
Some readers have asked me: What should I learn to work in C++ backend development?
C++/Linux server development, commonly known as C++ backend development, has a high demand for positions in large tech companies like BAT. Companies like Tencent have an urgent need for C++ backend developers. Although these positions require a high level of technical skill, friends who dream of entering these big companies should still give it a try.
Many individuals with a foundation in C/C++ often ask during interviews for backend development positions: What level of technical skill is required to enter a big company?
In terms of interviews, there are two situations: campus recruitment and social recruitment. For campus recruitment, the technical requirements are relatively low. Understanding C with STL, common data structures and algorithms, and being able to solve medium-difficulty problems from Leetcode during the written test can score you 70 points. Additionally, being proficient in STL, auto, lambda, and other usages will also earn you extra points. For interns, as long as they perform well, they have a chance of being hired; the remaining skills such as network programming and Linux environment programming can be trained after entering the company.
Therefore, campus recruitment places more emphasis on your foundation and learning ability. During the internship, the company will observe your technical learning progress to decide whether to offer you a formal offer. Of course, if you can master skills like Linux environment programming and network programming in advance, it will definitely increase your competitiveness, as competition is common in any field. Social recruitment places more emphasis on your work experience and project experience.
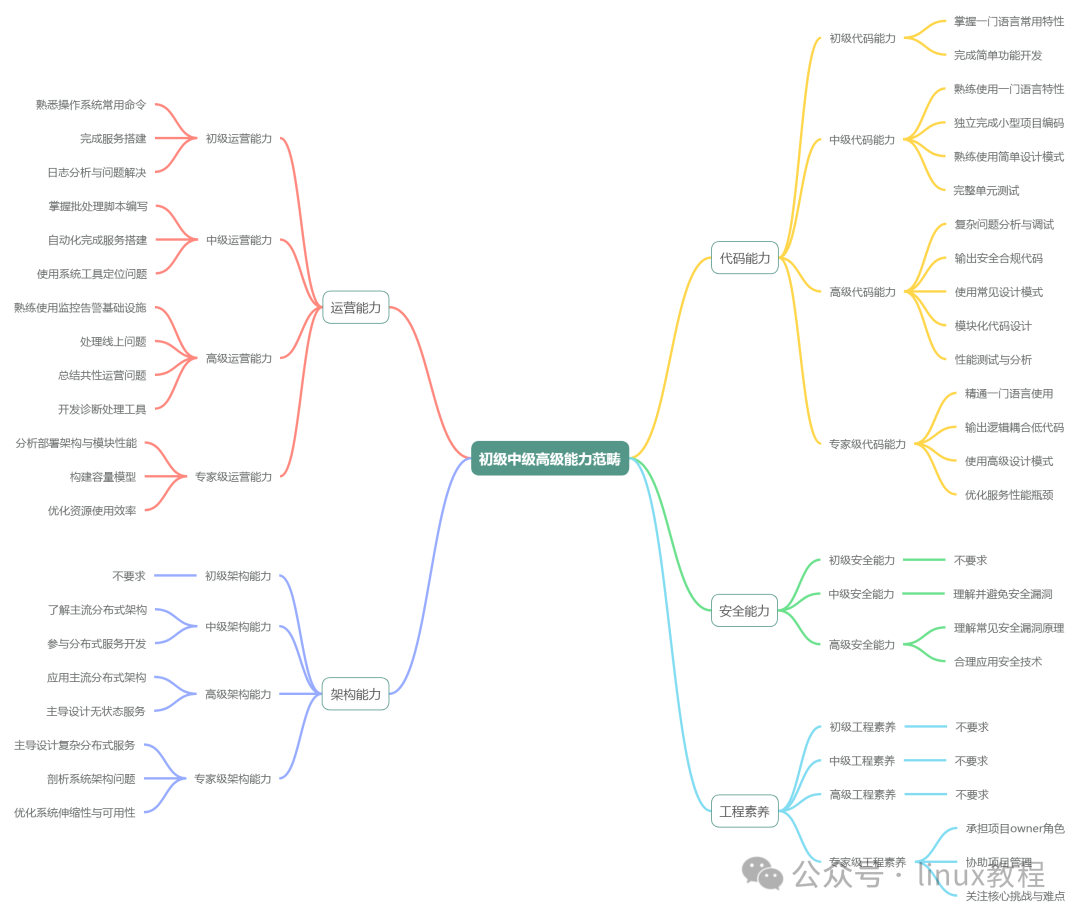
00
Basic Skill Requirements
-
Solid programming fundamentals, proficient in C/C++/Java and familiar with common algorithms and data structures;
-
Familiar with TCP/UDP network protocols, with relevant programming experience, and understanding of inter-process communication programming;
-
Understanding of scripting languages such as Python, Shell, Perl;
-
Familiar with MYSQL databases and SQL programming, understanding NoSQL databases, and mastering key-value storage principles;
-
A comprehensive and solid software knowledge structure, including operating systems, software engineering, design patterns, data structures, database systems, network security, and other professional knowledge;
-
Experience in designing and developing distributed systems, understanding load balancing technology, system disaster recovery design, and high-availability systems.
Before learning C/C++, it is essential to have a clear plan, understand what work this technology will lead to in the future, and what the conditions and requirements for this work are.
Some broad directions include: server direction, network security direction, audio/video/streaming/SDK, embedded direction, test development engineer, game engine development engineer, database development engineer, client/desktop development engineer, network transmission protocol optimization engineer, Linux kernel development engineer, storage development, etc.
Taking the server development direction as an example, this direction includes Linux server development engineers, Linux backend/backend development engineers, etc. For instance, Tencent has specific basic requirements for server development engineers, which can be referenced in the image below. The job requirements for other directions can also be found on relevant recruitment websites.
Next, a clear learning roadmap outline should be established to systematically learn C/C++, avoiding wasting time and energy.
Learning C++ places great importance on methodology. The difficulty lies not in the various syntax knowledge but in mastering the principles behind the language implementation, such as the runtime environment, operating systems, network knowledge, algorithmic thinking, etc.
For many who believe that C++ Linux server development is difficult to learn, cannot be learned, or is not understood.
Below is a summarized outline of a C++ backend learning path:
01
Basic Theory Column
1.1 Data Structures and Algorithms
Red-Black Tree
-
Application scenarios of red-black trees in process scheduling CFS and memory management
-
Mathematical proof and derivation of red-black trees
-
Handwritten demonstration of left and right rotations of red-black trees
-
Implementation of red-black tree addition operations and proof of three cases
-
Implementation of red-black tree deletion operations and proof of four cases
-
Thread-safe implementation methods of red-black trees
-
Practical characteristics of red-black trees in practice
B-trees and B+ trees for disk storage
-
Disk structure analysis and data storage principles
-
Application of multi-way trees and definition proof of B-trees
-
Two splitting methods for B-tree insertion
-
Borrowing and node merging methods for B-tree deletion
-
Handwritten demonstration of B-tree insertion, deletion, traversal, and search
-
Definition and implementation of B+ trees
-
Predecessor and successor pointers of B+ tree leaf nodes
-
Application scenarios and practical characteristics of B+ trees
-
Thread-safe implementation methods of B+ trees
Data Deduplication Techniques
-
Abhloriter Bitap algorithm for massive data deduplication
-
Hash principles and implementation of hash functions
-
Application scenarios of hash
-
Implementation principles of distributed hash
-
Bloom filter for massive data deduplication
-
Mathematical derivation and proof of Bloom filters
1.2 Design Patterns Column
Creational Design Patterns
-
Singleton Pattern
-
Strategy Pattern
-
Observer Pattern
-
Factory Method Pattern and Abstract Factory Pattern
-
Prototype Pattern
Structural Design Patterns
-
Adapter Pattern
-
Proxy Pattern
-
Chain of Responsibility Pattern
-
State Pattern
-
Bridge Pattern
-
Composite Pattern
1.3 New Features of C++ Column
STL Containers and Smart Pointers
-
STL Containers
-
Smart Pointers (shared_ptr, unique_ptr)
-
Usage of unordered_map
-
Usage and principles of hash
Regular Expressions and Function Objects
-
Basics of Regular Expressions (basic_regex, sub_match)
-
Function Object Templates (function, bind)
Multithreading and Concurrent Programming
-
New features of threads and coroutines
-
Atomic operations and usage and principles of atomic
-
Applications of Lambda Expressions
-
Usage of thread_local variables and condition_variable
Exception Handling and Error Handling
-
Exception Handling (exception_ptr)
-
Error Handling (error_category)
-
Usage and principles of coroutines
1.4 Linux Engineering Management and System Monitoring
Build Tools and Version Control
-
Makefile / CMake / configure principles and applications
-
Build tool parameter passing and operation functions
-
Git workflow, basic operations, branch management, and server setup
System Monitoring Tools
-
Linux runtime parameter commands and system runtime status
-
Inter-process communication facility status (ipcs) and system uptime (uptime)
-
Analysis tools for CPU average load, disk activity, and multi-processor usage (iostat, mpstat)
-
Monitoring, collecting, and reporting system activity (sar), memory usage (pmap), and multi-processor usage (nmon)
System Monitoring and Network Tools
-
glances, strace, ftptop, and power management (powertop)
-
MySQL performance monitoring (mytop), system runtime parameter analysis (htop/top/atop)
-
Linux network statistics monitoring tools (netstat), network packet analysis (tcpdump)
-
Standard protocols for remote login services (Telnet), real-time network statistics retrieval (iptraf), and network interface bandwidth usage (iftop)
02
High-Performance Networking Column
2.1 Asynchronous Network Library zvnet
-
Network I/O and I/O multiplexing: select/poll/epoll
-
Association of Socket and file descriptors
-
Code implementation of multiplexing select/poll
-
Differences in implementing LT/ET modes
-
Principles and implementation of event-driven reactor
-
Advantages of reactor for business implementation
-
poll encapsulation send_cb/recv_cb/accept_cb
-
Implementation of reactor in multi-core environments
-
Cross-platform (select/epoll/kqueue) encapsulation reactor
-
Network components: redis, memcached, nginx
-
Implementation of HTTP server
-
Encapsulation of sendbuffer and recvbuffer in HTTP protocol in reactor
-
HTTP protocol format
-
Finite State Machine (FSM) parsing HTTP
-
Other protocols: WebSocket, TCP file transfer
2.2 Network Principles
-
Implementation of million concurrent processing on the server (practical operation)
-
Differences between synchronous and asynchronous data processing
-
Asynchronous processing of network I/O with thread pool
-
ulimit support for FD reaching millions
-
Tuning rmem and wmem in sysctl.conf
-
Analysis of connection tracking (conntrack) principles
-
POSIX API and network protocol stack
-
connect, listen, accept, and three-way handshake
-
listen parameter backlog
-
Solutions to prevent SYN flood
-
close and four-way handshake
-
11 state transitions
-
Causes and solutions for many close_wait and time_wait
-
TCP keepalive and application layer heartbeat packets
-
Congestion control and sliding window
-
UDP reliable transport protocol QUIC
-
Advantages and disadvantages of UDP
-
UDP high concurrency design scheme
-
Why QQ chose UDP as the communication protocol in its early days
-
Principles of reliable transmission over UDP
-
Design principles of the QUIC protocol
-
Open-source solution quiche for QUIC
-
Design scheme and algorithm principles of KCP
2.3 Self-developed Framework: Implementation of User-Space Protocol Stack Based on DPDK
-
Design and implementation of user-space protocol stack
-
Applicable scenarios and implementation principles of user-space protocol stack
-
netmap open-source framework
-
Implementation of eth protocol, IP protocol, UDP protocol
-
Implementation of ARP protocol, ICMP protocol
-
Specific implementation of application layer POSIX API
-
Implementation of socket/bind/listen
-
Implementation of accept
-
Implementation of recv/send
-
Explanation of sliding window/slow start
-
Retransmission timer, persist timer, time_wait timer, keepalive timer
-
Implementation of epoll
-
Encapsulation of epoll data structure and implementation of thread safety
-
Implementation of FD readiness callback in protocol stack
-
Implementation of epoll interface
-
Implementation of LT/ET modes
-
High-performance asynchronous I/O mechanism IO_uring
-
IO_uring comparable to epoll
-
IO_uring system calls: io_uring_setup, io_uring_register, io_uring_enter
-
Relationship between liburing and IO_uring
-
Performance comparison of IO_uring and epoll
-
Shared memory mechanism of IO_uring
-
Usage scenarios of IO_uring
-
Implementation mechanism of IO_uring’s accept, connect, recv, send
-
IO_uring network read/write
-
IO_uring disk read/write
-
Implementation of proactor
03
Component Design Column
3.1 Pool-based Components
-
Handwritten thread pool and performance analysis (project)
-
Asynchronous processing usage scenarios of thread pool
-
Composition of thread pool task queue execution queue
-
Task callback and condition waiting
-
Dynamic prevention of thread pool shrinkage
-
Extension: Comparison analysis of nginx thread pool implementation
-
Implementation and scenario analysis of memory pool (project)
-
Application scenarios and performance analysis of memory pool
-
Small block memory allocation and management
-
Large block memory allocation and management
-
Handwritten memory pool, struct encapsulation, and API implementation
-
Two universal methods to avoid memory leaks
-
Three tools to locate memory leaks
-
Extension: nginx memory pool implementation
-
MySQL connection pool implementation (project)
-
Two factors affecting connection pool performance: top connections and MySQL authentication
-
Connection request return strategy
-
Connection timeout return strategy
-
Reconnect strategy for broken connections
-
Optimal strategy for connection quantity
3.2 High-Performance Components
-
Atomic operation CAS and lock implementation (project)
-
Usage scenarios and principles of mutex locks
-
Performance analysis of spin locks
-
Assembly implementation of atomic operations
-
Lock-free message queue implementation (project)
-
Performance of lock and lock-free queues
-
Memory barrier design
-
Design and implementation of lock-free array queue
-
Design and implementation of lock-free linked list queue
-
Network buffer design
-
RingBuffer design
-
Fixed-length message packets
-
ChainBuffer design
-
Double buffer design
-
Timer schemes: red-black tree, time wheel, minimum heap (project)
-
Usage scenarios of timers
-
Red-black tree storage of timers
-
Implementation of time wheel
-
Implementation of minimum heap
-
Implementation of distributed timers
-
Handwritten deadlock detection component (project)
-
Phenomena and principles of deadlocks
-
Implementation of pthread_mutex_lock/pthread_mutex_unlock dIsym
-
Construction of directed graphs
-
DFS to determine the existence of cycles in directed graphs
-
Three primitive operations: lock before, lock after, unlock after
-
Implementation of deadlock detection thread
-
Handwritten memory leak detection component (project)
-
Memory leak phenomena
-
Third-party memory leaks and code memory leaks
-
Implementation of malloc and free dIsym
-
Memory detection strategies
-
Application scenario testing
-
Step-by-step implementation of distributed locks (project)
-
Multithreaded resource competition mutex locks
-
Spin locks
-
Abnormal situations of locking
-
Implementation of unfair locks
-
Implementation of fair locks
3.3 Open Source Components
-
Asynchronous logging scheme spdlog (project)
-
Performance bottleneck analysis of logging libraries
-
Design and implementation of asynchronous logging library
-
Batch writing and double buffering mechanism
-
Log recovery after crashes
-
Application layer protocol design ProtoBuf (project)
-
IM, cloud platform, nginx, http, redis protocol design
-
How to ensure message integrity
-
Handwritten protobuf IM communication protocol
-
protobuf serialization and deserialization
-
protobuf encoding principles
-
The above is the content of the basic component design column, covering pool-based components, high-performance components, and open-source components.
04
Middleware Development
4.1 Redis
-
Detailed explanation of Redis-related commands and their principles
-
Implementation of distributed locks
-
Lua scripts to solve ACID atomicity
-
Analysis of ACID properties of Redis transactions
-
Redis protocol and asynchronous methods
-
Redis protocol parsing
-
Storage principles and data models
-
Master-slave synchronization and object model
-
Three cluster modes of Redis and four persistence schemes
-
Implementation of specific data structures (such as string, list, hash, set, zset, etc.)
4.2 MySQL
-
SQL statements, indexes, views, stored procedures, triggers
-
MySQL architecture, SQL execution process
-
SQL CURD and advanced queries
-
MySQL permission management
-
MySQL index principles and SQL optimization
-
Analysis of MySQL transaction principles
-
Types of locks, lock algorithm implementation, and lock operation objects
-
MySQL caching strategies
4.3 Kafka
-
Usage scenarios and design principles of Kafka
-
Publish-subscribe model and point-to-point message delivery
-
Principles of Kafka Brokers
-
Storage mechanism of Topics and Partitions
-
Offset lookup for messages
-
Storage mechanism of Kafka
-
Cornerstone of communication between microservices: gRPC
-
Internal component association of gRPC
-
Implementation of asynchronous gRPC
-
Asynchronous calls using callback methods
4.4 Nginx
-
Nginx reverse proxy and system parameter configuration conf principles
-
Nginx static file configuration
-
Nginx dynamic interface proxy configuration
-
Nginx forwarding of Mqtt protocol
-
Nginx pushing and pulling streams for Rtmp
-
Openresty proxying Redis cached data
-
Nginx filter module implementation
-
Nginx Handler module implementation
-
How to achieve load balancing
-
Nginx core data structures ngx_cycle_t, ngx_event_module_t
-
Design and implementation of the Upstream mechanism
05
Open Source Frameworks
5.1 Game Server Development – Skynet Design Principles
-
Multi-core concurrent programming: including multithreading, multiprocessing, CSP model, and Actor model
-
Implementation of Actor model: Lua service and C service
-
Implementation of message queue and Actor message scheduling
-
Skynet network layer encapsulation and Lua/C interface programming
-
Skynet Reactor network model encapsulation
-
Socket/SocketChannel encapsulation
-
High-performance C service development
-
Lua programming and Lua/C interface programming
-
Important components of Skynet and game project development
-
Basic interfaces: Skynet.send, Skynet.call, Skynet.response
-
Broadcast component: Multicastd
-
Data sharing components: SharedData, DataSheet
-
Development of games with thousands of players online
5.2 Distributed API Gateway
-
High-performance web gateway Openresty
-
Nginx and Lua modules
-
Openresty accessing Redis and MySQL
-
Restful API interface development
-
Openresty performance analysis
-
Kong dynamic load balancing and service discovery
-
Integration between Nginx, Openresty, and Kong
-
Principles of dynamic load balancing
-
Implementation principles of service discovery
-
Serverless architecture
-
Monitoring, fault detection, and recovery
-
Proxy layer caching and response services
-
System logs
5.3 SPDK Assisting MySQL Data Persistence
-
Design and implementation of SPDK file system
-
Principles of NVMe and PCIe
-
RPC between NVMe Controller and Bdev
-
Relationship between Blobstore and Blob
-
Implementation of POSIX API for file systems
-
4-layer structure design VFS
-
Asynchronous transformation of SPDK and POSIX synchronous API
-
Implementation of Open/Write/Read/Close
-
Performance testing of file systems and accommodating MySQL business
-
Using LD_PRELOAD to optimize MySQL system call implementation
-
Explanation of Iodepth and comparison of random read/write and sequential read/write performance
5.4 High-Performance Computing – CUDA Development
-
Development process of GPU parallel computing CUDA
-
Heterogeneous computing of CPU+GPU
-
GPU in computer architecture
-
Setting up CUDA environment: usage of NVCC and SRUN
-
CUDA vector addition and matrix multiplication
-
MPI and CUDA
-
Parallel computing in audio/video encoding and decoding
-
CUDA’s H.264 and MPEG encoding and decoding
-
FFmpeg’s support for CUDA
5.5 Parallel Computing and Asynchronous Network Engine Workflow
-
Application scenarios and programming paradigms of Workflow
-
Request processing of MySQL/Redis/Kafka/DNS
-
Parallel processing and task assembly
-
Implementation of Workflow components and thread pool
-
Implementation of DAG graph tasks and message queues
-
Implementation of pure C JSON parser
5.6 IoT Communication Protocol MQTT Implementation Framework – Mosquitto
-
Efficient usage scenarios of MQTT
-
Publish-subscribe model of MQTT
-
Data transmission in low-bandwidth network environments
-
Three QoS levels
-
Security authentication with OAuth and JWT
-
MQTT Broker
-
MQTT’s Last Will mechanism
-
Publish-subscribe filters
-
Docker deployment of Mosquitto
-
Real-time monitoring of MQTT logs
06
Cloud Native
6.1 Docker
Docker Kernel Features
-
Process namespace
-
UTS namespace
-
IPC namespace
-
Network namespace
-
File system namespace
-
Resource control of cgroup
Docker Container Management and Image Operations
-
Docker image download and image running
-
Docker storage management
-
Docker data volumes
-
Docker and container security
-
Five Docker network drivers
-
pipework cross-host communication
-
0vS partitioning VLAN and tunnel mode
-
GRE implementation for cross-host Docker communication
Docker Cloud and Container Orchestration
-
Syntax flow of Dockerfile
-
Orchestration tools Fig/Compose
-
FIynn architecture
-
What has Docker changed?
6.2 Kubernetes
k8s Environment Setup
-
k8s cluster security settings
-
k8s cluster network settings
-
k8s core service configuration
-
kubectl command tool
-
yaml file syntax
Usage of Pods and Services
-
Management configuration of Pods
-
Pod upgrades and rollbacks
-
DNS services in k8s
-
HTTP layer 7 policies and TLS security settings
Related Content of k8s Cluster Management
-
Management of Nodes
-
Namespace isolation mechanism
-
k8s cluster log management
-
k8s cluster monitoring
k8s Secondary Development and k8s API
-
RESTful interfaces
-
API aggregation mechanism
-
API groups
-
Go access to k8s API
07
Performance Analysis Column
7.1 Testing Frameworks
-
gtest and memory leak detection
-
googletest and googlemock files
-
Function detection and class testing
-
Test fixture
-
Type parameterization
-
Event testing
-
Memory leak detection
-
Setting expectations, expected parameters, call counts, and meeting expectations
-
Performance tools and performance analysis MySQL performance testing tool: mysqlslap Redis performance testing tool: redis-benchmark HTTP performance testing tool: wrk TCP performance testing tool: TCPBenchmarks Disk, memory, and network performance analysis Flame graph generation principles and construction methods Flame graph tool explanation Flame graph usage scenarios and principles Nginx dynamic flame graph MySQL flame graph Redis flame graph
7.2 Observability Technology BPF and eBPF
Kernel Observability Technology
-
Implementation principles of kernel BPF
-
Understanding tracing, sniffing, sampling, and observability
-
Dynamic hook: kprobe/uprobe
-
Static hook: tracepoint and USDT
-
Performance monitoring timer PMC mode
-
Observability of CPU and usage of taskset
-
BPF tools: bpftrace, BCC
-
Observability of kernel functions by BPF
-
Memory observability: kmalloc and vm_area_struct
-
File system observability: VFS status
-
Disk IO observability: bitesize, mdflush
-
BPF for network traffic statistics
-
BPF for observing Redis servers
-
Network observability: tcp_connect, tcp_accept, tcp_close
7.3 Kernel Source Mechanisms
Content related to kernel source mechanisms
-
Process scheduling mechanisms
-
QEMU debugging memory
-
Process scheduling: CFS and four other scheduling classes
-
task_struct structure
-
RCU mechanism and memory optimization barriers
-
Kernel memory management operating mechanisms
-
Virtual memory address layout
-
SMP/NUMA models
-
Page table and page table cache principles
-
Buddy system implementation
-
Block allocation (Slab/Slub/Slob) principles and implementation
-
brk/kmalloc/vmalloc system call process
-
File system components
-
Virtual File System (VFS)
-
Proc file system
-
super_block and inode structures
-
File descriptors and mounting processes
08
Distributed Architecture
8.1 Distributed Databases
-
Usage scenarios of RocksDB, different from kv storage
-
Prefix search
-
Low-priority writes
-
Support for time-to-live
-
Transactions (ACID) snapshot storage
-
Log-structured database engine
-
TiDB storage engine principles and RBAC-based permission management
-
Data encryption
-
Cluster schemes and Replication principles
-
TiDB cluster components: TiDB Server, PD Server, TiKV Server
-
Raft protocol
-
OLTP and OLAP
8.2 Distributed File Systems
-
Ceph kernel-level supported distributed storage
-
Cluster deployment
-
Five core components
-
Cluster monitoring
-
Performance tuning and benchmarking
-
Ceph storage cluster deployment
-
Synchronization mechanisms
-
Linear expansion
-
High availability implementation
-
Load balancing
8.3 Distributed Coordination
-
Etcd registration service center
-
Configuration service, service discovery, monitoring, leader election, distributed locks
-
Detailed architecture
-
Storage principles
-
Read-write mechanisms and analysis of ACID properties of transactions
-
Detailed explanation of the Raft consensus algorithm
-
User-space file system fuse for collaborative events usage scenarios
-
File system read-write events
-
Implementation principles /dev/fuse’s role
8.4 P2P Network Technology
-
Revealing the core technology of Kuaibo: Implementation of P2P framework
-
Analysis of gateway NAT table
-
NAT types
-
Code logic implementation of NAT type detection
-
Principles of network penetration
-
Three situations of network penetration
09
Listing of Practical Projects
9.1 DKV Storage Implementation (Tech Stack):
-
KV storage architecture design
-
Definition of storage nodes
-
TCP server/client
-
Hash data storage
-
List data storage
-
SkipTable data storage
-
RBTree data storage, network synchronization, and transaction serialization
-
Serialization and deserialization formats
-
Establishing transactions and releasing transactions
-
Thread-safe processing, memory management, and performance optimization
-
Usage of memory pools and LRU (Least Recently Used) implementation
-
Large and small block memory allocation strategies
-
Memory recovery mechanisms, data persistence
-
Performance testing of KV storage, network testing TPS (transactions per second), throughput testing, multi-language support (Go, Lua, Java)
9.2 Image Hosting Shared Cloud Storage (Tech Stack):
-
Ceph architecture analysis and configuration
-
Quick configuration of Ceph
-
File upload logic analysis
-
File download logic analysis
-
File transfer and interface design
-
HTTP interface design, image hosting database design
-
Implementation of file upload, download, and sharing functions
-
Implementation of business processes
-
Containerized Docker deployment
-
Crontab scheduled data cleanup
-
Docker server services
-
gRPC connection pool management
9.3 Containerized Docker Deployment (Tech Stack):
-
Crontab scheduled data cleanup
-
Docker server services
-
gRPC connection pool management
-
Product cloud public release/testing case analysis of cloud servers
-
Fiddler monitoring HTTP requests
-
Using Postman to simulate requests
-
wrk testing interface throughput
-
JMeter stress testing
9.4 Microservices Instant Messaging (Tech Stack):
-
Analysis and deployment of IM instant messaging project framework
-
Analysis of instant messaging application scenarios
-
Advantages and disadvantages of self-developed and third-party SDK for instant messaging
-
Instant messaging database design
-
Deployment of instant messaging project
-
IM message server/file transfer server instant messaging function implementation
-
User login verification password + obfuscation code MD5 matching
-
Full and incremental pulling methods for friend lists and user information
-
Unread message mechanism
-
Push-pull mechanism for one-on-one and group chat messages
-
Routing forwarding mechanism
9.5 World of Warcraft Backend TrinityCore (Tech Stack):
-
Implementation of network module
-
Implementation of map module
-
Implementation of A0I core algorithm
-
Implementation of combat module
-
Implementation of TrinityCore gameplay
-
User gameplay implementation – quest system
-
Data configuration and database design
-
Multiplayer gameplay implementation – guild design
10
k8s Secondary Development: Intranet Penetration
10.1 System Design and frp Open Source Project
-
Project background and requirement analysis
-
System design and database design
-
frp TCPMUX proxy and httpconnect multiplexer
-
frp ssh, http, https intranet penetration
-
frp AuthServerConfig token authentication
10.2 Application Management and Application Configuration
-
Maintenance of applications such as ssh, http, https
-
Application port allocation and configuration generation
-
Export application configuration to yaml format configuration files
10.3 Go Client Implementation of Kubernetes Cluster Application Deployment and Updates
-
Go client connecting to Kubernetes ai server
-
Go client creating configuration resource ConfigMap
-
Go client creating deployment resource Deployment
-
Go client creating service resource Service
10.4 Implementation of Frontend Page with vite/vue/elementUl
-
Vue component development and ElementUI
-
Application of Typescript’s interface
-
axios instance and interceptor
-
Encapsulation of get and post requests
-
Configuration files and API calls
10.5 Automated Domain Name Resolution and Kubernetes Cluster Deployment Tunnel Service
-
Automated domain name resolution and domain name remarks
-
Deployment of services and return of client configuration
-
Containerized deployment and flexibility of Tunnel service
-
Tunnel client configuration for deployment of Tunnel client program
-
certbot generates wildcard certificates for Tunnel applications.
11
Recommended Learning Books
-
MySQL: “High Performance MySQL 3rd Edition”
-
Nginx: “Understanding Nginx: Module Development and Architecture Analysis (2nd Edition)” (Tao Hui)
-
Redis: Redis Design and Implementation (Huang Jianhong)
-
Linux Kernel: “Understanding Linux Kernel Architecture” (Translated by Guo Xu)
-
Data Structures and Algorithms: “Introduction to Algorithms (3rd Edition)”
-
Performance Analysis: “The Pinnacle of Performance: Insights into Systems, Enterprises, and Cloud Computing”
-
MongoDB: “MongoDB: The Definitive Guide”
-
Ceph: “Ceph Distributed Storage Learning Guide” (Ceph China Community)
-
Docker: “Docker Containers and Container Clouds (2nd Edition)”
-
TCP/IP: “TCP/IP Illustrated Volumes 1, 2, and 3”
-
Linux System Programming: “Advanced Programming in the Unix Environment”
-
Computer: “Computer Systems: A Programmer’s Perspective”
-
DPDK: “Deep Dive into DPDK”
-
k8s: “Kubernetes: The Definitive Guide” by Gong Zheng et al.
-
bpf: “BPF: The Pinnacle of Insights into Linux System and Application Performance”
Many friends may lack patience and be eager for quick success when facing this long roadmap.
Indeed, there is so much to learn, how can one waste too much time on C/C++ basics/data structures and algorithms? Otherwise, how can one finish learning everything!
Here’s a saying to encourage everyone: Those who can “sit still” and are willing to learn without fear of being slow will eventually achieve success.
There is a lot of knowledge to learn, and the process requires you to slow down, even if it means completing a small C++ program, or spending a day just reading about C++ object-oriented knowledge. Study diligently, write articles well, and output effectively, and I believe you will eventually become a technical expert ∩( ・ω・)∩.