Linux | Red Hat Certified | IT Technology | Operations Engineer
👇 Join our technical exchange QQ group with 1000 members, note 【public account】 for faster approval

Understanding the File System Simply
To build a framework for the file system, we can start with this command:
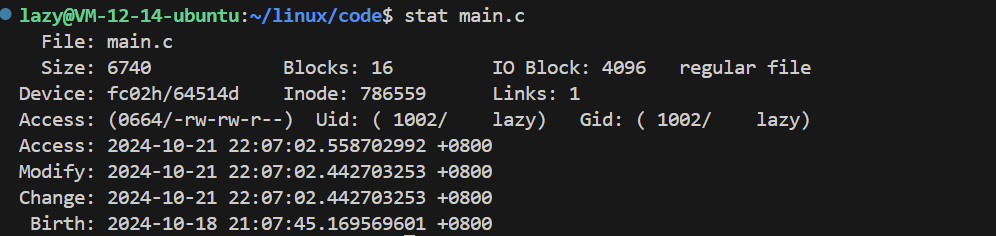
This is the stat command, which checks the information of a file. Is this information about the file’s attributes or its content?
We know that a file = attributes + content, but we often focus on the content of the file, while the attributes are not as commonly considered. Therefore, to understand the framework of the file system, we need to start with the file’s attributes.
From the information provided by stat, we see File: main.c, which represents the file name, Size represents the file size, Blocks? IO Block? Inode? What are these?
Don’t worry, let’s revisit the previous topic:
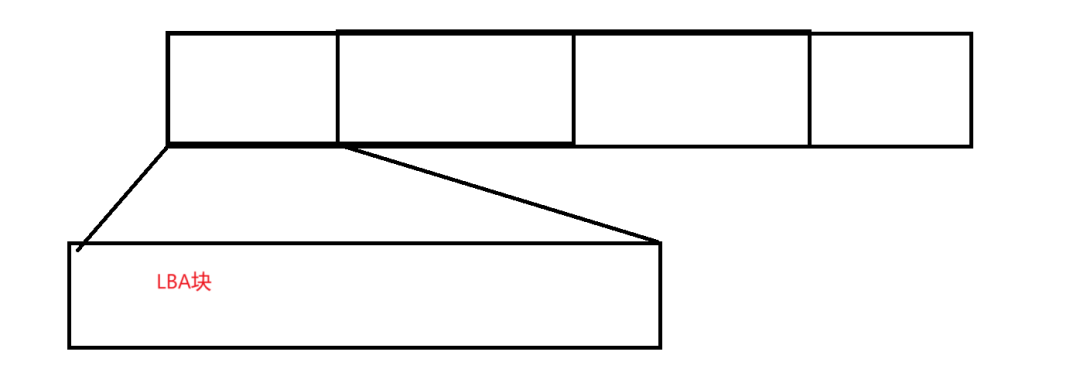
In the previous discussion, we converted the disk from a non-linear to a linear format, and we can view the linear space as an array. For arrays, we can find the storage address of data using a bitmap-like approach. However, due to the unique way disks retrieve data, which is done in 4KB chunks, the OS divides the data into multiple blocks, known as LBA blocks. Once divided, finding a whole block of space becomes much easier.
Thus, our management of files has transitioned from the disk, to CHS, to arrays, to LBA, and ultimately, we just need to clarify what is inside the LBA:
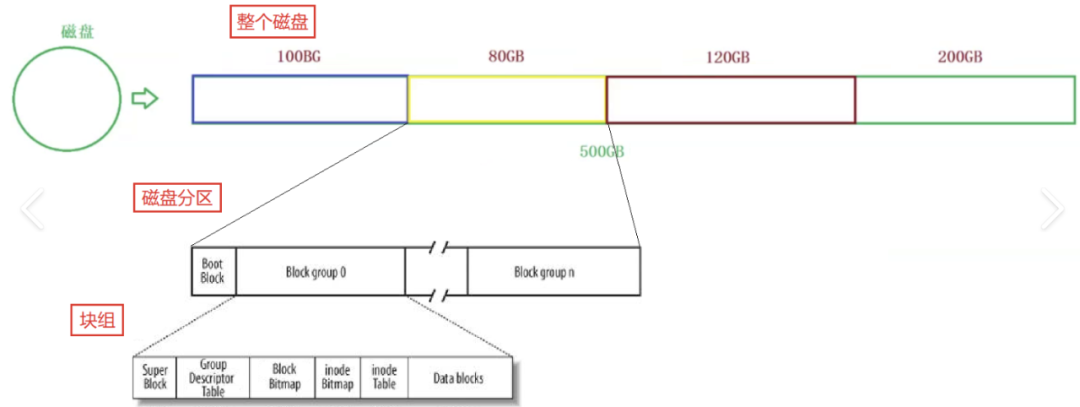
The illustrative image shows that within a block group, we have Super Block, Group Descriptor Table, Block Bitmap, Inode Table, and Data Blocks.
So where do we start our discussion?
Let’s start with Data Blocks: Data Blocks are where the content of the files is stored, but for ease of introduction, we have reduced the size of Data Blocks to be similar to others. This block occupies more than 95% of the entire block group’s space.
So what is inside the Data Blocks?

It appears very abstract because the Data Blocks store individual data blocks, each sized at 4KB, and when retrieving, we simply output that data block.
Among so many data blocks, they only store the content of the files.
Moreover, we know that a file = content + attributes. For the attributes of file content, Linux-specific file systems store the attributes and content separately, which we should keep in mind. We will stop our discussion on Data Blocks here.
Next, we have the Block Bitmap, which students are likely familiar with from learning C++.
When introducing bitmaps, we typically use them to determine whether data exists within a collection of data. Similarly, the block Bitmap is used to determine whether a specific data block contains data. We won’t elaborate on bitmaps here, but their introduction can significantly save time when traversing data blocks.
Next is the very important Inode Table, which stores file attributes such as file size, owner, last modified time, etc. This is the Inode Table.
So what attributes does a file generally have?
struct inode{ int size; mode_t mode; int creater; int time; ... int inode_number; int datablocks[N];};We can take a few common examples: file size, file permissions, creation time, etc. However, the most important aspects we should focus on are inode_number and datablocks[N].Since this block is called inode_table, it naturally contains a collection of these structures.
So!! The attributes of a file are just identical structures!!
Inside, how is the inode structure partitioned? It is partitioned by inode_number, and what is the role of datablocks? When we use a file, we find the corresponding file attribute structure through inode_number, and to find the content, we need datablocks, which point to the space of block Data:
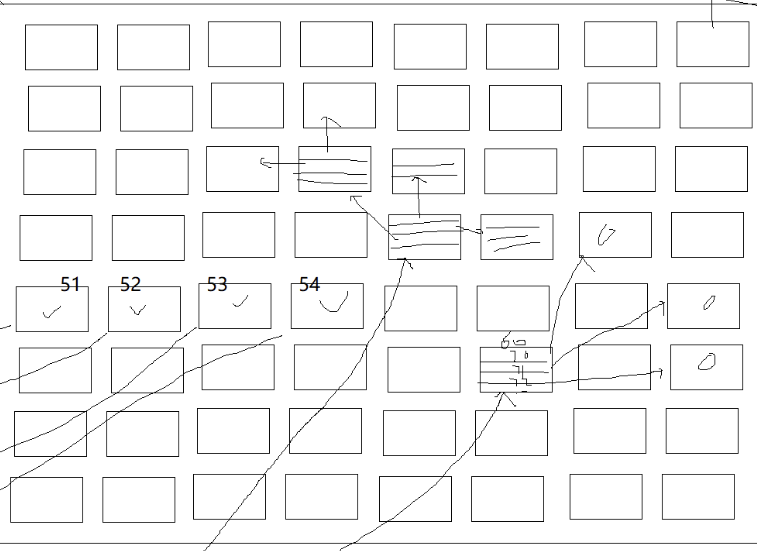
For example, if N equals 12, the first 11 directly point to data blocks, but we cannot find the corresponding large file, so the 12th points to a Data Block that also contains pointers to other data blocks, creating an exponential feel.
Moreover, data can point to 13, 14, and so on, and it is not just a simple one-layer relationship; it is a layer pointing to another layer, and so on, until it finally points to the data, allowing us to find the data of large files.
This method of data retrieval is called the ext2 file system, which is what most of us currently use, along with ext3, ext4, etc.
So we have a good understanding of the inode structure, what about the inode bitmap? Isn’t it similar?!!
We find a specific position in the table using the inode bitmap to check if a file’s attributes exist, and then proceed with subsequent operations.
Now, we clearly understand inode table, inode bitmap, data blocks, and data bitmap. For the remaining two, such as GDT, which stands for Group Descriptor Table, it describes the attributes of the block group, essentially the information of the block, reflecting a divide-and-conquer approach.
As for Super blocks, its name is quite powerful, as it stores the structural information of the file system itself, and not every group has one; only a few groups may have one. For example, it records the number of used inodes, unused inodes, number of used datablocks, and number of unused datablocks. These are the contents that the super block needs to record.
So, a question arises: since it records all structural information, why have so many of them?
Because disks can be damaged, and if the head happens to erase the content of a super block, wouldn’t that be disastrous? Therefore, we store a few more to increase fault tolerance!
Having said so much, inodes are extremely important. To view inode, use -i:
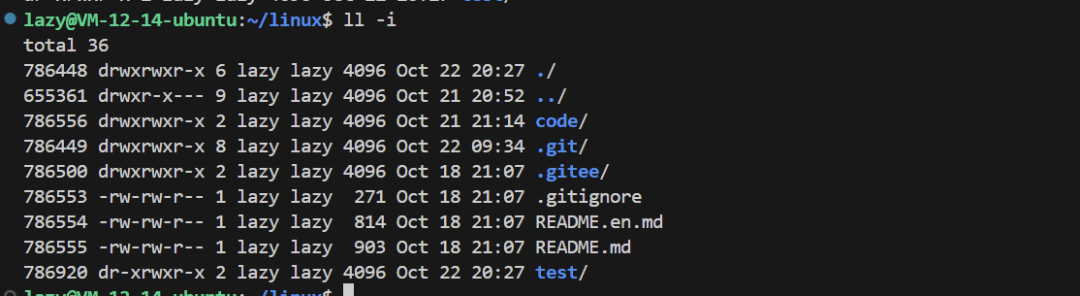
Understanding the Details
From the previous discussion, we have understood the six members within the block. Now let’s discuss specific detail issues:
First Detail:
How to find the corresponding data blocks through inode?
Since inode and data are partitioned, inode can be found through the array datablocks!
Second Detail:
Don’t we always use file names? It seems we haven’t used inode. However, when we change the file content, we are always using the file name, right?
At this point, we need to talk about directories. A directory = file attributes + file content. Don’t think that a directory is not a file. The question is, what is the file content of a directory?
The file content of a directory = the relationship between file names and inode numbers. When we create a file, the directory where the file is located will record the relationship between that file and its inode, making it easy to find and modify.
Thus, the file names in the directory represent the mapping relationship with inode!!
At this point, I believe students can understand why multiple files with the same name cannot be created in a directory. If a file with the same name is created, the entire file system would collapse due to the disruption of the mapping relationship.
However!! When we modify the directory, we still use the directory name! So what stores the relationship between the directory and inode?
Look at this:

pwd prints the path because of the environment variable PATH, and when we modify a file in that directory, we need to find the corresponding inode. To find the inode, we first need to locate the directory where the file is located, and to find that directory, we need to go up to the directory’s directory, eventually reaching the root directory!!
At the root directory, the OS has already preloaded information about the cached path. This involves knowledge points such as struct dentry, formatting, mounting, etc. For now, we just need to know that Linux caches path information, allowing us to modify the corresponding content through the file directory.
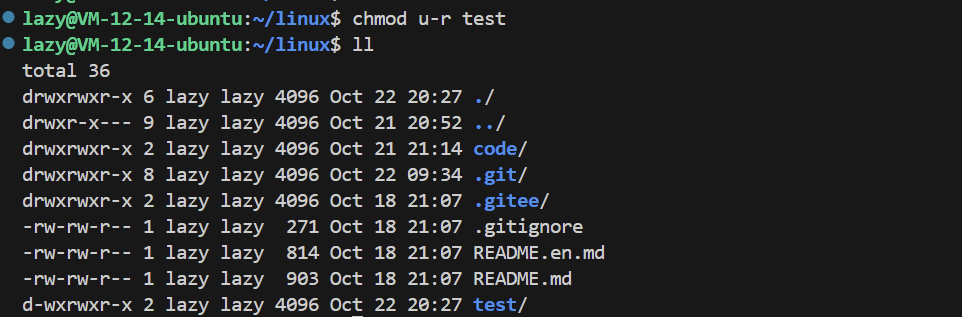
Now, let’s review the directory’s r w. When we remove r, meaning there is no read permission:

At this point, the directory does not allow us to read the file content, essentially preventing us from knowing the mapping relationship between file names and inode.
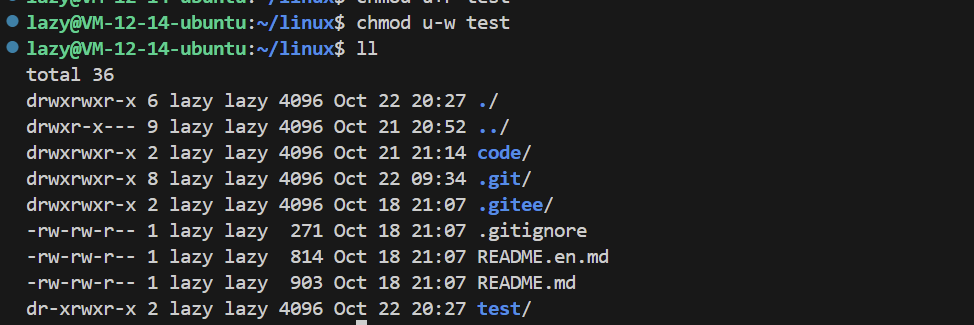
We won’t demonstrate this, but when we lose w permission, we cannot create files, which essentially prevents us from creating the mapping relationship between file names and inode!!
Thus, for Detail 2, we can conclude:
1. A directory cannot create multiple files with the same name because it would disrupt the mapping relationship.
2. The order of file lookup is through the file name to find the corresponding inode number.
3. r allows us to find the corresponding mapping relationship, while w prevents us from writing the corresponding mapping relationship.
Third Detail:
How do we understand file creation, deletion, and modification?
File creation involves finding the corresponding mapping relationship and adding data in the datablock, lookup is finding the corresponding mapping relationship, and modification is also through inode, modifying the data relationship in datablocks.
But what about deletion?
Actually, deletion here is a form of pseudo-deletion.
That is, simply setting the Inode bitmap and datablock bitmap to 0 is a form of deletion.
We have gained a simple understanding of the framework of the file system.
For course inquiries, add: HCIE666CCIE
↓ Or scan the QR code below ↓
What technical points and content would you like to see?
You can leave a message below to let us know!