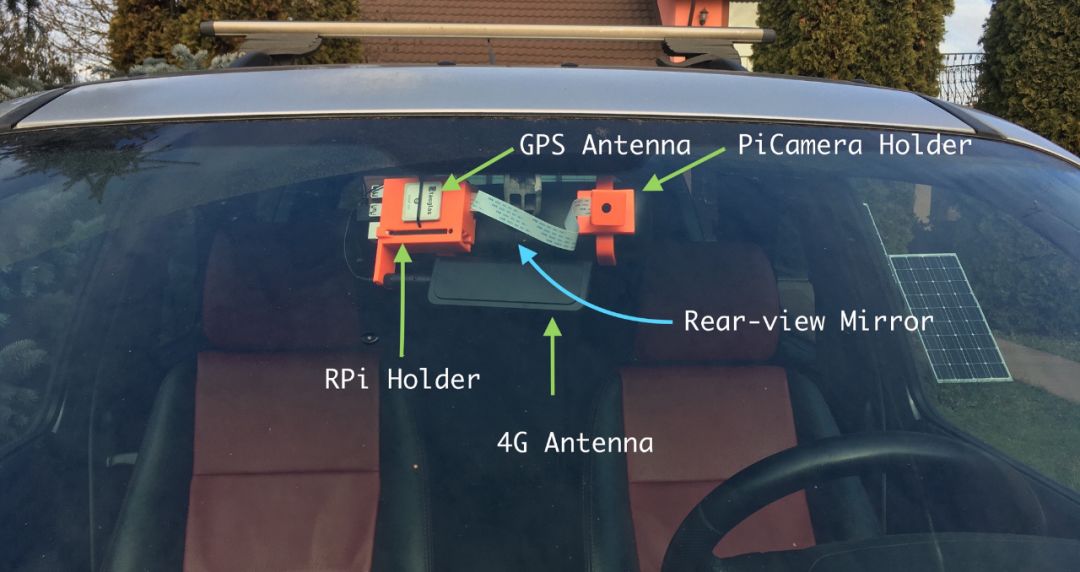
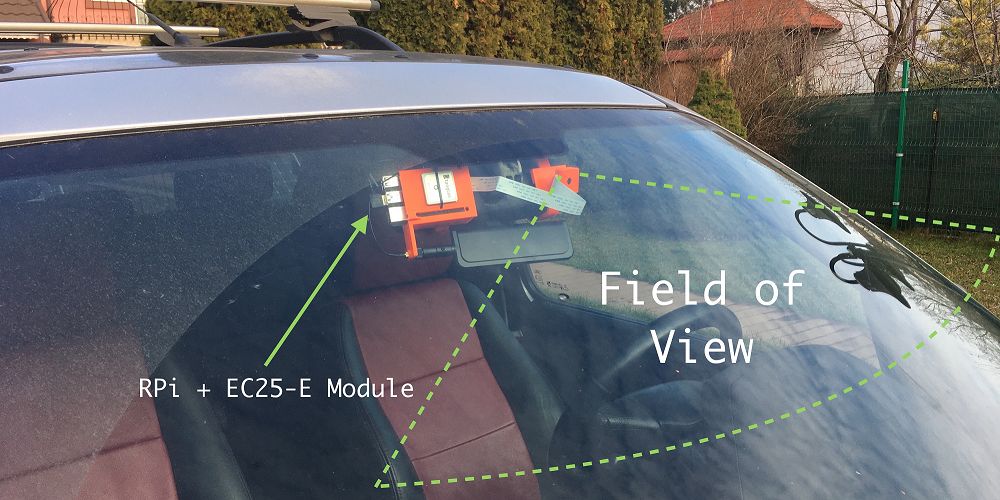

-
Keras implementation: https://github.com/experiencor/keras-yolo3

-
Submit merge request: https://github.com/experiencor/keras-yolo3/pull/244


-
Perform all inference locally;
-
Perform inference in the cloud.


-
Defining the cortex.yaml file, which is the configuration file for our API. Each API will handle one type of task. I assigned the task for the yolov3 API to detect the license plate bounding boxes on the given frame, while the crnn API predicts the license plate number with the help of CRAFT text detector and crnn;
-
Defining the predictor for each API. Basically, what you need to do is define a predict method for a specific class in cortex to receive a payload (all the servy parts are already handled by the platform), this payload can be used to predict results and then return the prediction results. It’s that simple!
<span># predictor.pyimport boto3</span>import picklelabels = [<span>"setosa"</span>, <span>"versicolor"</span>, <span>"virginica"</span>]<span><span>class</span> <span>PythonPredictor</span>:</span> <span><span>def</span> <span>__init__(<span>self</span>, config)</span></span>: s3 = boto3.client(<span>"s3"</span>) s3.download_file(config[<span>"bucket"</span>], config[<span>"key"</span>], <span>"model.pkl"</span>) <span>self</span>.model = pickle.load(open(<span>"model.pkl"</span>, <span>"rb"</span>)) <span><span>def</span> <span>predict(<span>self</span>, payload)</span></span>: measurements = [ payload[<span>"sepal_length"</span>], payload[<span>"sepal_width"</span>], payload[<span>"petal_length"</span>], payload[<span>"petal_width"</span>], ] label_id = <span>self</span>.model.predict([measurements])[<span>0</span>] <span>return</span> labels[label_id]curl http://***.amazonaws.com/iris-classifier \ -X POST -H <span>"Content-Type: application/json"</span> \ -d '{<span>"sepal_length"</span>: 5.2, <span>"sepal_width"</span>: 3.6, <span>"petal_length"</span>: 1.4, <span>"petal_width"</span>: 0.3}'-
Collect frames from the Pi Camera at an acceptable resolution (800×450 or 480×270) at a frame rate of 30 FPS and push each frame into a public queue;
-
In a separate process, I will take frames from the queue and distribute them to multiple workstations on different threads;
-
Each worker thread (or what I call an inference thread) will make API requests to my cortex API. First, a request to my yolov3 API, and then, if any license plate is detected, another request will send a batch of cropped license plates to my crnn API. The predicted license plate numbers will be returned in text format;
-
Each detected license plate (with or without recognized text) will be pushed to another queue, which will ultimately broadcast to the browser page. Additionally, the predicted license plate numbers will be pushed to another queue to be saved to disk in CSV format later;
-
The broadcast queue will receive a set of unordered frames. The consumer’s task is to first place them into a very small buffer (the size of a few frames) and broadcast a new frame to the client for reordering. This consumer runs separately in another process, and it must also try to keep the queue size fixed at a specified value to display frames at a consistent frame rate. Obviously, if the queue size decreases, the frame rate drops proportionally, and vice versa;
-
Meanwhile, another thread will run in the main process to get predictions and GPS data from another queue. When the client receives a termination signal, the predictions, GPS data, and time will also be stored to a CSV file.
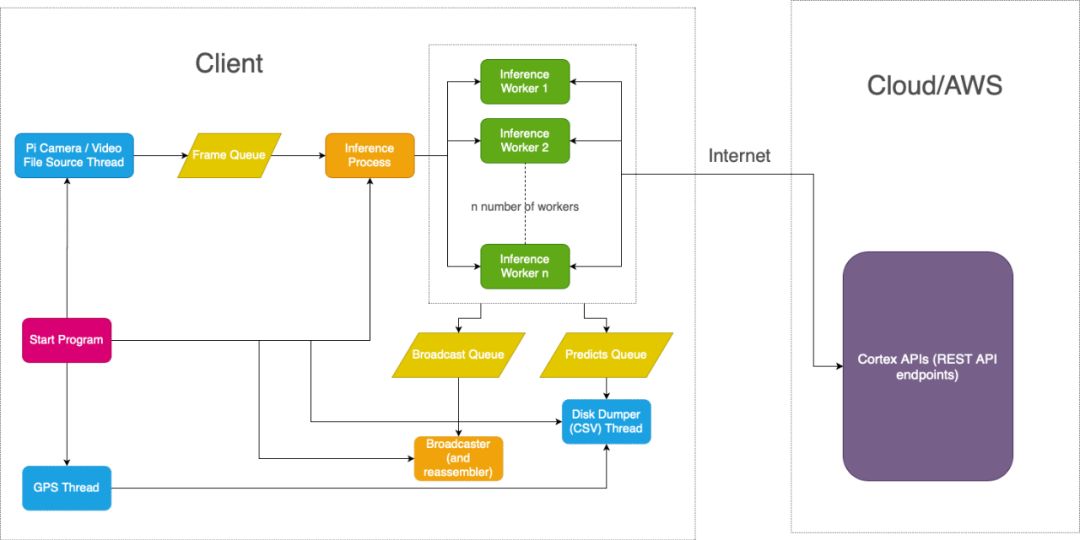
-
Reduce the width to 416 pixels, which is the size required by the YOLOv3 model, and the scale is obviously intact;
-
Convert the image to grayscale;
-
Remove the top 45% of the image. The idea here is that license plates won’t appear at the top of the car frame because cars don’t fly, right? As far as I know, removing 45% of the image does not affect the performance of the predictor;
-
Convert the image to JPEG again, but this time with much lower quality.
Recommended Articles:
001: Research resources and journals in the field of computer vision
002:German Kuka robots vs. world champion table tennis players
003:120 images outline the complete map of the global AI industry!
004:Facebook open-source computer vision system, understanding images at pixel level (with paper and code)
005:If you want to become a machine learning engineer, this self-learning guide is worth collecting
006:Eleven common filtering algorithms
007:Basics of image processing and computer vision, classic and recent developments
008:In-depth report on the robotics industry (full version)
009:From a laundry girl to Google’s chief scientist, she changed the AI world with loneliness!
010:Industrial-grade machine vision industry research report
011:Brief introduction to the principle of dual telecentric industrial lenses
012:How to equip an academic iPad?
013:Overview of machine vision systems
014:German craftsmen: We don’t have anything that’s “cheap and good”
015:Why the best robotic arms have 7 degrees of freedom instead of 6?
016:The most powerful technology video ever!
017:Comparison of the top 10 popular programming languages for robots, which one do you know?
018:Novel and complex mechanical principle diagrams!
019:A collection of knowledge related to robot control systems
020:The working principles of robots, the most detailed analysis ever!
021:Knowledge points on light source selection
022:This is a mechanical hand, this is automation, what you have is nothing!
023:Basic knowledge of cameras and lenses
024:Panorama of the IoT industry chain (with another 13 panoramic charts of the electronics industry, must collect)
025:How powerful is Japan? It’s breathtaking! I couldn’t sleep the night after watching it
026:Germany’s machinery has amazed the world: invincibility is so lonely