
What processes does an SQL statement go through during execution? As a newcomer to big data development, the author has organized the entire process of SQL task execution. This article shares the author’s learning and insights for everyone’s reference.
As a new developer in big data, I am curious about the entire process of SQL task execution. What processes does an SQL statement go through during execution? After reviewing relevant documentation, I organized this document to share my learning and insights for everyone’s reference.
An SQL task involves multiple system interactions from creation to obtaining results. Here, we present an overall flowchart, and let’s start our exploration from a simple requirement—counting the number of each prize awarded in an event.
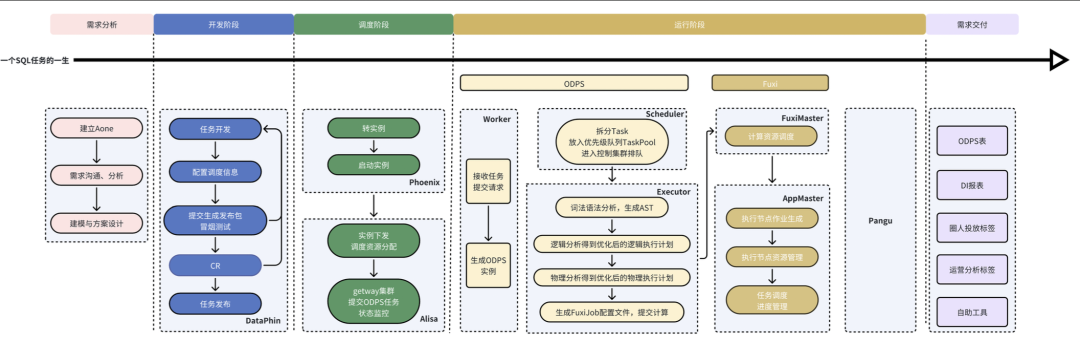
2. Task Development and Launch
First, we need to create and write an SQL task in the IDE. In the DataPhin development page, we create an offline periodic calculation task and write the SQL code.
SQL for counting the number of each event prize:
SELECT prize_id, COUNT(*) AS prize_send_cnt_1d FROM apcdm.dwd_ap_mkt_eqt_send_di WHERE dt = '${bizdate}' AND prize_id IN ('PZ169328936', 'PZ169298703') GROUP BY prize_id;
Configure Scheduling Information
After writing the SQL task, we need to configure the scheduling information for the task. This scheduling information is treated as metadata for the task and is maintained through the database. Only after configuring the correct scheduling information can the task be properly scheduled and executed. Common SQL task configurations are shown in the table below:
|
|
Task Node ID, Task Name, Node Type, Operations Responsible Person
|
|
|
Parameters used during Dataphin task scheduling, automatically replaced with specific values based on the task scheduling business date, scheduled time, and parameter value format, achieving dynamic replacement of parameters during task scheduling time.
Business Date: Day before the scheduling date
Scheduled/Trigger Time: Time when the task instance is planned to run
|
|
|
Instance Generation Method: T+1 next day generation, immediate generation after publication
|
|
Scheduling Type: Normal scheduling, paused scheduling, dry run scheduling
|
|
Effective Date: Date range for automatic scheduling
|
|
Re-run Attributes: Whether multiple re-runs will affect the result
|
|
Scheduling Cycle: How often to execute this task, can be monthly, weekly, daily, hourly, or minute-based scheduling
|
|
Cron Expression: Corresponding scheduling cycle cron expression
|
|
|
Upstream and downstream dependencies between nodes; downstream task nodes will only start running after the upstream task node runs successfully.
|
|
|
Input parameters (receiving output parameter values from upstream nodes as input for the current node), output parameters
|
|
|
Execution Engine, Scheduling Resource Group
|
After completing the SQL task writing and scheduling information configuration, we can submit the task and generate the release package. Before publishing, we can conduct smoke testing in the development environment. Smoke testing will generate an instance containing the code and scheduling information. Choosing instances generated before yesterday will run immediately as their scheduling time has been met. Choosing instances generated yesterday will require waiting for the scheduled time to arrive before running. After the task is submitted and smoke testing passes, we can go to the release center, select the task object to be released, and proceed with the release.
3. Instance Transition/Instance Production
Now that the task has been published online, what happens next?
The time is now 10:00 PM, and the Phoenix scheduling system begins to get busy. It compiles a batch of executable task instances in advance based on the task node definitions released by everyone and schedules this batch of task instances as a DAG according to the lineage and time dependencies between tasks. During the instance transition, the system’s built-in parsing function will parse the cron time expression configured for the task, setting the specific execution time for the corresponding task instance.
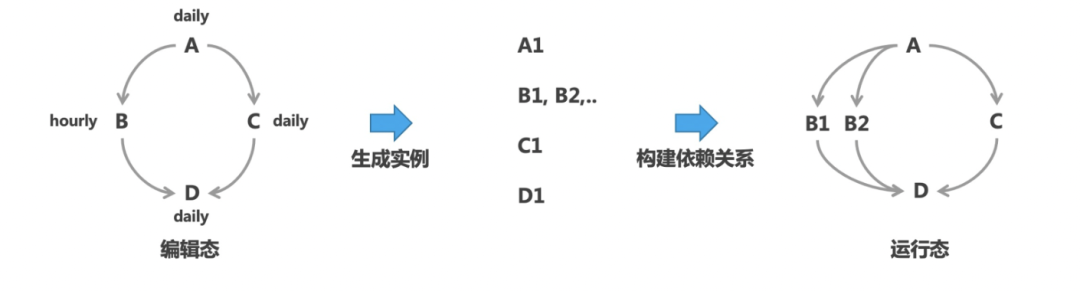
4. Timed Scheduling/Instance Start
After the instance transition process, the corresponding task instance DAG is ready. So how do we invoke the task instance for execution at the right time?
The early instance scheduling system was implemented using the Quartz framework, registering Quartz events and configuring the trigger’s cron time expression to specify the event’s trigger time. The Quartz framework triggers the corresponding event at the scheduled time based on the time expression, thereby starting the corresponding task instance. Since the Quartz framework encounters performance bottlenecks when the number of instances reaches millions, a new scheduling engine uses a self-developed solution of database-maintained status + asynchronous querying. Specifically, it maintains the execution time of all task instances in the database, and then the scheduling system’s background thread asynchronously queries the task instances that meet the time and triggers their execution.
5. Scheduling Resource Allocation
After invoking the task instance, we need to allocate resources to the instance and submit it to ODPS for execution. This logic is handled by the execution engine Alisa.
Once Alisa receives the task, it will dispatch the task to a specific gateway based on whether the task resource group is idle and whether the scheduling task execution cluster resources are available. The gateway is the process responsible for submitting ODPS tasks and managing task status within the Alisa cluster. Since tasks need to be submitted to the computing engine for execution, a session connection must be maintained during the process of submitting tasks, occupying a slot (slot), which refers to the capacity to submit tasks. To ensure that important business priorities use resources and to meet the resource usage needs of multiple users and tenants, a gateway execution cluster and resource group mode have been designed to control the slot usage. A cluster can contain multiple gateway machines, and the cluster’s slots can be allocated to multiple resource groups.
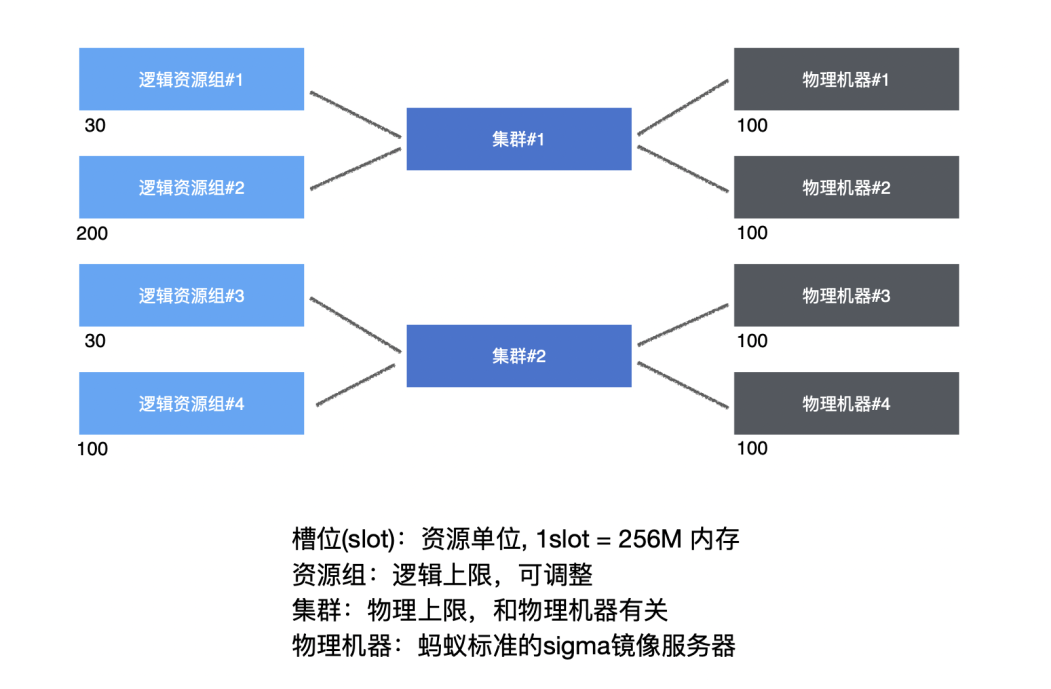
By setting the project space to a specific resource group, tasks submitted from this project space can use the slots of this resource group. Each resource group controls concurrency by setting a maximum slot (max_slot) and can view the slot usage of the project space in real-time through tesla.
By setting the project space to a specific resource group, tasks submitted from this project space can use the slots of this resource group. Each resource group controls concurrency by setting a maximum slot (max_slot) and can view the slot usage of the project space in real-time through tesla.
 The Alisa execution engine manages slot usage and maintains a heartbeat connection with each gateway machine, responsible for allocating slots to tasks. If the scheduling slots are full, the job will be in a congested state, waiting for slot allocation. Once the task is allocated a slot, it will begin submitting the task on the specified gateway machine, i.e., starting the odpscmd process on the gateway to submit the job.
After submitting the job through the gateway process using odpscmd, it officially enters the execution process of the ODPS system.
The ODPS system can be divided into two parts: the control layer and the compute layer. The submitted job first enters the control layer of ODPS, which includes the request processor Worker, scheduler Scheduler, and job execution manager Executor. After the job submission generates an instance, the Scheduler is responsible for scheduling the instance. The Scheduler first maintains an instance list, then retrieves the instance from the list, decomposes the instance into multiple Tasks, and places the runnable Tasks into the priority queue TaskPool, entering the control cluster’s queue. A background thread of the Scheduler periodically sorts the priority queue TaskPool, while another background thread periodically queries the resource status of the compute cluster. The Executor actively polls the Scheduler, and if the control cluster still has resources, it sends the highest priority SQLTask to the Executor.
The Alisa execution engine manages slot usage and maintains a heartbeat connection with each gateway machine, responsible for allocating slots to tasks. If the scheduling slots are full, the job will be in a congested state, waiting for slot allocation. Once the task is allocated a slot, it will begin submitting the task on the specified gateway machine, i.e., starting the odpscmd process on the gateway to submit the job.
After submitting the job through the gateway process using odpscmd, it officially enters the execution process of the ODPS system.
The ODPS system can be divided into two parts: the control layer and the compute layer. The submitted job first enters the control layer of ODPS, which includes the request processor Worker, scheduler Scheduler, and job execution manager Executor. After the job submission generates an instance, the Scheduler is responsible for scheduling the instance. The Scheduler first maintains an instance list, then retrieves the instance from the list, decomposes the instance into multiple Tasks, and places the runnable Tasks into the priority queue TaskPool, entering the control cluster’s queue. A background thread of the Scheduler periodically sorts the priority queue TaskPool, while another background thread periodically queries the resource status of the compute cluster. The Executor actively polls the Scheduler, and if the control cluster still has resources, it sends the highest priority SQLTask to the Executor.
 After the Executor receives the task, it calls SQL Parse Planner for lexical and syntactic analysis, obtaining an abstract syntax tree (AST) after lexical analysis and an optimized logical execution plan after logical analysis, followed by an optimized physical execution plan after physical analysis.
After the Executor receives the task, it calls SQL Parse Planner for lexical and syntactic analysis, obtaining an abstract syntax tree (AST) after lexical analysis and an optimized logical execution plan after logical analysis, followed by an optimized physical execution plan after physical analysis.
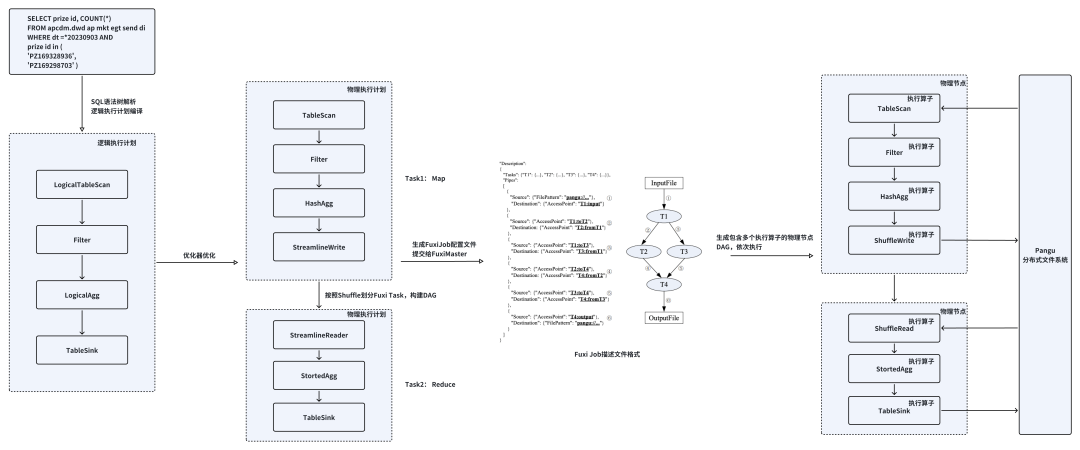
The physical execution plan is divided according to whether shuffle is needed during data processing, resulting in a physical operator DAG diagram, where one node corresponds to one Fuxi Task. Based on the DAG diagram and instance metadata (the number of instances for each Fuxi Task, resource specifications, etc.), a configuration file for Fuxi Job is generated and submitted to Fuxi Master.
Fuxi is the distributed scheduling execution framework of the big data computing platform, supporting millions of distributed jobs every day across various computing engines like ODPS and PAI, used to process massive amounts of data at the EB level daily. The Fuxi cluster consists of Master and Agent, with Agents distributed across each compute node, responsible for resource management of individual compute nodes and reporting node information to the Master. The Master collects resource usage from each node and manages and coordinates the allocation of computing resources.
The physical execution plan is divided according to whether shuffle is needed during data processing, resulting in a physical operator DAG diagram, where one node corresponds to one Fuxi Task. Based on the DAG diagram and instance metadata (the number of instances for each Fuxi Task, resource specifications, etc.), a configuration file for Fuxi Job is generated and submitted to Fuxi Master.
Fuxi is the distributed scheduling execution framework of the big data computing platform, supporting millions of distributed jobs every day across various computing engines like ODPS and PAI, used to process massive amounts of data at the EB level daily. The Fuxi cluster consists of Master and Agent, with Agents distributed across each compute node, responsible for resource management of individual compute nodes and reporting node information to the Master. The Master collects resource usage from each node and manages and coordinates the allocation of computing resources.
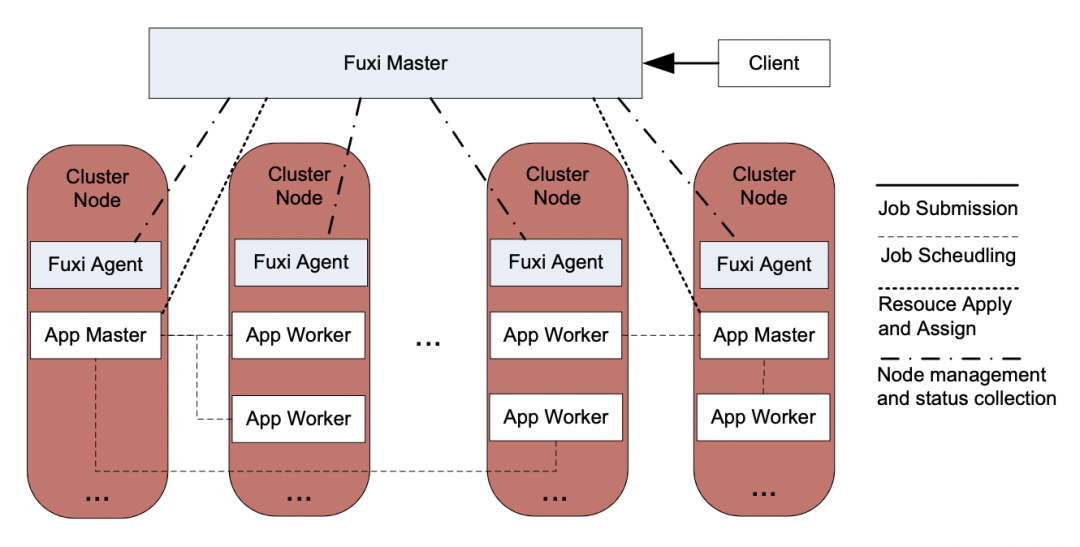 The ODPS task is transformed into a description file for Fuxi Task and submitted to Fuxi Master for processing. The Fuxi Master selects an idle node to start the Application Master process for the task. Once the Application Master starts, it requests computing resources from the Fuxi Master based on the task’s configuration information. Subsequent resource requests for the task are completed by the Application Master.
Upon receiving the resource request, if the cluster quota is full and resources are tight, it will queue on the compute cluster, waiting for resource allocation. If resources are available, it will allocate suitable resources based on the quota group of the Application, Job priority, and preemption conditions, notifying the Application Master process and informing Fuxi Agent of the resource allocation status. If the request is not fully satisfied, the Fuxi Master will continue to allocate resources to the Application Master when other allocatable idle resources are available.
The ODPS task is transformed into a description file for Fuxi Task and submitted to Fuxi Master for processing. The Fuxi Master selects an idle node to start the Application Master process for the task. Once the Application Master starts, it requests computing resources from the Fuxi Master based on the task’s configuration information. Subsequent resource requests for the task are completed by the Application Master.
Upon receiving the resource request, if the cluster quota is full and resources are tight, it will queue on the compute cluster, waiting for resource allocation. If resources are available, it will allocate suitable resources based on the quota group of the Application, Job priority, and preemption conditions, notifying the Application Master process and informing Fuxi Agent of the resource allocation status. If the request is not fully satisfied, the Fuxi Master will continue to allocate resources to the Application Master when other allocatable idle resources are available.

After receiving the resource allocation message, the Application Master sends the specific job plan to the corresponding Fuxi Agent. The job plan contains the necessary information to start specific processes, such as executable file name, startup parameters, and resource (e.g., CPU/memory) limits.
The Fuxi Agent, upon receiving the job plan from the Application Master, will start the worker job process. Once the worker starts, it will communicate with the Application Master, read data from distributed storage, and begin executing the computation logic. As the computation task executes, workers will be continuously launched and released. Once all computation tasks are completed, results will be written to the corresponding folder, and the worker will report back to the Application Master that the task has been successfully completed, which in turn communicates with the Fuxi Master to release resources.
Thus, the entire ODPS task execution is completed, and each component updates the task status in sequence. This SQL task instance is marked as successful, fulfilling its glorious mission, and awaits the next invocation from the scheduling engine.
After receiving the resource allocation message, the Application Master sends the specific job plan to the corresponding Fuxi Agent. The job plan contains the necessary information to start specific processes, such as executable file name, startup parameters, and resource (e.g., CPU/memory) limits.
The Fuxi Agent, upon receiving the job plan from the Application Master, will start the worker job process. Once the worker starts, it will communicate with the Application Master, read data from distributed storage, and begin executing the computation logic. As the computation task executes, workers will be continuously launched and released. Once all computation tasks are completed, results will be written to the corresponding folder, and the worker will report back to the Application Master that the task has been successfully completed, which in turn communicates with the Fuxi Master to release resources.
Thus, the entire ODPS task execution is completed, and each component updates the task status in sequence. This SQL task instance is marked as successful, fulfilling its glorious mission, and awaits the next invocation from the scheduling engine.