Introduction
The rapid development of artificial intelligence technology has led to the widespread application of intelligent voice embedded systems based on neural network technology in industries such as smartphones, smart speakers, wearable devices, smart homes, AI IoT, robotics, and automotive assistance systems due to their small size, low power consumption, and low cost. This article briefly introduces the hardware platform MT7686 and the intelligent voice recognition system developed based on convolutional neural network technology, covering the involved software and hardware architecture and algorithms.
Keywords
Artificial Intelligence (AI), Neural Networks (NN), Embedded Systems (EBS), Intelligent Voice (AVO)
Chapter 1 Basic Knowledge
The embedded intelligent voice recognition system mainly involves three major components: voice signal preprocessing, neural network recognition algorithms, and embedded system software and hardware design. This article mainly analyzes the related designs of embedded systems, providing only a conceptual introduction to the involved voice and algorithms.
1.1 Basic Functions of Intelligent Voice System
1.1.1 Audio Signal Input Function
The audio signal input typically refers to Mic Phone input, which can be in the form of a single Mic or a Mic array. From a working principle perspective, it can be divided into digital and analog types. The key performance indicators of the Mic aresensitivity and signal-to-noise ratio, generally requiring a sensitivitygreater than-42dBV @94dB 1kHz, SNR greater than 65dB.
1.1.2 Audio Signal Output Function
Audio signals are typically output through amplifiers driving speakers or headphones.
1.1.3 Wake Word and Command Word Customization Function
Wake words and command words are customized according to application scenarios and requirements.
1.1.4 Voice Interruption Function
The voice recognition technology can recognize command words and execute corresponding commands.
1.1.5 Voice Wake Function
The system can enter working mode through wake words while in low-power standby mode.
1.2 Audio Signal Front-End Preprocessing
1.2.1 Automatic Gain Control (AGC)
1.2.2 Noise Reduction (NS)
1.2.3 Echo Cancellation (AEC)
1.2.4 Voice Activity Detection (VAD)
1.2.5 Beamforming (BF)
1.2.6 Resampling (ReSample)
1.3 Introduction to Common Voice Recognition Algorithms
1.3.1 Neural Network (NN) Technology
● Deep Neural Network (DNN)
● Convolutional Neural Network (CNN)
● Recurrent Neural Network (RNN)
1.3.2 Voice Feature Introduction to MFCC
In voice recognition (Speech Recognition) and speaker recognition (Speaker Recognition), the most commonly used voice feature is the Mel-frequency cepstral coefficients (MFCC), which are the cepstral parameters extracted in the Mel scale frequency domain. The Mel scale describes the non-linear characteristics of human ear frequency, which can be approximately represented by the following formula:
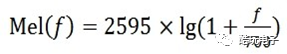
Where f is the frequency, measured in Hz. The following figure shows the relationship between Mel frequency and linear frequency:
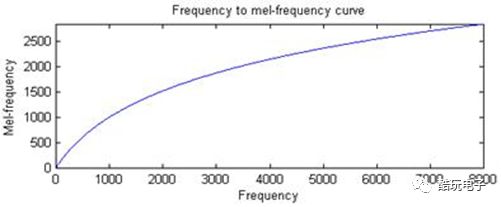
Figure 1 Relationship between Mel frequency and linear frequency
1.3.3 Voice Feature Parameter MFCC Extraction Process
Basic extraction process:

Figure 2 Basic process of MFCC parameter extraction
For detailed explanation of voice feature MFCC, please refer to Appendix 1.
1.3.4 Common Open Source Voice Algorithms
● WebRTC
Web Real-Time Communication, abbreviated as WebRTC, was incorporated into the World Wide Web Consortium’s W3C recommendation standard on June 1, 2011. WebRTC supports audio and video collection, encoding/decoding, network transmission, display, etc., and also supports cross-platform: Windows, Linux, Mac, Android, etc.
● Speex
Speex is a free open-source audio compression format primarily for voice. Currently, due to the emergence of Opus, there are almost no users encoding/decoding with Speex. Speex is often used for audio noise reduction, echo cancellation, gain control, and other front-end audio signal preprocessing.
Chapter 2 Intelligent Voice System Hardware Design
The intelligent voice embedded system has different implementation solutions due to different applications and algorithms, with the core part being the intelligent voice processing module, which is a basic requirement for constructing an intelligent voice system. The actual embedded voice recognition system includes the voice processing module and other auxiliary functional modules. This article takes the MT7686 platform as an example to detail the hardware selection and core circuit design of the voice system.
2.1 Overview of System Hardware Architecture
2.1.1 Architecture of Intelligent Voice Processing Module
The system architecture of the intelligent voice processing module is shown in Figure 3.
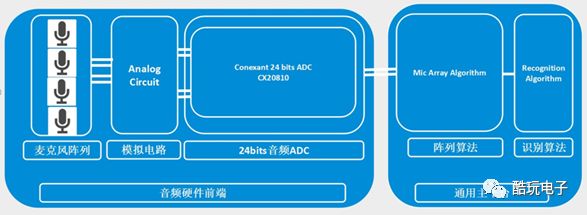
Figure 3: Architecture diagram of the intelligent voice processing module
The audio front-end circuit mainly includes coupling, amplification, filtering, and signal acquisition circuits for audio input signals, as well as audio analog-to-digital conversion and output circuits, and the power amplification circuit for audio signals. The general main platform usually includes an MCU processor and a DSP coprocessor. The MCU is used for timing, logic, and interface control, while the DSP is used for voice preprocessing, array algorithms, and recognition algorithms. The entire architecture is built around the input and output of audio signals and algorithm processing. Actual industry application solutions may also add some auxiliary functional modules as needed.
2.1.2 Architecture of Embedded Intelligent Voice System
As a system-level application, in addition to the core voice processing module, it also requires power supply modules, communication modules, debugging and upgrade modules, human-computer interaction modules, etc., to form a complete embedded intelligent voice processing system.
The functions of the embedded intelligent voice system are shown in Figure 4.
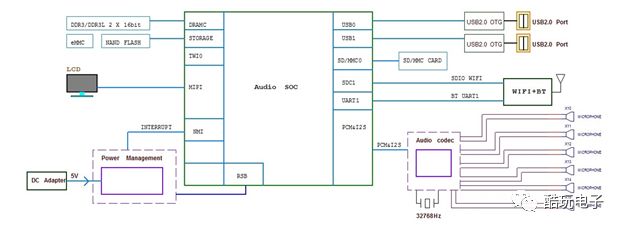 Figure 4:Function diagram of the intelligent voice system
Figure 4:Function diagram of the intelligent voice system
2.2 Core Components of Intelligent Voice System
The MT7876 embedded intelligent voice recognition solution is a low-end entry-level solution, which has a low cost and simple functions but fully possesses the core functions of an intelligent voice system. The MT7688 is based on ARM’s Cortex-M4F core with floating-point operation capability, with a main frequency of 192MHz; the audio Codec chip is selected based on the I2S interface ES8388.
2.2.1 Functional Block Diagram of MT7686
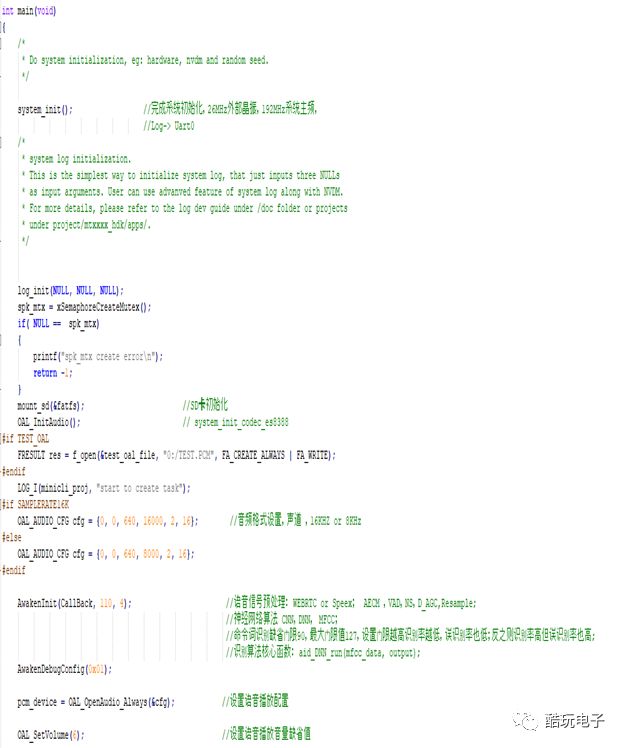
The system module of MT7686 is shown in Figure 5. The important functional modules and interfaces for the intelligent voice recognition solution are Cortex-M4 with FPU, SRAM, Flash, Crypto engine, DMA, and I2S, I2C, UART interfaces.
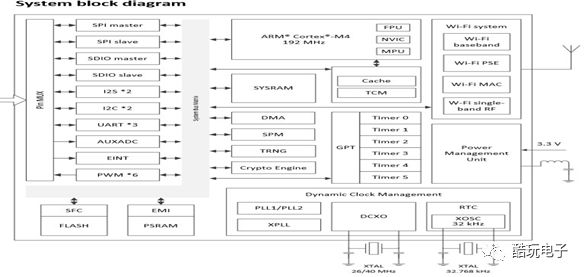
Figure 5 :Functional block diagram of MT7686 system module
2.2.2 MT7686 Main Functional Interfaces and Performance Parameters
The main functional interfaces and performance parameters of MT7686 are shown in Figure 6.

Figure6 : MT7686 Main Functional Interfaces and Performance Parameters
2.2.3 ES8388 Functional Block Diagram
The main functions of ES8388 are shown in Figure 7:
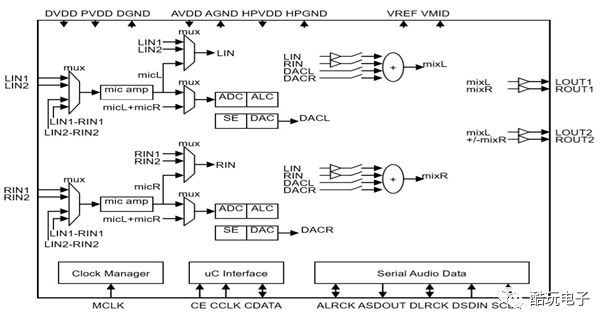
Figure7 :ES8388 Functional Block Diagram
2.2.4 ES8388 Performance Parameters

2.3 MT7686 Voice Recognition System Hardware Design
2.3.1 MT7686 Minimum System Design
The minimum system of MT7686 is shown in Figure 8.
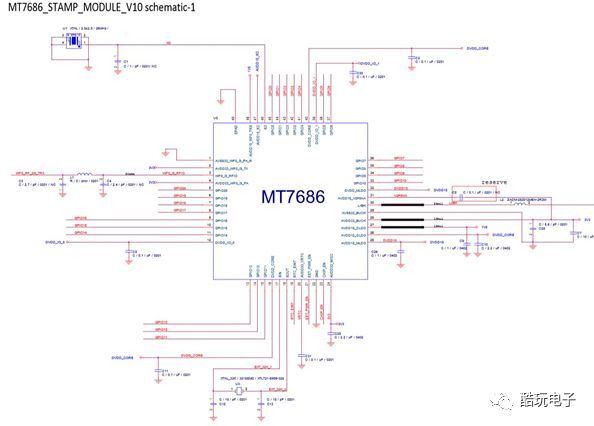
Figure8 :MT7686 Minimum System Diagram
It should be noted that the external crystal oscillator of MT7686 can use either 26MHz or 40MHz, which is default configured as 26MHz in the software initialization code.
2.3.2 ES8388 Interface Circuit Design
ES8388 supports up to 4 audio signal inputs and 4 audio signal outputs. MT7686 configures and controls ES8388 via the I2C bus, and the audio digital signal reading and writing between MT7686 and ES8388 is implemented through the I2S bus. The circuit diagram of its interface is shown in Figure 9.
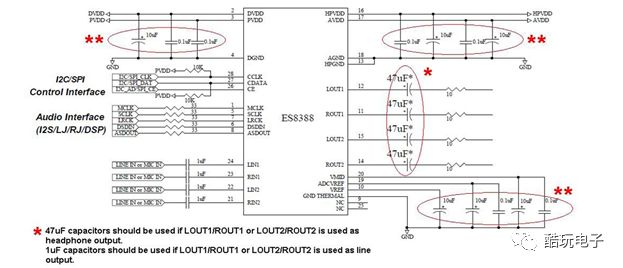
Figure9: ES8388 Interface Circuit Diagram
Chapter 3 Intelligent Voice System Software Architecture Description
The software architecture and development model of the embedded intelligent voice system are shown in Figure 10.
10 :Embedded Intelligent Voice System Software Architecture
The SDK hierarchical relationship of the MT7686 intelligent voice development platform is shown in Figure 11.
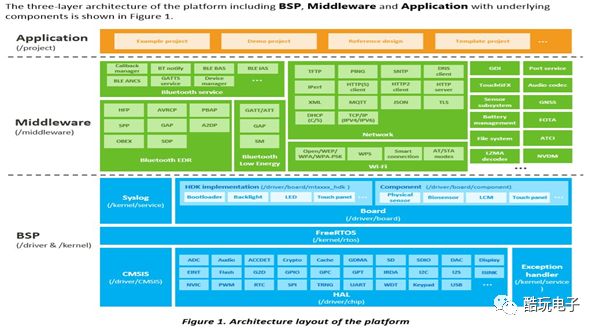
Figure11 :SDK Hierarchical Relationship Diagram
The project folder for the MT7686 intelligent voice project is shown in the following figure.
Among them, the <DOC> folder mainly contains various software and hardware documents and SDK API explanations, the <driver> folder includes three subfolders: CMSIS, Chip, and Board. The CMSIS folder mainly includes assembly and C startup code, DSP library files, and the most basic code; the Chip folder mainly includes the low-level drivers for various functional modules of MT7686, and the Board folder contains the board-level development package, including platform configuration files. The Kernel folder mainly contains operating system-related files, and the MT7686 intelligent voice development platform uses FreeRTOS, which has strong real-time performance and small code size. The Out folder contains the elf and bin files generated after compilation and linking, which are used for downloading and flashing the Flash memory. The Project folder is the entry point for project files, including the main function of the App and some system code.
Among them, the most difficult to understand and handle is the code under the middleware folder, which contains subfolders <MTK> and <third_party>. The <MTK> subfolder mainly contains various communication protocols and special modules, as shown in the following figure.
<third_party> includes voice preprocessing algorithms, voice recognition algorithms, FAT file systems, and other core functional modules of intelligent voice, as well as related network protocols.
The command word wake demonstration function requires algorithms mainly located in the <aid_awaken> folder.
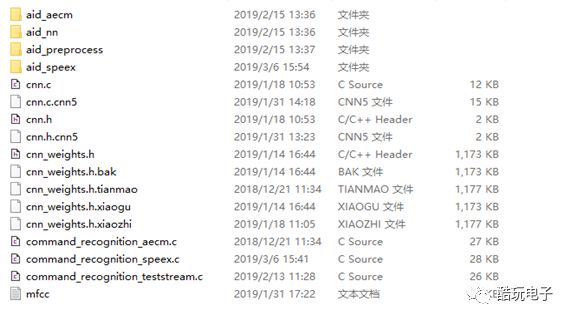
Among them, cnn.c, cnn.h, and cnn_weights.h contain the pre-trained command word model files, and the voice recognition function based on the CNN algorithm is mainly located in the command_recognition.c file. The <aid_nn> folder mainly includes a large number of basic function libraries for neural networks, and the <aid_preprocess> folder contains voice signal preprocessing algorithm files such as AGC, NS, VOD, etc.
Chapter 4 Core Source Code Analysis